题目1:二叉树的中序遍历(LeetCode 94)
问题描述
给定一个二叉树的根节点 root,返回它的中序 遍历。中序遍历的顺序是:左子树 → 根节点 → 右子树。
示例:
输入: root = [1, null, 2, 3]
输出: [1, 3, 2]
解释:
1
\
2
/
3
中序遍历: 左(1的左子树空) → 1 → 右子树(2的左子树3 → 2 → 右子树空) = [1, 3, 2]解题思路
核心思想: 递归(深度优先遍历)
-
先遍历左子树
-
然后访问根节点
-
最后遍历右子树
Java代码(带详细注释)
java
import java.util.ArrayList;
import java.util.List;
/**
* LeetCode 94. 二叉树的中序遍历
* 难度:简单
* 给定一个二叉树的根节点 root,返回它的中序遍历。
*
* 定义二叉树节点
*/
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
public class BinaryTreeInorderTraversal {
/**
* 递归法实现中序遍历
* 时间复杂度:O(n),空间复杂度:O(n)
*/
public List<Integer> inorderTraversal(TreeNode root) {
// 创建结果列表
List<Integer> result = new ArrayList<>();
// 调用递归函数
inorder(root, result);
return result;
}
/**
* 辅助递归函数
*/
private void inorder(TreeNode node, List<Integer> result) {
// 递归终止条件:节点为空
if (node == null) {
return;
}
// 1. 递归遍历左子树
inorder(node.left, result);
// 2. 访问当前节点(将节点值加入结果)
result.add(node.val);
// 3. 递归遍历右子树
inorder(node.right, result);
}
