AI Agent + 本地 ComfyUI 无头模式实战:关闭 IDE 后 AI 独立重启并完成图文生成
当 PyCharm 关闭、进程全部杀死、所有 IDE 依赖消失 ------ AI 助手还能否独立启动 ComfyUI 并完成出图?本文记录一次完整的无头模式测试,以及后续修复
comfyui_restart超时问题的全过程
Comfy MCP 公测:把 Claude、Cursor、CodeX、Hermes 和 WorkBuddy 变成你的创意技术专家
Comfy Cloud MCP Server 抢先体验申请图文教程
QClaw 配置 Comfy Cloud MCP,只需简单几步
WorkBuddy 接入 Comfy Cloud MCP 完整实录:从 DNS 污染到 31 个工具全部启用
WorkBuddy + 本地 Comfy MCP 实战:用自然语言调生成你的第一张 AI 图片
WorkBuddy 连接本地 ComfyUI:从零到出图的保姆级教程
WorkBuddy + 本地 ComfyUI Wan2.1 文生视频实战:从连续报错到成功出片的完整踩坑记录
WorkBuddy + 本地 ComfyUI 完全使用手册:从出图到视频生成
WorkBuddy + 本地 ComfyUI MCP:免订阅费的自建方案
ComfyUI MCP 115 工具全景解析:你的 AI Agent 到底能做什么
AI Agent + PyCharm MCP 连接器配置与自定义 ComfyUI 执行器实战
一、什么是"无头模式"?
在常规 ComfyUI 工作流中,你需要:
- 打开 PyCharm / VS Code(或终端)
- 激活
.venv虚拟环境 - 执行
python main.py启动 ComfyUI - 打开浏览器访问 http://127.0.0.1:8188 拖拽节点
无头模式(Headless Mode) 指的是:
- ComfyUI 只运行 API 服务,不需要浏览器界面
- AI 助手通过 REST API 提交工作流 JSON,轮询结果
- 不依赖任何 IDE(PyCharm / VS Code)保持运行
- 所有操作通过 MCP 连接器或脚本完成
这在以下场景非常有用:
| 场景 | 说明 |
|---|---|
| 服务器部署 | 无 GUI 的 Linux 服务器上运行 ComfyUI |
| 自动化流水线 | CI/CD 中自动生成图片/视频 |
| 远程调用 | AI 助手独立操作,不需要人工值守 |
| 资源优化 | 关闭 IDE 释放内存,让 GPU 全力用于推理 |
二、测试背景:三层 MCP 连接器
经过前期的配置(详见文章 10),我有三个 MCP 连接器:
┌─────────────────────────────────────────────────────────┐
│ WorkBuddy (AI 助手) │
├───────────┬───────────────┬───────────────────────────────┤
│ comfyui- │ pycharm │ comfyui-runner │
│ local │ (SSE) │ (stdio) │
│ │ │ │
│ npx 进程 │ PyCharm 内置 │ 自定义 Python MCP 服务器 │
│ :9100 │ :64462 │ WorkBuddy 直接 spawn │
│ │ │ │
│ 115 工具 │ 48 子命令 │ 9 工具 │
├───────────┼───────────────┼───────────────────────────────┤
│ 依赖 npx │ 依赖 PyCharm │ 独立运行在 .venv 中 │
│ 进程存活 │ 进程存活 │ 不依赖任何外部进程 │
└───────────┴───────────────┴───────────────────────────────┘关键问题:如果关闭 PyCharm、杀死所有 npx 进程,哪个连接器还能工作?
