|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 英文名称: T-RAG: LESSONS FROM THE LLM TRENCHES 中文名称: T-RAG:来自LLM战壕的经验教训 链接: https://arxiv.org/abs/2402.07483 作者: Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla 机构: 卡塔尔计算研究所, 哈马德·本·哈利法大学 日期: 2024-02-12 引用次数: 0 |
1 摘要
- 目标:开发一个可以安全、高效地回答私有企业文档问题 的大型语言模型(LLM)应用程序,主要考虑数据安全性、有限的计算资源以及需要健壮的应用程序来正确响应查询。
- 方法:应用程序结合了检索增强生成(RAG)和微调的开源 LLM,将其称之为 Tree-RAG(T-RAG)。T-RAG 使用树结构来表示组织内的实体层次结构,用于生成文本描述,以增强对组织层次结构内的实体进行查询时的上下文。
- 结果:我们的评估显示,这种结合表现优于简单的 RAG 或微调实现。最后,根据构建实际应用的 LLM 的经验,分享了一些获得的教训。
2 读后感
这篇文章的创新点逻辑比较简单:除了基本的 RAG 外,定位了问题中的实体,在事先定义好的实体树中寻找其父实体,并将其加入到问题的上下文中。可以视为对问题中实体抽象的方法。
我个人比较喜欢有两点:
第一点是:这是一个对问题抽象化,并与现有知识融合的范例。对问题进行规范化和抽象化 后再提问或存储,构建更复杂的存储结构,与原有知识融合,这可能是大模型领域一个重要的问题。与此相比,之前 RAG 直接将文档打散成碎片的方式确实过于简单粗暴。
第二点是:论文描述了本地 RAG 的具体实现方法,一些在实践中的常见问题的总结,例如在 LLAMA-7B 模型上精调所需的硬件,以及精调对原模型能力的影响。干货很多,看完可以少走一些弯路。
3 方法
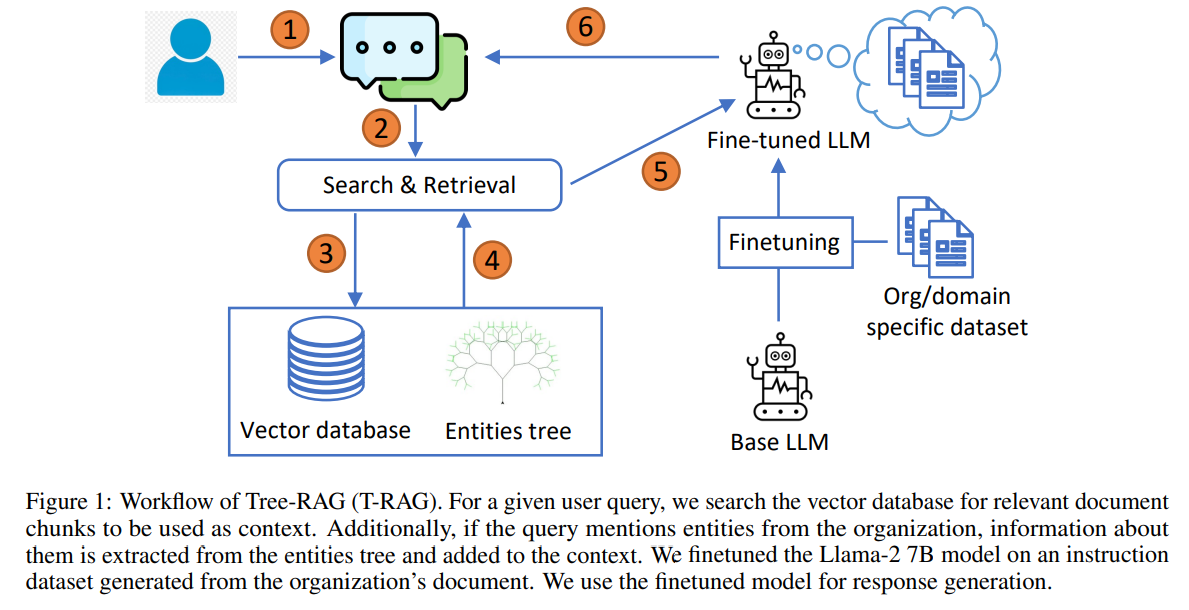