}流程图(Mermaid)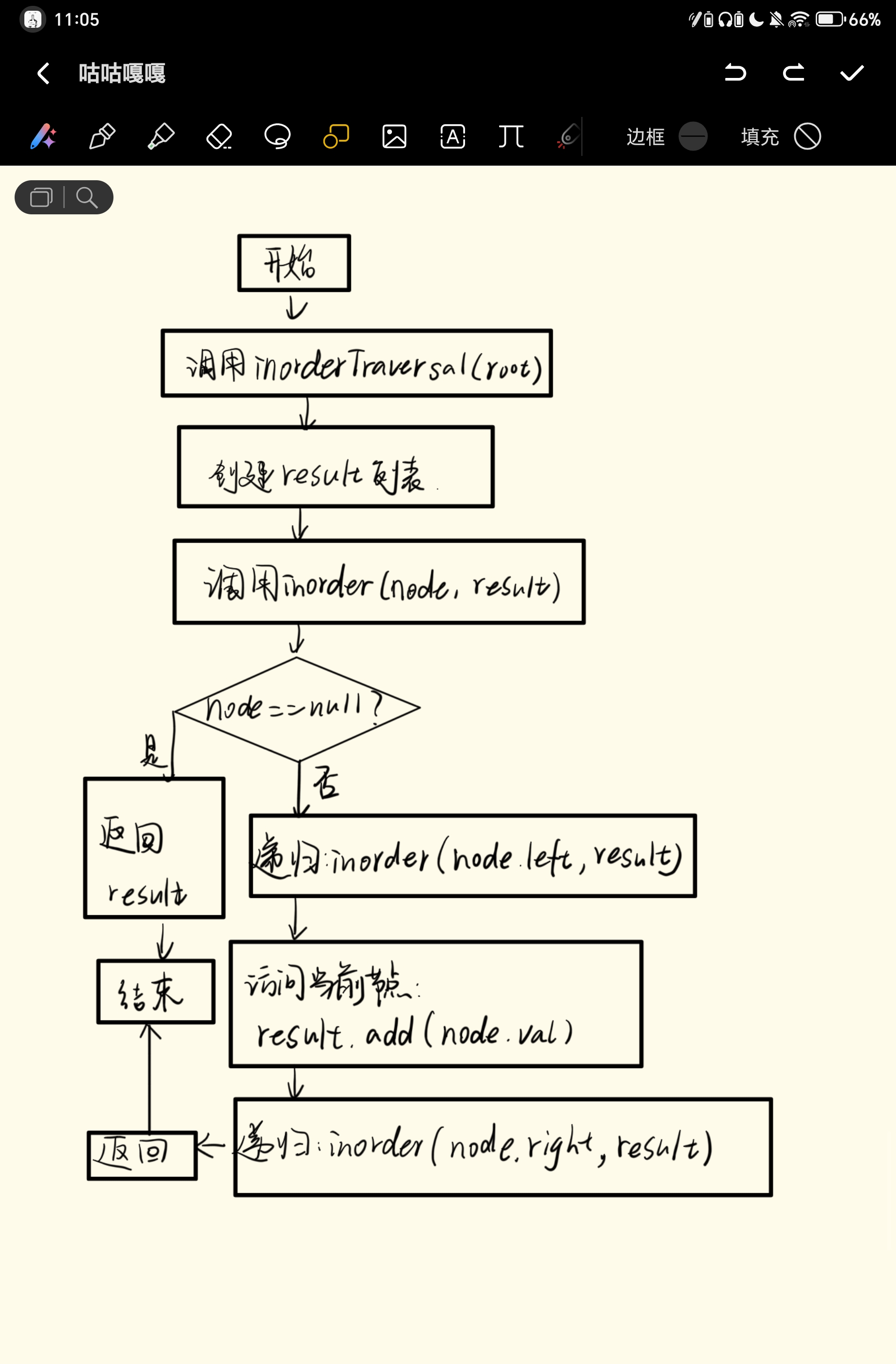
执行过程图解:
二叉树:
1
\
2
/
3
递归调用过程:
inorder(1)
├── inorder(1.left) → null → 返回
├── 访问 1 → result = [1]
└── inorder(1.right) → 进入节点2
├── inorder(2.left) → 进入节点3
│ ├── inorder(3.left) → null → 返回
│ ├── 访问 3 → result = [1, 3]
│ └── inorder(3.right) → null → 返回
├── 访问 2 → result = [1, 3, 2]
└── inorder(2.right) → null → 返回
最终结果: [1, 3, 2] ✓中序遍历的物理意义:
对于二叉搜索树(BST),中序遍历的结果是升序排列的!
例如:
5
/ \
3 7
/ \ \
2 4 8
中序遍历: [2, 3, 4, 5, 7, 8] ← 升序排列问题1:root = [1, null, 2, 3] 这个东西叫什么?怎么画出树?
答: 这叫做层序遍历的序列化表示(Level-order Serialization)。它是LeetCode为了方便输入输出,用数组表示二叉树的方式。
规则: 按照从上到下、从左到右的顺序列出所有节点,null 表示该位置没有节点。
如果数组是 [3, 9, 20, null, null, 15, 7]:
3
/ \
9 20
/ \ / \
null null 15 7
怎么画的?
索引0: 3 → 根
索引1: 9 → 3的左
索引2: 20 → 3的右
索引3: null → 9的左
索引4: null → 9的右
索引5: 15 → 20的左
索引6: 7 → 20的右
最终:
3
/ \
9 20
/ \
15 7问题2:递归是什么意思?
答: 递归就是函数调用自己,就像一个套娃,或者照镜子时看到镜子里还有镜子。
最经典的解释:
递归 = 递推 + 回归
"递":把问题分解成更小的子问题
"归":从最小的问题开始,一层层返回结果生活类比:
故事:从前有座山,山里有座庙,庙里有个和尚讲故事...
