RTX 5090 本地部署 Qwen3-Coder-30B-A3B 实测:90 Tokens/s,128K 上下文,仅占用 22.4GB 显存
最近体验了一下 Qwen3-Coder-30B-A3B-Instruct 的 GGUF 版本,在 RTX 5090 D V2(24GB) 上使用 llama.cpp 进行部署,整体效果超出预期。
最终实测:90 Tokens/s,128K Context,显存占用约22.4GB。
下面分享一下部署命令、参数解析以及实际测试结果。
一、测试环境
| 配置 | 参数 |
|---|---|
| GPU | NVIDIA GeForce RTX 5090 D V2 24GB |
| CUDA | 13.2 |
| Driver | 595.71.05 |
| 推理框架 | llama.cpp(llama-server) |
| 模型 | Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf |
| 上下文长度 | 128K |
| KV Cache | Q8_0 |
| 部署方式 | llama-server OpenAI API |
二、启动命令
bash
./build/bin/llama-server \
-m ~/work/models/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf \
--host 0.0.0.0 \
--port 8080 \
-c 128000 \
--alias "qwen3coder" \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--kv-unified \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
-np 1三、参数解析
下面对命令中的主要参数逐一说明。
1)模型路径
bash
-m ~/work/models/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf指定加载的 GGUF 模型。
这里使用的是:
Qwen3-Coder-30B-A3B-Instruct-Q4_K_M
属于 Q4_K_M 量化版本。
特点:
- 模型体积较小
- 推理速度快
- 精度保持较好
- 非常适合 24GB 显卡部署
2)监听地址
bash
--host 0.0.0.0允许局域网访问。
如果只允许本机访问,可以写:
bash
127.0.0.13)端口
bash
--port 8080API 地址变成:
http://IP:8080可直接兼容 OpenAI API。
4)上下文长度
bash
-c 128000表示:
Context = 128K Token
这是本次测试最大的亮点之一。
对于:
- 大型代码仓库
- 长文档分析
- RAG
- 多文件推理
都十分友好。
5)模型别名
bash
--alias "qwen3coder"客户端调用时:
json
{
"model":"qwen3coder"
}无需填写模型文件名。
6)Temperature
bash
--temp 0.6控制回答随机性。
数值越低:
- 更稳定
- 更适合代码生成
一般推荐:
代码:
0.2~0.6聊天:
0.7~1.07)Top-p
bash
--top-p 0.95控制采样范围。
常用值:
0.9
0.95
1.08)Top-k
bash
--top-k 20限制每一步只从前20个概率最高的 Token 中采样。
优点:
- 输出更稳定
- 减少胡言乱语
- 更适合代码模型
9)统一 KV Cache
bash
--kv-unified启用统一 KV Cache 管理。
优点:
- 减少碎片
- 更省显存
- 长上下文更加稳定
10)KV Cache 精度
bash
--cache-type-k q8_0
--cache-type-v q8_0将 Key、Value Cache 都量化为 Q8_0。
相比 FP16:
优点:
- 显存占用明显降低
- 推理速度更快
- 精度损失很小
对于 128K 长上下文来说,Q8_0 是一个兼顾性能与质量的选择。
11)并发数
bash
-np 1表示:
仅允许一个推理请求。
如果部署 API 服务,可根据硬件资源适当调大,但需要注意并发越高,对显存和吞吐的要求也越高。
四、性能测试
本次采用 Web UI 连续生成代码进行测试。
实际速度:
约 90 Tokens/s
下面是实际截图:
生成速度