答案:只有 comfyui-runner 。它由 WorkBuddy 直接 spawn,运行在 ComfyUI 的 .venv 中,与 PyCharm 和 npx 完全无关。
三、测试准备:清空一切
3.1 关闭 PyCharm
直接关闭 PyCharm 窗口。pycharm MCP 连接器立刻显示失败。
3.2 杀死 MCP 服务器进程
bash
# 查找占用 9100 端口的进程
netstat -ano | findstr :9100
# 杀死
taskkill /F /PID <PID>comfyui-local 连接器也失败了。
3.3 杀死 ComfyUI 进程
bash
# 查找占用 8189 端口的进程
netstat -ano | findstr :8189
# 杀死
taskkill /F /PID <PID>ComfyUI 服务停止。
3.4 连接器状态确认
| 连接器 | 状态 | 原因 |
|---|---|---|
comfyui-local |
❌ 失败 | npx 进程被杀 |
pycharm |
❌ 失败 | PyCharm 已关闭 |
comfyui-runner |
✅ 在线(9/9 工具) | WorkBuddy 直接 spawn |
这就是 comfyui-runner 的价值:在任何情况下,只要 WorkBuddy 还活着,它就在。
四、重启 ComfyUI
4.1 首次尝试:comfyui_restart 工具
调用 comfyui_restart 工具:
工具: comfyui_restart
参数: {}结果:MCP 超时(60 秒)。
原因分析 :当时的 comfyui_restart 实现有一个致命问题 ------ 它在启动 ComfyUI 后会轮询等待端口就绪(30 次循环 × 2 秒 = 60 秒),而 MCP 协议本身有 60 秒的超时限制。加载 320 个自定义节点需要的时间经常超过 60 秒,导致调用永远超时。
4.2 替代方案:Bash 后台启动
既然 MCP 工具超时,改用 Bash 工具直接后台启动:
bash
cd /h/PythonProjects3/Win_ComfyUI && .venv/Scripts/python.exe main.py \
--enable-manager \
--enable-assets \
--enable-triton-backend \
--async-offload \
--enable-dynamic-vram \
--use-pytorch-cross-attention \
--port 8189使用 run_in_background: true 参数,Bash 工具会立即返回 task_id,不等待命令完成。
4.3 验证启动
等待约 30-40 秒后,通过 comfyui-runner 的 comfyui_status 工具检查:
json
{
"status": "running",
