论文地址:https://jt-zhang.github.io/files/TurboDiffusion_Technical_Report.pdf
项目地址:https://github.com/thu-ml/TurboDiffusion
发表时间:2025年12月18日
内容由豆包ai总结
本文是由清华大学、生数科技(VIDU)和加州大学伯克利分校联合发表的TurboDiffusion技术报告,该框架实现了视频扩散模型端到端生成速度100-200倍的提升,且能保持视频生成质量,核心通过注意力加速、步数蒸馏、量化等技术结合算法与系统协同优化实现,在多款Wan系列视频扩散模型上的实验验证了其高效性与实用性。
TurboDiffusion与FastVideo相比,尤其是在1.3b模型上效果更优,这表明rCM蒸馏效果优于VSA+DMD蒸馏;同时在推理耗时上,是fastvideo的30~40%左右,表明SageSLA在RTX 5090显卡加速效果比VSA更佳。
摘要
TurboDiffusion是一款视频生成加速框架,在单张RTX 5090 GPU上,对Wan2.2-I2V-A14B-720P、Wan2.1-T2V-1.3B-480P等多款视频扩散模型实现100-200倍的生成速度提升,同时保证视频质量与原模型相当。其加速核心操作包括:
- 低比特SageAttention
- 可训练稀疏线性注意力(SLA)的注意力加速方案
- 基于rCM的高效步数蒸馏
- 将模型参数和激活量化为8位的W8A8量化(加速线性层并压缩模型)。
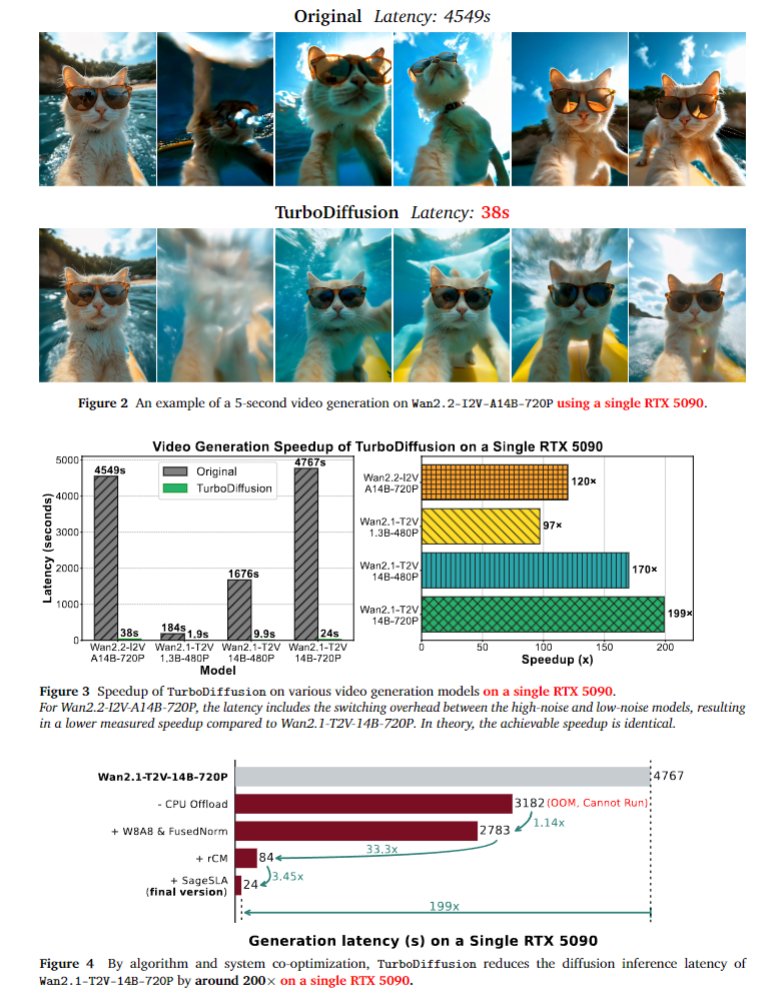
论文还提供了包含模型检查点、训练和推理代码的GitHub仓库,且展示了典型模型的生成延迟对比,如Wan2.1-T2V-1.3B-480P原模型生成5秒视频需184s,TurboDiffusion仅需1.9s。

