注意:该项目只展示部分功能,如需了解,文末咨询即可。
本文目录
- [1 开发环境](#1 开发环境)
- [2 系统设计](#2 系统设计)
- [3 系统展示](#3 系统展示)
- [3.1 功能展示视频](#3.1 功能展示视频)
- [3.2 大屏页面](#3.2 大屏页面)
- [3.3 分析页面](#3.3 分析页面)
- [3.4 数据管理页面](#3.4 数据管理页面)
- [4 更多推荐](#4 更多推荐)
- [5 部分功能代码](#5 部分功能代码)
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
在当今竞争激烈的零售行业中,尤其是在快节奏的时尚精品领域,数据已成为驱动业务增长和提升决策质量的核心资产。传统的零售管理模式往往依赖于经验和直觉,难以应对瞬息万变的市场需求、复杂的库存动态以及消费者日益个性化的偏好。随着大数据时代的到来,零售商积累了海量的销售、产品及客户行为数据,但这些数据往往分散、未经处理,其潜在价值未能被充分挖掘。因此,开发一个能够整合、处理并深度分析这些海量数据的系统,对于零售时尚精品店实现精细化运营、优化供应链管理、提升客户满意度以及最终增强市场竞争力具有极其重要的现实意义和商业价值。本系统旨在利用大数据技术,将原始的销售数据转化为直观的业务洞察,帮助企业从宏观销售趋势到微观产品特性等多个层面做出数据驱动的科学决策,从而在激烈的市场竞争中占得先机。
基于上述技术,本系统将重点研究并实现四大核心功能模块,以满足零售时尚精品店的数据分析需求。
1.数据预处理与集成模块:此模块是所有分析的基础。它负责从HDFS读取原始的-数据,并进行一系列精细化的预处理操作。