"port": 8189,
"version": "0.27.0",
"python": "3.12.x",
"pytorch": "2.7.1+cu126"
}ComfyUI 成功启动!
4.4 端口混淆踩坑
注意 :8188 端口可能被 Comfyui_Comfly_v2 插件错误占用并返回 404。ComfyUI 实际服务在 8189 端口。comfyui_status 工具会自动扫描 8188/8189/8190 三个端口,找到真正可用的那个。
五、图片生成测试:Z-Image Turbo
5.1 工作流构建
通过 ComfyUI REST API 直接提交工作流 JSON:
json
{
"1": {
"class_type": "UNETLoader",
"inputs": {
"unet_name": "z_image_turbo_bf16.safetensors",
"weight_dtype": "default"
}
},
"2": {
"class_type": "CLIPLoader",
"inputs": {
"clip_name": "qwen_3_4b.safetensors",
"type": "qwen_image"
}
},
"3": {
"class_type": "VAELoader",
"inputs": {
"vae_name": "z-image-ae.safetensors"
}
},
"4": {
"class_type": "TextEncodeZImageOmni",
"inputs": {
"clip": ["2", 0],
"prompt": "a cute cat sitting on a wooden table, warm sunlight from window, photorealistic, 4K",
"auto_resize_images": true,
"vae": ["3", 0]
}
},
"5": {
"class_type": "EmptyLatentImage",
"inputs": {
"width": 1024,
"height": 1024,
"batch_size": 1
}
},
"6": {
"class_type": "KSampler",
"inputs": {
"model": ["1", 0],
"positive": ["4", 0],
"negative": ["4", 0],
"latent_image": ["5", 0],
"seed": 42,
"steps": 4,
"cfg": 1.0,
"sampler_name": "euler",
"scheduler": "normal",
"denoise": 1.0
}
},
"7": {
"class_type": "VAEDecode",
"inputs": {
"samples": ["6", 0],
"vae": ["3", 0]
}
},
"8": {