这就是递归!故事里套着同样的故事。
电影《盗梦空间》:
梦中梦 → 一层层进入 → 最底层 → 一层层出来
这就是递归的执行过程!代码中的递归(中序遍历):
java
private void inorder(TreeNode node, List<Integer> result) {
if (node == null) {
return; // 这是最小的问题:空节点什么都不做
}
// "递"的过程:不断深入左子树
inorder(node.left, result); // 调用自己,处理更小的子树
result.add(node.val); // 访问当前节点
// 从递归中"归"回来,再处理右子树
inorder(node.right, result); // 再次调用自己
}递归的四个要素:
-
终止条件:什么时候停止(node == null)
-
递归调用:调用自己(inorder(node.left, result))
-
当前处理:当前层做什么(result.add(node.val))
-
返回值:需要返回什么(void表示不返回)
问题3:inorderTraversal 翻译一下是什么意思?
答: 这是英语专业术语:
| 单词 | 含义 |
|---|---|
inorder |
中序(in + order,在中间的顺序) |
Traversal |
遍历(走过、访问每一个节点) |
inorderTraversal |
中序遍历 |
其他两种遍历:
-
preorderTraversal= 前序遍历(pre = 在前) -
postorderTraversal= 后序遍历(post = 在后)
问题4:inorder(root, result); 是方法吗?
答: 是的,这是一个方法调用。
java
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
inorder(root, result); // ← 这里调用了下面的方法
return result;
}
private void inorder(TreeNode node, List<Integer> result) {
// 这里是方法的具体实现
}方法调用就是"找人干活":
java
// 调用者(老板)
inorder(root, result);
// ↑ ↑
// 参数1 参数2
// 被调用的方法(员工)
private void inorder(TreeNode node, List<Integer> result) {
// 老板让我处理 node 和 result
// 我用 node 和 result 来做具体工作
}方法的结构:
private void inorder(TreeNode node, List<Integer> result)
↑ ↑ ↑ ↑ ↑
修饰符 返回值 方法名 参数1 参数2问题5:return 后面没有东西,是因为 void 的原因吗?
答: 完全正确!
java
private void inorder(TreeNode node, List<Integer> result) {
if (node == null) {
return; // ← 因为返回值类型是 void,所以什么都不返回
}
// ...
}void 和 return 的关系:
| 返回值类型 | return 用法 |
例子 |
|---|---|---|
void(无返回值) |
return; 或省略 |
if(条件) return; |
非 void(有返回值) |
return 值; |
return 5; |
java
// void方法:可以省略return
private void method1() {
// 执行完所有代码自动返回
}
// void方法:也可以写return(提前结束)
private void method2() {
if (condition) {
return; // 提前结束,不执行后面的代码
}
// 后面的代码...
}
// 非void方法:必须有return
private int method3() {
return 5; // 必须返回一个int
}在递归中的意义:
java
if (node == null) {
return; // 到达空节点,停止递归,返回上一层
}
// 如果不写return,会继续执行,但node是null,访问node.left会报错!问题6:inorder(node.left, result); 是什么意思?
答: 这是递归调用 ,意思是"去处理当前节点的左子树"。
它不是在赋值,而是在执行操作!
java
// 错误理解 ❌
inorder(node.left, result); // 把左节点的值赋给result?
// 正确理解 ✓
inorder(node.left, result); // 去遍历左子树,把结果放到result里详细图解:
当前节点是 1:
1 ← node
/ \
null 2
执行 inorder(node.left, result):
意思是:去处理 node.left(即左子树)
左子树是 null → 递归终止,什么都不做
然后回到节点1,执行 result.add(1)
然后执行 inorder(node.right, result) → 去处理右子树
整个过程:
inorder(1)
├─→ inorder(1.left) ← 去处理左子树
│ └→ 发现是null,返回
├─→ result.add(1) ← 访问当前节点
└─→ inorder(1.right) ← 去处理右子树
└→ ...不是"赋值",是"执行遍历动作":
java
// 如果 node = 1
inorder(node.left, result);
// 等价于:去遍历以节点1的左孩子为根的整棵树
// 并把遍历结果添加到 result 列表中问题7:JVM怎么知道它从哪个节点开始遍历?