2.多维度销售分析模块:该模块聚焦于销售业绩的全面洞察,是系统的核心分析部分。具体分析维度包括:
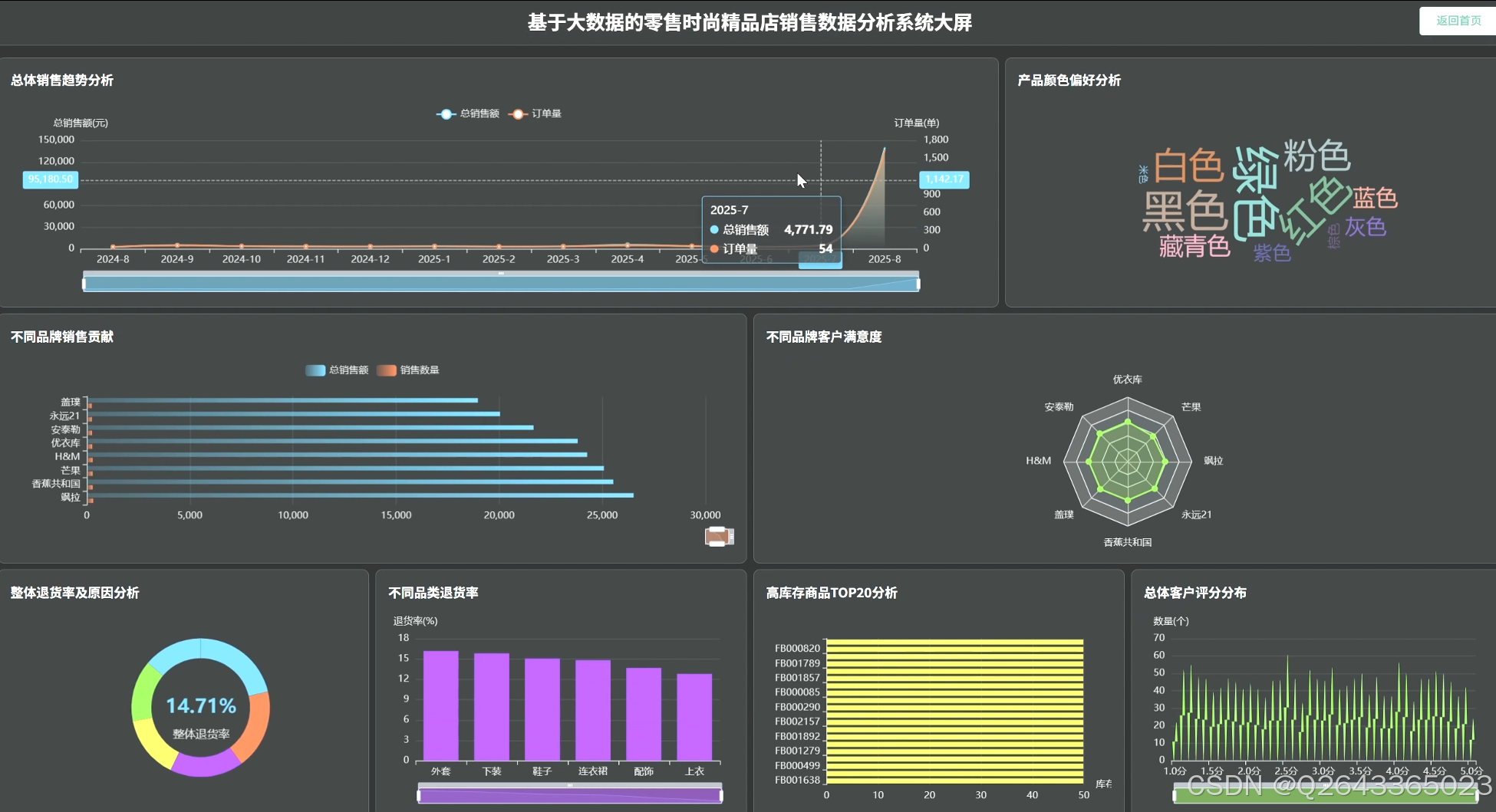
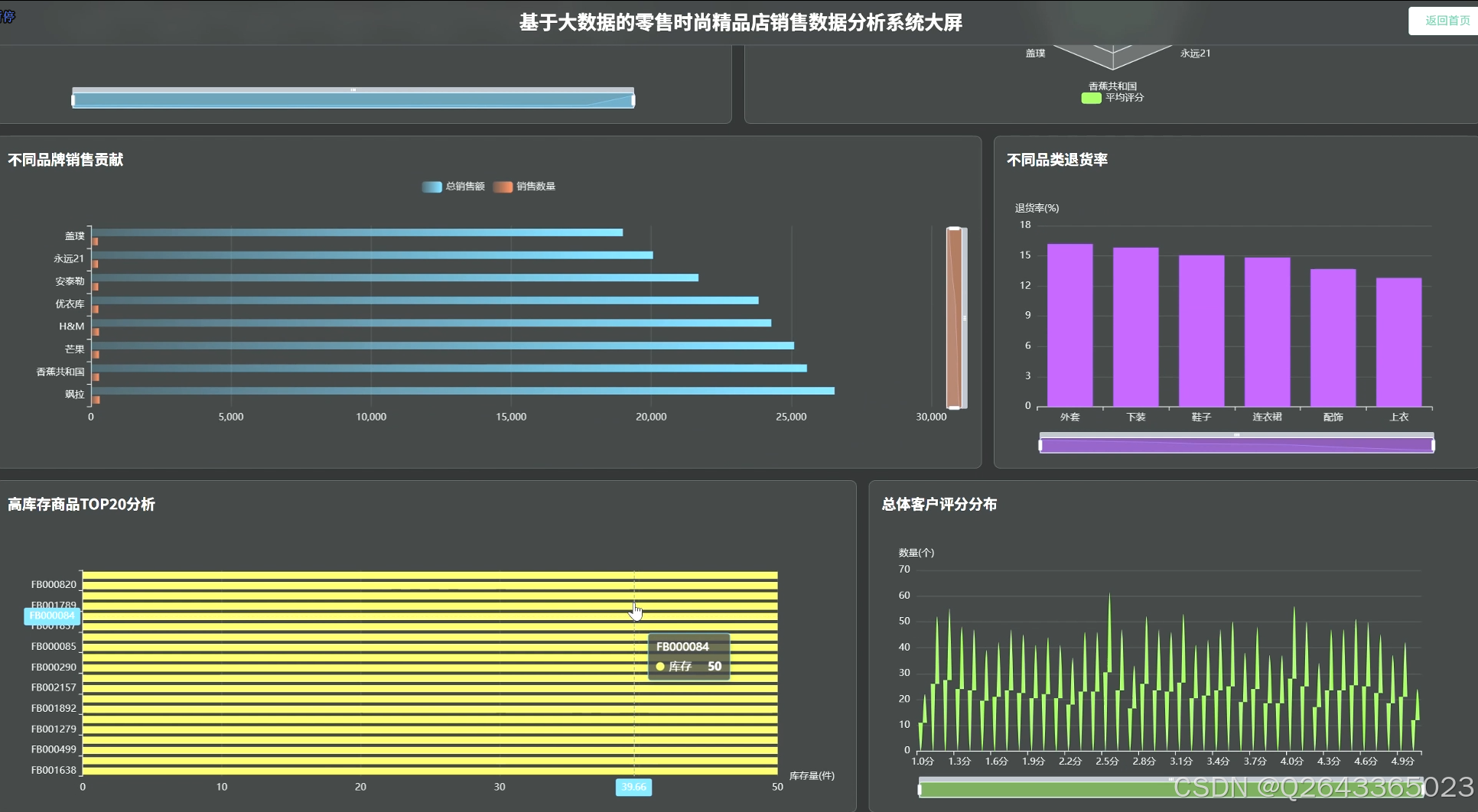
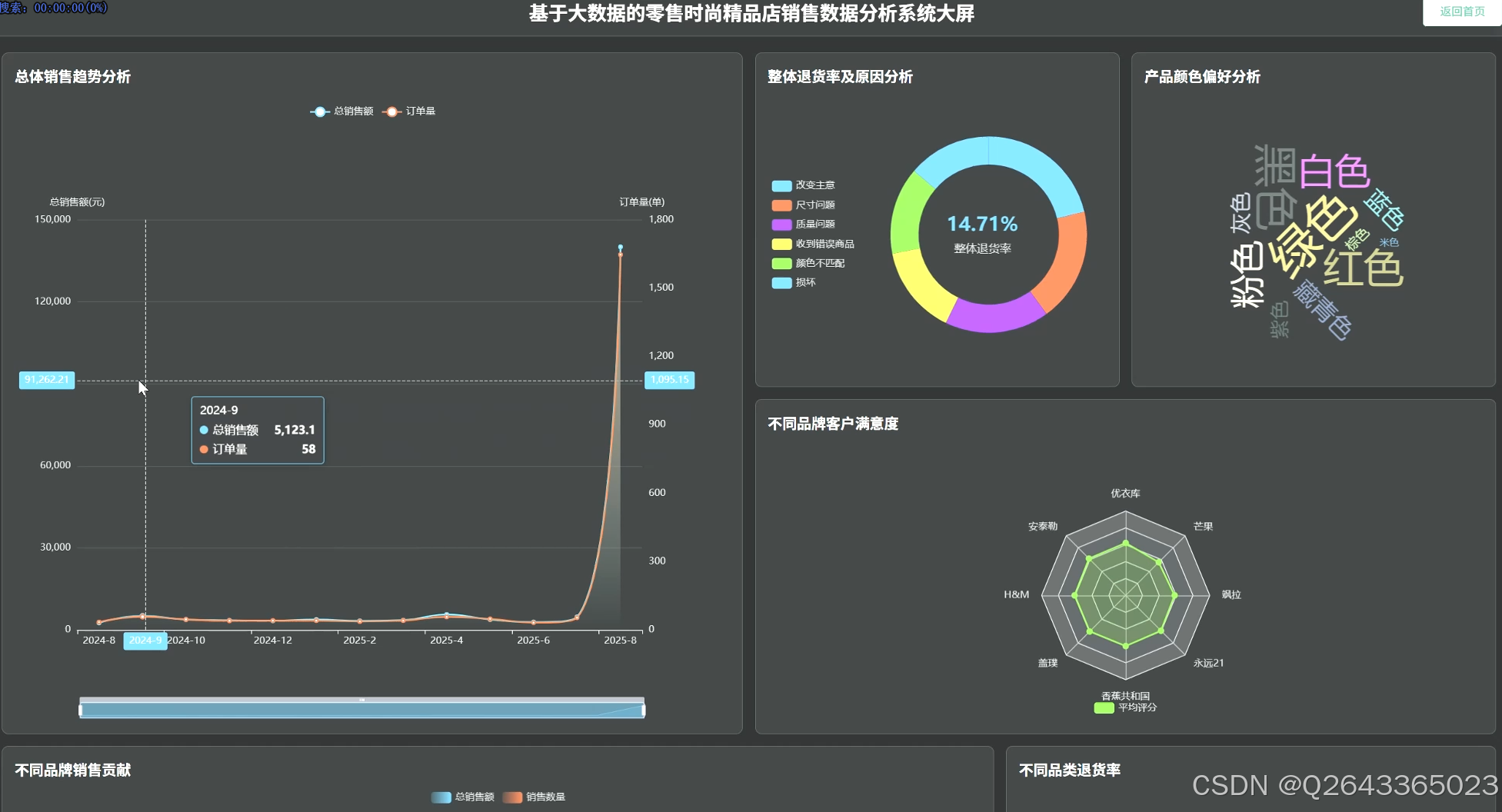
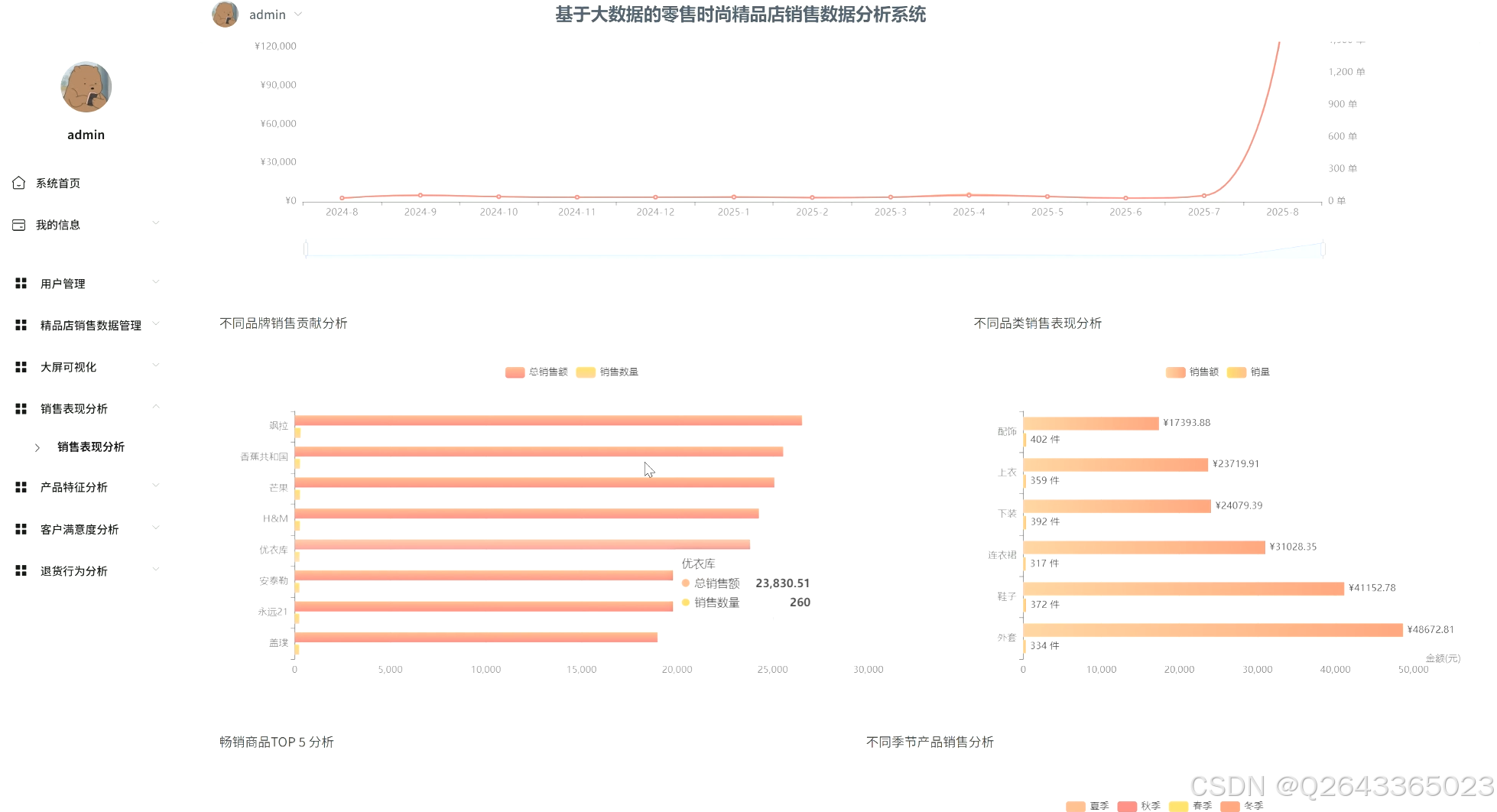
3.业绩分析:通过对销售额和订单量的按月/季统计,分析总体销售趋势;深入到不同品类、品牌及季节性产品的销售贡献度分析;并挖掘TOP N畅销商品。
