摘要
当前大语言模型智能体已可开展实际生物医药研究,但对其开展严谨评测存在较大难度。仅依托最终结果的评测基准存在2大缺陷:
❶ 智能体得出正确答案,可能依靠模型记忆、刷分行为,或是错误推理偶然得到正确结果;
❷ 部分科学有效的差异化分析方案,仅因与参考方案不一致就被判定为错误。
为此,本文提出过程级评测框架BiomniBench,依托领域专家定制的任务专属评分细则,对智能体的完整分析链路进行打分。本框架首发版本为BiomniBench-DA,包含100项数据分析任务,覆盖17类分析任务、5大疾病领域及普通生物学范畴;所有任务均源自Nature/Cell/Science等顶刊论文,由原论文作者或领域专家联合构建。研究基于4类智能体框架,对主流闭源前沿模型与开源模型开展评测,得到3项核心结论:闭源与开源基础模型得分差距较小,所有模型仍存在较大性能提升空间;智能体框架对得分的影响,超过模型代际迭代带来的差距;智能体可规范引用真实文献支撑结论,但在分析方法选择、生物学解读与科学推理方面普遍存在短板。BiomniBench是首个面向生物医药领域大语言模型智能体的过程级评测基准,可实现多维度能力诊断,弥补了结果导向评测的不足。
