目录
- 一、RAG及其成型框架
-
- [1.1 什么是RAG](#1.1 什么是RAG)
- [1.2 三大组件通俗讲解,新手一眼看懂整套架构](#1.2 三大组件通俗讲解,新手一眼看懂整套架构)
- 二、部署Embedding模型
-
- [2.1 下载模型](#2.1 下载模型)
- [2.2 部署模型](#2.2 部署模型)
- [2.3 向量转换](#2.3 向量转换)
- 三、部署向量库数据库
-
- [3.1 部署Milvus](#3.1 部署Milvus)
- [3.2 部署Attu](#3.2 部署Attu)
- 四、测试场景
-
- [4.1 创建个人知识库](#4.1 创建个人知识库)
- [4.2 数据检索](#4.2 数据检索)
一、RAG及其成型框架
1.1 什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)在2020年被首次提出,是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力。
一句话总结:RAG 是给现有 AI 一个"现成知识库",让 AI 在回答问题前,先主动去指定的"资料库"里查资料,再基于真实、最新的资料生成答案,降低胡说八道的概率。
1.2 三大组件通俗讲解,新手一眼看懂整套架构
首先,为什么要转化为向量?
计算机底层只能处理数字,不能直接识别文字,相似度的计算也是利用向量的内积进行运算。语义相同的文字,生成的向量数字整体分布高度相似。
其次,需要应用到什么技术
很多刚入门向量检索的朋友,分不清模型、向量库、可视化工具的定位,需要先把三者核心作用讲透。