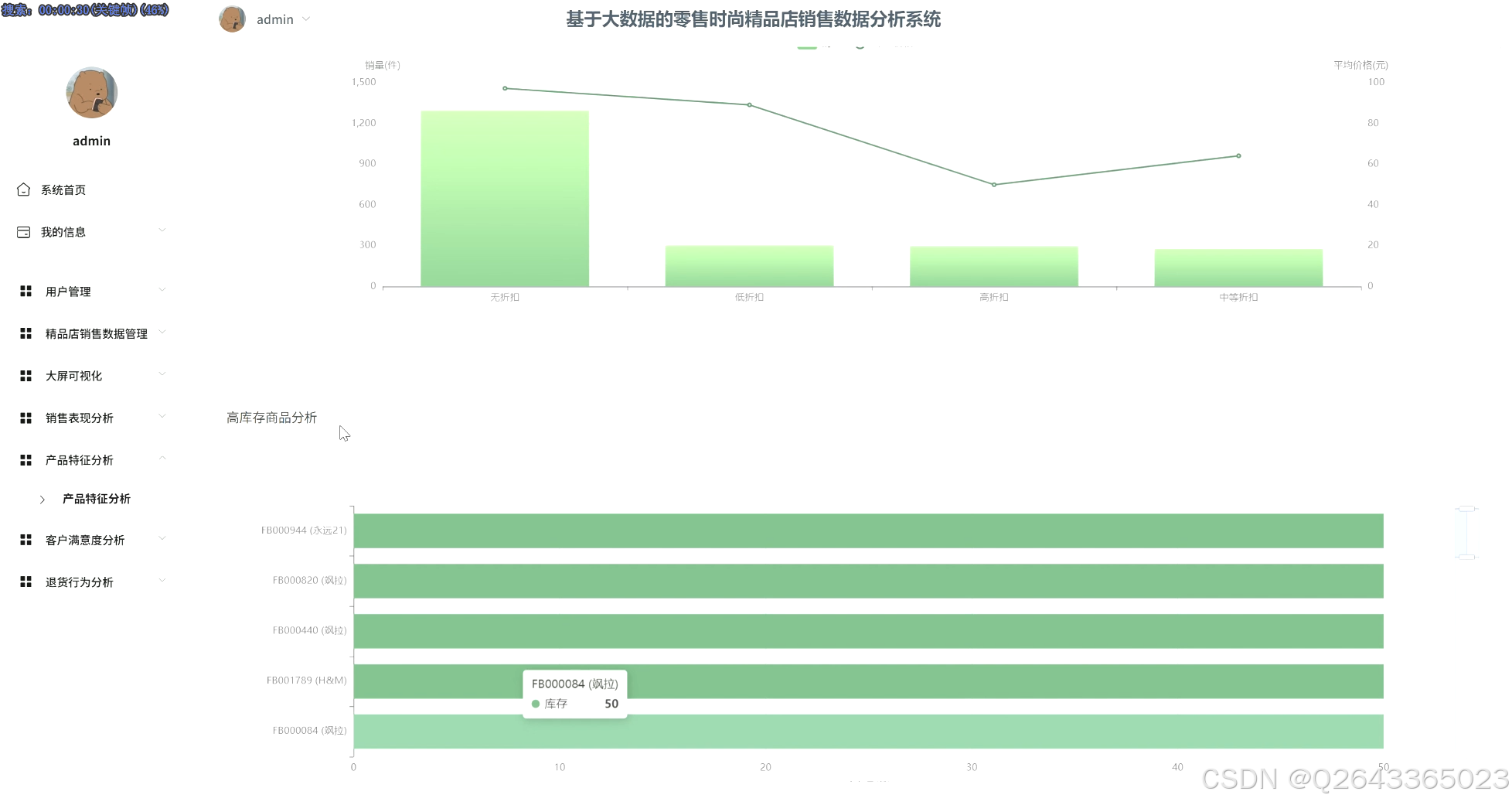
产品特性分析:从消费者偏好出发,分析最受欢迎的产品颜色与尺码;通过关联分析,评估价格与折扣策略对销量的影响;并识别高库存商品,进行库存与销售关联分析以预警积压风险。
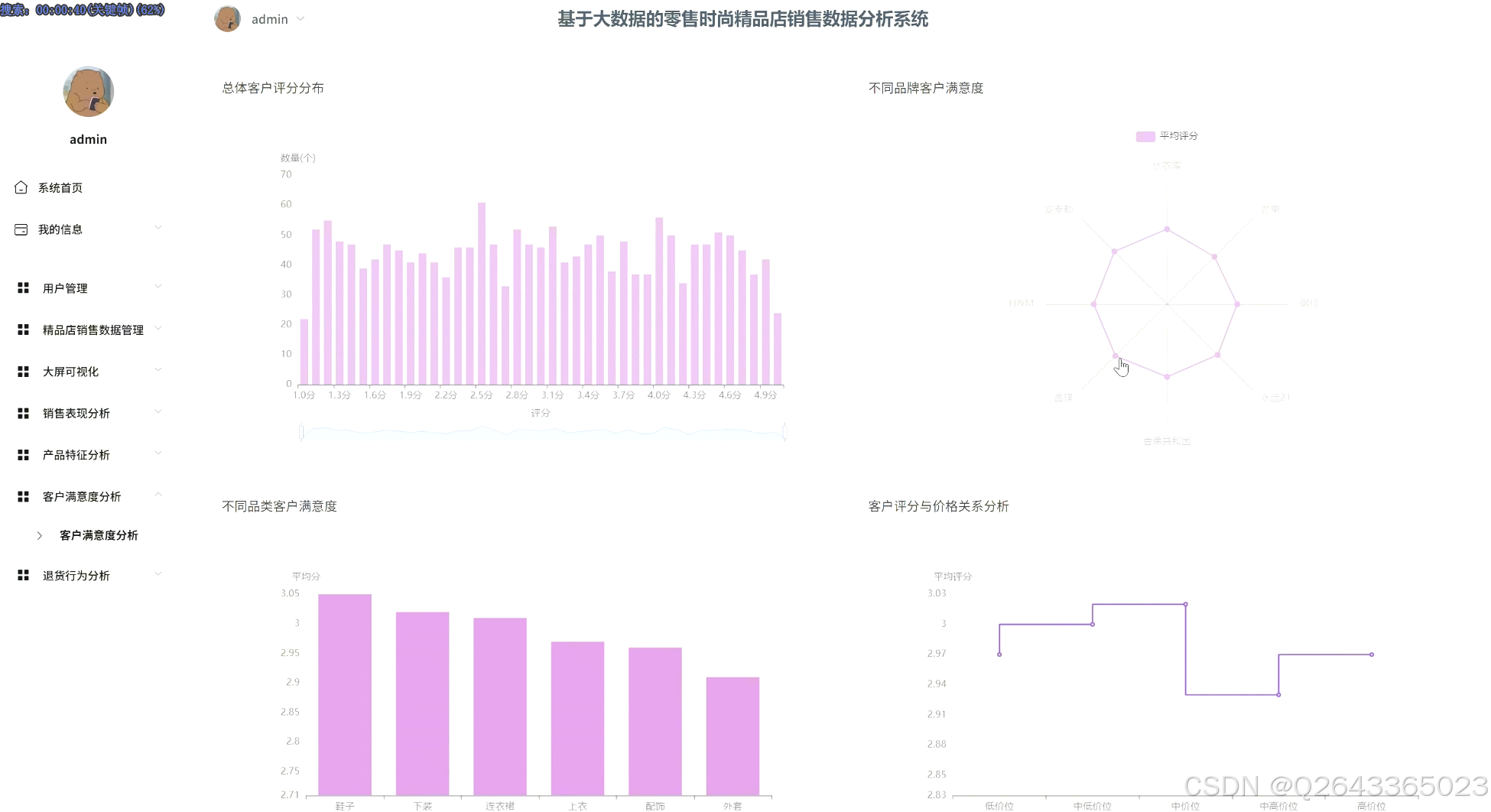
客户满意度分析:通过分析总体客户评分、对比不同品类/品牌的满意度,并深入挖掘低分产品的共同特征,以及探究评分与价格的关系,全面评估产品口碑。