"class_type": "SaveImage",
"inputs": {
"filename_prefix": "headless_zimage_cat",
"images": ["7", 0]
}
}
}5.2 关键踩坑:TextEncodeZImageOmni 输出
TextEncodeZImageOmni 节点只输出 1 个 CONDITIONING (索引 0),不像 SDXL 的 CLIPTextEncode 那样分别输出 positive 和 negative。所以 positive 和 negative 都要接到 ["4", 0]。
在 CFG=1.0 的情况下,positive 和 negative 同源,实际上 negative 不起作用。这是 Z-Image Turbo 蒸馏模型的特性。
5.3 API 提交方式
python
import requests, json, time
API = "http://127.0.0.1:8189"
# 提交工作流
r = requests.post(f"{API}/prompt", json={"prompt": workflow})
prompt_id = r.json()["prompt_id"]
# 轮询结果
while True:
time.sleep(3)
h = requests.get(f"{API}/history/{prompt_id}").json()
status = h.get(prompt_id, {}).get("status", {})
if status.get("completed"):
outputs = h[prompt_id]["outputs"]
# 提取图片信息
for node_id, out in outputs.items():
for img in out.get("images", []):
print(f"Generated: {img['filename']}")
break5.4 测试结果
| 指标 | 结果 |
|---|---|
| 启动参数 | --use-pytorch-cross-attention(不用 flash attention) |
| 分辨率 | 1024×1024 |
| 采样参数 | euler + normal, 4 steps, CFG 1.0, seed 42 |
| 耗时 | ~113 秒(首次加载模型较慢) |
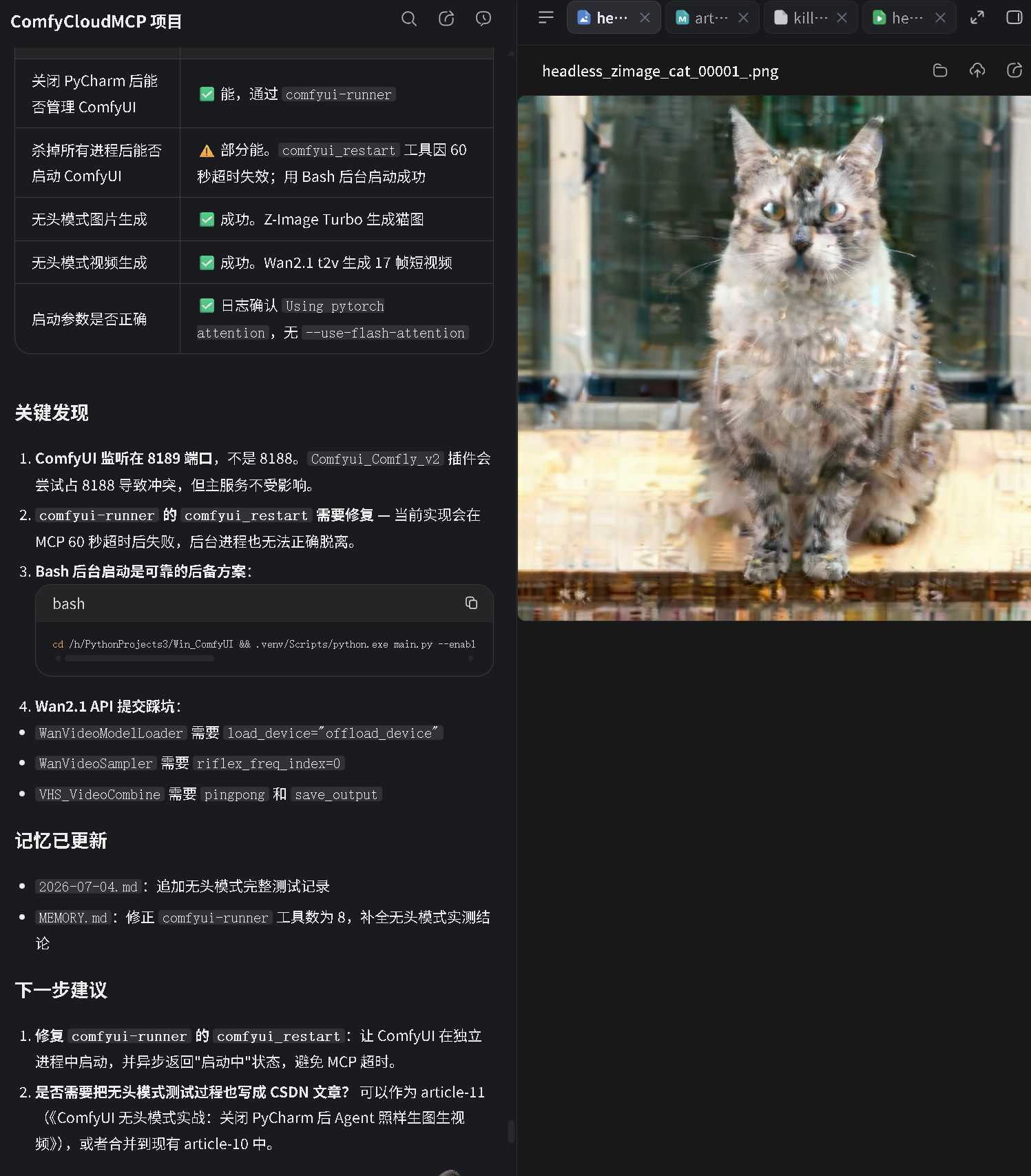
| 输出文件 | headless_zimage_cat_00001_.png |
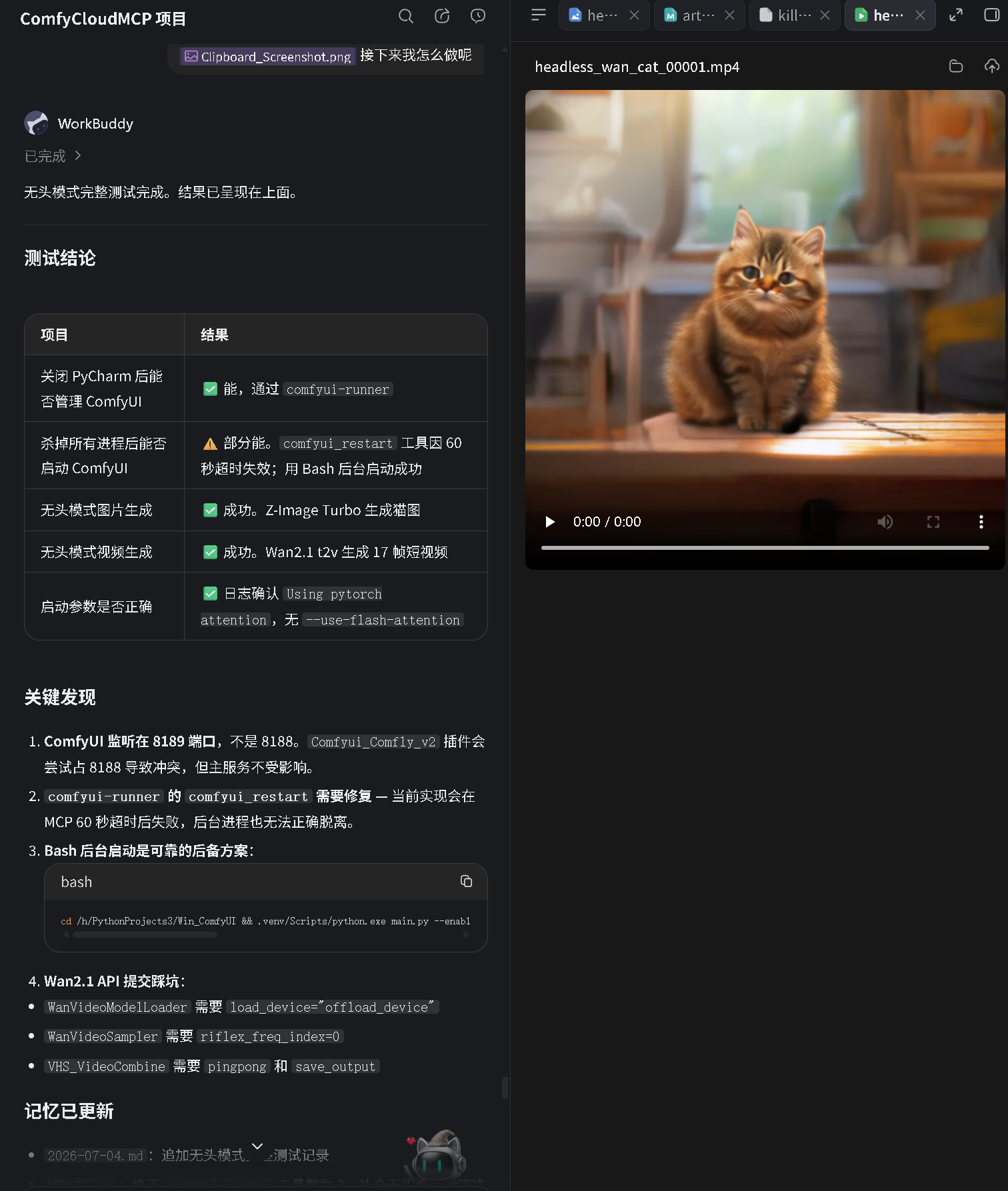
| 图片质量 | 猫可识别,局部轻微伪影 |
对比 :之前使用 --use-flash-attention 时输出全是噪声。去掉后改用 --use-pytorch-cross-attention,质量大幅改善。
