说明
感觉停滞了一段时间,本来qtv200应该在去年12月就迭代好了。回顾了一下原因:
- 1 工作的约束。因为量化现在是打辅助的角色(现在的工作还是比较香的),去年上了项目,几乎与世隔绝的那种,打断了整体的节奏。
- 2 信心的影响。目前的量化效果并没有达到显著的程度,特别是因为之前的策略和标的都比较单一,且没有分叉,所以没有收集到足够多的反馈。
- 3 计算环境的变化与演进。算力主机的租用、算网重要组件的更新,这些变化客观上说是非常大的,足以支持新一轮的创新。关于创新的定义,我记得马斯克有过一段话,原文不记得了,大致是这么说的:并不是完全创造一种全新的方法才是创新,即使是同样事,当客观条件发生变化时(如新工具),那么即使重新用该方法去做,也是一种创新。
从总体上,我对于qtv的想象是没有太大变化的,如果模糊的形容,qtv应该是运行在一个强化学习框架之下,会根据实际情况自动调整策略;qtv的模型是在是一个非常大的空间内,不断进行自动建模和优化的,类似遗传算法那;qtv的手工模式提供非常友好的前端、通知等交互方式;qtv会有一个规则引擎,执行自动交易;qtv可以接受无限扩展算力,高速的执行海量运算,其中有一种应该是采用显卡进行大规模LR并行建模;qtv会采用贝叶斯体系的算法;...
这些模糊的期待是完全可能且正在实现的,因此在准备前提条件和开始正式的版本迭代会有一个取舍。不能沉迷于幻想与技术,要时刻牢记并且思考正在做的事与目标的关联性,这是写本篇文章的第一动机。
内容
1 业务回顾
了解实际的表现
在过去的一年里,虽然没有持续扩大规范,但是策略一直在默默的执行。从行情上看,最近的一年应该是蛮负面的,以后可以把这段时间列为一个单独的测试空间。
好消息是,第一版(只有一个策略)并没有亏一毛钱。
第一个策略focus在510300、510500、512000、512010这四个ETF上,总体上盈利约10%,由于自动的交易都采取了较悲观的参数,所以实操结果会比这个更高一些。
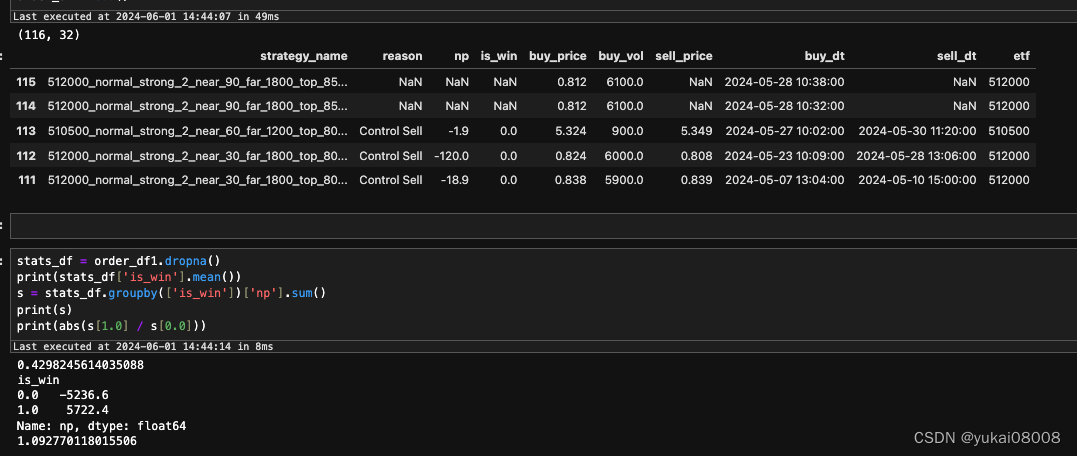
总体上有115个订单,平均一个月有10个订单,所以从数量上还是可以的。手工上,我follow了一些订单
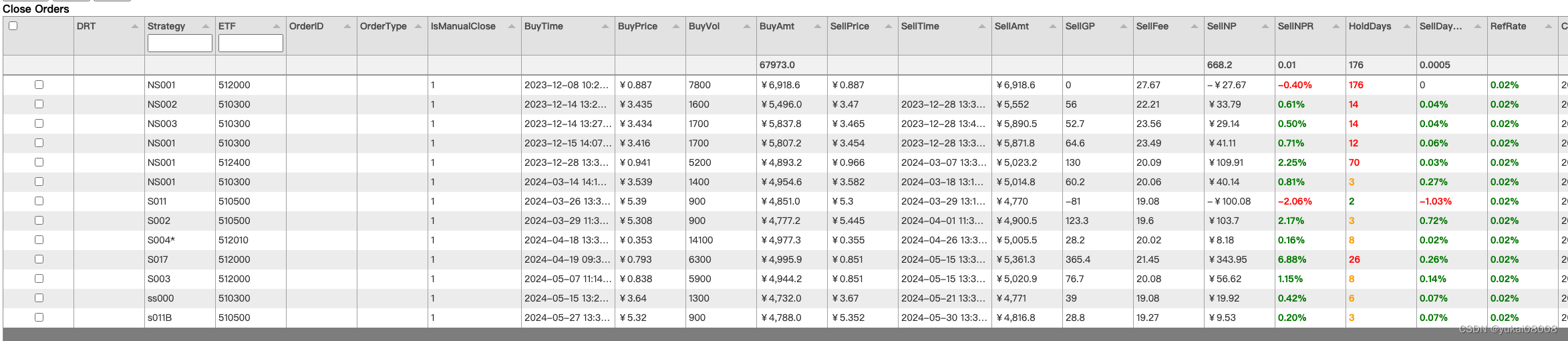
其中,NS开头的是我自己拍脑袋的操作,盈利率不高,且还有一堆被套的单子。 ⇒ 拍脑袋策略不可取,严格遵守策略一定是更好的。
