告警太多,不代表系统更安全。很多值班同学都遇到过:半夜手机响,打开一看几十条告警,CPU、接口超时、队列积压、错误率上涨全挤在一起。你知道有问题,但不知道哪个最重要。最后只能先重启服务、再看日志、再问开发有没有发布。处理完已经天亮了。
现在有人搜"Claude Code 日志分析""AI 运维告警""DevOps Runbook 自动生成""Codex 排查脚本",说明一个趋势很明显:大家不是想让 AI 直接接管生产,而是想让值班排查不再靠经验硬撑。AI 编程工具适合做的,是把告警、日志、发布记录和排查动作整理成可复用流程。
告警要先分组,不要逐条看
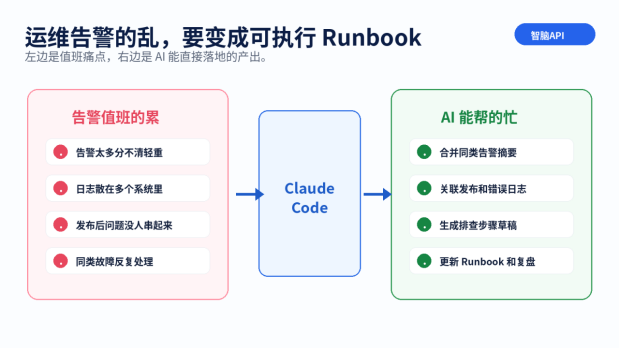
告警系统最容易犯的错,是把每一条都当成独立事件。实际上很多告警是同一个根因的连锁反应。比如数据库慢导致接口超时,接口超时导致错误率上涨,错误率上涨又触发用户侧告警。值班同学如果逐条处理,会被噪音拖死。
Claude Code 可以先做告警摘要。你把告警列表、时间窗口、服务名、最近发布记录给它,让它按照服务、时间、错误类型、影响范围分组,输出可能的主线。它不能替你确认事故,但能帮你从一堆碎片里看出"可能是同一波问题"。
日志归因要和发布记录放一起看
线上故障很多跟发布有关,但不是所有发布都直接出问题。关键是要看时间线:什么时候发布,什么时候错误率开始涨,哪些接口先出问题,哪些服务同时报警。人手工拼这个时间线很累,AI 可以帮你整理。
你可以让它根据日志片段和发布记录生成时间线:10:02 发布订单服务,10:07 支付回调错误率上涨,10:09 队列积压,10:12 用户反馈付款后状态未更新。这样一看,排查方向就比"系统挂了"清楚很多。
不要让 AI 直接动生产
这点必须强调。DevOps 场景里,AI 可以分析日志、生成排查步骤、写脚本草稿、整理 Runbook,但不应该在没有审核的情况下直接执行危险操作。比如删库、重启核心服务、扩容、改防火墙、清缓存,这些都需要人确认。
正确做法是让 AI 输出建议命令和风险说明。比如"建议先查询队列积压情况,不建议直接清空队列,因为可能丢消息"。有些命令可以在测试环境验证,有些只作为人工操作参考。生产环境的按钮,必须在人手里。
Runbook 才是长期收益
一次故障处理完,如果没有沉淀,下次还会从头来。Runbook 就是把经验写成步骤:现象是什么,先看什么指标,查哪些日志,常见原因有哪些,哪些操作危险,什么时候升级给谁。AI 可以在复盘后帮你把这些内容整理成文档。
很多团队的 Runbook 最初都很粗糙,没关系。先写出第一版,后面每次故障后更新。AI 的价值是降低维护成本,让值班经验不要只留在某个老员工脑子里。
适合哪些场景
这套工作流适合接口错误率告警、队列积压、定时任务失败、数据库慢查询、发布后异常、批处理脚本失败、第三方服务超时等场景。尤其适合中小团队,运维和开发不是完全分开的,很多时候一个人要看业务、日志、脚本和发布。
不适合直接交给 AI 的是高危生产操作。AI 生成的命令必须经过人确认。你可以用它当排查助手,不要把它当无人值守运维。
智脑API 怎么接入这类流程
运维排查对稳定入口要求很高。半夜出问题时,如果每个人的工具配置都不一样,很容易更乱。把 Claude Code、Codex 接入智脑API后,可以统一团队的 AI 编程工具入口,把"告警摘要、日志归因、Runbook 更新、复盘草稿"做成固定流程。配置教程在这里:https://my.feishu.cn/wiki/NIgLwuuj1ibzJIkLGM0cgVNinzg。
一个实用提示词
请根据以下告警、日志片段和最近发布记录,整理一条故障时间线。不要给出高危操作命令。请输出:影响范围、可能根因、需要继续确认的信息、建议的低风险排查步骤、需要升级给谁、事后 Runbook 应该补充哪些内容。
这个提示词把边界写得很清楚:分析可以,危险操作不行。这样用起来更稳。
告警阈值也要定期复盘
很多告警一开始有用,后来业务量变了、架构变了,阈值却没变。结果要么误报太多,要么真正出问题时没响。AI 可以帮你根据历史告警和处理记录,整理哪些告警经常无动作关闭,哪些告警总是和真实故障有关。这个分析能帮助团队调阈值,而不是靠感觉关闭告警。
另外,日志分析时要注意隐私和安全。给 AI 的日志最好脱敏,尤其是手机号、邮箱、token、订单号、用户地址、支付信息。排查效率很重要,但不能为了方便把敏感信息到处复制。把脱敏规则写进 Runbook,长期会更稳。
值班交接也可以流程化。上一班处理了什么、还有哪些告警未确认、哪些服务需要继续观察、哪些客户反馈还没关闭,这些信息最好不要只靠口头交代。让 AI 根据聊天记录和处理记录整理交接摘要,再由值班人确认,会比临时翻群消息靠谱得多。
如果团队有多个环境,也可以让 AI 帮你区分"测试环境噪音"和"生产环境风险"。同样的报错,在测试环境可能只是有人压测,在生产环境就可能是客户真实受影响。把环境、服务、时间、影响范围放在同一张摘要里,值班人判断会快很多。
最后说句实话
告警太多,团队就会麻木。真正可靠的值班体系,不是把手机响得更勤,而是让每次响都有线索、有优先级、有处理步骤、有复盘沉淀。Claude Code 能帮你做的是整理、归因和沉淀。把这些动作固定下来,值班不会轻松到没压力,但至少不会每次都像第一次遇到问题。