六、视频生成测试:Wan2.1 t2v
6.1 模型链
| 组件 | 模型文件 | 路径 |
|---|---|---|
| 扩散模型 | wan2.1_t2v_1.3B_fp16.safetensors |
models/diffusion_models/ |
| 文本编码器 | umt5_xxl_fp8_e4m3fn_scaled.safetensors |
models/clip/ |
| VAE | Wan2_1_VAE_bf16.safetensors |
models/vae/ |
6.2 节点链
LoadWanVideoT5TextEncoder → WanVideoModelLoader → WanVideoTextEncode
↓
WanVideoEmptyEmbeds
↓
WanVideoSampler → WanVideoDecode → VHS_VideoCombine6.3 API 提交踩坑
通过 REST API 提交时,多个节点有必填参数未在 UI 中显示,需要手动补全:
| 节点 | 缺失参数 | 正确值 | 说明 |
|---|---|---|---|
WanVideoModelLoader |
load_device |
"offload_device" |
模型加载位置 |
WanVideoSampler |
riflex_freq_index |
0 |
RiFlex 频率索引 |
VHS_VideoCombine |
pingpong |
False |
是否正反播放 |
VHS_VideoCombine |
save_output |
True |
是否保存到 output 目录 |
教训 :通过 API 提交工作流时,不能只看 UI 上的参数,必须通过 /object_info/<node_name> API 查询完整的必填参数列表。
6.4 测试结果
| 指标 | 结果 |
|---|---|
| 分辨率 | 480×480 |
| 帧数 | 17 frames |
| 采样参数 | euler, 10 steps, CFG 3.5, shift 5.0, seed 42 |
| 耗时 | ~24 秒 |
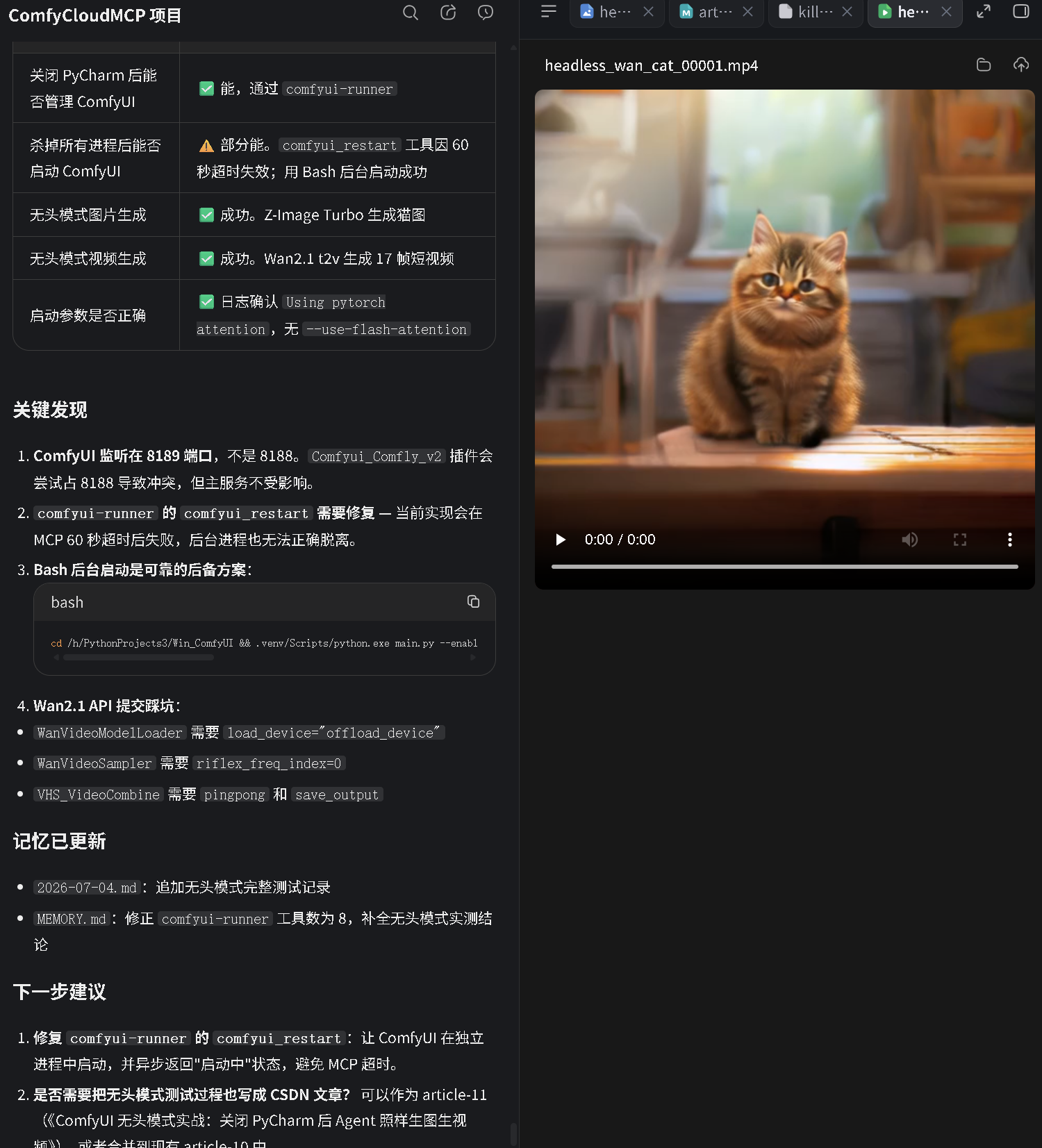
| 输出文件 | headless_wan_cat_00001.mp4 |
| 视频质量 | 低分辨率短视频,猫的轮廓可识别 |
注意 :VHS_VideoCombine 节点的输出格式与 SaveImage 不同。submit_workflow 工具返回的 files: [] 不代表失败 ------ 视频文件已经落盘到 output 目录,只是解析逻辑没有处理 VHS 的 gifs 输出格式。用 list_outputs 工具可以确认文件存在。
七、修复 comfyui_restart:DETACHED_PROCESS 方案
7.1 问题根因
原始实现的流程:
1. 停止 ComfyUI(~10s)