huggingface.co/datasets/phylobio/BiomniBench-DA
yuanhao@phylo.bio
#大语言模型智能体 #过程级评测 #结果导向评测 #生物医药研究 #评测基准数据集 #数据分析 #评分细则 #智能体框架 #科学推理 #生物学解读
引言
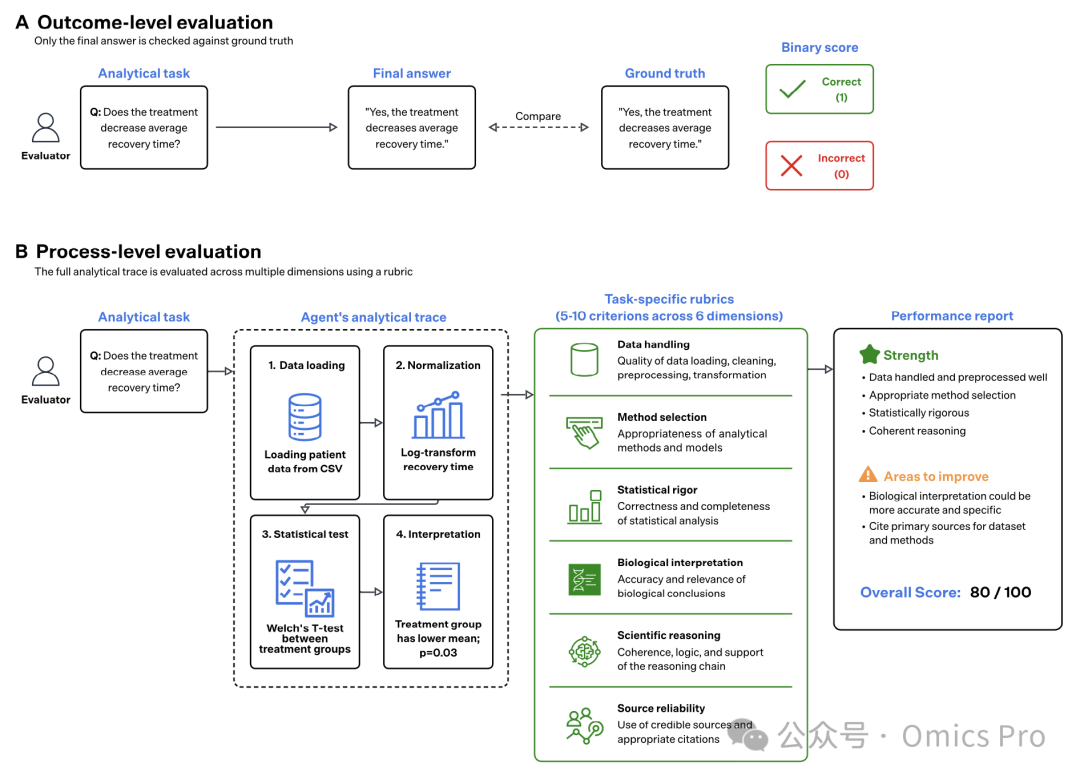
图1 过程级评测与结果导向评测对比
(A) 结果导向评测:仅将智能体最终答案与标准答案进行比对;
(B) 过程级评测:依托专属评分细则,对智能体完整分析链路开展多维度打分,可定位智能体的具体缺陷。评测维度包含数据处理质量、分析方法选取、统计严谨性、生物学解读、科学推理及文献可靠性,并给出综合得分。
BiomniBench-DA:基准设计
专家主导的数据集构建流程
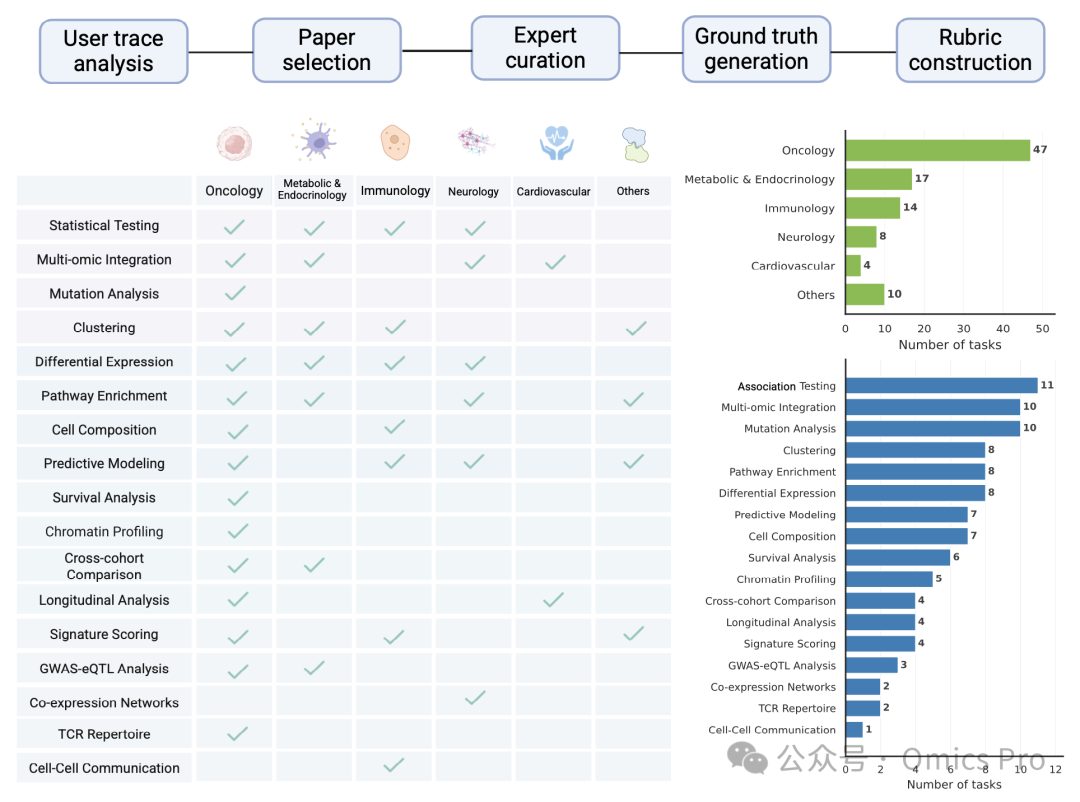
图2 BiomniBench-DA数据集整体概览(共100项任务)
