目录
[Bahdanau 注意力(又称加性注意力,Additive Attention)](#Bahdanau 注意力(又称加性注意力,Additive Attention))
[x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1):](#x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1):)
介绍
编码器解码器前言:
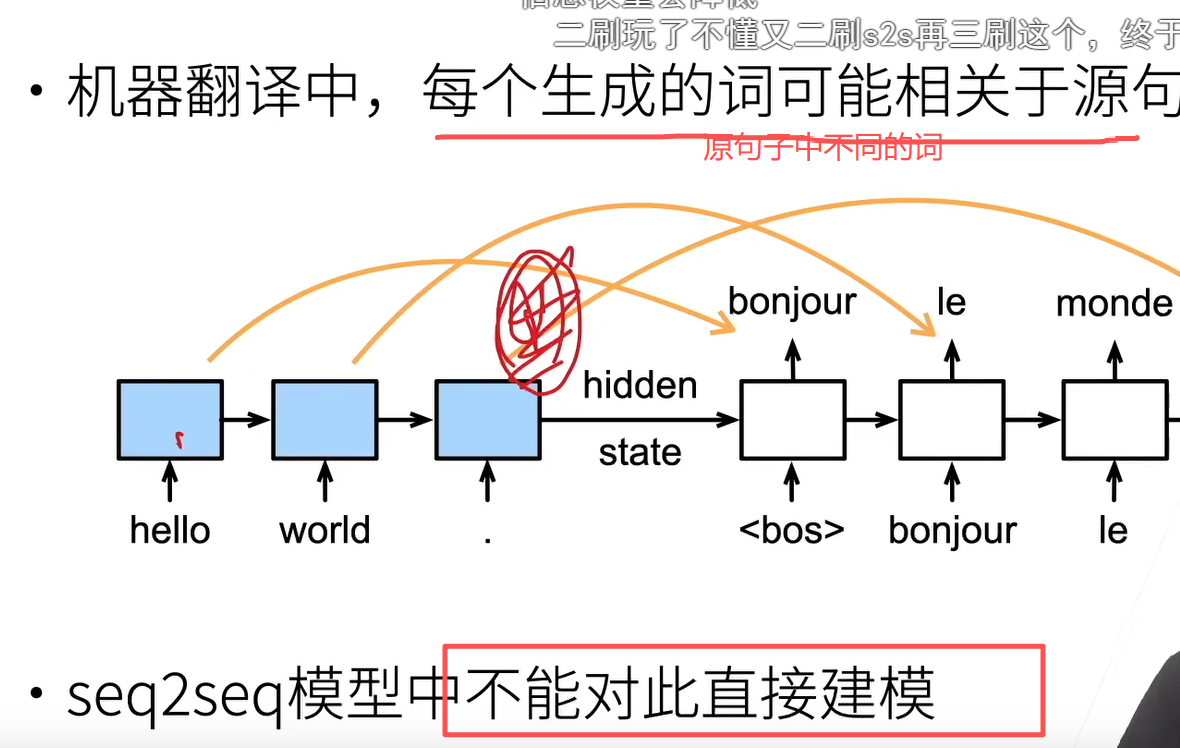
因为seq2seq是直接根据最后一个隐藏状态来输出,但实际上一般不同语言结构固定的,比如英文主语谓语宾语,不同词在对应结构上就有对应类似意思
需要从句子到具体要关注的单词,从粗粒度到细粒度
简单来说,它在回答一个问题:为什么翻译的时候,模型需要知道"生成的词"对应"原句的哪个词"?
我们可以拆解成三个部分来理解:
1. 核心现象:词与词的"对齐"
-
上半部分的箭头:展示了翻译过程中的一种自然对应关系。
-
左边是原句(英文):
hello world . -
右边是翻译结果(法文):
<bos> bonjour le monde -
橙色弧线 :比如法文的
bonjour(你好)对应英文的hello;法文的monde(世界)对应英文的world。这说明在生成目标词时,模型应该重点关注源句中特定的那个词。
-
2. 传统模型的缺陷
-
中间的蓝色方块(Encoder) :这是传统 seq2seq 模型的编码器,它把整句话压缩成一个"隐藏状态(hidden state)"。
-
红框里的结论:"seq2seq 模型中不能对此直接建模"。
-
底部的解释 :传统的 seq2seq 模型在生成翻译结果时,完全依赖编码器传过来的最后一个隐藏状态。这就好比你读完一句话后,只凭最后的"印象"去翻译每一个词。这样会丢失句子中单词的具体位置信息,导致翻译不准确,特别是当句子很长时。
3. 解决方案的方向
-
底部文字:"需要从句子到具体要关注的单词,从粗粒度到细粒度"。
-
这正是注意力机制(Attention) 的核心思想:模型在生成每一个输出词时,不再死盯着一个最终的隐藏状态,而是会动态地回头看源句子里的所有词,并给每个词分配不同的"关注度"(权重),挑出最相关的几个词来辅助生成当前的词。
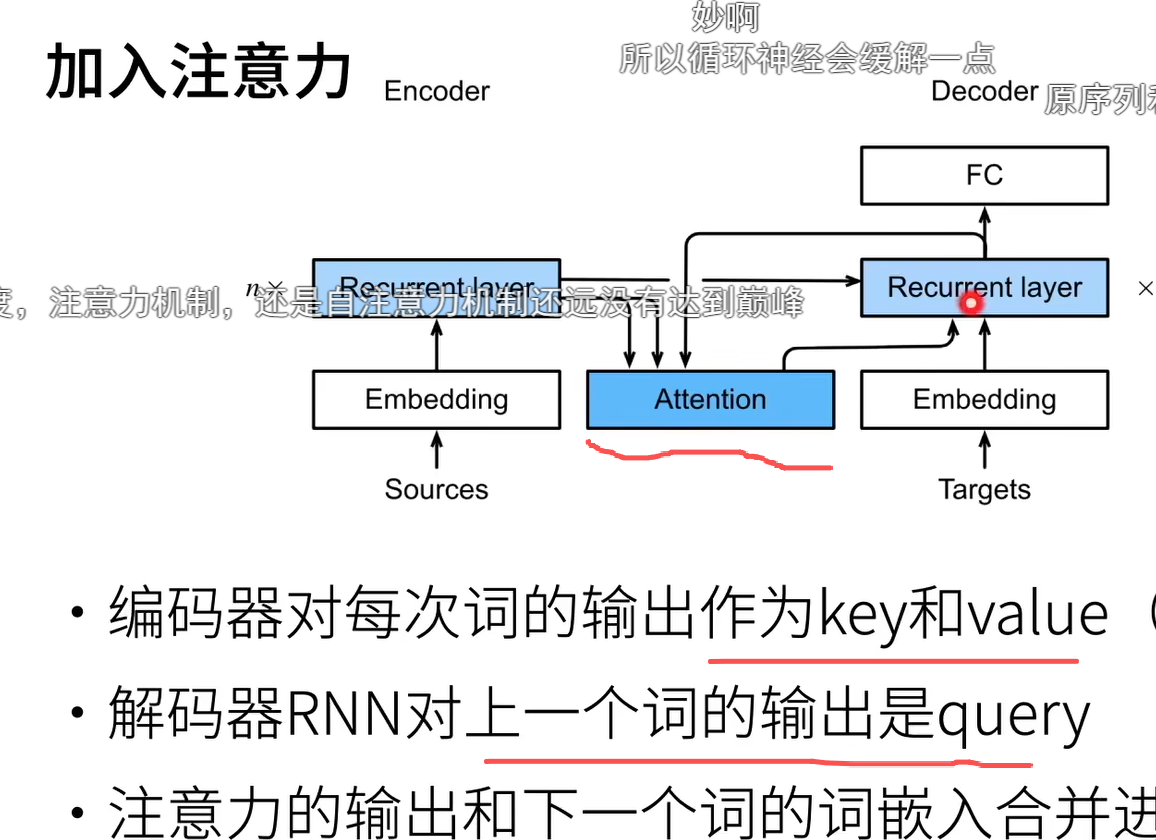
传统解码器是编码器最后一个时刻最后一层的输出作为上下文和embedding一起作为输入
这里的key value是一样的
在原本的S2Q中,RNN最后一个时刻的隐状态作为输出和Embedding合作作为解码器的输入,但是加入注意力后,就不一定是最后时刻的,而是前面任何一个时刻,这个时刻与此时Embedding输入相关
encoder不用全连接层,就拿hidden state就可以 这里编码器输出,其实是所有时间步最终隐藏层的隐状态
本来预测下一个词的时候用的是上一个词的隐变量,现在把这个隐变量作为查询,去查询在解码器的输入中对应的部分
query就是你当前预测的词的上一个词的输出,用这个输出去在attention里面找对应的k-v,拿来预测当前的这个词
例子:
想要预测出"你好",将"你好"作为query,进而放入Attention中找到hello附近的词(k-v),然后将这个k-v作为上下文和输入的Embedding一起放入RNN
例子
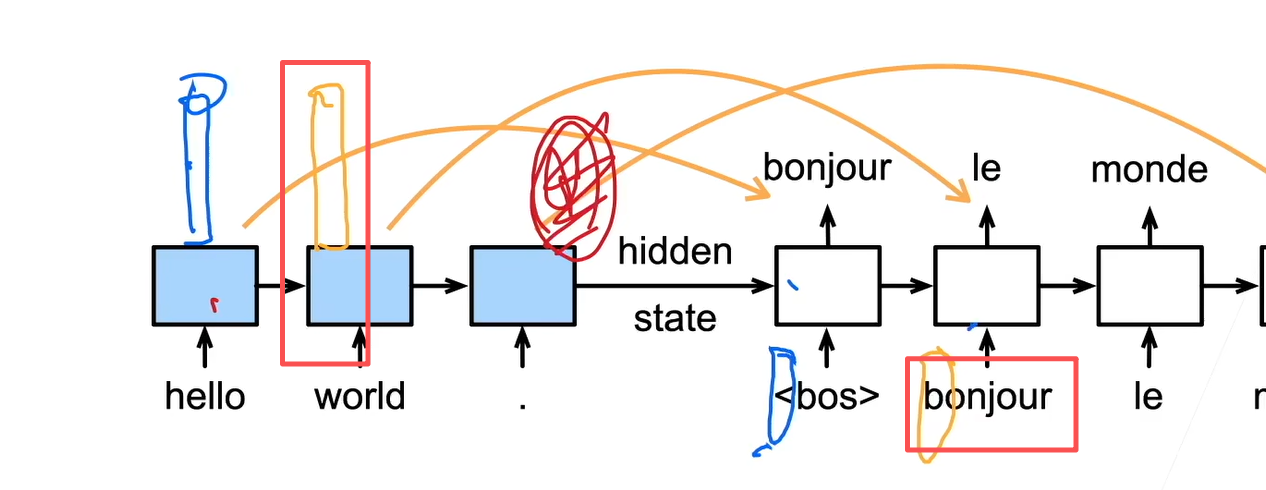
现在要求,比如预测法语的le这个词时候是需要world的隐状态和bonjour的embedding进行输入