1 方法
本节从核心技术、训练流程、推理阶段加速细节三个方面,详细阐述了TurboDiffusion的实现方案,是框架实现加速的核心理论与操作基础。
1.1 主要技术
TurboDiffusion融合四种核心技术实现扩散模型加速,各技术相互配合形成叠加加速效果:
- 低比特量化注意力加速:采用SageAttention2++变体,实现低比特量化下的注意力计算加速;
- 稀疏注意力加速:引入稀疏线性注意力(SLA),其稀疏计算与低比特张量核心加速相正交,可在SageAttention基础上实现累积加速;
- 步数蒸馏:使用当前 sota 的扩散蒸馏方法rCM,减少采样步数,且通过模型权重融合,天然继承注意力层面的加速效果;
- 线性层量化:采用W8A8量化,将数据类型设为INT8,以128×128为块粒度进行量化,实现线性层加速。
1.2 训练
基于预训练的视频扩散模型,TurboDiffusion采用并行+融合的训练流程,具体步骤为:
- 将原模型的全注意力替换为SLA,并对预训练模型微调以适配稀疏性;同时,利用rCM将预训练模型蒸馏为采样步数更少的学生模型;
- 将SLA微调与rCM训练得到的参数更新融合,得到单一的加速模型;
- 训练过程可灵活使用真实数据或合成数据,详细实现见项目GitHub代码。
1.3 推理
针对经SLA和rCM训练后的模型,TurboDiffusion在推理阶段叠加多重工程优化,进一步降低延迟,具体操作:
- 注意力加速:将SLA替换为SageSLA(基于SageAttention的SLA CUDA实现),充分利用硬件算力;
- 步数蒸馏落地:将采样步数从原有的100步大幅缩减至3或4步(实践中推荐4步以保证最佳画质);
- 线性层量化部署:先将线性层参数以128×128块粒度量化为INT8,推理时将线性层激活值以相同粒度量化为INT8,并利用INT8张量核心完成计算,此举使模型体积压缩约一半,同时提升线性层计算速度;
- 其他工程优化:基于Triton或CUDA重新实现LayerNorm、RMSNorm等操作,提升计算效率。
2 评估
本节通过设定标准化的实验环境,从效率和生成质量两方面,在多款Wan系列模型上对TurboDiffusion进行全面评估,并与原模型、FastVideo基线模型对比,验证其优越性。
2.1 实验设置
- 评估模型与基线:测试模型为Wan2.2-I2V-A14B-720P、Wan2.1-T2V-1.3B-480P、Wan2.1-T2V-14B-720P、Wan2.1-T2V-14B-480P;基线为Wan模型官方实现(Original)和FastVideo框架,其中FastVideo未提供Wan2.2-A14B-I2V-720P的加速版本,该模型仅对比TurboDiffusion与原模型。
- 超参数设置:TurboDiffusion的Top-K比率设为0.1(对应90%注意力稀疏性),采样步数3步,实践推荐Top-K在0.1,0.15、采样步数4步以保证最佳画质;FastVideo使用官方默认参数(3步采样、80%注意力稀疏性)。
- 硬件环境:主推理实验在单张RTX 5090 GPU上完成,同时在RTX 4090、H100等GPU上也实现了显著加速(加速比略低于RTX 5090)。
- 效率评估指标:报告端到端扩散生成延迟,排除文本编码和VAE解码阶段的耗时。
2.2 效率与质量
实验结果表明,TurboDiffusion在实现最高加速效率的同时,能保持与原模型相当的视频生成质量,显著优于FastVideo基线模型,以下为各模型的核心实验数据与结论:
- Wan2.2-I2V-A14B-720P :生成5秒视频,原模型延迟4549s,TurboDiffusion仅38s,加速比120×;因包含高低噪声模型切换开销,实测加速比略低,理论上与同量级模型加速比一致,且在各类复杂文本/图像提示下,均能高质量还原场景。对于高难度场景生成能力下降
- Wan2.1-T2V-1.3B-480P :生成5秒视频,原模型184s,FastVideo 5.3s,TurboDiffusion 1.9s,加速比97×,在赛博朋克、超现实主义、3D场景等多种风格提示下,画质有损失,且速度远快于FastVideo。不太适用,但优于FastVideo
- Wan2.1-T2V-14B-720P :生成5秒视频,原模型4767s,FastVideo 72.6s,TurboDiffusion 24s,加速比199×,是加速效果最优的模型,在写实、游戏、纪录片等风格下均表现优异。存在细微效果下降
- Wan2.1-T2V-14B-480P :生成5秒视频,原模型1676s,FastVideo 26.3s,TurboDiffusion 9.9s,加速比170×,在动漫、游戏等场景中,画质与原模型匹配,速度显著领先FastVideo。存在效果下降
此外,论文通过算法与系统协同优化的拆解实验,展示了Wan2.1-T2V-14B-720P的加速过程:从CPU卸载仅1.14×加速,到叠加W8A8量化+融合归一化达33.3×,再叠加rCM达约114×,最终叠加SageSLA实现199×的最终加速,验证了各技术模块的叠加加速效果。
2.3 效果图片
wan2.2-I2V-A14B-720p
画面提示词为第一帧,文本提示词为:"主观视角自拍视频,画面极度混乱且节奏极快。一只戴着墨镜的白猫面无表情地站在冲浪板上,突然冲浪板向侧面猛甩,将猫和相机一同甩入水中;镜头急剧向下俯冲,在下沉过程中被汹涌的气泡、旋转的涡流和模糊的水痕吞噬。阴影逐渐加重,水压波纹扭曲了画面边缘,零散的气泡飞速掠过镜头向上浮起,显示相机仍在持续下沉。随后,白猫以爆发性的速度向上蹬水,拖着镜头穿过翻滚的气泡和亮度迅速提升的水域,阳光重新倾泻而下;相机飞速上升,水流从镜头表面滑落,最终在一阵耀眼的光芒和水花中冲破水面,瞬间恢复为歪斜、慌乱的自拍视角,白猫也随之浮出水面。"

