博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
大数据技术、Spark、Hadoop、Hive、python语言、
requests爬虫技术、
NLP弹幕情感分析、MySQL、Echarts、
基于用户协同过滤推荐算法
Spark哔哩哔哩视频数据分析可视化系统 Hadoop大数据技术 情感分析 舆情分析 爬虫 推荐系统 协同过滤推荐算法 毕业设计
2、项目界面
(1)首页---数据概况
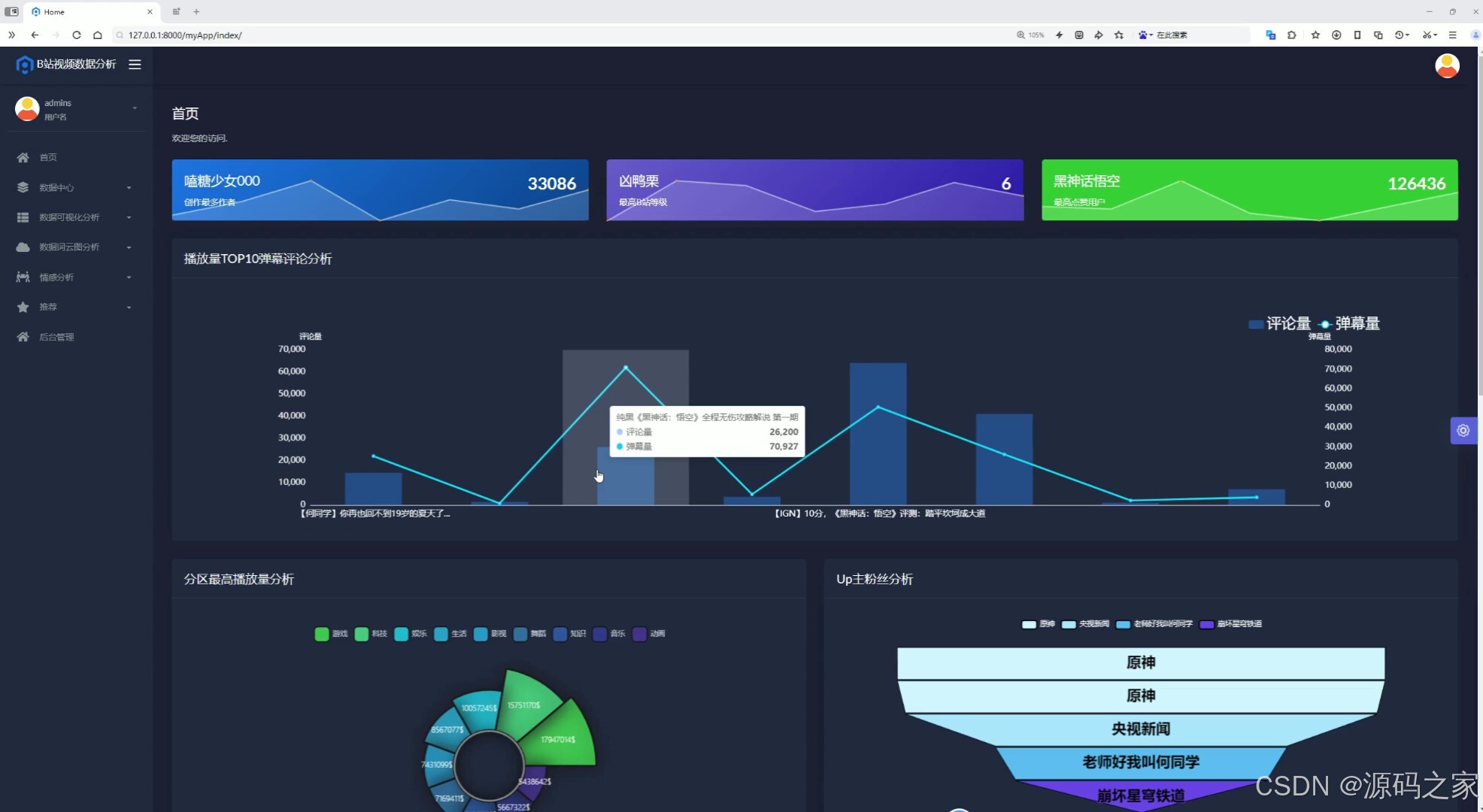
(2)分区播放三连分析
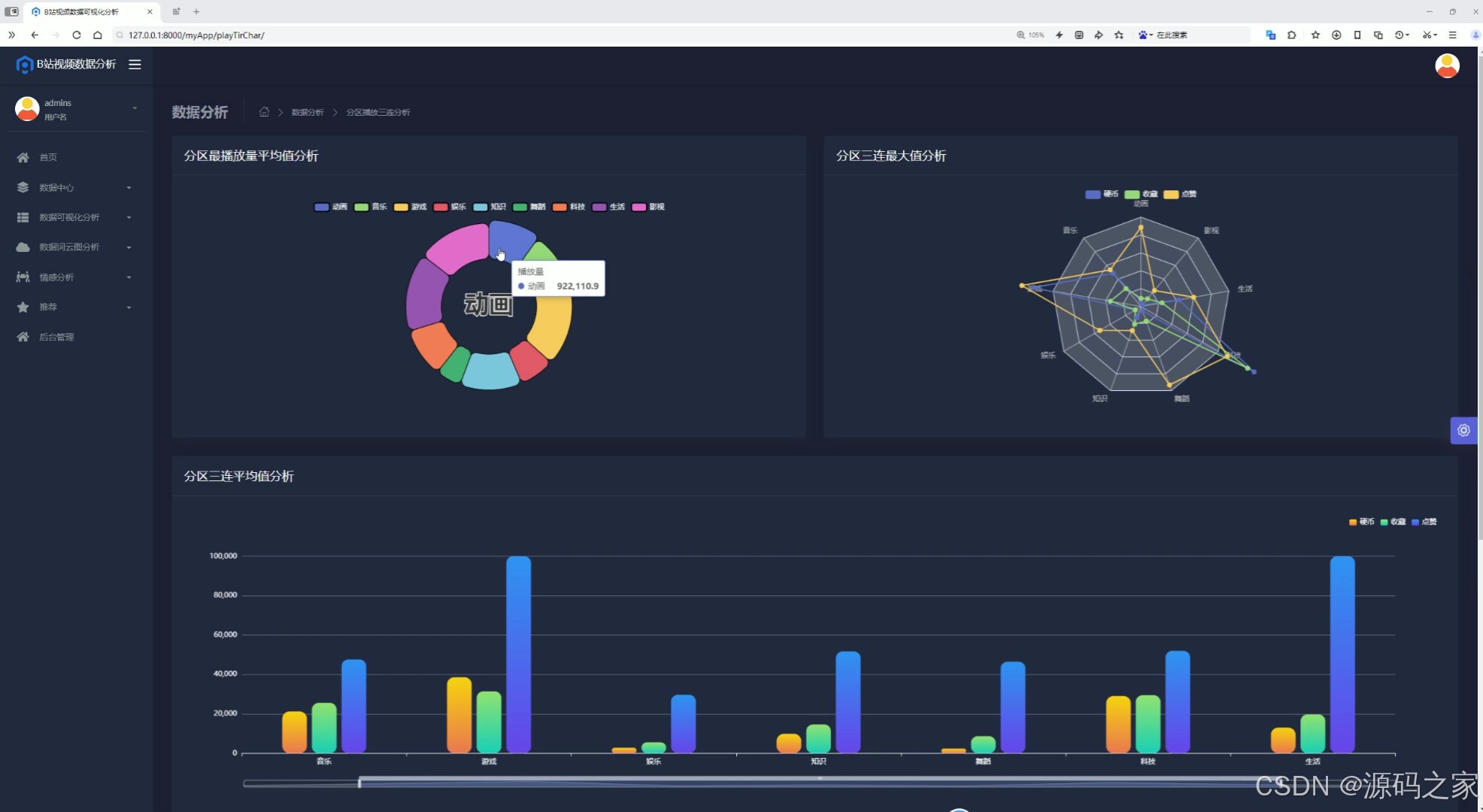
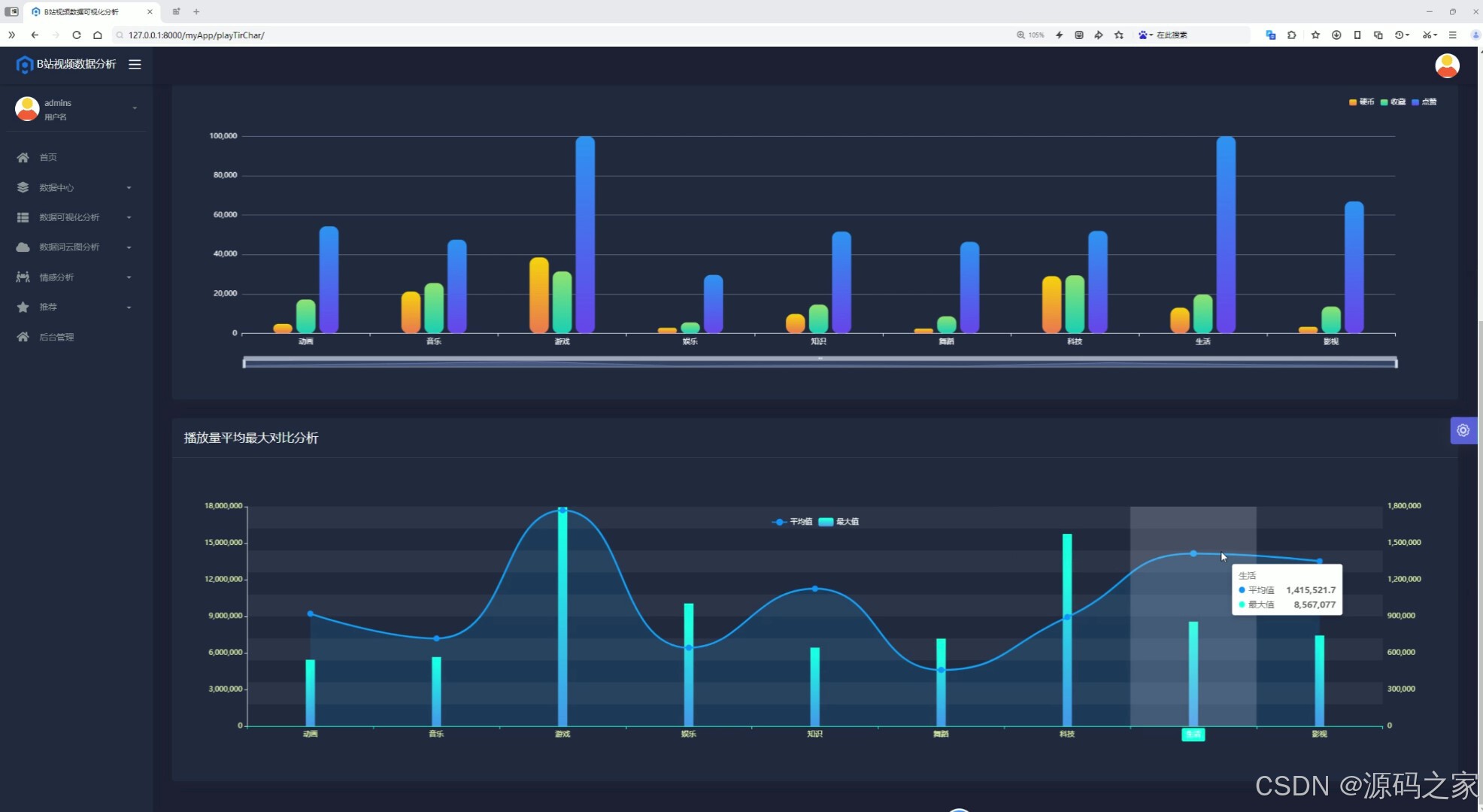
(3)分区播放三连分析2
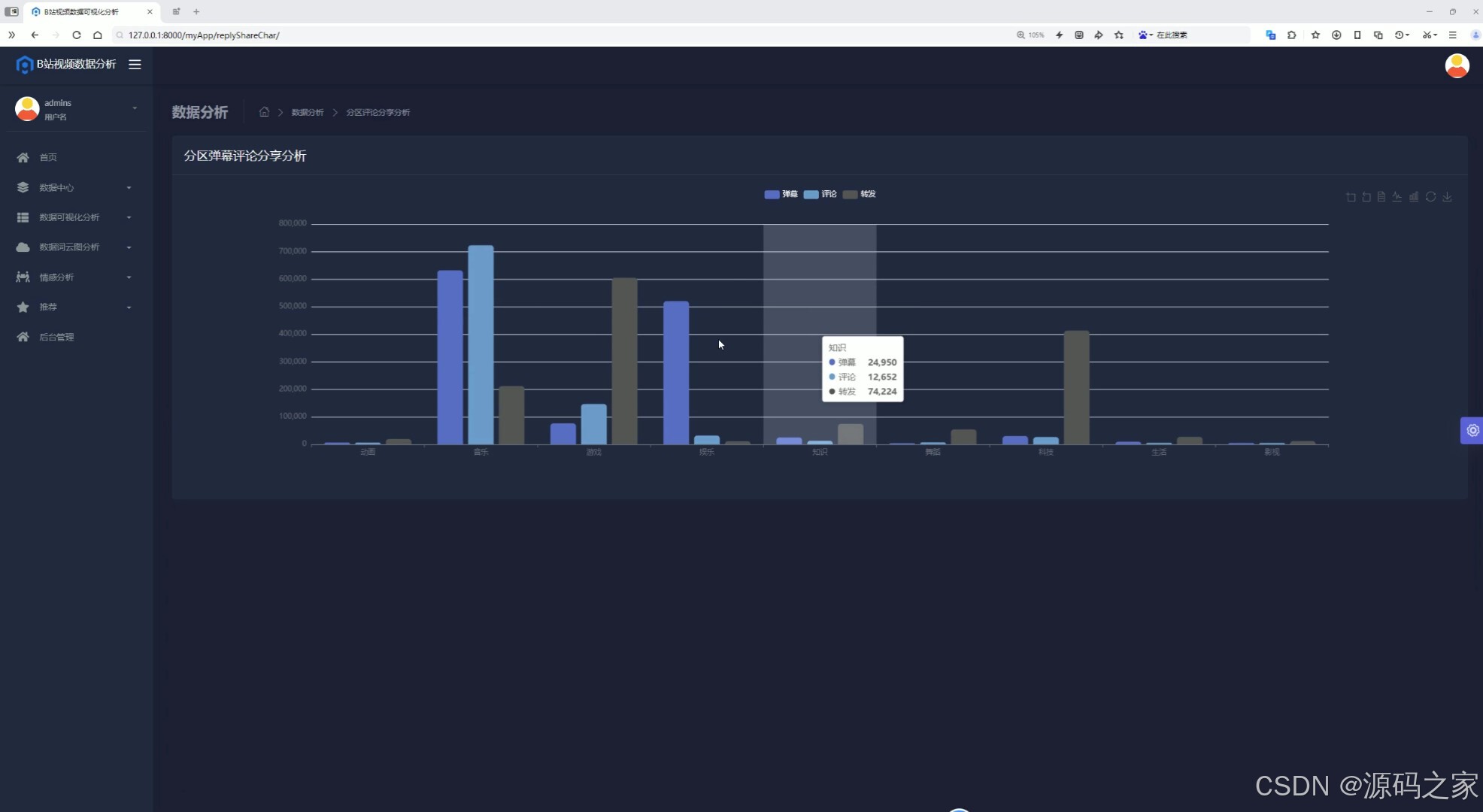
(4)分区弹幕评论
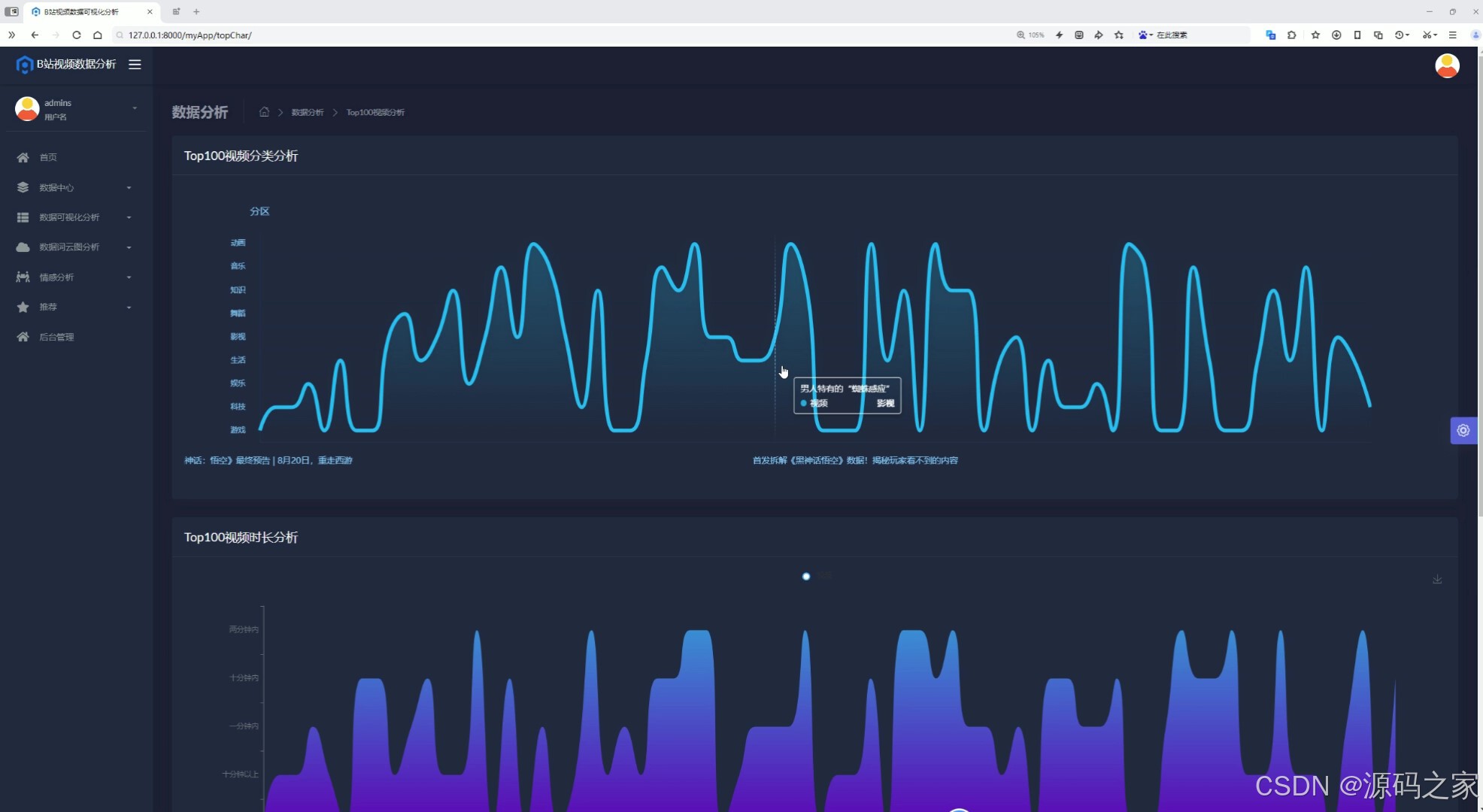
(5)Top100视频分析
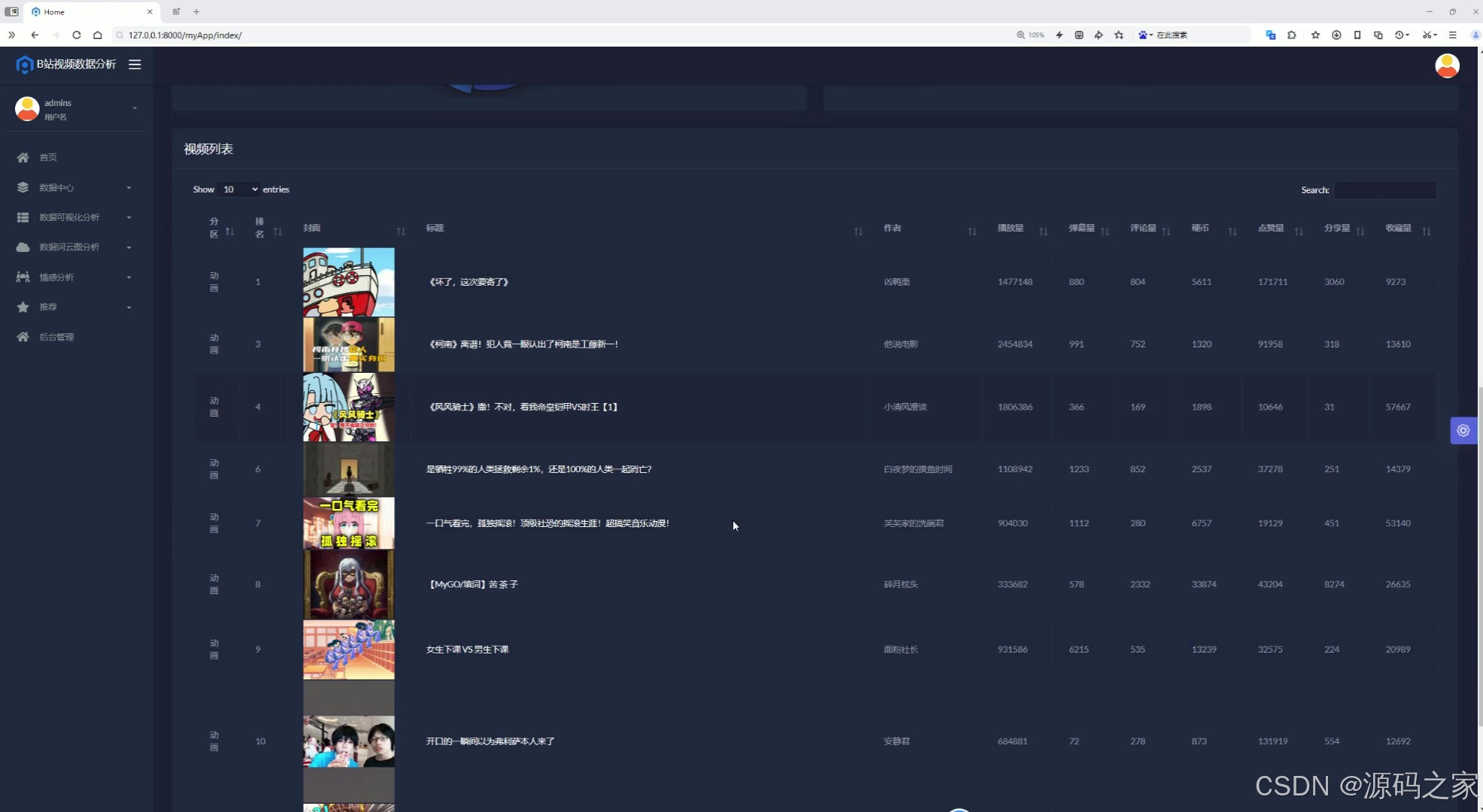
(6)首页-视频列表
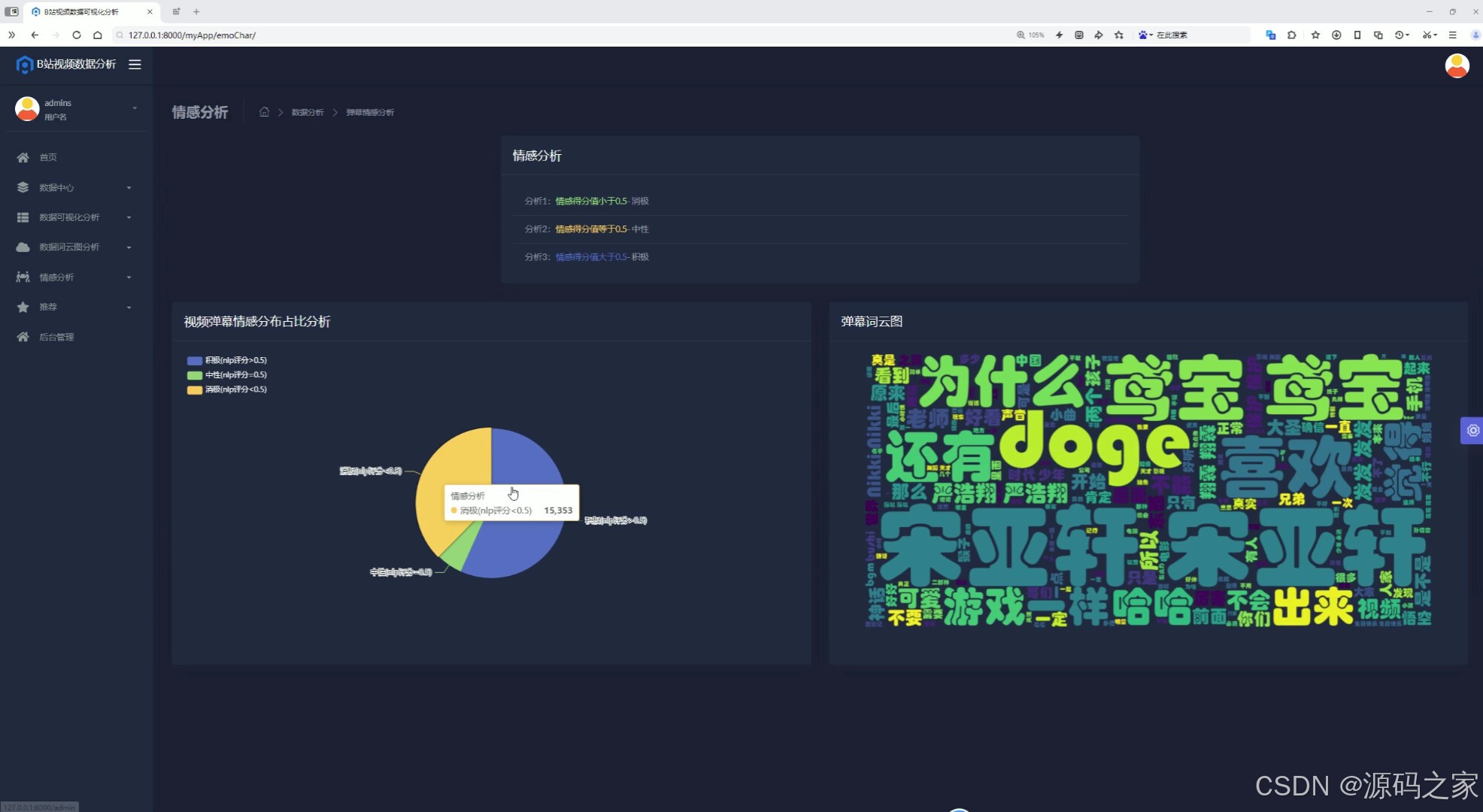
(7)弹幕情感分析
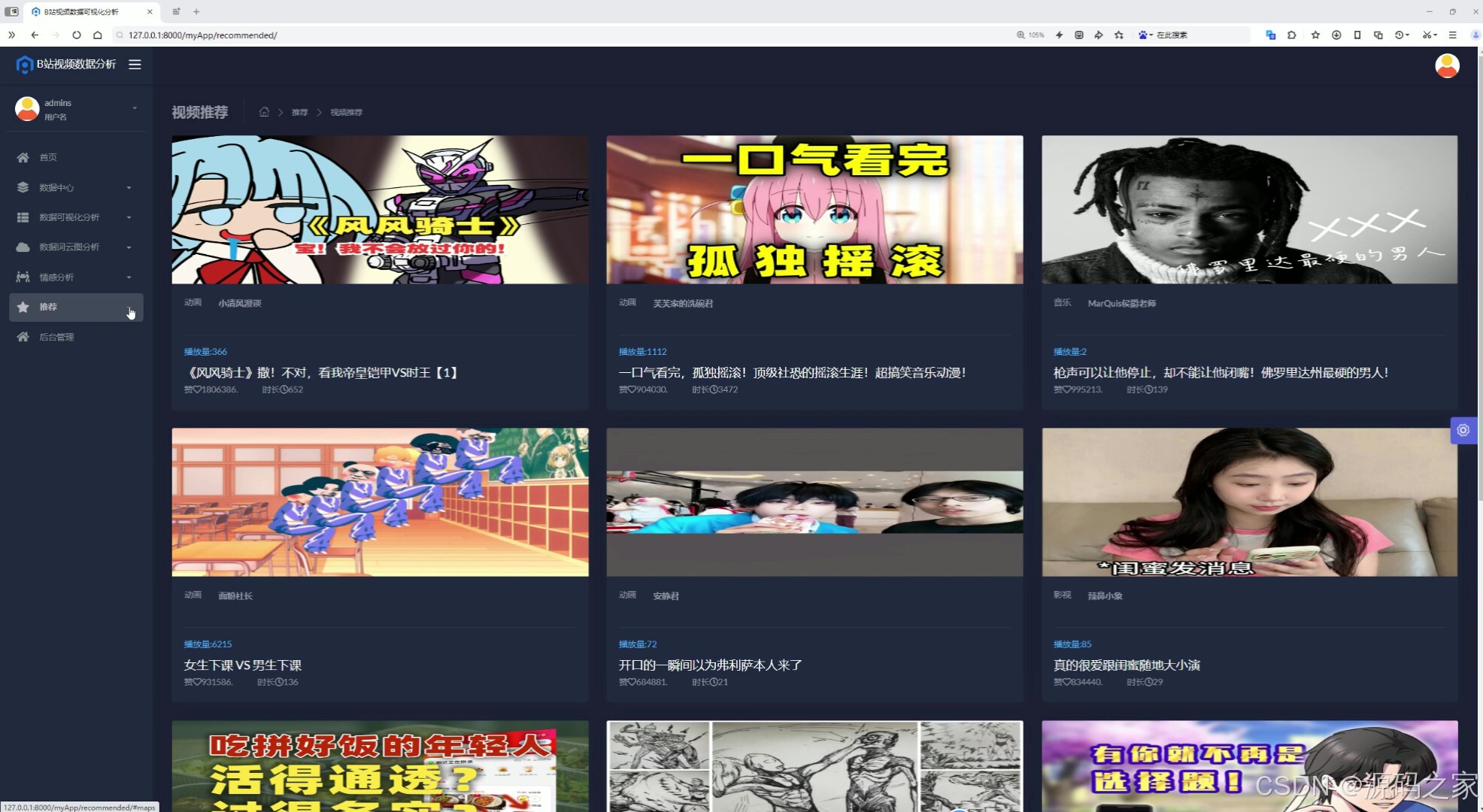
(8)推荐
(9)词云图分析
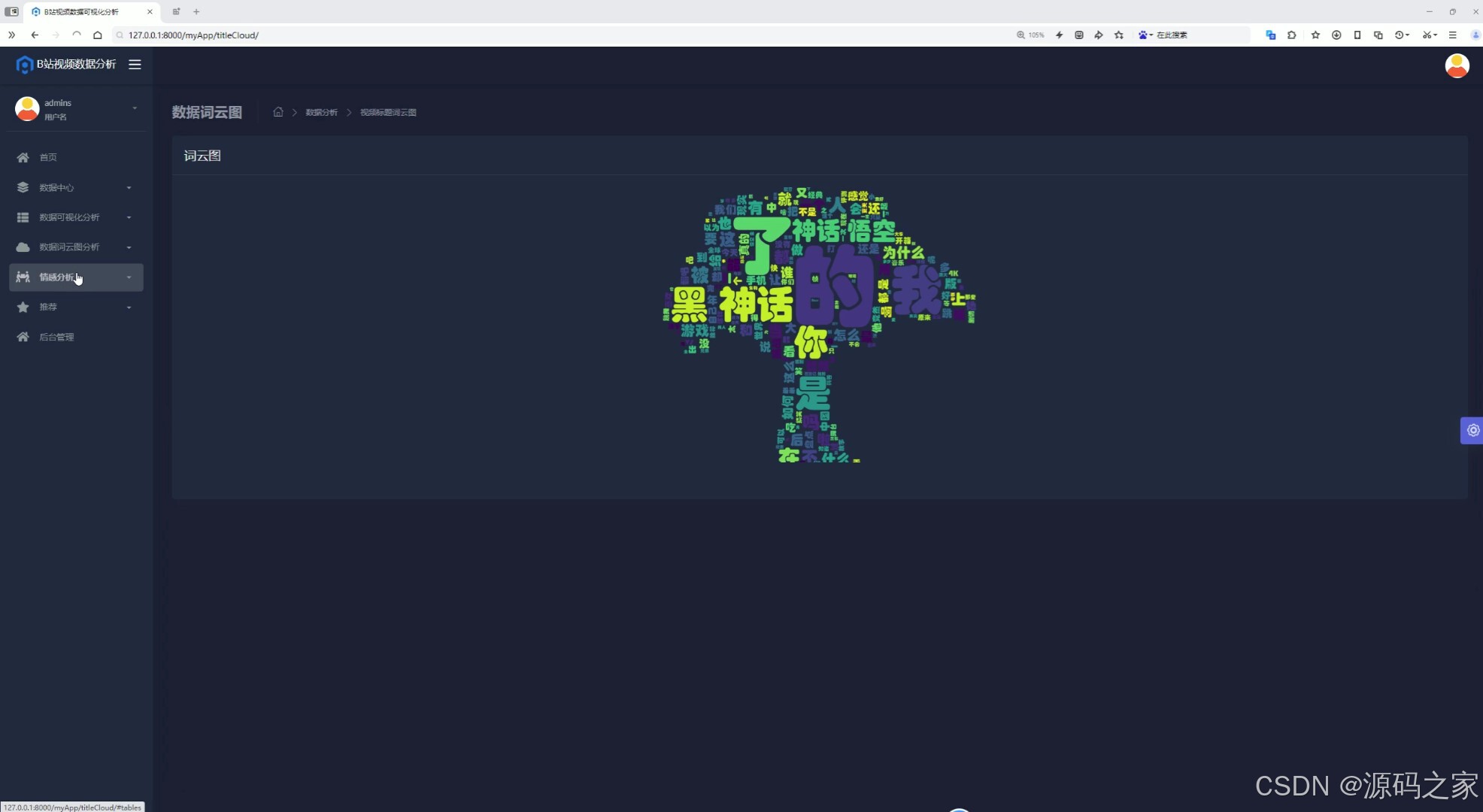
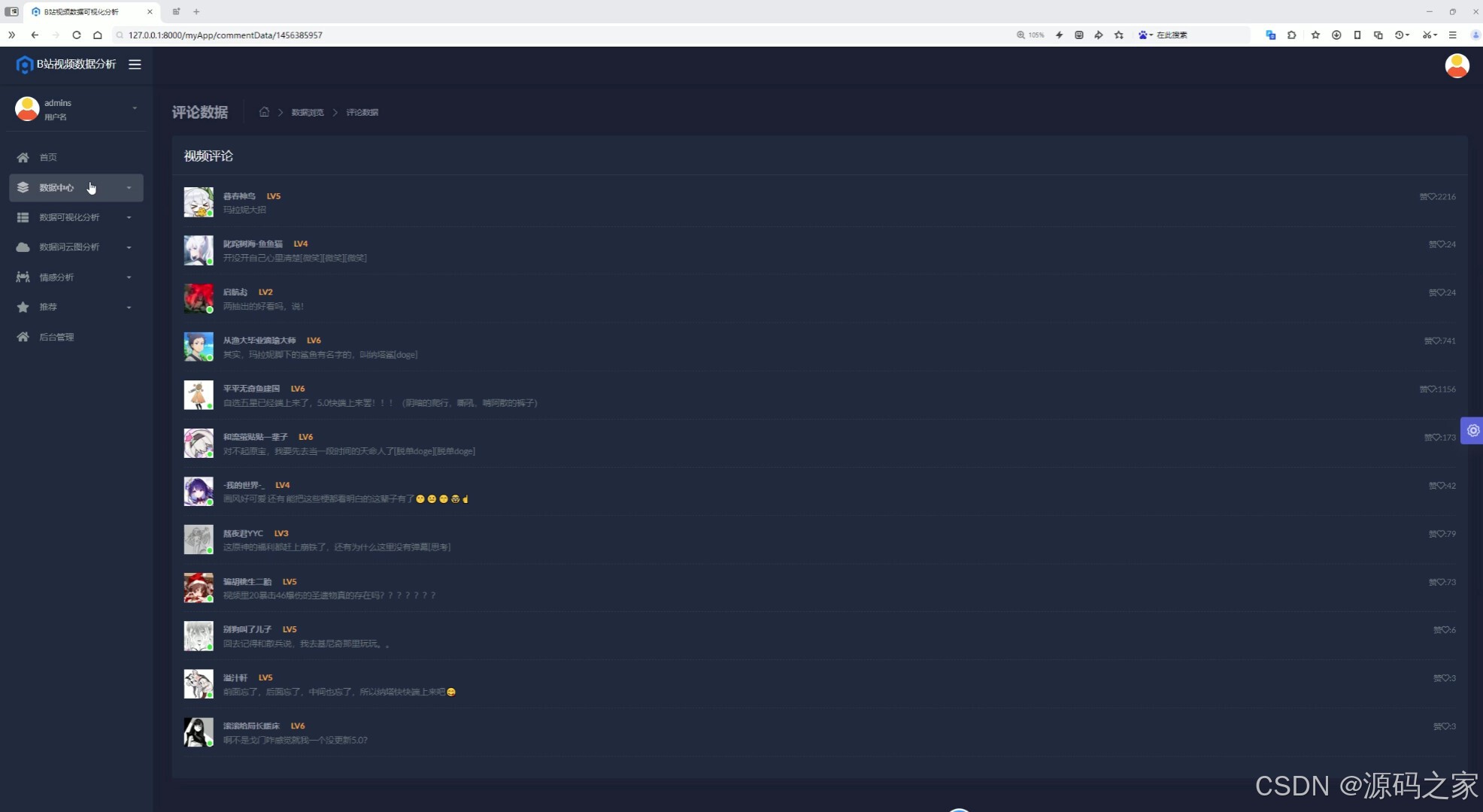
(10)评论数据
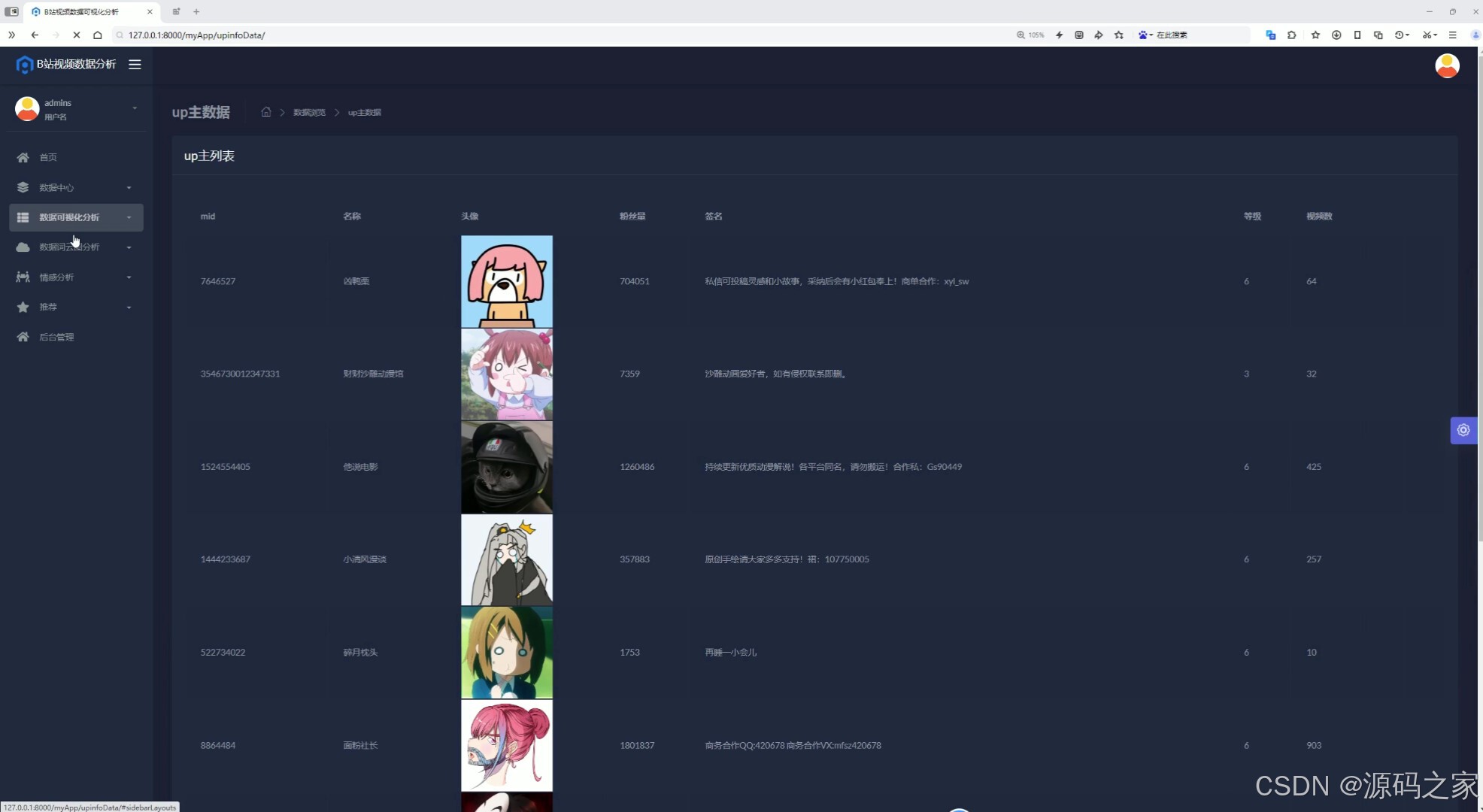
(11)UP主数据
(12)注册登录
(13)后台管理
3、项目说明
摘 要
随着数据量的迅速增长和互联网技术的不断发展,在线平台和数据分析需求日益增加。传统的内容推荐和数据分析方式难以处理庞大的数据集,且无法满足实时分析和精确推荐的需求。为解决这些问题,构建了一种基于Spark、Hadoop、Hive和Python技术的系统。
该系统通过前端和后端的协作,提供高效的数据分析与可视化服务。前端采用了现代的Web技术实现数据中心、数据可视化分析、数据词云图分析、情感分析和视频推荐等功能。后端则通过Myapp模块处理用户认证与授权。系统使用Hive作为数据库,存储和管理数据。前端提供交互式的分析工具,支持用户实时查看数据分析结果。后端则确保数据安全和用户访问权限的管理。