答: JVM是通过递归调用栈来追踪的。每次递归调用,JVM都会记录当前执行到哪里。
调用栈(Call Stack)图示:
假设树:
1
/ \
2 3
执行 inorder(1):
Step 1: 调用 inorder(1)
JVM把"inorder(1)"压入栈顶
栈:[inorder(1)]
Step 2: inorder(1) 调用 inorder(1.left) = inorder(2)
栈:[inorder(1), inorder(2)] ← 最上面是当前执行的
Step 3: inorder(2) 调用 inorder(2.left) = inorder(null)
栈:[inorder(1), inorder(2), inorder(null)]
Step 4: inorder(null) 发现是null,return
弹出 inorder(null)
栈:[inorder(1), inorder(2)]
Step 5: 回到 inorder(2),执行 result.add(2)
栈:[inorder(1), inorder(2)]
Step 6: inorder(2) 调用 inorder(2.right) = inorder(null)
栈:[inorder(1), inorder(2), inorder(null)]
Step 7: inorder(null) 返回
弹出 inorder(null)
栈:[inorder(1), inorder(2)]
Step 8: inorder(2) 执行完毕,返回
弹出 inorder(2)
栈:[inorder(1)]
Step 9: 回到 inorder(1),执行 result.add(1)
栈:[inorder(1)]
Step 10: inorder(1) 调用 inorder(1.right) = inorder(3)
栈:[inorder(1), inorder(3)]
... 继续处理节点3
这就是JVM的"记忆"机制 —— 它通过栈记住每个递归调用的位置!关键理解:
-
每次递归调用,JVM都会在栈上创建一个新的帧(frame)
-
每个帧记录了:方法名、参数、局部变量、执行位置
-
当方法返回时,弹出栈顶帧,回到上一层继续执行
-
所以JVM永远不会迷路!
题目2:二叉树的最大深度(LeetCode 104)
问题描述
给定一个二叉树,找出其最大深度。二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
示例:
输入: root = [3, 9, 20, null, null, 15, 7]
输出: 3
解释:
3
/ \
9 20
/ \
15 7
最大深度 = 3解题思路
核心思想: 递归(分治法)
-