相当于用编码器建立索引,用解码器来定位关注点
比如上一次预测的值是hello,那么我会根据这个hello去寻找下一个词是什么,并将这个词作为解码器的初始化,比如预测hello world时候并不能拿到world的embedding(因为还没预测出来),只能拿decoder中world之前的hidden state去代替这里想预测的world
比如source是你好世界,target是hello world,现在你预测得到hello,根据hello去预测world,所以query是hello
预测出hello,将hello作为query,进而放入Attention中找到hello附近的词作为k-v,然后将这个k-v作为上下文和输入的Embedding一起放入RNN 只能拿decoder中world之前的hidden state去代替这里想预测的world(找到上一个输出附近的词,作为解码器输入,提高长句子准确)
要预测下一个词的时候,将当前预测出的词作为query,编码器各个状态作为(key,value),进行attention,来找到对预测下一个词有用的原文
预测当前词的时候,可以根据上一个词看看,为了更好的预测当前词,我应该更加关注encoder的哪些key value(哪些时间步的hidden)
总结:

其实就是把原来**"由编码器综合输出放到解码器一步步推出来"的机制改成了"解码器和编码器按注意力机制来处理数据"的机制**,具体看那个流程图就很好懂了 通过上一个来预测查找下一个可能性最大的字
有无注意力机制区别:

代码:
Bahdanau 注意力 (又称加性注意力,Additive Attention)

python
import torch
from torch import nn
from d2l import torch as d2l
#@save
class AttentionDecoder(d2l.Decoder):#继承父类decoder
"""带有注意力机制解码器的基本接口"""
#调用父类的 __init__方法。
#**kwargs表示将接收到的所有关键字参数(如 vocab_size, embed_size等)原封不动地传给父类。
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
"""
AdditiveAttention:加法注意力机制,适合处理查询和键维度不同时的对齐。这里查询、键、值的维度都设为 num_hiddens。
Embedding:将离散的词索引映射为稠密向量,维度 embed_size。
GRU:输入维度 = 词嵌入 embed_size+ 上下文向量 num_hiddens(因为要将注意力结果拼接到词嵌入上)。输出隐状态维度仍为 num_hiddens。
dense:将 GRU 输出的隐状态映射回词汇表大小,用于预测下一个词的概率分布
"""
# 加法注意力机制:查询、键、值的维度均为 num_hiddens
"""
加性注意力在K,Q前有个可学习的矩阵,通过学习可以更加好的找到两者之间的相似性 点积的注意力机制没有参数,直接两个向量按位相乘
"""
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
# GRU循环神经网络,输入维度 = 嵌入维度 + 上下文向量维度(num_hiddens)********
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
# 输出层:将隐状态映射到词汇表大小
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