Embedding模型:BAAI/bge-large-zh-v1.5(当前中文最强检索模型)- 向量数据库:
Milvus 2.4.0单机Docker部署 - 可视化工具管理:
Attu 2.4(Milvus官方Web后台)
其关系如下:
| 组件 | 全称定位 | 通俗比喻 | 核心本职工作 |
|---|---|---|---|
| BAAI/bge-large-zh-v1.5 | Embedding 嵌入模型(语义转换器) | 翻译员 | 把自然文字翻译成机器能识别的 1024 维数字向量,精准捕捉中文语义相似度。 |
| Milvus 2.4.0 | 高性能向量数据库 | 档案仓库 + 高速检索机 | 专门存储 BAAI/bge-large-zh-v1.5 生成的向量、原文内容,建立索引实现毫秒级海量向量相似度匹配,负责精准召回相似法条,只负责 "找资料",不会理解文字含义。 |
| Attu | Milvus 的「可视化操作台」 | 显示屏 | 可视化创建集合、配置 HNSW 索引、手动导入向量、在线执行向量检索。 |
最后,完整链路
简而言之就是:BAAI/bge-large-zh-v1.5将文字转为向量,存储到Milvus中。用户每次搜索的时候,基于输入的文字同样调用 BAAI/bge-large-zh-v1.5 生成查询向量,Milvus利用内存暴力计算所有法条向量的 IP 相似度,取出最匹配的几条内容返回。
二、部署Embedding模型
2.1 下载模型
国内用户建议登录魔塔社区下载模型:魔塔社区地址
直接搜索bge-large-zh,然后下载即可
2.2 部署模型