图 1:Tree-RAG(T-RAG)的工作流程。对于给定的用户查询,在向量数据库中搜索要用作上下文的相关文档块。此外,如果查询提及组织中的实体,则会从实体树中提取有关这些实体的信息并将其添加到上下文中。我们在从组织文档生成的指令数据集上对 Llama-2 7B 模型进行了微调。我们使用微调模型来生成响应。

3.1 指令数据集准备
先使用 LangChain 库将原始 PDF 文件解析为文本格式,表格和结构图则由人工专家手动转化为文本。
然后,根据文档中的各个节标题,将每一节分解成一个独立的块。通过在几轮迭代中为每个块生成一组(问题、答案)对。
- 在第一次迭代中,对于每个块,提示 Llama-2 模型为提供的区块生成问题和答案。提示模型生成各种问题类型,例如对或错、摘要、简答等。记录提供问题、答案和相关块的模型响应。
- 在第二次迭代中,对于每个块,提示模型一个对话示例,并要求在用户和 AI 助手之间生成一个对话。
- 在第三次迭代中,模型被要求执行相同的任务(为给定的块生成问题和答案); 在此迭代中,为模型提供了由人类专家根据文档创建的问题示例。
汇总各种迭代过程中产生的问题和答案,以此创建一个数据集。对生成的问题和答案进行了人工检查,并剔除了重复的问题。最后,得到了一个包含 1,614 个问答对的数据集。我们将这个数据集随机分成了 90% 的训练集和 10% 的验证集。
3.2 LLM 微调
使用 QLoRA(Hugging Face 'peft' 库)对基本的 LLM 模型,在 Q&A 指令数据集上进行训练。微调过程在 4 个内存为 24G 的 Quadro RTX 6000 GPU 的设备上进行。
3.3 实体树
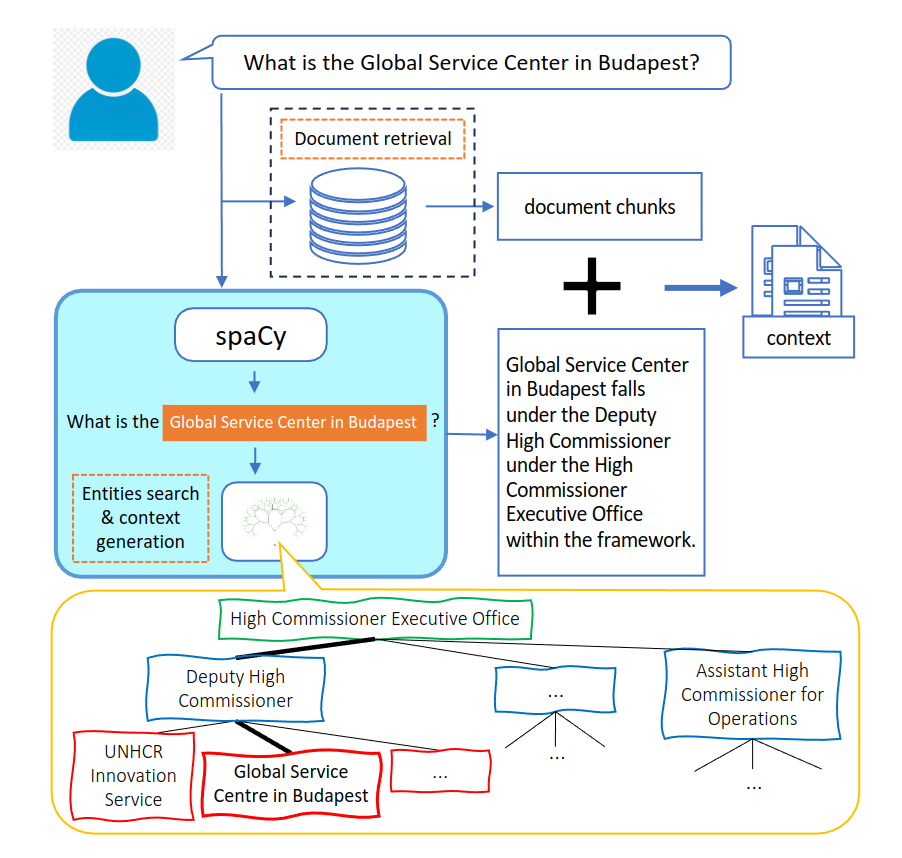
实体树包含了组织内实体及其在层次结构中位置的信息。好像树中,每个节点都代表一个实体,父节点表示它所在的组。例如,在图 2 所示的难民署组织结构中,难民署创新处是隶属于副高级专员的一个实体。
在检索过程中,实体树被用来增强向量数据库检索到的上下文。解析器模块会在用户查询中寻找与组织内实体名称匹配的关键字。如果找到匹配项,就会从树中提取有关每个匹配实体的信息,并将其转换为文本语句,这些语句提供了关于实体及其在组织层次结构中的位置的信息。然后,这些信息会与从向量数据库中检索到的文档块结合起来,形成上下文。这样,当用户询问有关实体的问题时,模型就能访问到有关实体及其在组织层次结构中位置的信息。