"""
初始化解码器状态:
- enc_outputs: 编码器所有时间步的输出 (batch_size, num_steps, num_hiddens)
- enc_valid_lens: 有效长度(用于mask填充部分)
- 返回: (enc_outputs转置为(num_steps, batch_size, num_hiddens),
隐藏状态, 有效长度)
"""
"""
为什么接收 enc_outputs并拆包:编码器返回的是 (outputs, hidden_state)元组,其中 outputs形状 (batch, steps, hiddens),hidden_state形状 (layers, batch, hiddens)。
permute(1,0,2):将 outputs从 (batch, steps, hiddens)转为 (steps, batch, hiddens),以便在解码循环中按时间步迭代(循环的第一个维度是时间步)。
返回三元组:包含编码器输出(时间步优先)、编码器最后隐状态、有效长度(用于 mask 填充位置)。
"""
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
"""
前向传播:
- X: 目标序列 (batch_size, num_steps)
- state: (编码器输出, 隐藏状态, 有效长度)
"""
enc_outputs, hidden_state, enc_valid_lens = state
# 词嵌入并转置为 (num_steps, batch_size, embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
#每次的hidden_state发生改变,query也就变了,context随之改变
for x in X:
# 当前时间步的查询:取最后一个GRU层的隐藏状态作为query
# shape: (batch_size, 1, num_hiddens) hidden_state每次迭代完一轮会改变, 就变为上一个时刻rnn的输出了**********
query = torch.unsqueeze(hidden_state[-1], dim=1)
"""
注意力机制的工作流程:
计算 query 与每个 key 的匹配分数(加法注意力使用加性打分函数)。
对分数做 softmax 归一化,得到注意力权重(形状 (batch, 1, num_steps))。
用这些权重对 value(即 enc_outputs)进行加权求和,得到一个上下文向量 context,形状 (batch, 1, num_hiddens)。
所以 context本质上是对编码器所有时间步输出的加权平均,权重由当前解码状态决定****,它告诉解码器"在生成当前词时,应该重点关注源句子中的哪些部分"。这个上下文向量随后与当前词嵌入拼接,共同送入 GRU 以更新隐藏状态。
"""
# 通过注意力计算上下文向量 context (batch_size, 1, num_hiddens) 核心部分和之前传统的对比
#********** k v 一样 所以enc_outputs是一样的
#enc_valid_lens:因为pad是占位符,没有实际意义,pad掉就是说这块不用考虑 比方说原句太短,后面的部分用占位符填充所以不用考虑
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 将当前词嵌入与上下文向量拼接 (batch_size, 1, embed_size+num_hiddens)