我们需要找一个框架来运行下载的模型,这里我们使用vLLM,具体的下载及安装步骤可以参考我的这篇文章:Linux 环境极速部署 vLLM:从零搭建生产级大模型推理服务
安装完vLLM后,一建启动下载的BAAI/bge-large-zh-v1.5模型即可,下面命令表示允许所有ip访问,同时映射的端口是8890,最高只占用20%的电脑显存
bash
vllm serve /work/ai/model/bgeModel --trust-remote-code --host 0.0.0.0 --port 8890 --tensor-parallel-size 1 --gpu-memory-utilization 0.2 --max-num-seqs 4看到如下界面表示启动成功
2.3 向量转换
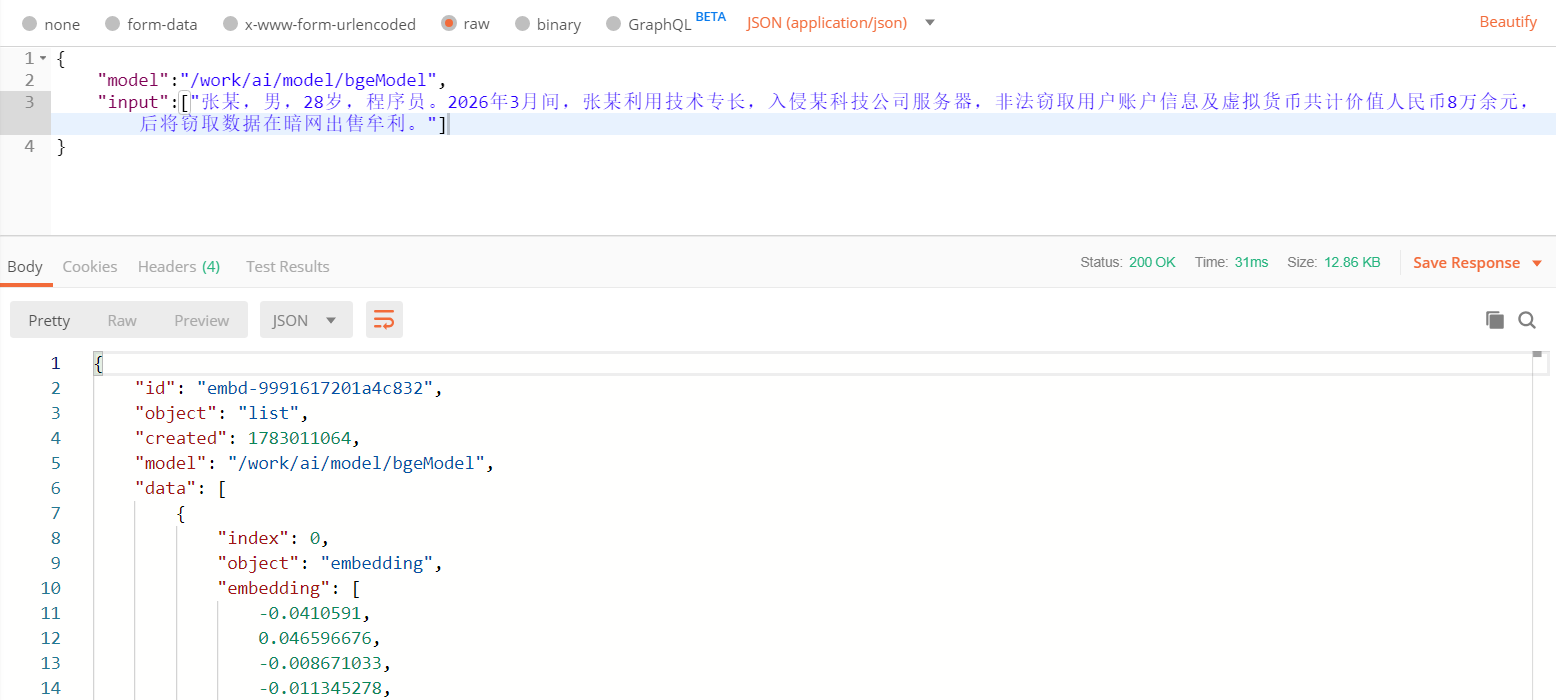
启动模型后,可通过post接口http://IP地址:端口/v1/embeddings来实现向量转换,请求体如下:
bash
{
"model":"xxxxxxx",
"input":["xxxxxxx"]
}其中model为模型地址,input为需要转化的内容。返回结果中的embedding即为转换的1024维向量
三、部署向量库数据库
3.1 部署Milvus
Milvus通过docker和docker compose部署,需要提前安装好

首先拉取Milvus镜像,总共有三个docker镜像,分别是milvus、etcd和minio。国内基本上都没办法直接从原始网站上拉取,所以建议从镜像网站拉取,再改名字
bash
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/milvusdb/milvus:v2.4.0