最大深度 = max(左子树最大深度, 右子树最大深度) + 1
-
递归终止条件:节点为空,返回0
Java代码(带详细注释)
java
/**
* LeetCode 104. 二叉树的最大深度
* 难度:简单
* 给定一个二叉树,找出其最大深度。
*/
public class MaximumDepthOfBinaryTree {
public int maxDepth(TreeNode root) {
// 递归终止条件:节点为空,深度为0
if (root == null) {
return 0;
}
// 计算左子树的最大深度
int leftDepth = maxDepth(root.left);
// 计算右子树的最大深度
int rightDepth = maxDepth(root.right);
// 当前节点的深度 = max(左子树深度, 右子树深度) + 1
return Math.max(leftDepth, rightDepth) + 1;
}
}流程图(Mermaid)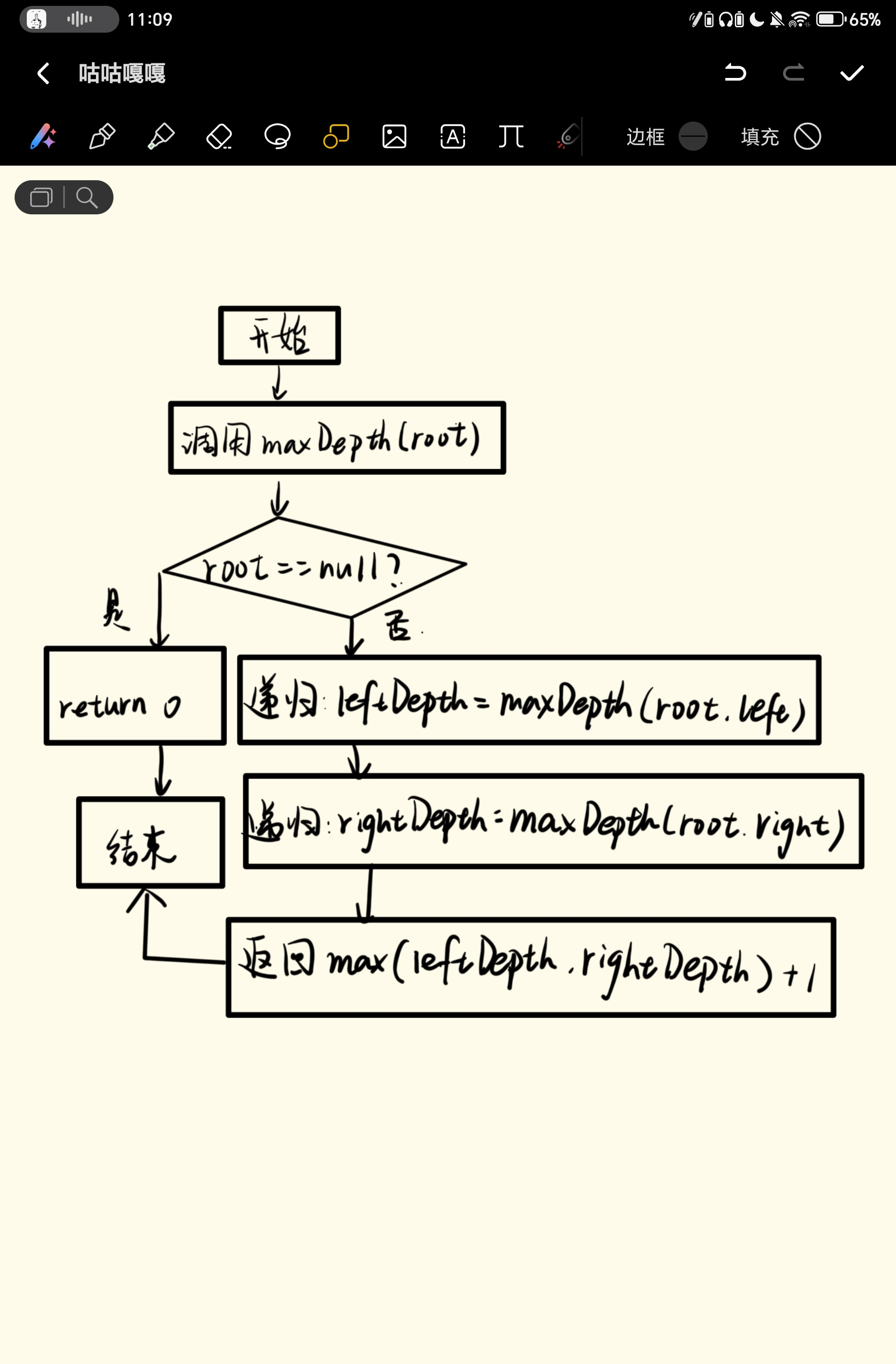
执行过程图解:
二叉树:
3
/ \
9 20
/ \
15 7
递归计算过程:
maxDepth(3)
├── leftDepth = maxDepth(9)
│ ├── leftDepth = maxDepth(null) = 0
│ ├── rightDepth = maxDepth(null) = 0
│ └── 返回 max(0,0) + 1 = 1
├── rightDepth = maxDepth(20)
│ ├── leftDepth = maxDepth(15)
│ │ ├── leftDepth = maxDepth(null) = 0
│ │ ├── rightDepth = maxDepth(null) = 0
│ │ └── 返回 max(0,0) + 1 = 1
│ ├── rightDepth = maxDepth(7)
│ │ ├── leftDepth = maxDepth(null) = 0
│ │ ├── rightDepth = maxDepth(null) = 0
│ │ └── 返回 max(0,0) + 1 = 1
│ └── 返回 max(1,1) + 1 = 2
└── 返回 max(1,2) + 1 = 3
最终结果: 3 ✓可视化深度计算:
节点3: 深度 = max(节点9深度, 节点20深度) + 1
= max(1, 2) + 1 = 3
节点20: 深度 = max(节点15深度, 节点7深度) + 1
= max(1, 1) + 1 = 2
叶子节点: 深度 = max(0, 0) + 1 = 1问题1:递归和遍历有什么区别?