#number of query和上一节additiveAttention的一样,加一维是为了调用additiveAttention的接口 关于矩阵形状可以看书 书上标记了 个人理解当前query只有一个词,加一维是因为,每个query要对encoder的每个时间步求一个权重,最后加权
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)#(batch_size, 1, embed_size+num_hiddens)
# 送入RNN,x需变为 (1, batch_size, embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
# 保存注意力权重供可视化
self._attention_weights.append(self.attention.attention_weights)
# 将所有时间步的输出拼接并通过全连接层
# outputs形状: (num_steps, batch_size, num_hiddens)
outputs = self.dense(torch.cat(outputs, dim=0))
# 返回 (batch_size, num_steps, vocab_size) 和更新后的状态
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
# # 转置为 (batch_size, num_steps, vocab_size)
@property
def attention_weights(self):
"""返回内部存储的注意力权重列表"""
return self._attention_weights
# 测试代码
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()#切换到评估模式,关闭 dropout 和 batch normalization 的训练行为。
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size, num_steps)模拟一个批次大小为4、序列长度为7的全零输入(假设所有 token 都是 <pad> 索引0)。实际训练时会替换为真实数据。
#先用编码器处理输入,再用编码器的输出初始化解码器状态。None表示不提供有效长度(即全部视为有效)。
state = decoder.init_state(encoder(X), None)
#执行一次解码(教师强制,即输入真实目标序列)。输出形状应为 (4,7,10)。
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))代码小细节:
@property
是 Python 内置的一个装饰器,用于将一个类方法转换为只读属性。它的作用:
让方法像属性一样访问:调用时不需要加括号 (),例如 decoder.attention_weights而不是 decoder.attention_weights()。
提供封装性:可以在内部实现复杂的计算逻辑,但对外表现为一个简单的属性,便于维护和修改。
常配合 setter/deleter 使用(此处未用到),控制属性的赋值和删除行为。
这样,外部代码就可以通过 decoder.attention_weights获取注意力权重列表,而无需关心内部变量名 _attention_weights或额外的函数调用。同时,你也可以在 forward中动态更新 _attention_weights,而 attention_weights属性始终返回最新的值。