bash
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/milvusdb/milvus:v2.4.0 milvusdb/milvus:v2.4.0
bash
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/coreos/etcd:v3.5.5
bash
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/coreos/etcd:v3.5.5 quay.io/coreos/etcd:v3.5.5
bash
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/minio/minio:RELEASE.2023-03-20T20-16-18Z
bash
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/minio/minio:RELEASE.2023-03-20T20-16-18Z docker.io/minio/minio:RELEASE.2023-03-20T20-16-18Zdocker images 验证所有的镜像

新建启动文件docker-compose.yml,注意端口映射,不要和现有服务冲突
yaml
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -name=etcd -data-dir=/etcd -advertise-client-urls=http://0.0.0.0:2379 -listen-client-urls=http://0.0.0.0:2379 -listen-peer-urls=http://0.0.0.0:2380
ports:
- "2379:2379"
networks:
- milvus
restart: always
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
ports:
- "9010:9000"
- "9011:9001"
networks:
- milvus
restart: always
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.4.0
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9092:9091"
depends_on:
- "etcd"
- "minio"
networks:
- milvus
restart: always
networks:
milvus:
driver: bridge启动 Milvus,三个容器全部 Up 即为部署成功。
bash
docker compose up -d
docker compose ps
3.2 部署Attu
接着我们部署Attu,用于可视化管理Milvus。依旧从镜像网站拉取,再改名字
bash
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/zilliz/attu:v2.4
bash
