介绍
sqoop是隶属于Apache旗下的, 最早是属于cloudera公司的,是一个用户进行数据的导入导出的工具, 主要是将关系型的数据库(MySQL, oracle...)导入到hadoop生态圈(HDFS,HIVE,Hbase...) , 以及将hadoop生态圈数据导出到关系型数据库中
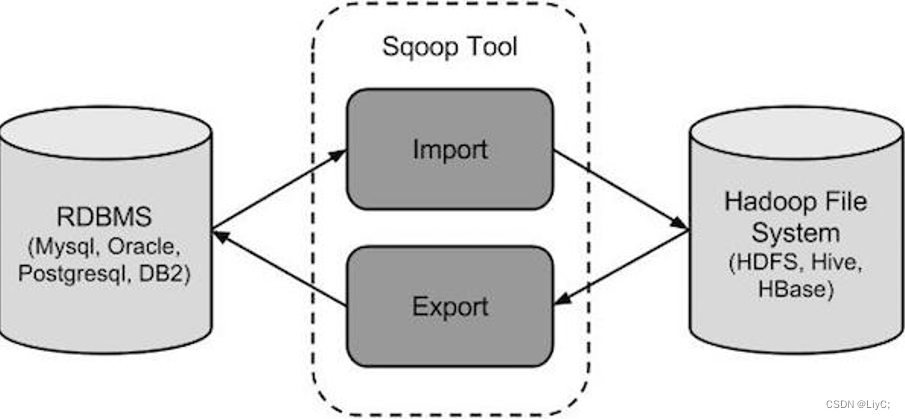
操作
将数据从mysql中导入到HDFS中
1.全量导入
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/test \
--username root \
--password 123456 \
--table emp \
--fields-terminated-by '\001' \
--delete-target-dir \
--target-dir '/sqoop_works/emp_1' \
--split-by id \
-m 2 相关参数:
- --connect:连接关系型数据库的URL
- --username:连接数据库的用户名
- --password:连接数据库的密码
- --table:指定使用该数据库的表
- --fields-terminated-by:设置分隔符
- --delete-target-dir:删除目标地址中的文件夹
- --target-dir:导入在HDFS中的地址
(选用)需要两个一起使用,即在/sqoop_works/emp_1目录下导入数据,如果这个目录之前有数据了,则删除原来的数据再导入。
- --split-by:按照属性切割数据
- -m:设置map数量
(选用)需两个一起使用,即按照id对数据进行切割,结果分为两份。
结果:
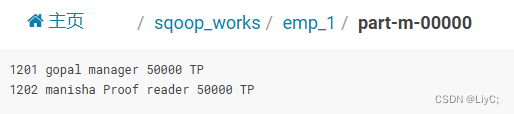
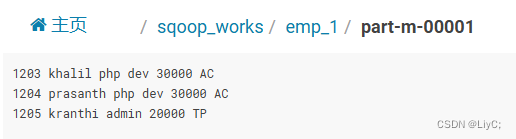
2.条件导入
基于全量导入,在语句中写上--where(条件)或--query(SQL语句)
例如:
--where 'id > 1205'
或者:
--query 'select deg from emp where 1=1 AND $CONDITIONS'
CONDITIONS是一个占位符,通常用来动态添加条件。在实际使用中,CONDITIONS会被替换为具体的条件语句,比如WHERE子句中的具体条件,以实现更灵活的查询功能。
将数据从mysql中导入到Hive中
1.全量导入
sqoop import \
--connect jdbc:mysql://192.168.52.150:3306/test \
--username root \
--password 123456 \
--table emp_add \
--hcatalog-database hivesqoop \
--hcatalog-table emp_add_hive \与导入到HDSF类似,只是导入到的地方不同
- --hcatalog-database:指定数据库名称
- --hcatalog-table:指定表名
上述代码功能为:把msql中的test数据库emp_add表的数据导入到Hive中hivesqoop数据库中的emp_add_hive表
2.条件导入
同样的也是加--where(条件)或--query(SQL语句)
将数据从Hive导出到msql中
语句如下:
sqoop export \
--connect jdbc:mysql://192.168.52.150:3306/test \
--username root \
--password 123456 \
--table emp_add_mysql \
--hcatalog-database hivesqoop \
--hcatalog-table emp_add_hive \和导入类似,只是把sqoop import换成了sqoop export
导出数据的时候,必须先在mysql中创建表才可以将数据导入到这个表里面