enc_outputs在这里是一个元组(tuple),它包含了编码器 encoder(X)返回的两个元素:
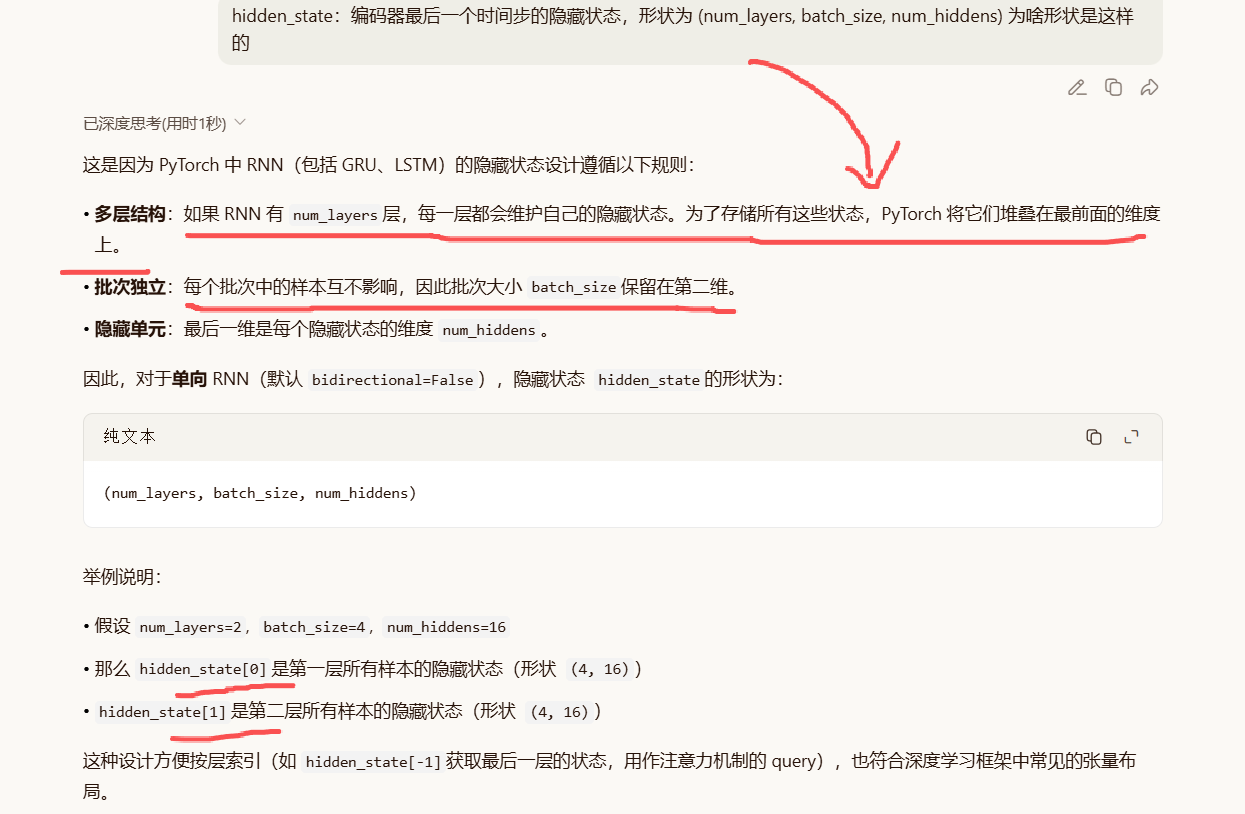
outputs:编码器在所有时间步的输出,形状为 (batch_size, num_steps, num_hiddens)。
hidden_state:编码器最后一个时间步的隐藏状态,形状为 (num_layers, batch_size, num_hiddens)。
代码 outputs, hidden_state = enc_outputs就是对这个二元组的解包赋值。
可以理解为:
enc_outputs = encoder(X) # 返回 (outputs, hidden_state)
outputs = enc_outputs0 # 第一个元素
hidden_state = enc_outputs1 # 第二个元素
前向传播:
context上下文是什么
"""
注意力机制的工作流程:
计算 query 与每个 key 的匹配分数(加法注意力使用加性打分函数)。对分数做 softmax 归一化,得到注意力权重(形状 (batch, 1, num_steps))。
用这些权重对 value(即 enc_outputs)进行加权求和,得到一个上下文向量 context,形状 (batch, 1, num_hiddens)。
所以 context本质上是对编码器所有时间步输出的加权平均,权重由当前解码状态决定****,它告诉解码器"在生成当前词时,应该重点关注源句子中的哪些部分"。这个上下文向量随后与当前词嵌入拼接,共同送入 GRU 以更新隐藏状态。
"""
注意力计算(上一篇内容):

关键点:三维张量如何参与计算?
-
虽然
enc_outputs是三维的,但注意力机制的核心操作(线性变换、加法、tanh、线性变换)都是逐元素 或沿最后一维进行的,不会破坏时间步的独立性。 -
例如
linear_k(key)会作用于(batch, num_steps, num_hiddens)的最后一维,输出仍是(batch, num_steps, hidden_dim)。 -
最后的 softmax 沿时间步维度(第1维)进行,得到每个时间步的权重。
总结qkv三者的关系:******
-
query(q) :来自解码器当前时间步的隐藏状态,动态变化。
-
key(k) :编码器输出,固定不变,用于计算注意力分数。
-
value(v) :编码器输出(与 key 相同),固定不变,用于加权求和得到上下文向量。
所以,v 和 k 一样,每次都是一样的(同一份 enc_outputs),只有 q 在变化。


forward:
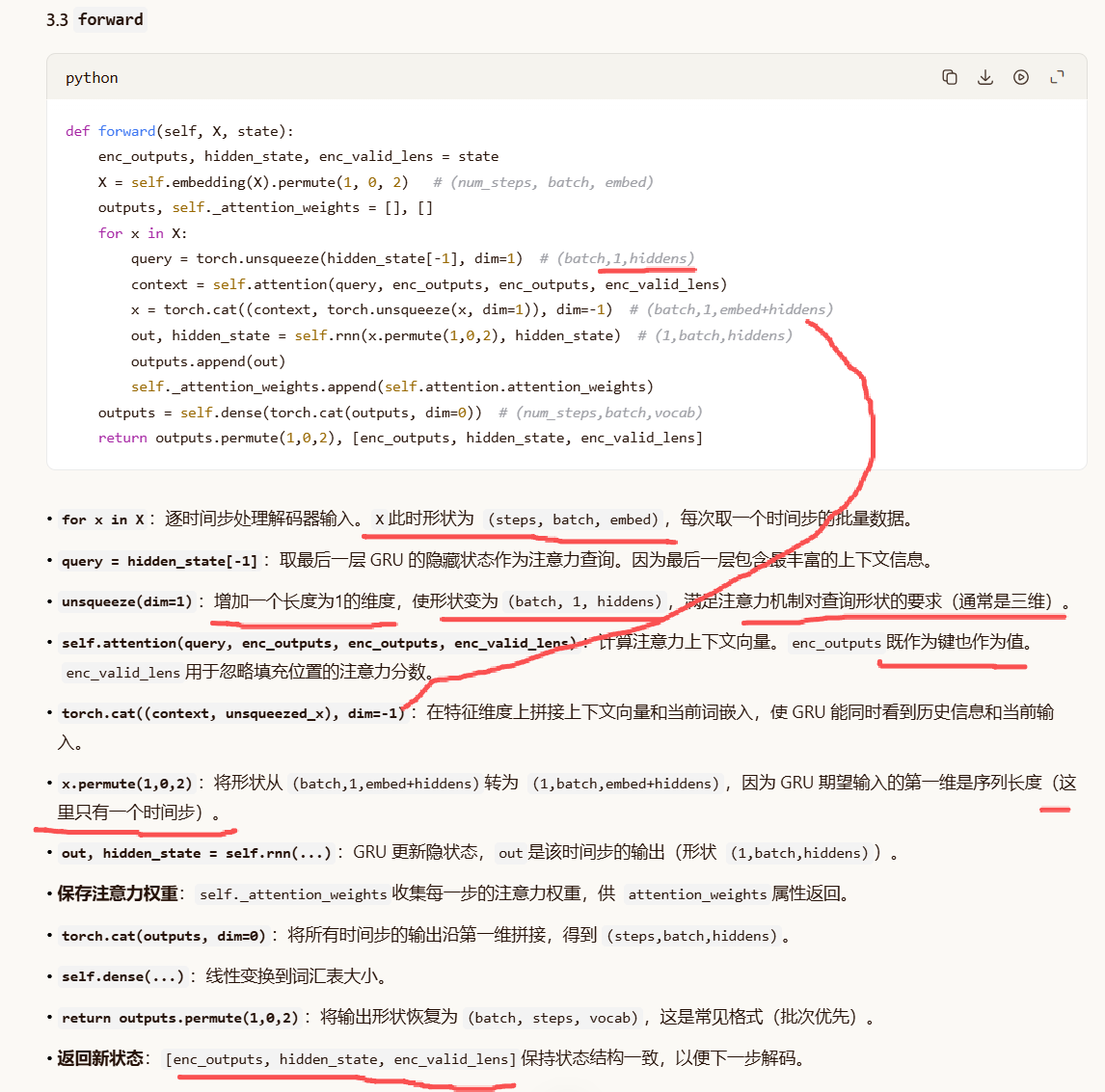
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1):
context形状:(batch_size, 1, num_hiddens)
torch.unsqueeze(x, dim=1)形状:(batch_size, 1, embed_size)
dim=-1等价于 dim=2,即沿最后一个维度(特征维度)拼接。
结果形状:(batch_size, 1, embed_size + num_hiddens)

self.dense(nn.linear)

大总结:
总而言之,我们的context和我们不使用注意力时有点区别
例子