上图:数据集5阶段构建流程,依次为用户行为分析、文献筛选、专家定制任务、参考真值生成、评分细则设计;
左下:任务类型与疾病领域的交叉覆盖矩阵(勾选代表该类别下设有对应任务);
右下:数据集按疾病领域、分析任务的分布统计。
实验与结果
固定智能体框架下基础大模型性能
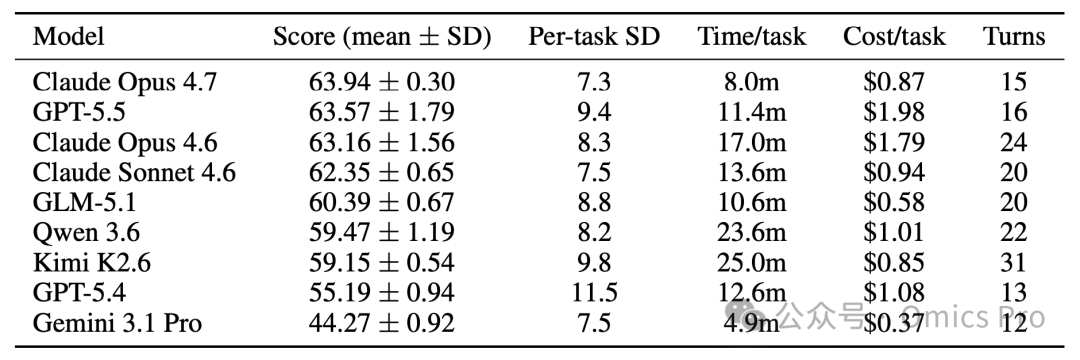
表1 基于Terminus-2框架的9款大模型评测结果
表格统计100项任务3轮重复实验的平均得分、单任务标准差、单任务运行时长、调用成本及交互轮次;得分、标准差、运行耗时、成本、交互轮次均为统计均值/中位数。
不同大模型与智能体框架组合性能
表2 多智能体框架 + 大模型组合的交叉评测结果
统计3类框架Claude Code、Codex CLI、Gemini CLI搭配对应大模型的综合得分、稳定性、运行时长、调用成本与交互轮次,统计规则与表1一致。
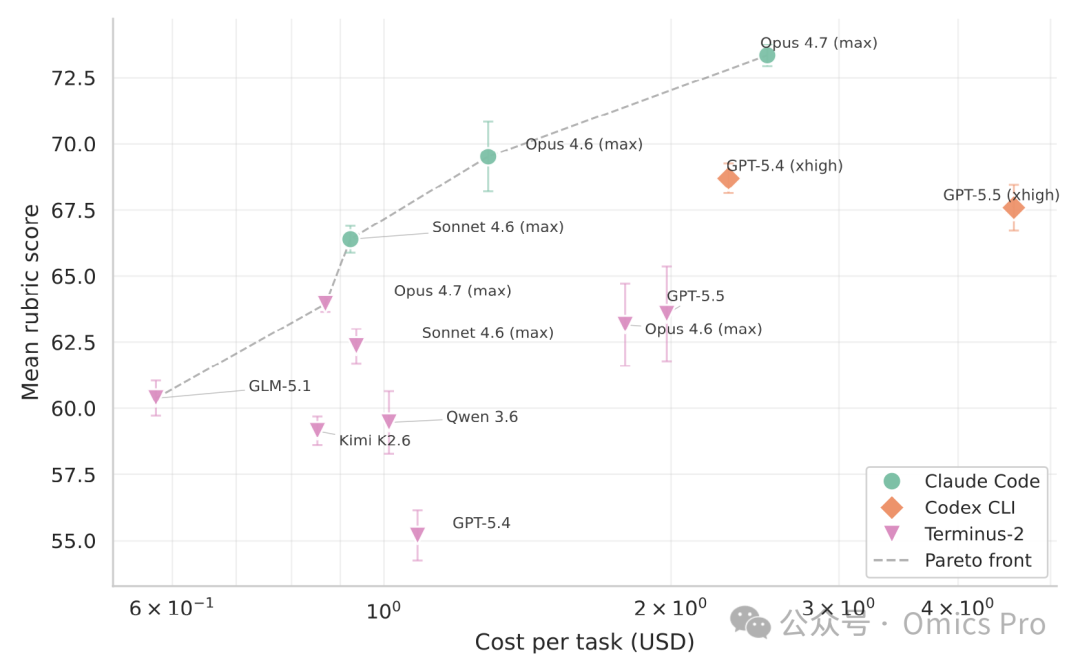
图3 不同模型-框架组合的成本-性能帕累托分布图
