📖标题:P-MTP: Efficient Document Parsing via Multi-Token Prediction with Progressive Depth Scaling
🌐来源:arXiv, 2606.24447v1
🛎️文章简介
🔸研究问题:如何解决视觉语言模型在文档解析任务中因自回归解码导致的推理延迟高及多令牌预测深层优化不稳定的问题?
🔸主要贡献:论文提出P-MTP框架,通过渐进课程损失和置信度门控动态起草机制,实现文档解析高达5倍加速且精度无损。
📝重点思路
🔸采用轻量级串行共享MLP作为多令牌预测模块,在单次前向传播中循环生成多个前瞻令牌,平衡了建模能力与计算开销。
🔸设计渐进课程损失用于训练,包含序列路径约束和回溯目标约束,根据累积概率自适应加权,抑制远距离预测的梯度噪声。
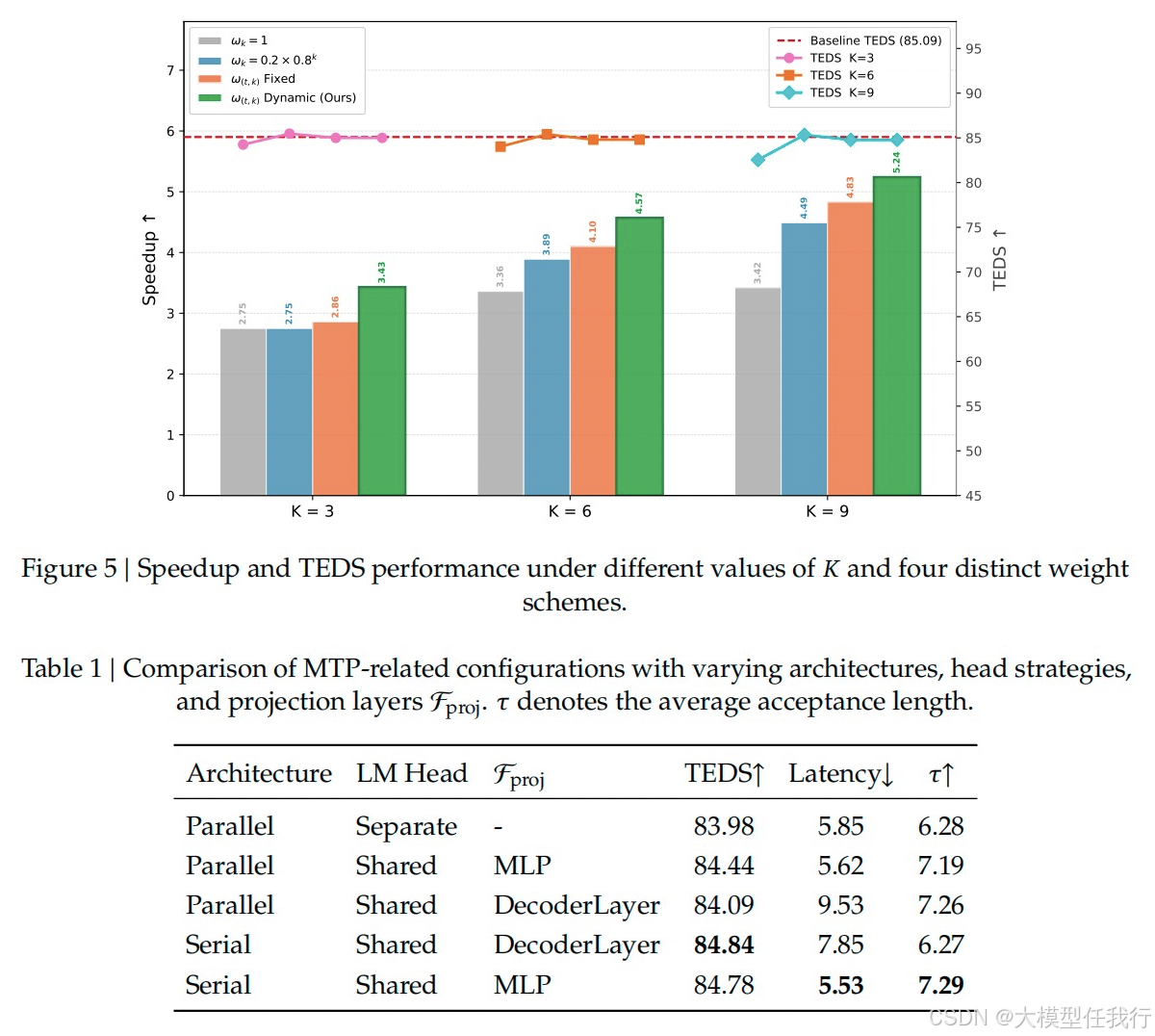
🔸利用上述动态权重机制实现从易到难的自动优化过渡,使模型能稳定扩展至9层甚至更深的预测深度,避免传统静态权重的局限。
🔸提出置信度门控动态起草策略用于推理,依据实时累积联合概率自适应调整起草长度,在高确信度时延长预测,低确信度时及时截断。
🔸建立可靠性感知的阈值校准方法,将推理置信度阈值与训练终端损失及预测深度关联,确保推理行为与训练时的课程学习动态一致。
🔎分析总结
🔸在PubTabNet等基准测试中,P-MTP在保持TEDS分数与基线持平的情况下,实现了最高5.24倍的推理加速,验证了深层前瞻预测的有效性。
🔸消融实验表明,动态权重策略显著优于固定权重或静态衰减权重,且序列约束与回溯约束的协同作用是提升接受率和加速比的关键。
🔸相比固定深度起草,置信度门控动态起草在不同预测深度下均提升了平均接受长度,有效减少了无效计算,进一步推高了吞吐量。
🔸该方法具有良好的通用性与扩展性,在InternVL、Qwen3-VL等不同基座模型及公式、表格、通用文档解析任务上均取得显著加速效果。
🔸模型规模缩放实验显示,随着参数量增加,方法的平均接受长度单调上升,证明大模型更强的长程依赖捕获能力有利于多令牌预测。
💡个人观点
论文不同于以往依赖静态权重的做法,设计了轨迹感知的动态损失权重,将训练时的课程学习思想延伸至推理阶段,通过置信度门控实现了"按需预测"。