一直有传言说,MySQL 表的数据只要超过 2000 万行,其性能就会下降。而本文作者用实验分析证明:至少在 2023 年,这已不再是 MySQL 表的有效软限制。
传言
互联网上有一则传言说,我们应该避免单个 MySQL 表中的数据超过 2000 万行,否则表的性能就会下降------当数据量超过这个软限制时,你就会发现 SQL 的查询速度会比平时慢很多。这是多年前针对 HDD 做出的判断。我想知道,时至 2023 年,SSD 上的 MySQL 是否仍然有此限制。如果真的有,那么原因是什么呢?
环境
数据库
▶ MySQL 版本: 8.0.25
▶ 实例类型:AWS db.r5.large(2vCPUs, 16GiB RAM)
▶ EBS 存储类型:General Purpose SSD(gp2)
测试客户端
▶ Linux 内核版本:6.1
▶ 实例类型:AWS t2.micro(1 vCPU, 1GiB RAM)
实验设计
创建具有相同结构、但大小不同的表。我一共创建了 9 个表,数据行数分别为:10 万、20 万、50 万、100 万、200 万、500 万、1000 万、2000 万、3000 万、5000 万和 6000 万。
- 创建几个具有相同结构的表:
sql
CREATE TABLE row_test(
`id` int NOT NULL AUTO_INCREMENT,
`person_id` int NOT NULL,
`person_name` VARCHAR(200),
`insert_time` int,
`update_time` int,
PRIMARY KEY (`id`),
KEY `query_by_update_time` (`update_time`),
KEY `query_by_insert_time` (`insert_time`)
);- 插入不同的数据。我使用了测试客户端和表复制的方式创建了这些表。脚本可参考:https://github.com/gongyisheng/playground/blob/main/mysql/row_test/insert_data.py。
sql