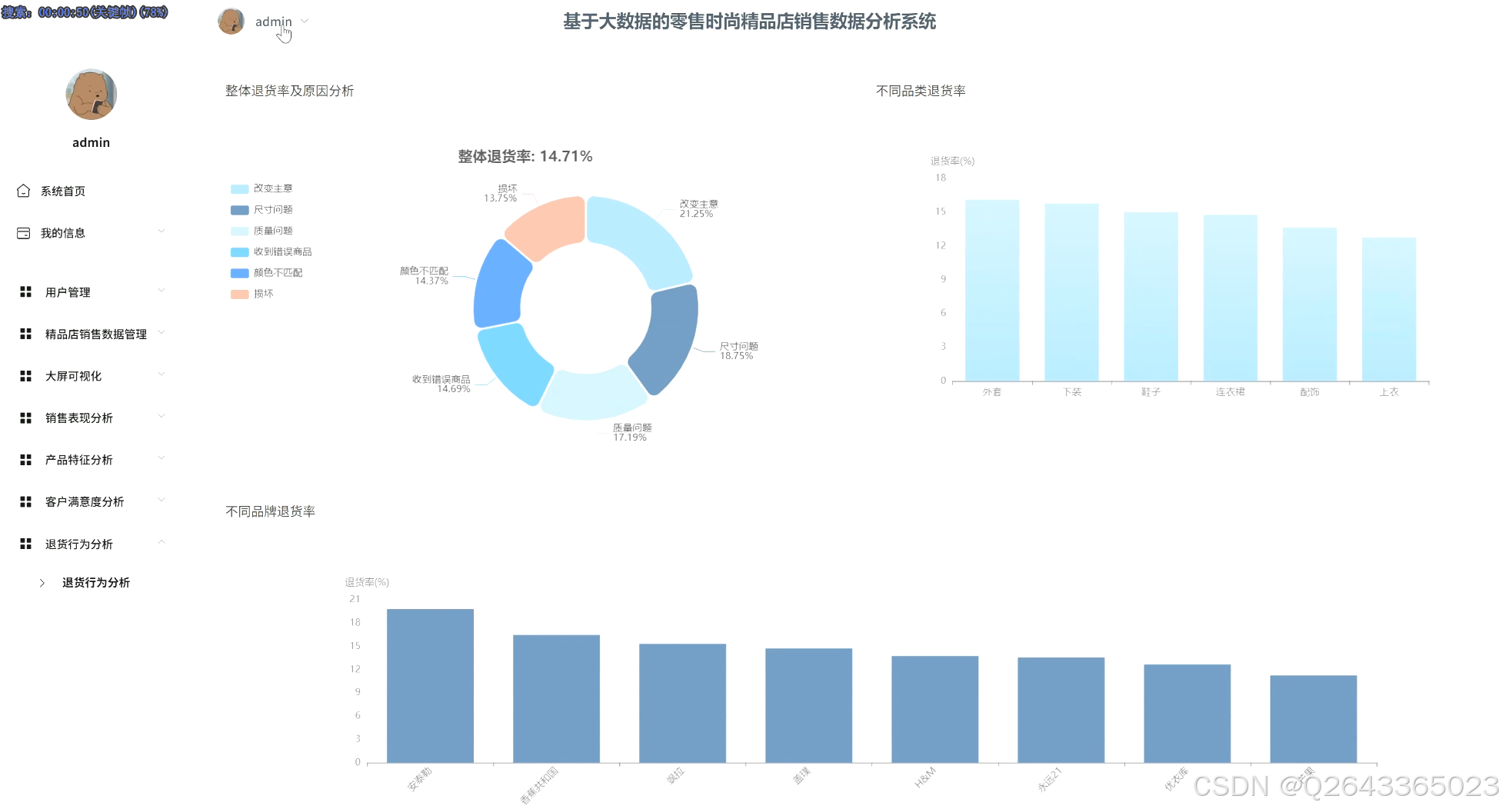
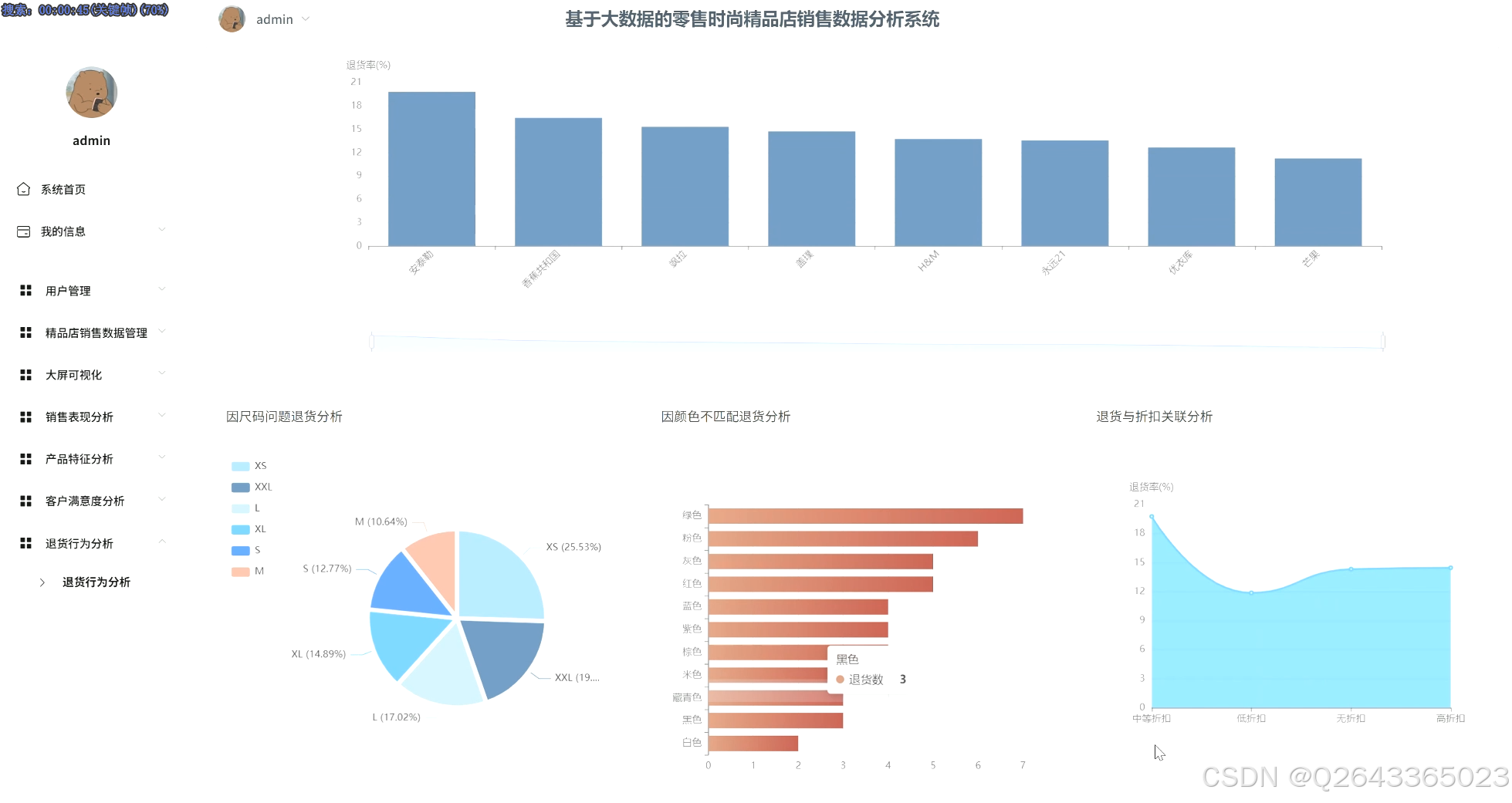
退货行为分析:计算整体退货率并溯源退货原因;横向对比不同品类/品牌的退货率差异;并进一步下钻,分析退货行为与产品尺码、颜色、价格等具体属性的深层关联。
数据可视化展示模块:此模块负责将上述所有分析维度的结果,通过ECharts图表进行直观呈现。系统将设计多个主题分析看板(如销售业绩看板、产品洞察看板等),并通过组合不同类型的图表,动态展示销售趋势、品类占比、品牌贡献、颜色偏好、退货原因构成等关键指标,最终将核心图表集成为一个综合性的数据驾驶舱(大屏)。
4.系统管理与交互模块:为保证系统的可用性和安全性,该模块将实现标准的用户注册登录功能和权限管理。同时,为管理员提供一个后台数据管理界面,支持对录入系统的数据进行增、删、改、查等基本操作,确保数据的可维护性。
3 系统展示
3.1 功能展示视频
基于hadoop大数据的零售时尚精品店销售数据分析系统源码 !!!请点击这里查看功能演示!!!