答: 这是两个不同维度的概念:
| 概念 | 含义 | 例子 |
|---|---|---|
| 遍历 | 访问每个节点一次 | 中序遍历、前序遍历、后序遍历 |
| 递归 | 一种实现方式 | 用递归来实现遍历 |
它们是"方法"和"目的"的关系:
遍历 是"目的"(我要访问所有节点)
递归 是"方法"(我用什么方式来实现)类比理解:
吃饭(目的) vs 用筷子吃(方法)
遍历(目的) vs 用递归实现遍历(方法)四种遍历方式:
1. 前序遍历(根左右)
2. 中序遍历(左根右) ← 这些是"遍历顺序"
3. 后序遍历(左右根)
4. 层序遍历(按层)
每种都可以用递归或迭代实现!代码对比:
java
// 递归实现中序遍历
void inorder(TreeNode node) {
if (node == null) return;
inorder(node.left); // 递归调用自己
visit(node);
inorder(node.right);
}
// 迭代实现中序遍历(用栈)
void inorder(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (curr != null || !stack.isEmpty()) {
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
curr = stack.pop();
visit(curr);
curr = curr.right;
}
}结论: 递归是一种实现遍历的方式,遍历是我们要完成的任务。
问题2:遍历用 for(xx : xx) 体现,那递归呢?
答: 递归没有特定的语法符号 ,它是通过函数调用自己来实现的。
java
// 遍历(用for循环)
for (int i = 0; i < nums.length; i++) {
// 访问每个元素
}
// 特点:有循环语法 for/while
// 递归(没有特殊语法)
void inorder(TreeNode node) {
if (node == null) return;
inorder(node.left); // ← 这就是递归!调用自己
visit(node);
inorder(node.right); // ← 递归调用自己
}
// 特点:函数内部调用自己递归的"标志"就是:函数里调用自己!
java
// 递归的识别方法:
void 方法名(参数) {
if (终止条件) return;
// ... 可能有一些处理
方法名(子参数); // ← 这里!调用自己!
// ... 可能有一些处理
}类比:
for循环:就像在操场上跑圈,一圈一圈重复
for → 跑一圈 → for → 跑一圈 → for → ...
递归:就像剥洋葱,一层一层剥开
剥洋葱(大洋葱)