# test client
INSERT INTO {table} (person_id, person_name, insert_time, update_time) VALUES ({person_id}, {person_name}, {insert_time}, {update_time})
# copy
create table like <table>
insert into (`person_id`, `person_name`, `insert_time`, `update_time`)
select `person_id`, `person_name`, `insert_time`, `update_time` fromperson_id、person_name、insert_time 和 update_time 的值是随机的。
- 使用测试客户端执行以下 sql 查询来测试性能。脚本可参考:https://github.com/gongyisheng/playground/blob/main/mysql/row_test/select_test.py。
sql
select count(*) from <table> -- full table scan
select count(*) from <table> where id = 12345 -- query by primary key
select count(*) from <table> where insert_time = 12345 -- query by index
select * from <table> where insert_time = 12345 -- query by index, but cause 2-times index tree lookup- 查看 innodb 缓冲池状态。
sql
SHOW ENGINE INNODB STATUS
SHOW STATUS LIKE 'innodb_buffer_pool_page%结果
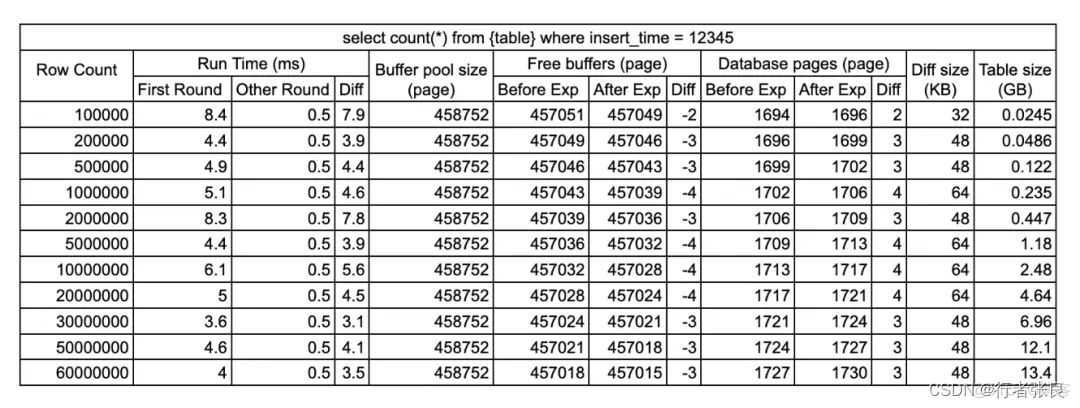