关键词:数据可视化;Spark;Hadoop;Hive;Python
本论文详细探讨了基于大数据技术的B站数据可视化分析系统的设计与实现过程。论文首先介绍了研究背景和目的,指出随着社交媒体平台的数据量急剧增加,传统数据分析方法已难以满足实时、高效分析需求。在这种背景下,数据可视化和大数据分析技术为平台内容优化和用户行为预测提供了有效支持。特别是在B站这样的多元化视频平台上,通过大数据技术处理用户评论、视频播放量、互动行为等数据,能够为平台运营人员和内容创作者提供深入的洞察力,进而提升用户体验和平台活跃度。本文通过分析国内外相关领域的研究现状,强调了数据可视化与情感分析在用户行为预测中的重要作用,也指出了现有技术在应用中的一些局限性和挑战。
在技术实现方面,本文详细介绍了系统开发过程中采用的各类技术和工具。首先,Python语言作为主要编程语言,提供了丰富的数据分析库和强大的处理能力,使得系统能够高效地处理大规模数据。Flask框架则为系统的前后端交互提供了高效的支持,确保了用户请求的快速响应。Echarts则为数据的可视化分析提供了强大的图表展示功能,使得用户可以直观地看到视频的互动趋势、评论情感等关键数据。为了处理大数据,系统采用了Spark和Hadoop框架,利用其分布式计算和存储能力,实现了对海量数据的实时处理。Hive数据库作为数据存储系统,提供了高效的数据查询和管理功能。所有这些技术的结合,使得系统能够在海量数据中提取有价值的信息,并通过直观的数据展示帮助用户更好地理解平台趋势和用户行为。
论文进一步对系统功能进行了详细设计,明确了前台和后台功能的实现方案。前台功能包括数据中心、数据可视化分析、词云图分析、情感分析和视频推荐等模块,这些功能通过与后台的数据处理系统的协作,提供了丰富的用户交互体验。后台功能则包括MyApp模块(包含历史记录表和用户表)以及认证与授权模块,确保系统的数据安全性与用户隐私保护。在系统实现步骤方面,本文详细描述了数据获取与爬取、数据清洗与预处理、数据分析与建模以及数据存储与展示等环节的技术实现过程。这些步骤为系统的高效运行提供了保障,使得系统能够在不断变化的社交平台环境中,实时获取和分析数据,进行精准的内容推荐和趋势预测。