用一个具体的翻译例子来说明。
假设我们要把英文句子 "I love you" 翻译成中文 "我爱你"。
没有注意力机制的传统 Seq2Seq
-
编码器读完整个句子后,只输出一个固定的上下文向量(通常是最后一个时间步的隐藏状态)。这个向量试图压缩整个源句子的信息。
-
解码器生成每个中文词时,都依赖同一个固定向量,无法动态关注源句子的不同部分。
-
例如生成"爱"时,模型只能从那个固定向量里猜测,不知道应该重点看源句子的哪个单词。
使用注意力机制的 Seq2Seq(本节代码)
-
编码器输出所有时间步的隐藏状态 (
enc_outputs),形状(batch, num_steps, num_hiddens)。 -
解码器每生成一个词,都用当前隐藏状态作为 query ,去查询编码器的所有输出(作为 key 和 value ),计算出一个动态的上下文向量
context。 -
例如:
-
生成"我"时,query 会让注意力权重集中在源句子的"I"上,得到的
context主要包含"I"的信息。 -
生成"爱"时,query 会让注意力集中在"love"上。
-
生成"你"时,注意力集中在"you"上。
-
在代码中具体体现
for x in X: # 每个时间步
query = hidden_state[-1].unsqueeze(1) # 当前解码状态
context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)
# context 是动态计算的,不同时间步不同
x = torch.cat((context, x.unsqueeze(1)), dim=-1)
out, hidden_state = self.rnn(x.permute(1,0,2), hidden_state)- 如果没有注意力,我们会直接拿
enc_outputs的最后一个时间步(或固定池化)作为初始状态,然后循环中不再重新计算context,即context是静态的。
总结 :使用注意力时,context是动态加权 的结果,每一步都不同;不使用注意力时,context是固定压缩的向量,所有步骤共享。这就是本质区别。
训练代码:
python
# 超参数设置
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
# 加载神经机器翻译数据集(英法平行语料)
# train_iter: 训练数据迭代器,src_vocab: 源语言词表,tgt_vocab: 目标语言词表
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
# 创建编码器:Seq2SeqEncoder(普通RNN编码器)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# 创建解码器:带Bahdanau注意力的Seq2SeqAttentionDecoder(之前定义的类)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
# 组合成完整的编码器-解码器网络
net = d2l.EncoderDecoder(encoder, decoder)
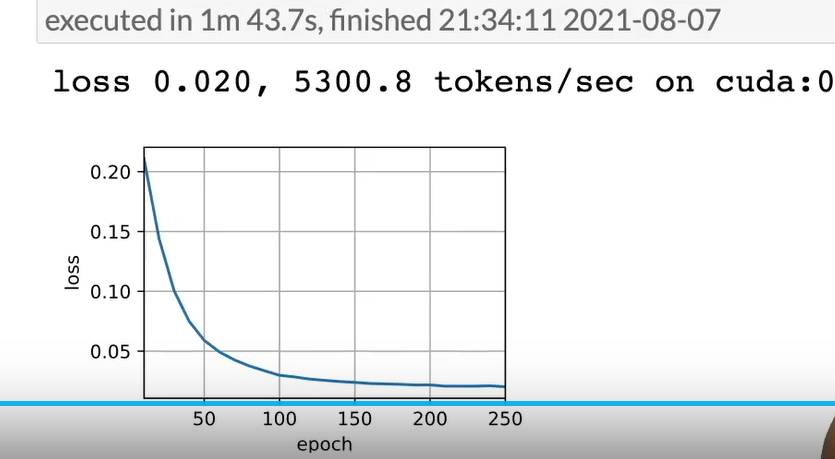
# 训练模型
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
# 测试句子(英法对照)
engs = ['go .', "i lost .", "he's calm .", "i'm home ."]
