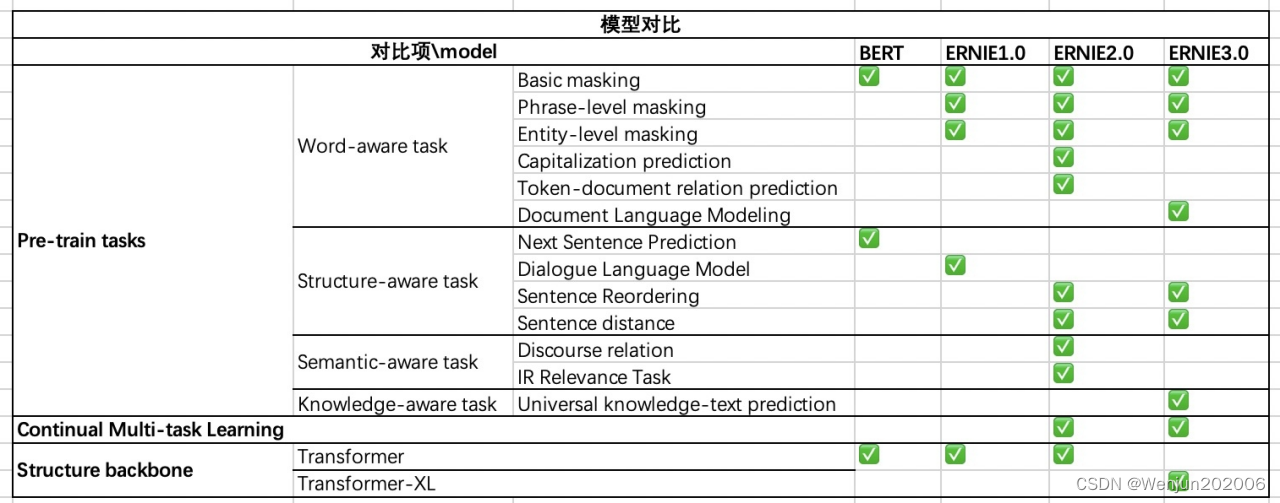
总结:ERNIE 3.0与ERNIE 2.0比较
(1)相同点:
采用连续学习
采用了多个语义层级的预训练任务
(2)不同点:
ERNIE 3.0 Transformer-XL Encoder(自回归+自编码), ERNIE 2.0 Transformer Encoder(自编码)
预训练任务的细微差别,ERNIE3.0里增加的知识图谱
ERNIE 3.0考虑到不同的预训练任务具有不同的高层语义,而共享着底层的语义(比如语法,词法等),为了充分地利用数据并且实现高效预训练,ERNIE 3.0中对采用了多任务训练中的常见做法,将不同的特征层分为了通用语义层(Universal Representation)和任务相关层(Task-specific Representation)。
参考
- Sun Y, Wang S, Li Y, et al. Ernie: Enhanced representation through knowledge integrationJ. arXiv preprint arXiv:1904.09223, 2019.
- Sun Y, Wang S, Li Y, et al. Ernie 2.0: A continual pre-training framework for language understandingC//Proceedings of the AAAI * Conference on Artificial Intelligence. 2020, 34(05): 8968-8975.
- Sun Y, Wang S, Feng S, et al. ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and * GenerationJ. arXiv preprint arXiv:2107.02137, 2021.
- 冯仕堃《百度知识增强技术ERNIE最新进展及其应用实践》 DataFun
- 常见的 BERT Mask 策略
- 自回归语言模型 VS 自编码语言模型
- 【论文极速看】ERNIE 3.0 通过用知识图谱加强的语言模型
- ERNIE3.0 Demo试玩,被卷到了
- 刷新50多个NLP任务基准,百度ERNIE 3.0知识增强大模型显威力
- 什么是 One/zero-shot learning?