系统测试部分,本文通过全面的测试用例设计,验证了各项功能的可行性与稳定性。包括登录注册、数据采集、数据分析、视频推荐等模块,经过严格的功能测试和性能测试,系统均能按预期正常运行,满足设计需求。通过测试结果,可以看出系统在数据处理、用户交互以及视频推荐等方面的可靠性和高效性。
综上所述,本论文成功设计并实现了一个基于大数据技术和数据可视化的B站数据分析系统。系统通过先进的技术手段,不仅实现了对B站平台数据的高效采集、处理与分析,还通过可视化方式提供了直观的数据展示与分析结果。这些成果不仅为平台的运营管理提供了科学依据,也为内容创作者提供了有价值的反馈,具有广泛的应用前景。
4、核心代码
python
#coding:utf8
#导包
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StructField,StringType,FloatType,IntegerType
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql import functions as F
from pyspark.sql.functions import col,when,count
if __name__ == '__main__':
#构建
spark = SparkSession.builder.appName("sparkSQL").master("local[*]").\
config("spark.sql.shuffle.partitions",2).\
config("spark.sql.warehouse.dir","hdfs://node1:8020/user/hive/warehouse").\
config("hive.metastore.uris","thrift://node1:9083").\
enableHiveSupport().\
getOrCreate()
#
sc = spark.sparkContext
#读取数据
topVideo = spark.read.table('topVideo')
upInfoTwo = spark.read.table('upInfoTwo')
videoCommentsTwo = spark.read.table('videoCommentsTwo')