→ 剥掉外皮
→ 剥洋葱(小一点的洋葱) ← 调用自己
→ 剥掉外皮
→ 剥洋葱(更小的洋葱)
→ ...直到没有洋葱可剥题目3:翻转二叉树(LeetCode 226)
问题描述
给你一棵二叉树的根节点 root,翻转这棵二叉树,并返回其根节点。
示例:
输入: root = [4, 2, 7, 1, 3, 6, 9]
输出: [4, 7, 2, 9, 6, 3, 1]
解释:
4 4
/ \ / \
2 7 翻转后→ 7 2
/ \ / \ / \ / \
1 3 6 9 9 6 3 1解题思路
核心思想: 递归(分治法)
-
交换当前节点的左右子树
-
递归翻转左子树
-
递归翻转右子树
Java代码(带详细注释)
java
/**
* LeetCode 226. 翻转二叉树
* 难度:简单
* 给你一棵二叉树的根节点 root,翻转这棵二叉树,并返回其根节点。
*/
public class InvertBinaryTree {
public TreeNode invertTree(TreeNode root) {
// 递归终止条件:节点为空
if (root == null) {
return null;
}
// 1. 交换当前节点的左右子树
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 2. 递归翻转左子树
invertTree(root.left);
// 3. 递归翻转右子树
invertTree(root.right);
// 返回根节点
return root;
}
}流程图(Mermaid)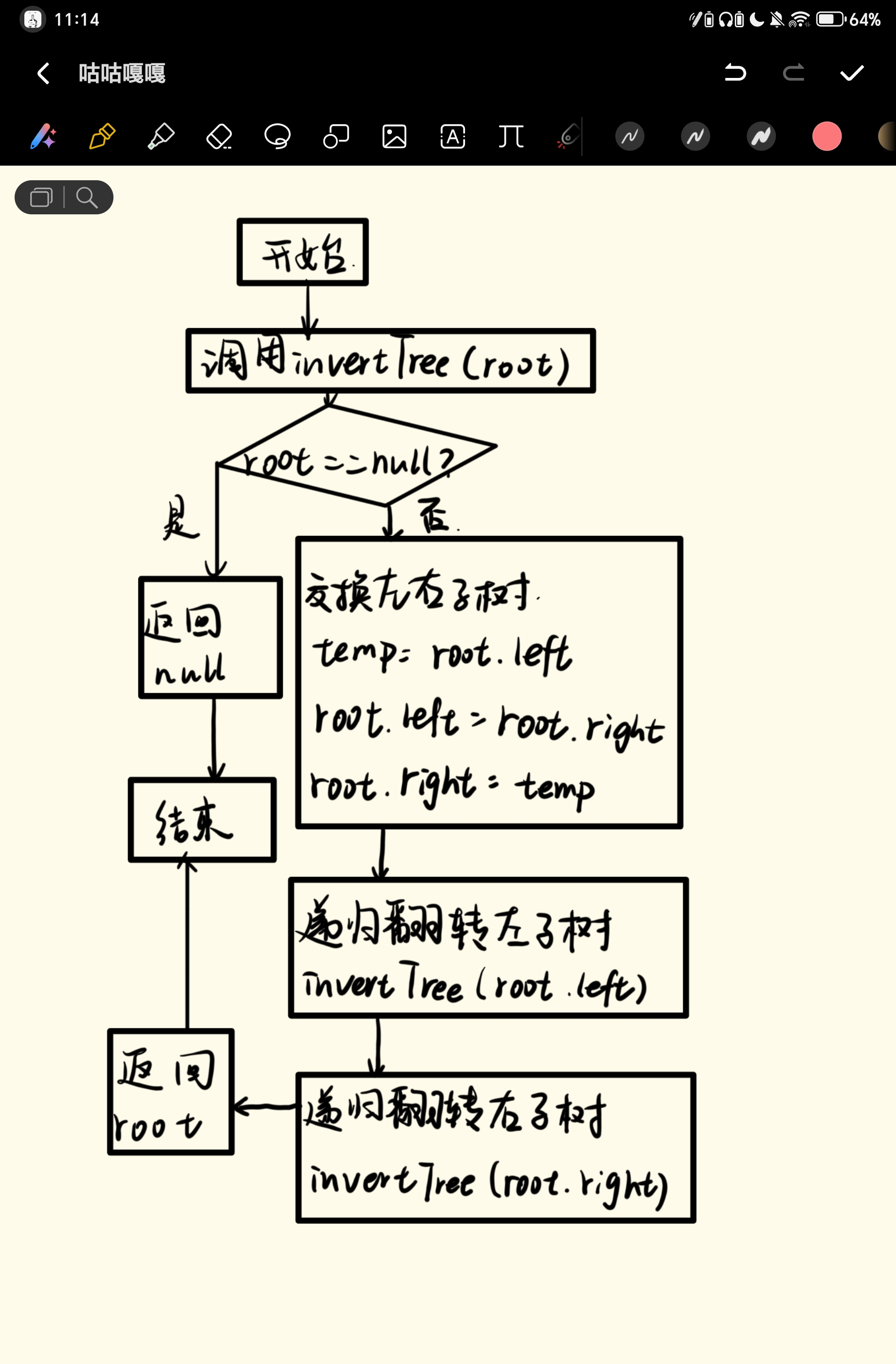
执行过程图解:
原二叉树:
4
/ \
2 7
/ \ / \
1 3 6 9
翻转过程(从根开始):
Step 1: 翻转节点4
4
/ \
7 2 ← 交换了左右子树
/ \ / \
6 9 1 3
Step 2: 递归翻转左子树(节点7)
4
/ \
7 2
/ \ / \
9 6 1 3 ← 节点7的左右子树交换了
Step 3: 递归翻转右子树(节点2)
4
/ \
7 2
/ \ / \
9 6 3 1 ← 节点2的左右子树交换了
最终结果:
4
/ \
7 2
/ \ / \
9 6 3 1 ✓逐层翻转细节:
原树:
4
/ \
2 7
/ \ / \
1 3 6 9
第1层(根节点4):
交换 2 和 7
4
/ \
7 2
/ \ / \
6 9 1 3
第2层(节点7):
交换 6 和 9
4
/ \
7 2
/ \ / \
9 6 1 3
第2层(节点2):
交换 1 和 3
4
/ \
7 2
/ \ / \
9 6 3 1
完成 ✓问题1:invertTree(root.left); 中 invertTree() 是方法吗?JVM怎么知道要翻转节点?