3.2 大屏页面
3.3 分析页面
3.4 数据管理页面

4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
紧跟风口!2026计算机毕设新赛道:精选三大热门领域下的创新选题, 拒绝平庸!毕设技术亮点+功能创新,双管齐下
纯分享!2026届计算机毕业设计选题全攻略(选题+技术栈+创新点+避坑),这80个题目覆盖所有方向,计算机毕设选题大全收藏
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
5 部分功能代码
python
APP_NAME = "FashionBoutiqueSalesAnalysis"
HDFS_DATA_PATH = "hdfs://localhost:9000/dataset/fashion_boutique_dataset.csv"
LOCAL_OUTPUT_DIR = "output/sales_analysis_results"
def create_spark_session(app_name):
"""创建并返回一个SparkSession对象"""
return SparkSession.builder \
.appName(app_name) \
.config("spark.driver.memory", "4g") \
.getOrCreate()
def save_analysis_result(df, file_name):
"""
将分析结果的Spark DataFrame保存为单个CSV文件。
使用 toPandas() 是为了确保输出是单个文件,便于前端或数据库导入。
在生产级别的大数据场景下,通常会直接写入分布式数据库或数据仓库。
"""
if not os.path.exists(LOCAL_OUTPUT_DIR):
os.makedirs(LOCAL_OUTPUT_DIR)
output_path = os.path.join(LOCAL_OUTPUT_DIR, file_name)
print(f"正在保存分析结果到: {output_path}")
pandas_df = df.toPandas()
pandas_df.to_csv(output_path, index=False, encoding='utf-8-sig')
print("保存成功。")
print(f"\n--- {file_name} 分析结果 ---")
print(pandas_df.to_string())
print("-----------------------------------\n")
def preprocess_data(spark, hdfs_path):
"""
数据预处理函数,负责加载、清洗和转换数据。
"""
print("开始加载并预处理数据...")
df = spark.read.csv(hdfs_path, header=True, inferSchema=True)
# 1. 数据类型转换:将日期字符串转为日期类型,并提取年份和月份用于后续分析
df = df.withColumn("purchase_date", col("purchase_date").cast("timestamp"))
df = df.withColumn("sale_year", year(col("purchase_date")))
df = df.withColumn("sale_month", month(col("purchase_date")))
# 2. 缺失值处理:根据业务逻辑填充缺失值
df = df.withColumn("size", when(col("category") == "Accessories", "通用尺码").otherwise(col("size")))
df = df.fillna({"customer_rating": 0.0, "return_reason": "未退货"})
# 3. 数据一致性校验/处理:确保 current_price 的准确性
# 此处假设数据是可信的,也可以取消注释以进行强制重算
# df = df.withColumn("current_price", spark_round(col("original_price") * (1 - col("markdown_percentage")), 2))
print("数据预处理完成。")
return df
def sales_trend_analysis(df):
"""
1.1 总体销售趋势分析:按年月统计总销售额和订单量
"""
result_df = df.groupBy("sale_year", "sale_month") \
.agg(
spark_round(spark_sum("current_price"), 2).alias("total_sales"),
count("product_id").alias("order_count")
) \
.orderBy("sale_year", "sale_month")
save_analysis_result(result_df, "sales_trend_analysis.csv")
def category_sales_analysis(df):
"""
1.2 不同品类销售表现分析:统计各品类销售额及占比
"""
# 计算总销售额
total_sales_value = df.select(spark_sum("current_price")).first()[0]
result_df = df.groupBy("category") \
.agg(spark_round(spark_sum("current_price"), 2).alias("category_sales")) \
.withColumn("sales_percentage", spark_round(col("category_sales") / total_sales_value * 100, 2)) \
.orderBy(desc("category_sales"))
save_analysis_result(result_df, "category_sales_analysis.csv")
def top_selling_products_analysis(df, top_n=10):
"""
1.5 畅销商品TOP N分析:按销售额找出最畅销的商品
"""
product_sales = df.groupBy("product_id") \
.agg(spark_round(spark_sum("current_price"), 2).alias("total_sales"))
# 使用窗口函数进行排名
window = Window.orderBy(desc("total_sales"))
result_df = product_sales.withColumn("rank", desc("total_sales")).select(
col("product_id"),
col("total_sales")
).orderBy(desc("total_sales")).limit(top_n)源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