#需求1 Top10回复与弹幕对比
top_ten_videos = topVideo.orderBy(col("playCnt").desc()).limit(10)
result1 = top_ten_videos.select("title","replyCnt","danmuCnt")
# sql
result1.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "sortRepDanmu"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result1.write.mode("overwrite").saveAsTable("sortRepDanmu", "parquet")
spark.sql("select * from sortRepDanmu").show()
#需求二 分区最高播放量
max_playCnt_df = topVideo.groupby("partition").agg(F.max("playCnt").alias("max_playCnt"))
result2 = max_playCnt_df.select("partition","max_playCnt")
# sql
result2.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "maxPartition"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result2.write.mode("overwrite").saveAsTable("maxPartition", "parquet")
spark.sql("select * from maxPartition").show()
#需求三 up粉丝量
result3 = upInfoTwo.orderBy(col("fensi").desc()).limit(5)
result3 = result3.select("upName","fensi")
# sql
result3.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "maxUp"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result3.write.mode("overwrite").saveAsTable("maxUp", "parquet")
spark.sql("select * from maxUp").show()
#需求四
avg_playCnt_df = topVideo.groupby("partition").agg(F.avg("playCnt").alias("avg_playCnt"))
result4 = avg_playCnt_df.select("partition","avg_playCnt")
# sql
result4.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "avgPartition"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result4.write.mode("overwrite").saveAsTable("avgPartition", "parquet")
spark.sql("select * from avgPartition").show()
#平均 最大
avg_max_playCnt_df = topVideo.groupby("partition").agg(F.avg("playCnt").alias("avg_playCnt"),
F.max("playCnt").alias("max_playCnt"))
resultCb = avg_max_playCnt_df.select("partition","avg_playCnt","max_playCnt")
# sql
resultCb.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "cbPartition"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
resultCb.write.mode("overwrite").saveAsTable("cbPartition", "parquet")
spark.sql("select * from cbPartition").show()
#需求五 硬币收藏 点赞