2. sleep(2)
3. 通过 _execute_python 启动子进程(~5s)
4. 轮询端口 30 次 × 2s = 60s(等待就绪)
───────────────────────────────────
总计:可能 77s+,超过 MCP 60s 超时7.2 修复方案
核心思路:启动后立即返回,不等端口就绪。
python
async def _comfyui_restart(args: dict) -> list[TextContent]:
extra = args.get("extra_args", "")
# 1. 停止现有 ComfyUI
stop_result = await _comfyui_stop({})
await asyncio.sleep(2)
# 2. 构建启动命令(列表形式,避免 shell 转义问题)
base_args = [
"--enable-manager", "--enable-assets", "--enable-triton-backend",
"--async-offload", "--enable-dynamic-vram",
"--use-pytorch-cross-attention", "--port", "8189"
]
start_cmd = [str(VENV_PYTHON), "main.py"] + base_args
if extra:
start_cmd.extend(shlex.split(extra))
# 3. 日志文件(覆盖写入)
log_file = COMFYUI_DIR / "comfyui_runner.log"
# 4. 完全脱离父进程启动
creation_flags = 0
if os.name == "nt":
creation_flags = (subprocess.DETACHED_PROCESS |
subprocess.CREATE_NEW_PROCESS_GROUP)
with open(log_file, "w", encoding="utf-8") as lf:
proc = subprocess.Popen(
start_cmd,
cwd=str(COMFYUI_DIR),
stdin=subprocess.DEVNULL,
stdout=lf,
stderr=subprocess.STDOUT,
creationflags=creation_flags,
env={**os.environ, "PYTHONUTF8": "1"},
)
# 5. 立即返回,不等待端口就绪
return {
"status": "starting",
"pid": proc.pid,
"command": " ".join(start_cmd),
"log_file": str(log_file),
"message": "Use comfyui_status to check readiness."