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/zilliz/attu:v2.4 docker.io/zilliz/attu:v2.4启动可视化工具
bash
docker run -d --name attu -p 8088:3000 zilliz/attu:v2.4此时我们总共启动了四个docker容器

访问:http://IP地址:8088,连接参数为服务器IP地址,端口为milvus部署的端口,账号密码为空,连接成功即可。
四、测试场景
4.1 创建个人知识库
下面我们以创建法律知识库来做示例
先创建一个法律知识集合law_collection。其中主键id选择自增;向量字段为后续需要检索的字段,类型为float vector,长度即1024,例如我这的law_vector即为法律正文的向量字段;其余字段自定义。
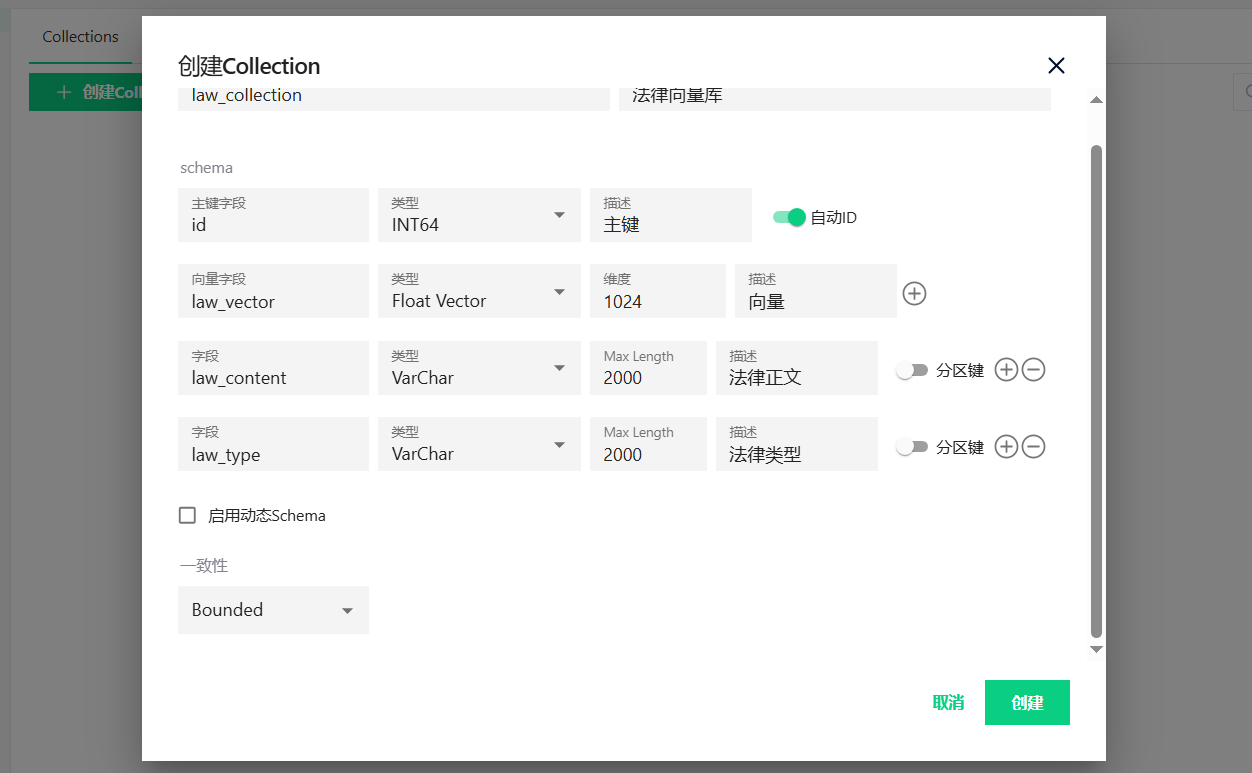
给需要检索的字段增加索引
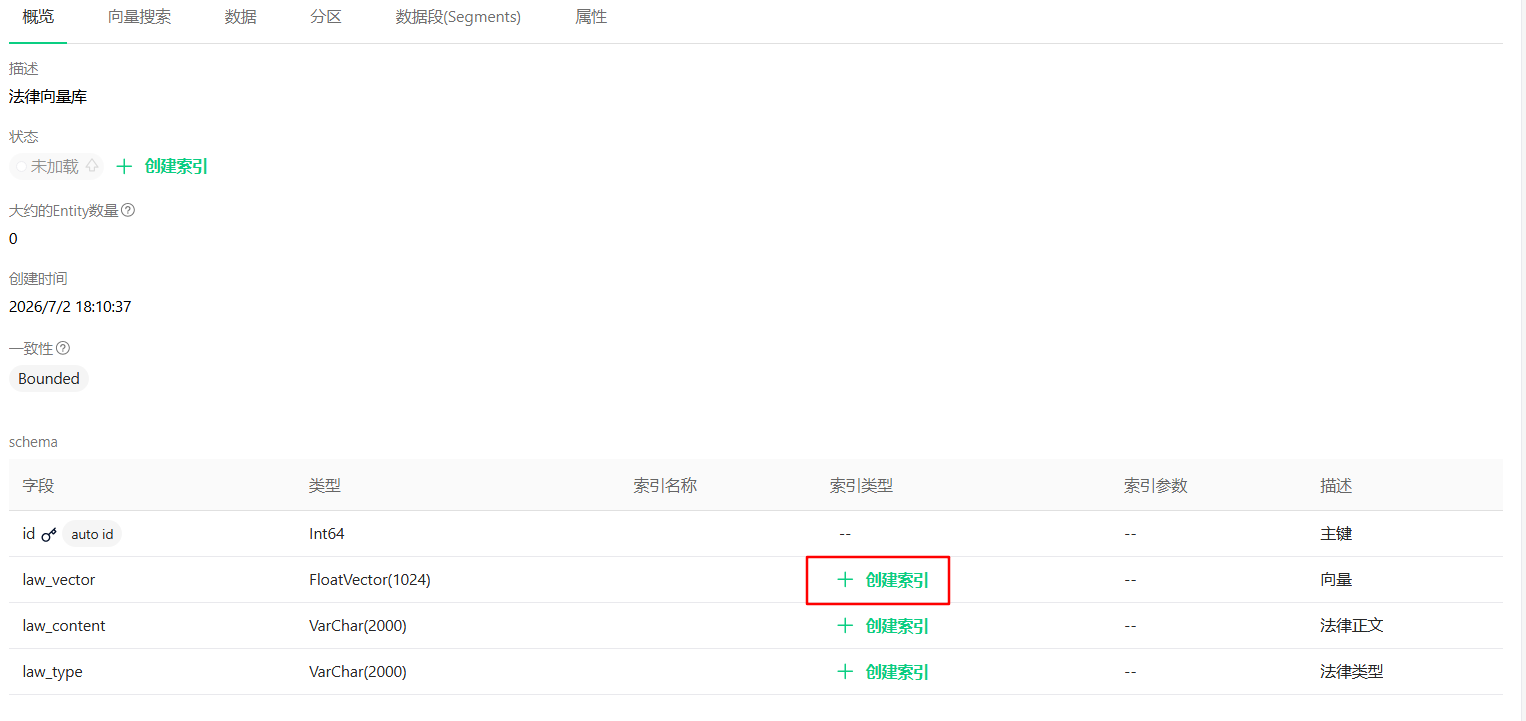
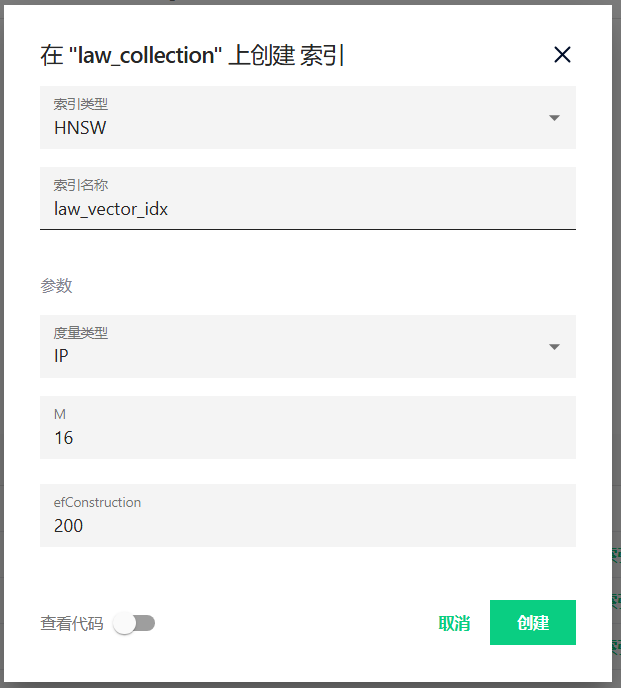
创建完后点击状态处的字样加载到内存,只有被加载到内存中的集合才可以被检索
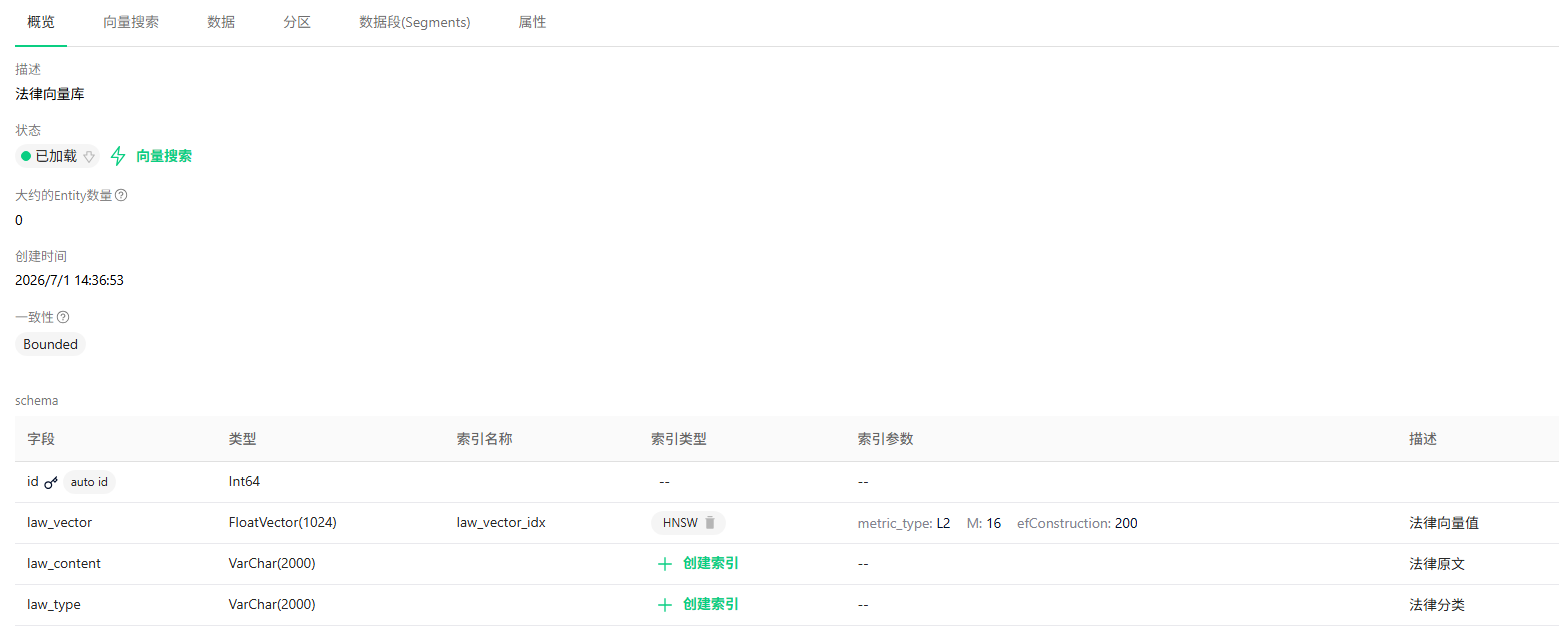
接着我们导入数据,导入数据分为页面导入和接口导入
页面导入数据
页面导入的数据为json格式,字段和我们创建字段保持一致即可,可以先从网站上下载模板,再填入数据

然后上传该json文件,刷新便可看见
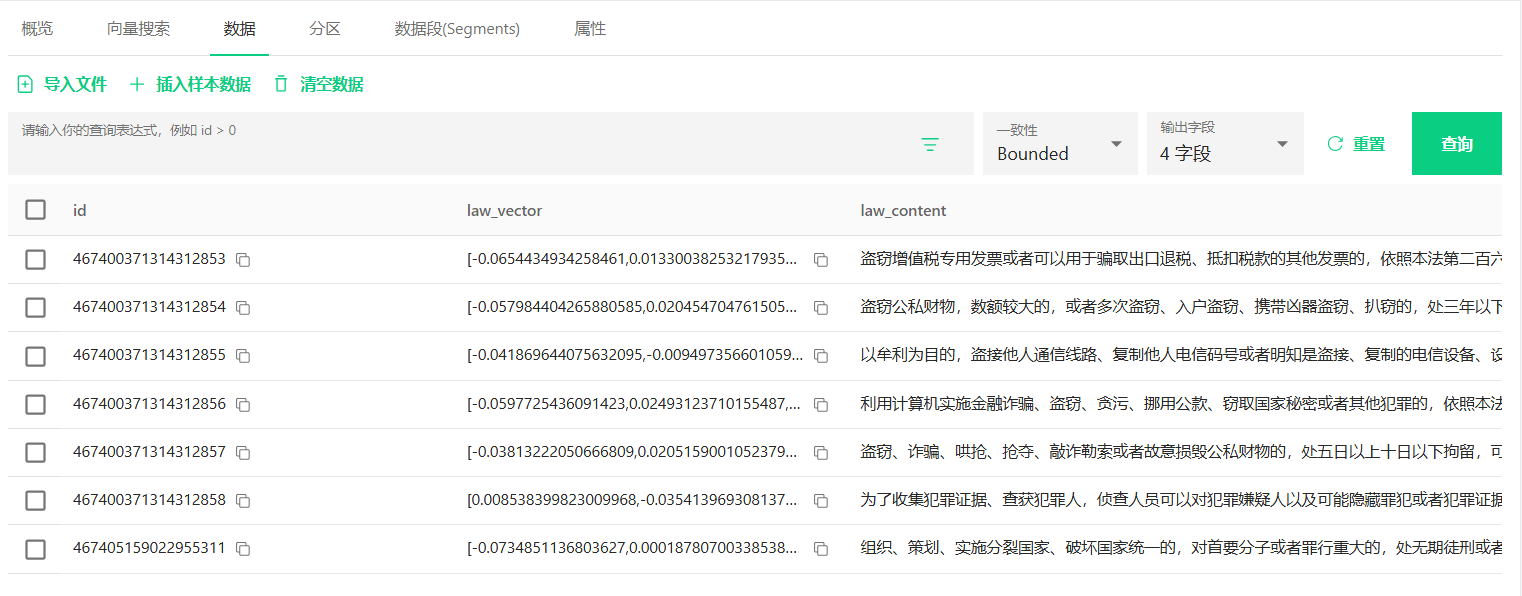
接口插入数据