avg_metrics_df = topVideo.groupby("partition").agg(F.avg("coinCnt").alias("avg_coinCnt"),
F.avg("favoriteCnt").alias("avg_favoriteCnt"),
F.avg("likeCnt").alias("avg_likeCnt"),)
result5 = avg_metrics_df.select("partition","avg_coinCnt","avg_favoriteCnt","avg_likeCnt")
# sql
result5.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "avgCFL"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result5.write.mode("overwrite").saveAsTable("avgCFL", "parquet")
spark.sql("select * from avgCFL").show()
#需求五 硬币收藏 点赞 zuida
avg_metrics_df2 = topVideo.groupby("partition").agg(F.max("coinCnt").alias("max_coinCnt"),
F.max("favoriteCnt").alias("max_favoriteCnt"),
F.max("likeCnt").alias("max_likeCnt"),)
result6 = avg_metrics_df2.select("partition","max_coinCnt","max_favoriteCnt","max_likeCnt")
# sql
result6.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "maxCFL"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result6.write.mode("overwrite").saveAsTable("maxCFL", "parquet")
spark.sql("select * from maxCFL").show()
#需求7 弹幕评论 转发
avg_metrics_df3 = topVideo.groupby("partition").agg(F.max("danmuCnt").alias("max_danmuCnt"),
F.max("replyCnt").alias("max_replyCnt"),
F.max("shareCnt").alias("max_shareCnt"),)
result7 = avg_metrics_df3.select("partition","max_danmuCnt","max_replyCnt","max_shareCnt")
# sql
result7.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "maxDRS"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result7.write.mode("overwrite").saveAsTable("maxDRS", "parquet")
spark.sql("select * from maxDRS").show()
#需求八 TOP100视频分析
top100_df = topVideo.orderBy(F.desc("playCnt")).limit(100)
result8 = top100_df.select("partition","title")
# sql
result8.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "topPartition"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result8.write.mode("overwrite").saveAsTable("topPartition", "parquet")
spark.sql("select * from topPartition").show()
#需求9 时间分析
videoData_classified = top100_df.withColumn("time_category",
when(col("duration").between(0,60),"一分钟内")
. when(col("duration").between(60,120),"两分钟内")
. when(col("duration").between(120,300),"五分钟内")
. when(col("duration").between(300,600),"十分钟内")
. when(col("duration") > 600,"十分钟以上"))
result9 = videoData_classified.groupby("time_category").agg(count('*').alias("count"))
# sql
result9.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "durationCateGory"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result9.write.mode("overwrite").saveAsTable("durationCateGory", "parquet")
spark.sql("select * from durationCateGory").show()
#需求十
result10 = videoData_classified.select("title","time_category")
# sql
result10.write.mode("overwrite"). \
format("jdbc"). \
option("url", "jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8"). \
option("dbtable", "topDuration"). \
option("user", "root"). \
option("password", "root"). \
option("encoding", "utf-8"). \
save()
result10.write.mode("overwrite").saveAsTable("topDuration", "parquet")
spark.sql("select * from topDuration").show()🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