fras = ['va !', "j'ai perdu .", "il est calme .", "je suis chez moi ."]
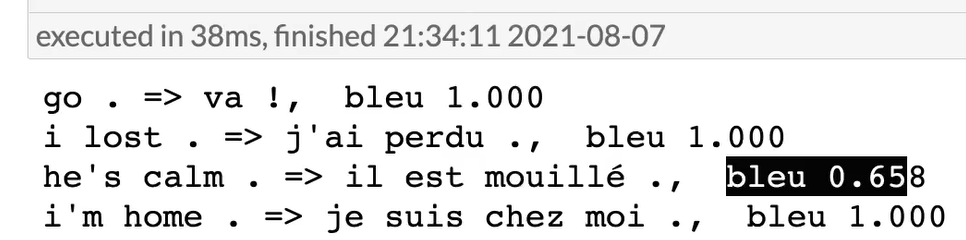
for eng, fra in zip(engs, fras):
# 预测翻译,同时返回注意力权重序列
# dec_attention_weight_seq: 列表,每个元素对应解码器一个时间步的注意力权重
# 每个元素形状复杂,通常为 (batch, num_heads, num_queries, num_keys)
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
# 打印翻译结果和BLEU分数(k=2表示使用2-gram)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
# 可视化注意力权重(仅针对最后一个句子)
# 将解码器所有时间步的注意力权重拼接并重塑
# step[0][0][0] 含义:
# step: 一个时间步的注意力权重,形状 (batch, num_heads, num_queries, num_keys)
# step[0]: 取出批次中第一个样本(batch=1)
# step[0][0]: 取出第一个注意力头(num_heads=1)
# step[0][0][0]: 取出第一个查询位置(num_queries=1),因为解码器每步只有一个查询
# 最终得到一个长度为 num_steps 的列表,每个元素是长度为 num_steps 的向量
# 沿第0维拼接后形状为 (num_steps, num_steps)
# reshape 成 (1, 1, num_steps, num_steps) 用于热力图显示
attention_weights = torch.cat(
[step[0][0][0] for step in dec_attention_weight_seq], 0
).reshape((1, 1, -1, num_steps))
# 截取到最后一个英文句子的词数+1(+1包含结束符<eos>)
# engs[-1] 是 "i'm home .",split() 得到 ["i'm", "home", "."],长度3,+1=4
# 因此只显示前4个查询位置对应的注意力分布
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')关键点补充说明
-
dec_attention_weight_seq的结构d2l.predict_seq2seq在True参数下会返回注意力权重。每个时间步的权重形状为(1, 1, 1, num_steps),即(batch=1, num_heads=1, num_queries=1, num_keys=num_steps)。因此step[0][0][0]取出的是一个长度为num_steps的一维向量,表示当前解码步对编码器各位置的注意力分布。 -
**
len(engs[-1].split()) + 1**-
engs[-1]是最后一个英文句子"i'm home .",split()得到["i'm", "home", "."],长度3。 -
+1表示包含序列结束标记<eos>(通常在预测时也会生成该标记)。这样热力图的查询位置只显示到实际生成的长度(不包括填充),便于观察对齐情况。
-
-
热力图展示
show_heatmaps将注意力权重矩阵以颜色深浅的形式呈现,横轴为编码器位置(Key positions),纵轴为解码器位置(Query positions),直观展示翻译时的对齐关系。
结果:
可视化权重:
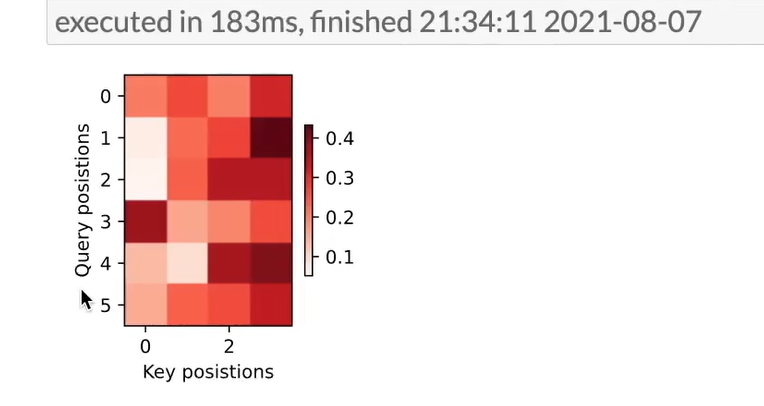
还是把高权重给离他最近的几个单词的hidden_state了(总体看,还是权重偏向原句的后面) 偏向后面是必然的 因为encoder最后一个位置的k包含了所有信息 和decoder每个q更容易相似
问题:
问题1:看懂了数学逻辑,还是不太理解k q v的具体含义