也可以通过接口http://IP地址:19530/v2/vectordb/entities/insert插入数据,请求体如下。其中collectionName为集合名称,data中字段和和我们创建字段保持一致
bash
{
"collectionName":"xxxxx",
"data":[
{
"law_content":"xxxxx",
"law_type":"xxxxxx",
"law_vector":[]
}
]
}插入成功将返回ids
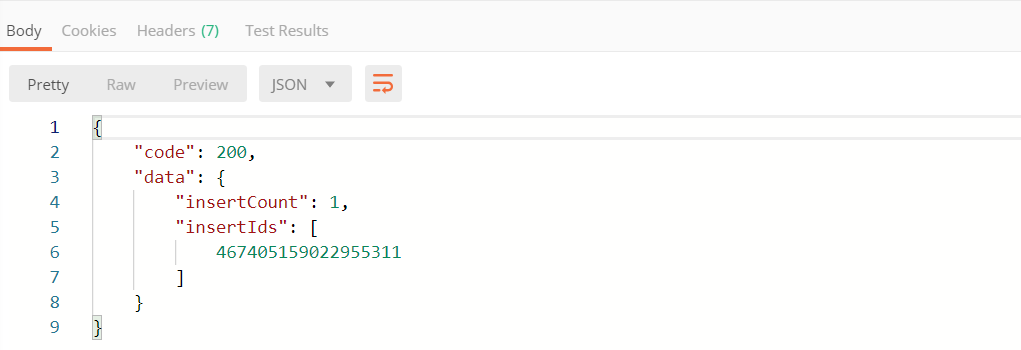
4.2 数据检索
插入完成数据后,便可进行数据相似度检索
例如,我这边先利用Embedding模型生成有关于计算机犯罪的向量,理论上应该可以检索出相关的犯罪法律条文。
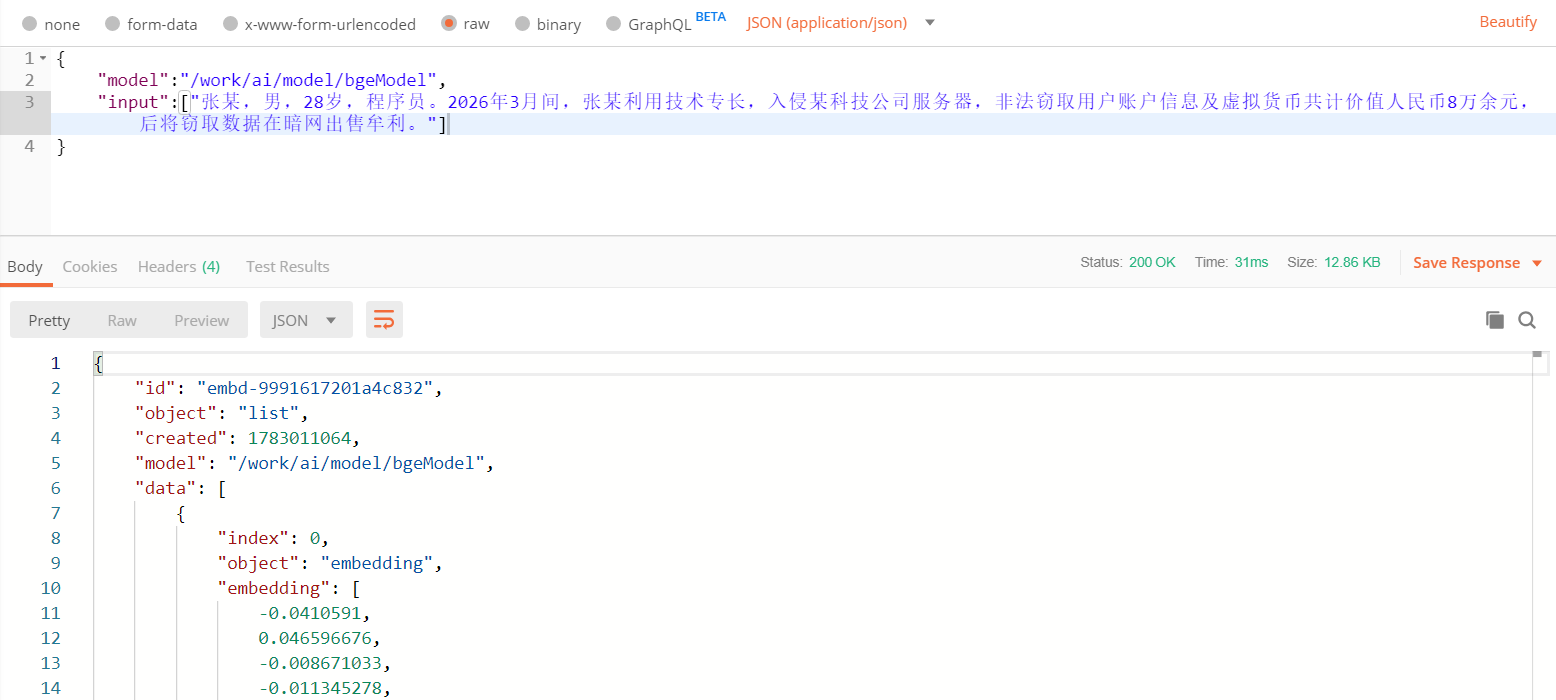
调用接口http://IP地址:19530/v2/vectordb/entities/search进行检索,其中请求体如下。collectionName为集合名称,data为转换需要检索的向量值,annsField表示向量值映射的字段,limit表示展示最匹配的前几条数据,outputFields表示结果需要展示的字段
bash
{
"collectionName":"law_collection",
"data":[[xxx]] ,
"annsField":"law_vector",
"limit":3,
"outputFields":["id","law_content","law_type"]
}最终检索的效果如下,还是蛮准确的。至此,私有化法律RAG系统100%落地完成,后面就是对接业务