查询1:select count(*) from
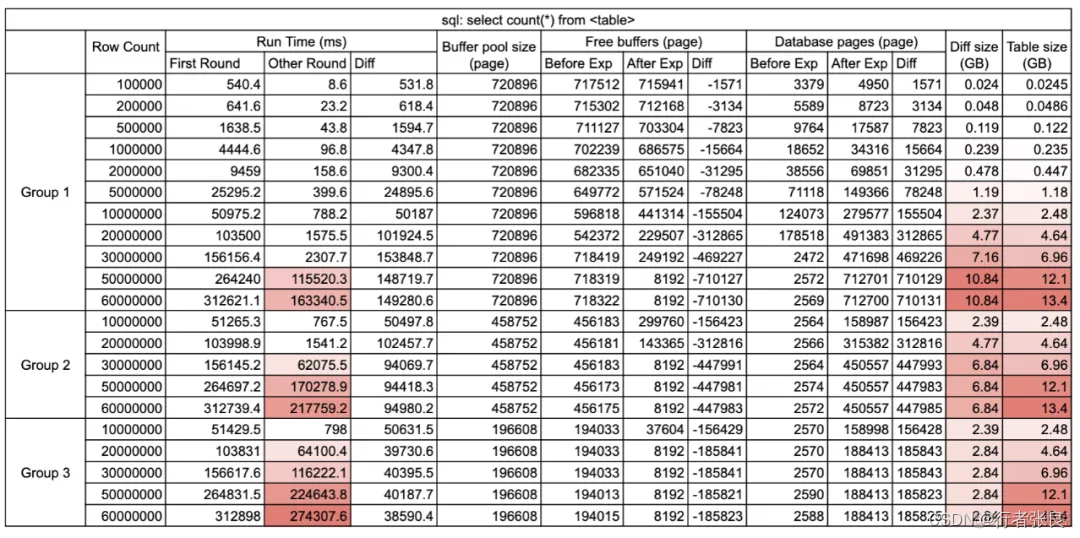
这种查询会执行全表扫描,MySQL 并不擅长这种工作。
▶ 第一轮:没有缓存。第一次执行查询时,缓冲池中没有缓存数据。
▶ 第二轮:有缓存。当缓冲池中已经有数据缓存时执行查询,通常在第一次查询执行完之后。
观察结果:
1. 第一轮查询的执行时间超出了后面几次。
原因是 MySQL 使用了 innodb_buffer_pool 来缓存数据页。在第一次执行查询之前,缓冲池是空的,所以 MySQL 必须进行大量的磁盘 I/O 才能从 .idb 文件加载表。但在第一次执行结束后,缓冲池中存储了数据,后续查询可以直接读取内存,避免磁盘 I/O,因此速度更快。该过程称为 MySQL 缓冲池预热。
2. select count(*) from < table > 会设法将整个表加载到缓冲池。
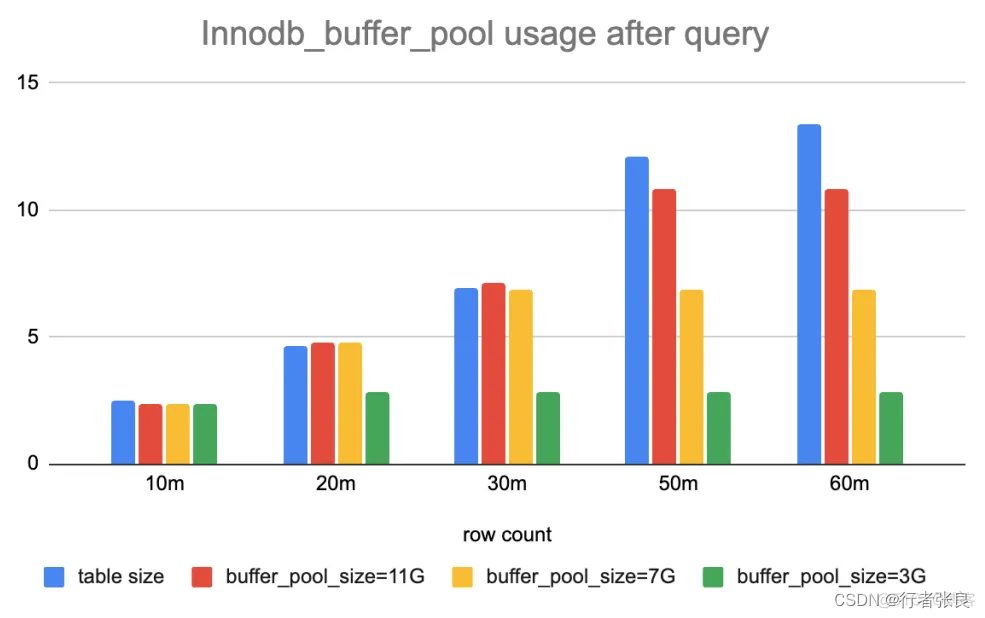
我比较了实验前后 innodb_buffer_pool 的统计数据。运行查询后,如果缓冲池足够大,则其使用量变化等于表的大小。否则,只有部分表会缓存在缓冲池中。原因是查询 select count(*) from table 会做全表扫描,并做逐行统计。如果没有缓存,就需要将完整的表加载到内存中。为什么?因为 Innodb 支持事务,它不能保证事务在不同时间看到同一张表。全表扫描是获得准确行数的唯一安全方法。
3. 如果缓冲池不能容纳全表,则会爆发查询延迟。
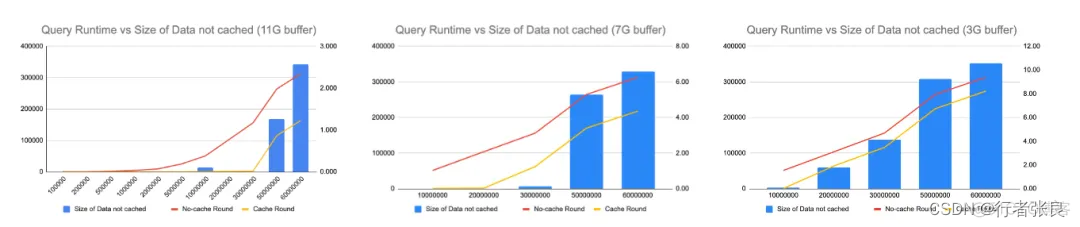
我注意到 innodb_buffer_pool 的大小会极大地影响查询性能,因此我尝试在不同的配置下运行查询。当使用 11G 缓冲区,而表的大小达到 5000 万行时,就会爆发查询延迟。接着,我将缓冲区缩减到 7G,当表的大小达到 3000 万行时,爆发了查询延迟。最后,我将缓冲区缩减到 3G,当表的大小仅为 2000 万行时,就爆发了查询延迟。很明显,如果表中的数据无法缓存在缓冲池中,则 select count(*) from