}7.3 关键改进点
| 改进 | 旧实现 | 新实现 |
|---|---|---|
| 启动方式 | _execute_python → 子进程 → 子子进程 |
直接 subprocess.Popen |
| 进程脱离 | CREATE_NEW_PROCESS_GROUP |
`DETACHED_PROCESS |
| 日志 | DEVNULL(丢弃) |
写入 comfyui_runner.log(可排查) |
| 等待就绪 | 轮询 60s(超时) | 立即返回(调用方自行轮询) |
| 命令格式 | shell 字符串(转义地狱) | 列表(无转义问题) |
| 总耗时 | 77s+(超时) | ~12s(停止+启动) |
7.4 Windows 进程脱离原理
DETACHED_PROCESS (0x00000008)
→ 子进程不继承父进程的控制台
→ 即使父进程退出,子进程继续运行
CREATE_NEW_PROCESS_GROUP (0x00000200)
→ 创建新的进程组
→ Ctrl+C 信号不会传递到子进程
→ 适合后台服务两个标志组合使用,确保 ComfyUI 进程完全独立于 MCP 服务器进程。
7.5 使用方式
修复后的调用流程:
步骤 1: comfyui_restart()
→ 立即返回 {"status": "starting", "pid": 12345}
步骤 2: 等待 30-40 秒(让 ComfyUI 加载 320 个节点)
步骤 3: comfyui_status()
→ 返回 {"status": "running", "port": 8189, "version": "0.27.0"}
如果 status 仍为 "not_running",查看日志:
read_file(path="comfyui_runner.log")八、无头模式完整工作流
以下是修复后,AI 助手在无头模式下的完整操作链路:
用户: "帮我重启 ComfyUI 并生成一张猫的图片"
AI 助手:
1. comfyui_restart()
→ {"status": "starting", "pid": 12345}
2. (等待 30 秒)
3. comfyui_status()
→ {"status": "running", "port": 8189} ✓
4. submit_workflow(workflow_json=..., timeout=120)
→ {"status": "completed", "images": [{"filename": "cat_00001_.png"}]}
5. list_outputs(count=5)
→ 确认文件存在
全程无需打开浏览器,无需 PyCharm,无需人工干预九、总结:无头模式的能力边界
能做到的
| 能力 | 实现方式 |
|---|---|
| 启动 ComfyUI | comfyui_restart(DETACHED_PROCESS) |
| 停止 ComfyUI | comfyui_stop(端口扫描 + taskkill) |
| 检查状态 | comfyui_status(REST API 探测) |
| 提交工作流 | submit_workflow(POST /prompt + 轮询 /history) |
| 查看输出 | list_outputs(扫描 output 目录) |
| 读取日志 | read_file(读取 comfyui_runner.log) |
| 执行任意 Python | execute_python(在 .venv 中运行) |
| 执行 Shell 命令 | execute_shell(自动替换 python 路径) |
做不到的
| 限制 | 原因 |
|---|---|
| 打开浏览器界面 | 无头模式不启动 GUI |
| 拖拽节点编辑工作流 | 需要浏览器前端 |
| 安装自定义节点 | 外科手术式安装需要人工审查依赖(安全准则) |
| 启动 PyCharm | GUI 应用,沙箱无法启动 |
最佳实践
- 首次启动用 Bash 后台 :如果
comfyui_restart的 MCP 连接器刚重启过,用 Bashrun_in_background更可靠 - 后续重启用 comfyui_restart:修复后的版本已经稳定,支持 DETACHED_PROCESS
- 始终检查状态 :启动后用
comfyui_status确认端口就绪,再提交工作流 - 日志是最后防线 :如果启动失败,
read_file(path="comfyui_runner.log")查看 ComfyUI 的完整启动日志 - 工作流参数要完整 :通过 API 提交时,用
/object_info/<node>查询所有必填参数,不要只看 UI
附录:启动参数说明
bash
python main.py \
--enable-manager \ # 启用 ComfyUI Manager
--enable-assets \ # 启用 Asset Seeder 分布式模型分发
--enable-triton-backend \ # 启用 comfy-kitchen triton 后端
--async-offload \ # 异步模型卸载(节省显存)
--enable-dynamic-vram \ # 动态 VRAM 管理
--use-pytorch-cross-attention \ # 使用 PyTorch 原生注意力(兼容性最好)
--port 8189 # 指定端口(避免 8188 冲突)不要用 --use-flash-attention:与 Z-Image Turbo 等模型不兼容,会导致输出全噪声。
本文为 ComfyCloudMCP 系列第 11 篇文章
上一篇:PyCharm MCP 连接器配置与自定义 ComfyUI 执行器实战
环境:Windows 11 + ComfyUI v0.27.0 + Python 3.12 + PyTorch 2.7.1+cu126 + RTX 3090