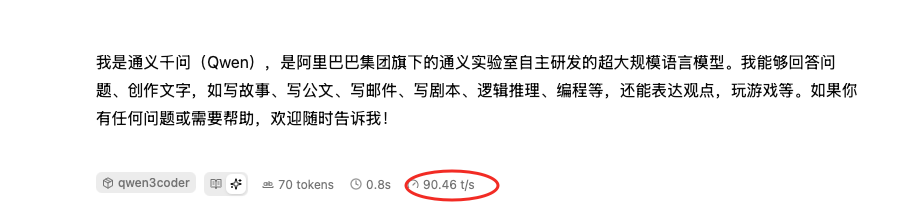
可以看到页面右下角显示:
90.46 t/s
这一速度对于 30B 级别模型来说表现十分优秀,日常代码补全、问答、生成文档都非常流畅。
五、GPU 占用
运行期间查看:
bash
nvidia-smi结果如下。
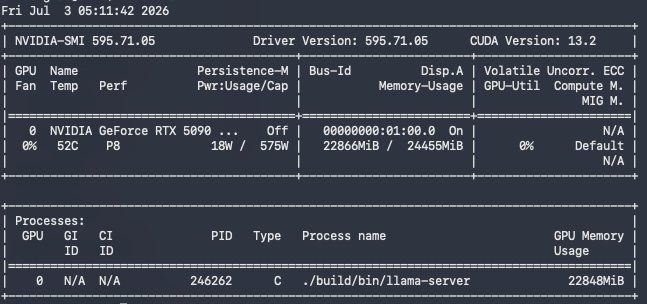
从监控结果可以看到:
GPU:
RTX 5090 D V2显存:
22866 MiB / 24555 MiB约:
22.4GB
GPU 温度:
52℃功耗:
18W(截图采样时)可以看到,24GB 显存基本可以完整承载该模型,同时支持 128K 上下文运行。显存利用率较高,但仍保留少量余量,整体运行稳定。
六、实际体验
连续体验几个小时后,总体感受如下。
优点:
- 推理速度快,约 90 Tokens/s。
- 128K 超长上下文,对代码仓库分析和 RAG 场景非常友好。
- Q4_K_M 量化在速度与效果之间取得了不错的平衡。
- llama.cpp 部署简单,兼容 OpenAI API,方便接入 Cherry Studio、Open WebUI、VS Code 等客户端。
需要注意:
- 128K 上下文会显著增加 KV Cache 占用,因此建议使用 Q8_0 或其他量化 KV Cache,以降低显存压力。
- 24GB 显存几乎被充分利用,如果还需要多并发服务或加载更高精度模型,则建议选择更大显存的显卡。
七、总结
整体来看,Qwen3-Coder-30B-A3B-Instruct-Q4_K_M + llama.cpp + RTX 5090 D V2 的组合,在单卡环境下表现相当出色。
本次测试结果如下:
| 项目 | 测试结果 |
|---|---|
| 模型 | Qwen3-Coder-30B-A3B-Instruct-Q4_K_M |
| 推理框架 | llama.cpp(llama-server) |
| 显卡 | RTX 5090 D V2 24GB |
| 上下文 | 128K |
| KV Cache | Q8_0 |
| 实测速度 | 90.46 Tokens/s |
| 显存占用 | 22.4GB |
| API | OpenAI Compatible |
对于开发者来说,这一配置已经能够胜任代码生成、项目分析、知识库问答以及日常 AI 编程助手等任务。如果你的目标是在单卡 24GB 显存上获得较长上下文和较高推理速度,这套方案值得尝试。
八、不足点:不支持图像识别
需要注意的是,这个模型本身是 纯文本 / 代码模型,不支持多模态图像输入。
实际调用图片分析时会报错:
text
Error analyzing image batch_amazon_photos/item_0/IMG_20260106_082824.jpg:
Error code: 500 - {
'error': {
'code': 500,
'message': 'image input is not supported - hint: if this is unexpected, you may need to provide the mmproj',
'type': 'server_error'
}
}报错核心信息是:
text
image input is not supported也就是说,当前加载的:
text
Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf并不是视觉语言模型,无法直接处理图片、截图、商品照片、OCR 或视觉问答任务。
如果需要图像识别能力,需要换用支持多模态的模型,并额外配置对应的 mmproj 文件;否则建议把图片先通过 OCR / 图像识别工具转成文本,再交给该模型进行分析。
因此,本次部署更适合:
- 代码生成
- 长文本问答
- 本地知识库
- 文档总结
- API 调用
- 128K 长上下文推理
但不适合直接做图片理解、商品图片分析或视觉问答。
Qwopus3.6-27B-Coder 虽然支持搭配 mmproj 做图像输入,但纯文本 128K 下实测约 15 tokens/s;加入 mmproj 后约 8 tokens/s。相比 Qwen3-Coder-30B-A3B 的 90 tokens/s,主要差异来自模型结构:A3B MoE 每次只激活较少参数,而 27B dense 类模型推理负载更高。因此如果优先追求本地代码推理速度,Qwen3-Coder-30B-A3B 更合适;如果需要图像输入能力,则需要接受明显更低的吞吐。