横轴为单任务调用成本(对数坐标,单位:美元),纵轴为评测平均得分;误差棒代表3轮重复实验的标准差;虚线为帕累托前沿,前沿上方的组合在性能与成本上更具优势;本图未纳入Gemini系列组合(无成本数据)。
智能体性能拆解分析
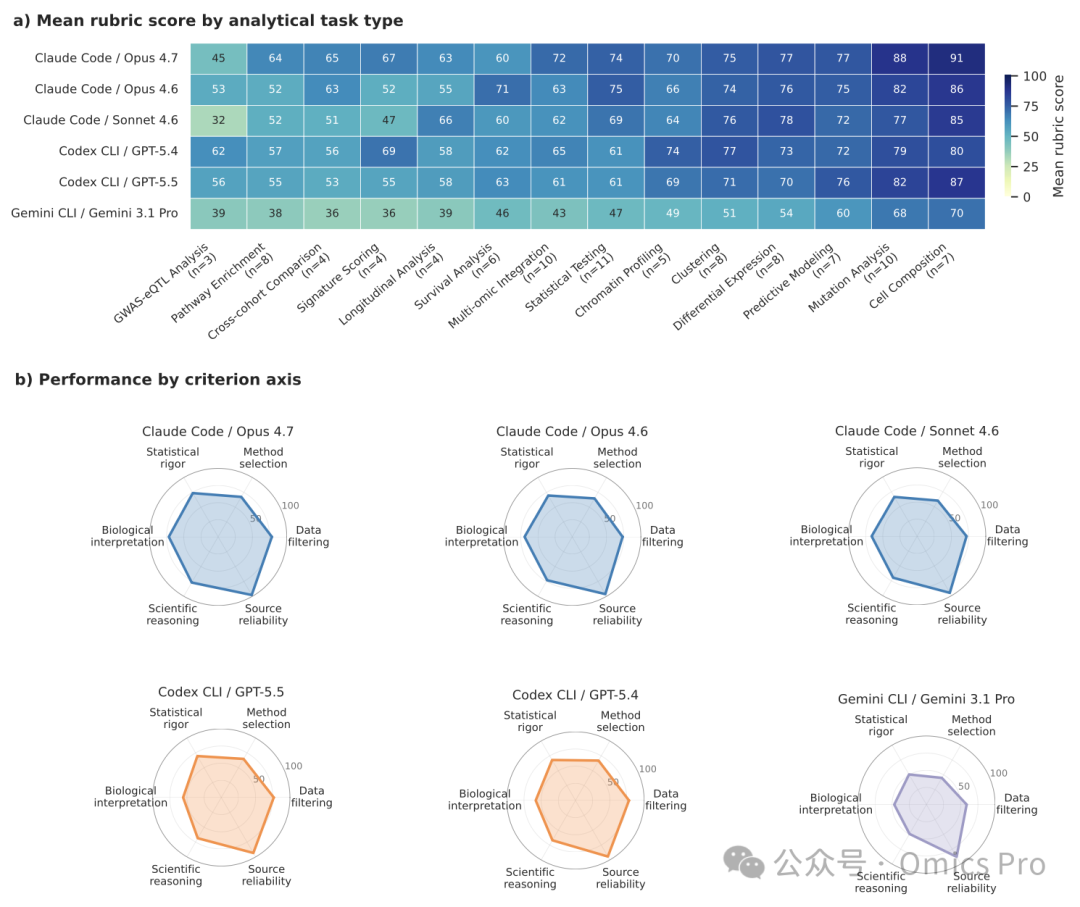
图4 智能体多维度性能拆解分析
(a) 不同模型-框架组合在各类分析任务上的平均得分(按任务难度由高至低排序,仅展示样本≥3的任务类别);
(b) 6大评测维度下各组合的得分占比,维度包含数据处理、分析方法选择、统计严谨性、生物学解读、科学推理、文献可靠性。
详细总结
思维导图
参考
BiomniBench: Process-level Evaluation of LLM Agents for Real-world Biomedical Research
doi: https://doi.org/10.64898/2026.05.12.724604
注:AI辅助创作,如有不当欢迎指出。内容仅供参考,不构成任何建议。