画面提示词为第一帧,文本提示词为:"一辆通体无色、外观粗犷的六轮月球车 ------ 悬架臂裸露在外,配有防滚架框架,轮胎宽大且适配低重力环境 ------ 从左至右滑行进入画面,扬起滚滚月尘,尘雾在真空中缓缓飘散。身着白色宇航服的宇航员迈着轻盈、弹跳式的月面步伐,跃上月球车的开放式底盘。远处,一艘采用垂直推进器下降模式的垂直起降(VTOL)着陆器,悄然降落在灰色的月表之上。天地之上,巨大的极光状等离子体光带在繁星密布的天幕中翻涌波动,将摇曳的绿、蓝、紫色光芒投射在荒芜的月原上,为整个场景镀上一层超凡脱俗的奇幻光晕。"

画面提示为第一帧,文本提示为:"乌玛・瑟曼饰演的碧翠丝・基多在电影感的光影中,稳稳握着她那把锋利如剃刀的武士刀。毫无征兆地,整把金属刀身瞬间失去坚硬质感,刀体如不稳定的液体般颤动。刀身表面彻底失稳 ------ 一块块金属以缓慢的褶皱状下坠脱落,化作银浆细流一滴滴缓缓淌下。片刻之间,这把刀便坍缩成一团毫无形状的金属熔物,棱角尽失,结构全无。浓稠的液态金属从她的手中溢出,紧接着,一片片泛着微光的液膜剥落坠地。她此刻手中仅剩一团颤巍巍、形似水银的液状物,不住地垂落、滴淌。当刀身最后的固态残体消融、碎裂 ,从她指缝间流尽时,她的神情也从沉着戒备转为震惊错愕,陷入手无寸铁、茫然无措的境地。"

画面提示为第一帧,文本提示为:"特写镜头对准一位老水手,他身着饱经风霜的黄色雨衣,坐在沐浴着阳光、轻轻摇晃的双体船甲板上。船身每一次微微起伏,他脸上的光影便悄然变幻。他吸了一口烟斗,烟锅里的火星骤然亮了几分,呼出的一缕青烟随船身的晃动袅袅摇曳、曲折飘散。他的猫卧在身旁,双眼半阖,每当甲板倾斜,猫咪的身体便会顺着本能轻柔地调整姿态。阳光在光洁的木质甲板上跃动闪烁,船下的海面碧波翻涌,映出片片倏忽晃动的粼粼光斑。一对海鸟从头顶滑翔而过,遇风时微微低掠。镜头缓缓向前推近,所有的动静都愈发清晰 ------ 青烟轻颤,猫毛微扬,船身每一次轻晃都伴着甲板的吱呀轻响 ------ 这静谧的瞬间,就此化作海上鲜活灵动的一幕。"

画面提示为第一帧,文本提示为:"雨夜的东京街头,一名身着风衣、手持黑伞的男子步履匆匆,急切地穿行其间,大步踏过水洼,溅起阵阵水花。手持跟拍镜头从侧后方追拍他,画面晃动急促,仿佛拼尽全力才堪堪跟上他的脚步。镜头焦点始终锁定在男子身上,而霓虹招牌因快速移动拖曳出一道道斑斓的焦外光轨。整幕场景透着赛博朋克与黑色电影的氛围感 ------ 神秘、孤寂,又带着一丝焦躁不安。湿滑的路面倒映着绚烂的霓虹光影,雨滴凌厉地划过画面,一层薄雾缓缓飘动;男子迈着坚定的快步奋力前行,周遭的一切都随他的脚步而动。"

wan2.1-T2V-1.3B-480p
一位时髦女子漫步在东京街头,霓虹灯璀璨温暖,城市标识跃动生辉。她身着黑色皮夹克,搭配红色长裙与黑色靴子,手提黑色手提包,戴着墨镜,唇上涂着红色口红。她步伐从容自信,举手投足间尽显从容。湿漉漉的街道在灯光映照下泛着镜面般的光泽,五彩斑斓的霓虹灯在光线下熠熠生辉。行人络绎不绝,熙熙攘攘。

摄像机在纽约某大型博物馆展厅内旋转,环绕着一排排复古电视机,每台电视都播放着不同的节目:1950年代的科幻片、恐怖片、新闻、静电画面,以及1970年代的情景喜剧等。



Wan2.1-T2V-14B-720P


Wan2.1-T2V-14B-480P

3 结论
TurboDiffusion融合低比特注意力(SageAttention)、稀疏线性注意力(SLA)、rCM步数蒸馏、W8A8量化及多项工程优化,实现了视频扩散模型端到端100-200倍的加速,且画质损失可忽略不计。在单张RTX 5090 GPU上,该框架将多款大尺度视频扩散模型的5秒视频生成时间降至1分钟内,大幅提升了高质量视频生成的效率与实用性,解决了传统视频扩散模型生成速度慢的核心痛点。