从最近的实操上看,每个月也就5~6个订单的样子(有一些还在ope的状态)。一般来说,策略订单基本上不会超过10天的持有,有一些超长的是因为短信系统不靠谱:早就获利了解了,但是短信没通知到。 ⇒ 短信系统不可靠,还是用邮件+app通知靠谱
订单的平均盈利率在1个点左右,周转率按10天算的话,一年(250交易日)可以周转25次。订单的日均收益率大约是无风险(5%)的3~4倍的样子,大体上差不多。
有一些策略因为是基于同质模型的信号,所以有些订单会有不合理的聚拢情况。
仅从支持度上看,如果把订单规模扩大10倍应该就差不多了,每个月有50~60个订单。
每个订单假设5000元,平均盈利1%就是50元,总盈利为¥2500。50个订单每个月交易额为25万,按10天周转率,合理分配的话只要8万左右的资金(最大)。月利润率约为3.12%。
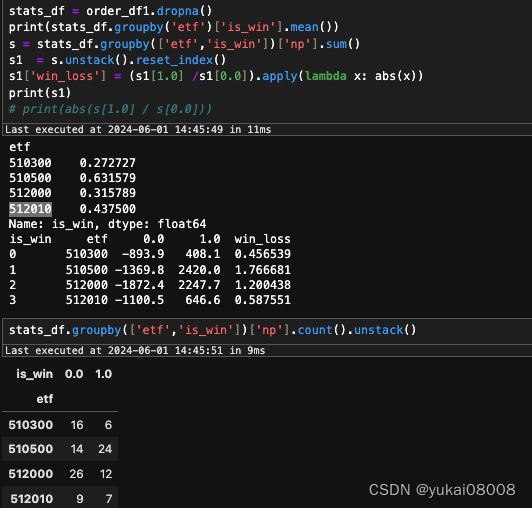
另外,可以看到这四个标的也有很大的不同。510300和512010是亏损的,但是其交易次数明显少,这块我不知道是否也是模型的自限性:因为没有足够多的买信号产生,虽然模型犯错了,但是犯错的总额还是较少的。510500的盈亏比已经不错了,1.76,比较接近2。512000烦的错也不少,但还是明显盈利的。
结论
优点:
- 1 稳赢。看起来,要确保胜利还是可以的。
- 2 盈利率足够高。单月3%的平均盈利率是可以期待的,这意味着复利模式(即利润再投入)下24个月,可达到本金翻倍。
不足:
- 1 支持度不够。目前的订单量太少了,还不足以作出具有统计可靠性的论断。
- 2 盈亏比不够高。盈亏比是容错性能的保障,这可能是唯一需要特别关注的指标。特别是对于510300、512010这种,在任何情况下,是否还能保持盈亏比大于1?
2 技术性回顾
在过去的一年里,权重指数出现大幅回撤,这种情况以后也还会出现。在历史上,还曾经有过更大的回撤情况。所以从业务上,必然有一种考虑:如何确保量化可以应对足够极端的情况?
我认为,首先应该按时间分散风险;其次应该确保在不同的情况下,交易系统都能够正常运行(对冲)。
我想,按照一个长周期,例如1年来分散所有的投资,应该会很安全。但是这样资金的利用率就太低了,所以可以想象,应该是有一个较为协调的中值,且可以随风险偏好改变。风险偏好可能是更宏观的需求和模型。
另外,我们假定模型主要在稳态区间运行,而不是在变迁态。如果从统计上描述,如何属于稳态应该是有一些方法的,不展开。但是变迁始终会发生,怎么应对呢?