可以把 Q、K、V 想象成在一次**"图书馆借书"**的过程:
-
Query (q) - 查询 :代表你**"想找什么"**。比如你现在手里有一张纸条写着"我想找关于人工智能的资料",这就是你的查询意图。在神经网络中,它通常是当前正在处理的位置(比如解码器当前要翻译的词)发出的"询问"。
-
Key (k) - 键 :代表物品**"叫什么名字/有什么标签"**。比如图书馆里每一本书的书脊标签。在神经网络中,它是序列中每一个元素(比如句子中每一个词)的特征,用来和你的查询进行比对。
-
Value (v) - 值 :代表物品**"实际包含什么内容"**。比如书里面的具体文字和图表。只有当你的查询(Query)和书的标签(Key)匹配上了,你才会把这本书的内容(Value)拿出来。
总结:用 Query 去和所有的 Key 算相似度(打分),得分高的 Key 对应的 Value 就会被赋予高权重,最后把所有 Value 加权混合,就得到了"注意力"的结果。
问题8:q是decoder的输出,那第一次q是怎么得来的?
在 Seq2Seq 模型(带注意力的)中,第一次计算注意力时,解码器还没有产生任何输出。
这时候的 Query (q) 并不是来自解码器的输出,而是来自编码器(Encoder)的最后一个时间步的隐藏状态。
-
编码器读完整个输入句子后,会产出一个包含了整个句子总结性信息的向量。
-
模型把这个向量作为解码器启动时的初始状态(也就是第一次的 Query),去和编码器产生的所有输出进行比对,从而生成第一个目标词。
问题3:一般都是在decoder加入注意力吗,不可以在encoder加入吗?
当然可以!而且现在非常普遍。比如bert
-
在 Decoder 加注意力(通常是 Cross Attention):主要是为了"对齐"。比如翻译时,生成"苹果"这个词时,模型需要知道该重点关注源语言里的"apple"还是"apple Inc."。
-
在 Encoder 加注意力(通常是 Self-Attention):是为了让编码器更好地理解输入序列的内部关系。比如在一句话中,"因为"和"所以"相隔很远,但它们语义高度相关。在 Encoder 中加入自注意力,可以让模型轻松捕捉到这种长距离的依赖关系。现在的 Transformer 模型就是把自注意力作为核心组件大量使用的。
问题4:enc_valid_lens的值能再讲下如何设置的吗?可以用时间序列为例子吗?
enc_valid_lens的作用是告诉注意力层哪些位置是真实的输入,哪些是后来强行补齐的"废话"(Padding),防止模型去关注那些无效的填充位置。
时间序列例子:
假设你在预测股票走势,设定的批处理大小(batch size)是 2,最大输入长度是 5 天。
-
样本 A (最近有数据的5天):
[100, 101, 102, 103, 104]-> 有效长度5 -
样本 B (最近只有数据的3天,为了凑齐5天补了两个0):
[200, 201, 202, 0, 0]-> 有效长度3
在这种情况下,enc_valid_lens就是一个包含这两个样本真实长度的向量,比如 tensor([5, 3])。
当模型在计算注意力分数时,如果发现有 Padding(值为0的位置),就会利用 valid_lens把这些位置的分数屏蔽掉(通常设为负无穷),这样经过 Softmax 后,它们的权重就变成了 0。
问题5:注意力机制是不是和昨天讲的束搜索(在最后的全连接层处理的)有些类似?
它们完全不是一回事,处于模型的不同阶段,解决的问题也不同。
-
注意力机制(Attention) 是模型内部的"计算结构"。它在神经网络的前向传播过程中起作用,负责决定在生成某个词时,应该"多看"输入序列的哪一部分。它影响的是模型学到了什么特征。
-
束搜索(Beam Search) 是模型推理时的"解码策略"。当模型已经训练好了,要去生成最终的翻译结果或文章时,束搜索是一种用来寻找概率最高输出路径的算法(比如每一步不只选概率最高的1个词,而是选概率最高的前3个词继续往下试)。它影响的是模型输出的最终结果质量。
打个比方:注意力机制是汽车的发动机 (决定了车能不能跑得快、跑得稳);束搜索是导航软件的寻路算法(决定了车最终走哪条路线到达目的地)。