3.4 配置
在本地部署应用程序时,使用 Llama-2 模型,并采用 Chroma DBvector 数据库来存储文档块以进行上下文检索。
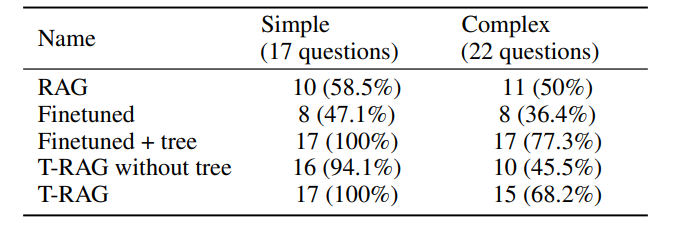
表 -2 展示了几种实验配置,其中,第二行的 Finetuned 在提问时并未使用上下文。而第三行的 T-RAG 则使用了来自两个来源的上下文信息:从原始文档生成的指令数据集中的问题和答案对,以及树上下文,该上下文为用户查询中提到的实体提供从实体树中提取的信息。

4 实验结果
4.1 效果评估
采用自动和人工方式来评估语言模型(LLMs)。在自动评估中,使用 GPT-4 语言模型作为评估工具。研究表明,语言模型的评估结果与人类对各种任务的评估结果是一致的。
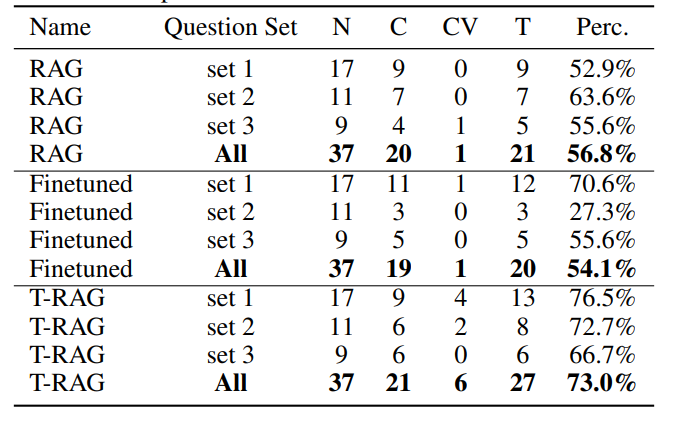
表 -3 中 N 代表每组问题的数量,将回答手动评分为"正确"(C),"正确但冗长"(CV)。T 是回答正确的总数(T = C + CV)。可以看出,尽管 T-RAG 的效果较好,但它有可能生成冗长的答案(测试数据不多)。
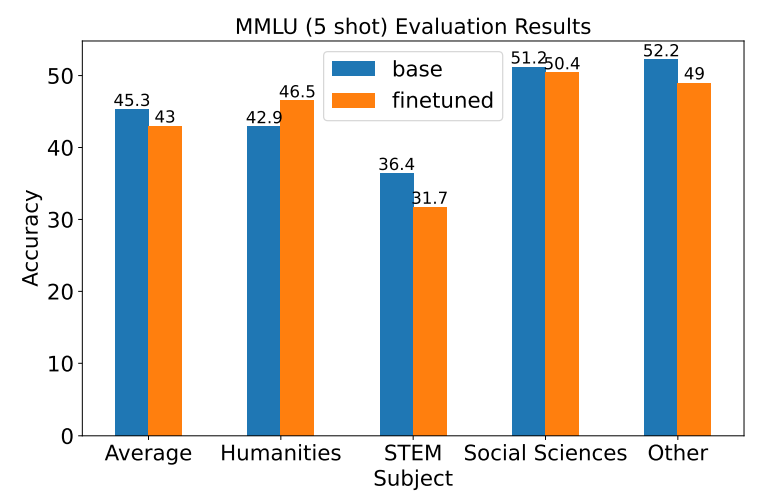
4.2 微调模型后过拟合
模型微调可能导致模型忘记其在训练前所学习的内容。为了评估过拟合情况,使用了大规模多任务语言理解(MMLU)基准测试来对比微调前后的效果。结果显示,其影响较小。
5 经验教训总结
- 虽然构建一个初始的 RAG 应用程序很容易,但要使其健壮并非易事,需要领域知识专家的帮助,并需要做出许多设计选择以优化系统的不同组件。
- 微调的模型可能对问题的措辞敏感。
- 通过将信息纳入模型的参数,微调模型可以节省 LLM 的有限上下文窗口的空间,从而减少所需的上下文量。
- 在系统开发的各个阶段,让最终用户参与测试可以生成反馈,帮助引导开发过程中的决策。
- 树提供了一个适合表示层次信息(如组织中的实体)的结构,可以用来增强上下文。
6 相关论文
- 先抽象再提问的另一种方法:论文阅读_提示工程_通过抽象激发大模型的推理能力