假设,我们的资金是100,我觉得可以分为两份。一份50将在稳态时运行,这些资金投资的策略更追逐短期利益。一旦判断行情退出稳态,那么这些资金将限制不做投资。另一份则作为长期投资,用于平衡变迁态无法交易带来的交易机会损失。这些资金投资的策略追求长期利益,基本上是以半年或者年为投资单位。在低位时持仓,高位减仓,但是其交易频率非常低。
长期投资还有一个重要用途:提供T+0的支持。特别地,在低位时仓位变大,T+0的Capacity也自动增大,反之,在高位自动钳制T+0的行为。
另外,长期投资还有吸收损失的特性。一些策略可能会产生"滞留"的订单,这些可以按照一定特性纳入长期投资,从而吸收伤害。
结论:
- 1 判断稳态和非稳态
- 2 长短期策略组合
2.1 特征回顾
最初只使用了价格趋势,而并不使用交易动量;后来的大部分模型使用了动量。
从构成交易的基础(回归理论)来说,只使用价格趋势是合理的,因为标的本身已经具备了统计稳定性。动量当然可以考虑,本着赛马不相马的原则,未来这些都会存在。
比较好的是使用了VV,这使得开发和复现都是参数化,容易复现。
比较差的是,这些处理都没有持久化,更像是一个个火花,一闪而逝。
结论:
- 1 VV服务化
- 2 特征持久化
2.2 基本模型信号回顾:双刃剑模型、风险模型。
最初没有意识到双刃剑模型的特性,只是单调的关注涨的成功率。有很多时候大涨的信号也同时意味着大跌,所以这种模型,对赌的成分太高了。
所以,我们真正的目标是盈亏比,而不是"有变化"。那么,怎么找出那些特征呢?怎么保证大多数时候吃到好的,很少的情况才吃瘪?我觉得,我是不知道这个方法的。但是,当我们把情况进行泛化、抽象化,我们可以发现这种情况是存在的,一定存在一组或者若干组特征,可以实现上面的情况。但是如何找出来可能不一定采取解析化方法。可以想象,我通过遗传算法来让计算机进行大量的尝试,找到那一组解。在这个过程当中,一定会找到一定范围内的若干组参数,甚至从分布的角度,会存在若干个中心点。这也是我认为单量是可以很容易的扩容的,而且是属于比较科学的方式。双刃剑模型可能在演变之后成为大砍刀模型:一边的刃很锋利,这是获利面;而另一边的刃很宽,这是亏损面。大砍刀模型就是属于那种可以拿着乱砍的,因为相对于获利,损失几乎可以不计。
除了双刃剑模型,还有风险模型。这种建模方式可能会更加简单,因为风险模型的核心就是不犯错。假设,我们面对亏损的概率很低,那么我们可以放心买入,然后利用回归中的波动性迅速卖出获利。可以认为,风险模型本身就认定现在处于稳态,价格将围绕中枢上下波动。所以,如果配合底仓,这类模型甚至可以演变T+0交易。一天之内,只要波动超过0.5%就可能获利,一天内反复波动则可以反复套利。
结论:
- 1 将双刃剑演变为大砍刀
- 2 采用遗传算法+MLR
- 3 风险模型的T+0方法
3 交易操作回顾
消息本身的滞后和丢失比较强。在获取信息被后的信息时非常困惑,然后要采取进一步验证时也不知道数据在哪。在录入数据时还是太麻烦了,我希望更简单一些。
结论:
- 1 短信只作为可有可无的补充,采用邮件APP push,或者以后用机器人push(webhook)
- 2 订单既有表格形式的汇总态,用于统计;也要有类似对象的明细态,用于交易时提供足够信息。
- 3 有dashboard,方便统计,形成足够商业化的投资报告。
4 Next
- 1 资金上,将会划分成若干部分作为初始态,之后会使用强化学习框架自动分配(削弱或者增强)。
- 2 基础结构上,将采用DataFlow,自动流转所有的数据。各功能部分将只注重逻辑。半固定化的结构将会简化维护过程,且又可以无限扩展。
- 3 时间轴。所有单元,在执行时只要考虑自身的运行,遵守同样的运行逻辑(TimeTraveller)。这是一个非常重要且核心的运行机制,将会形成对象来进行约束和调度。或者说,每个功能都是一个TT实例。
- 4 数据点的分类存储。Mongo、ClickHouse和Milvus将是三种主要的数据点。Mongo会存储各种原始数据或者弹性数据,一般居于底层。ClickHouse将会存储结构化数据,如决策数据、市场价格数据等。Milvus则存储大量的特征数据,如VV之后的特征向量。
- 5 模型的再次迭代。