必须执行昂贵的磁盘 I/O,这会导致查询运行时间直线上升。
4. 对于没有缓存的查询,查询花费的时间与表的大小呈线性关系,与缓冲池大小无关。
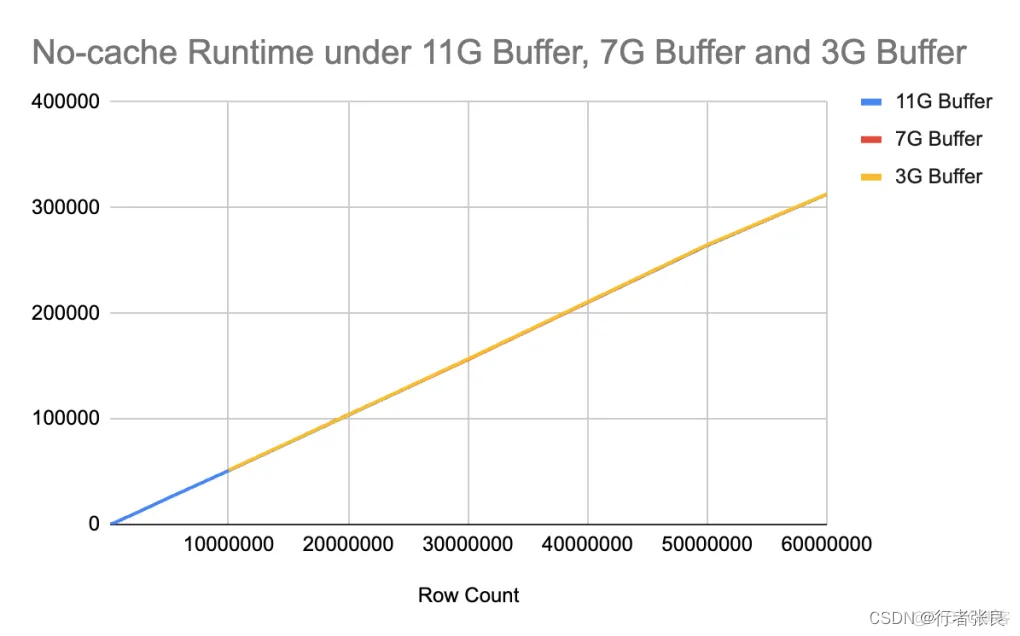
当没有缓存时,查询花费的时间由磁盘 I/O 决定,与缓冲池大小无关。在 IOPS 相同的情况下,是否使用 select count(*) 预热缓冲池并没有区别。
5. 如果无法完整地缓存整个表,则有无缓存的查询运行时间差异是恒定的。
另请注意,如果无法完整地缓存整个表,虽然查询运行时会突然上升,但运行时是可预测的。无论表的大小如何,有无缓存的时间差异是恒定的。原因是表的部分数据缓存在缓冲区中,这里的时间差异来自从缓冲区读取数据节省的时间。
查询2,3:select count(*) from where = 12345
这个查询使用了索引。由于不是范围查询,MySQL 只需要利用 B+ 树的路径从上到下查找页面,并将这些页面缓存到 innodb 缓冲池中即可。
我创建的表的 B+ 树的深度都是 3,因此前面的 3~4 次 I/O 都被拿来预热缓冲区,平均耗时 4~6 毫秒。之后,再次运行相同的查询,MySQL 就会直接从内存中查找结果,耗时为 0.5 毫秒,约等于网络 RTT。如果缓存页面长时间未命中,并从缓冲池中逐出,则必须再次从磁盘加载该页面,这样就需要磁盘 I/O(最多 4 次)。
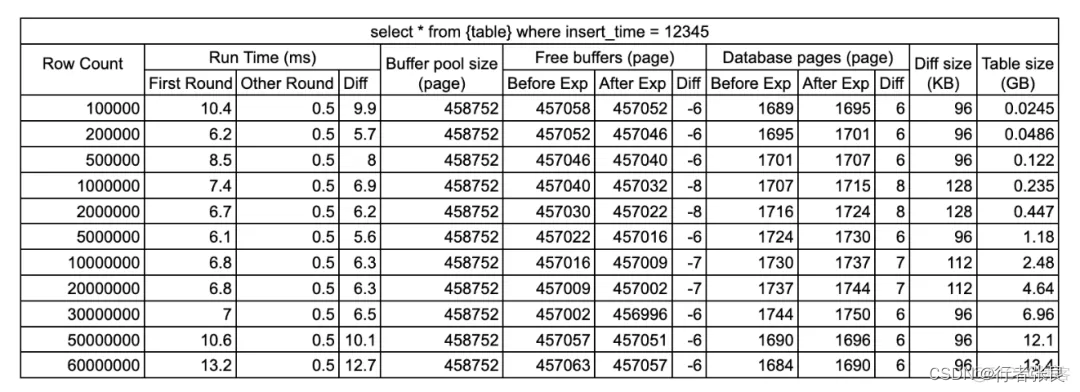
查询4:select * from where = 12345
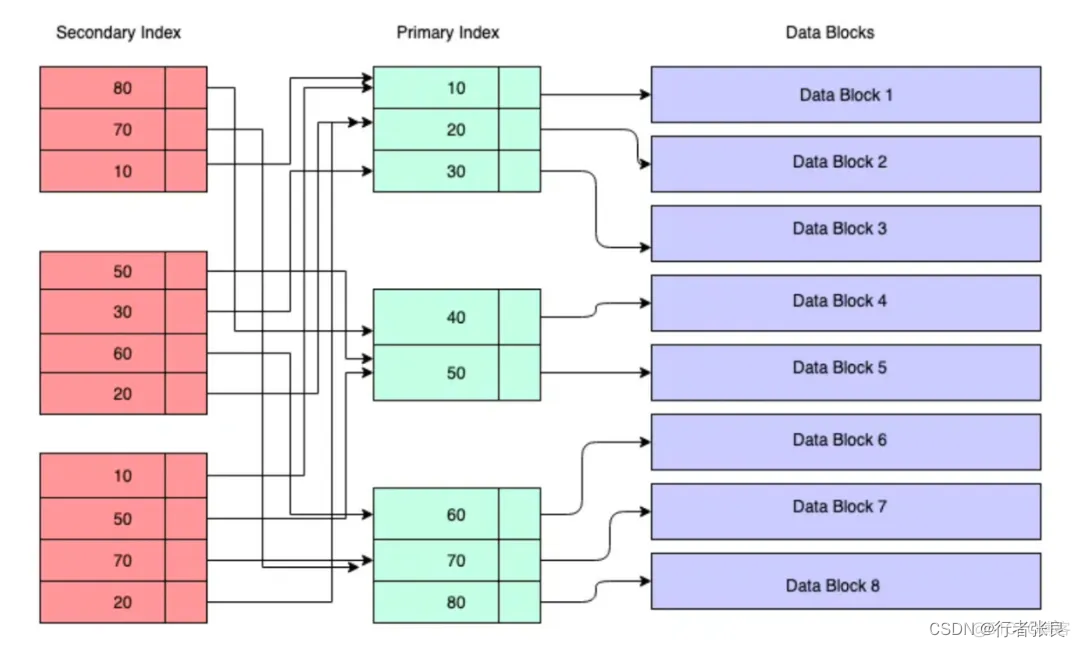
这个查询涉及两次索引查找。由于 select * 需要查询获取的 person_name、person_id 字段并不在索引中,因此在查询执行期间,数据库引擎必须查找 2 个 B+ 树。它首先查找 insert_time B+ 树,获取目标行的主键,然后查找主键 B+ 树,获取该行的完整数据,如下图所示:
这就是我们应该在生产中避免 select * 的原因。此次实验证实,此查询加载的页面块比查询 2 或 3 多出了 2 倍,且最高可达 8 倍。查询的平均运行时间为 6~10 毫秒,也是查询 2 或 3 的 1.5~2 倍。
传言是怎么来的

首先,我们需要知道 innodb 索引页的物理结构。默认页面大小为 16k,由页眉、系统记录、用户记录、页面导向器和尾部组成。只有剩下的 14~15k 用来存储数据。
假设你使用 INT 作为主键(4 字节),每行 1KB 的有效负载。每个叶页可以存储 15 行,一个指向该页的指针需要 4+8=12 字节。因此,每个非叶页最多可以容纳 15k / 12 字节 = 1280 个指针。如果你有一个 4 层的 B+ 树,它最多可以容纳 1280128015 = 24.6M 行数据。
回到 HDD 占据市场主导地位,且 SSD 对于数据库而言过于昂贵的时代,4 次随机 I/O 可能是我们可以容忍的最坏情况,而使用 2 次索引树查找的查询甚至会使情况变得更糟。当时的工程师想要控制索引树的深度,不希望它们太深。而如今 SSD 越来越流行,随机 I/O 比以前便宜了,因此我们应该反思一下 10 年前的规则。
顺便说一句,5 层 B+ 树可以容纳 128012801280*15 = 31.4B 行数据,超过了 INT 所能容纳的最大数据量。对每行大小的不同假设将导致不同的软限制,或小于或大于 2000 万行。例如,在我的实验中,每一行大约是 816 字节(我使用 utf8mb4 字符集,所以每个字符占用 4 个字节),4 层 B+ 树可以容纳的软限制是 29.5M。
结论
▶ Innodb 缓存池的大小、表的大小决定了是否会出现性能降级。
▶ 判断是否需要拆分 MySQL 表的一个更有意义的指标是查询运行时/缓冲池命中率。如果查询总是命中缓冲区,则不会有任何性能问题。2000 万行只是一个经验值。
▶ 除了拆分 MySQL 表之外,增加 Innodb 缓存池的大小和数据库的内存也是一个选择。
▶ 如果可能,请避免在生产中使用 select *,这类语句在最坏的情况下会导致 2 次索引树查找。
▶ (我个人的意见)考虑到 SSD 现在越来越流行,2000 万行不再是 MySQL 表的有效软限制。