答: 是的,invertTree() 是一个方法 。JVM并不是"知道要翻转",而是按照你写的代码执行!
java
public TreeNode invertTree(TreeNode root) {
if (root == null) return null;
// 第1步:交换左右孩子
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 第2步:递归翻转左子树
invertTree(root.left); // ← 这里调用自己
// 第3步:递归翻转右子树
invertTree(root.right); // ← 这里调用自己
return root;
}JVM执行流程(详细拆解):
调用: invertTree(节点4)
执行过程(从代码行数看):
Line 1: 调用方法,root = 节点4
Line 2: root != null,继续
Line 3: temp = root.left (temp = 节点2)
Line 4: root.left = root.right (节点4的左孩子变成节点7)
Line 5: root.right = temp (节点4的右孩子变成节点2)
Line 6: 调用 invertTree(root.left)
→ 此时 root.left 是节点7
→ 进入新的 invertTree(节点7)
→ 重复同样的过程...
Line 7: 上一行执行完毕,回来继续
Line 8: 调用 invertTree(root.right)
→ 此时 root.right 是节点2
→ 进入新的 invertTree(节点2)
→ 重复同样的过程...
Line 9: 返回 rootJVM的执行规则:
-
顺序执行:代码从上到下执行
-
方法调用:跳到方法体执行,执行完跳回来
-
递归调用:和普通方法调用一样,只是调用的方法是自己
所以JVM不知道"要翻转"这个概念,它只是在执行:
交换 → 处理左子树 → 处理右子树 → 返回完整的执行追踪:
调用 invertTree(4):
├─ 交换 4 的左右孩子: 2 ↔ 7
├─ 执行 invertTree(4.left) → invertTree(7):
│ ├─ 交换 7 的左右孩子: 6 ↔ 9
│ ├─ 执行 invertTree(7.left) → invertTree(9):
│ │ ├─ 9 无孩子,直接返回 9
│ │ └─ 返回
│ ├─ 执行 invertTree(7.right) → invertTree(6):
│ │ ├─ 6 无孩子,直接返回 6
│ │ └─ 返回
│ └─ 返回 7
├─ 执行 invertTree(4.right) → invertTree(2):
│ ├─ 交换 2 的左右孩子: 1 ↔ 3
│ ├─ 执行 invertTree(2.left) → invertTree(3):
│ │ ├─ 3 无孩子,返回 3
│ │ └─ 返回
│ ├─ 执行 invertTree(2.right) → invertTree(1):
│ │ ├─ 1 无孩子,返回 1
│ │ └─ 返回
│ └─ 返回 2
└─ 返回 4
树被成功翻转!✓关键理解:
-
JVM是"傻瓜式"执行器,它只执行指令
-
你写"交换左右",它就交换
-
你写"递归翻转左子树",它就递归翻转左子树
-
它不需要理解"翻转"的含义,只需要执行你写的代码