欢迎订阅,点赞+关注,每日精进1%,与百万开发者共攀技术珠峰
更多内容持续更新中~ 😀😀😀
JDBC高级篇:优化、封装与事务全流程指南
1,代码冗余问题
在使用JDBC时,我们会发现创建连接池、获取连接以及连接回收等代码在每个操作中都写一遍代码就会很冗余。为了解决此问题,我们可以尝试将这些连接池的操作封装为全局工具类。
2,JDBC工具类的简单封装
工具类内部需要封装的共性代码可包括:
- 维护一个连接池对象;
- 对外提供在连接池中获取连接的方法;
- 对外提供回收连接的方法;
此外,由于工具类仅对外提供共性的功能代码,因此工具类内的所有方法均为 静态方法。
在 util 子包下创建 JDBCUtil 工具类,其 Durid连接池配置信息和 Java 代码如下:
bash
driverClassName =com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/JDBC
username=your_username
password=your_password
initialSize=10
maxActive=20
java
package com.hpu.senior.util;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class JDBCUtil {
// 创建连接池引用,因为要提供给当前项目的全局使用,因此为静态的
private static DataSource dataSource; // 此处使用DataSource使代码更灵活,多态思想
// 项目启动时即通过此静态代码块创建连接池对象,赋值给dataSource引用
static {
try {
Properties properties = new Properties();
InputStream inputStream = JDBCUtil.class.getClassLoader().getResourceAsStream("db.properties");
properties.load(inputStream);
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 对外提供在连接池中获取连接的方法
*/
public static Connection getConnection(){
try {
return dataSource.getConnection();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
/**
* 对外提供回收连接的方法
*/
public static void release(Connection connection){
try {
connection.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}注意:上述代码中的 DruidDataSourceFactory要选 com.alibaba.druid.pool 下面的,如下图:

接下来编写测试代码进行测试:
java
package com.hpu.senior;
import com.hpu.senior.util.JDBCUtil;
import org.junit.Test;
import java.sql.Connection;
public class JDBCUtilTest {
@Test
public void testGetConnection() throws Exception {
Connection connection = JDBCUtil.getConnection();
//CRUD...
System.out.println(connection);
JDBCUtil.release(connection);
}
}运行结果如下,可以成功获取到连接对象:

以上即为一个简化版的 JDBC 工具类封装。
3,ThreadLocal
设想这样一个电商系统的开发场景,用户在查询商品的时候会和数据库交互一次,因此会获取到一个数据库连接。而查询到商品之后用户短期之内可能不会下单,这就会导致这个数据库连接被归还到连接池。归还之后假设此用户将此商品加入到购物车,此操作就会再拿到一个数据库连接。而此连接后续可能还会被归还。而后用户如果再进行下单操作就会再次拿到一个数据库连接和数据库进行交互。
在此场景下,多次获取的连接很可能不一样,这就会导致同一线程用户多次操作获取了多个连接,会造成连接资源的浪费。为了避免这种资源浪费,我们需要尽可能地让这一个用户线程在多次操作过程中拿到的是同一个连接。 在此种情况下,我们就可以通过ThreadLocal实现此需求。
ThreadLocal 为解决多线程程序的并发问题提供了一种新的思路。使用这个工具类可以很简洁地编写出优美的多线程程序。通常用来在在多线程中管理共享数据库连接、Session等。
ThreadLocal 用于保存某个线程共享变量。Java中,每一个线程对象中都有一个 ThreadLocalMap <ThreadLocal, Object>,其 key 就是一个ThreadLocal,而 Object 即为该线程的共享变量。ThreadLocalMap 是通过 ThreadLocal 的 set 和 get 方法操作的。对于同一个 static ThreadLocal,不同线程只能从中 get,set,remove 自己的变量,而不会影响其他线程的变量。
-
ThreadLocal对象.get(): 获取ThreadLocal中当前线程共享变量的值;
-
ThreadLocal对象.set(): 设置ThreadLocal中当前线程共享变量的值;
-
ThreadLocal对象.remove(): 移除ThreadLocal中当前线程共享变量的值;
ThreadLocal 的一些典型应用场景如下:
- 在进行对象跨层传递的时候(如DAO层和Service层之间),使用ThreadLocal可以避免多次传递,打破层次间的约束;
- 线程间数据隔离;
- 进行事务操作,用于存储线程事务信息(后续会介绍);
- 数据库连接管理、Session会话管理;
4,JDBC工具类封装优化
接下来我们基于
ThreadLocal优化前面的 JDBC 工具类的封装,将连接对象放在每个线程的ThreadLocal 中 ,解决同一用户线程下,连接对象的频繁获取和释放问题,尽量保证同一用户线程在多次操作过程中拿到的是同一个连接。
工具类内部需要封装的共性代码可包括:
- 维护一个连接池对象和一个线程绑定变量的 ThreadLocal 对象;
- 对外提供在连接池中获取连接的方法;
- 对外提供回收连接的方法;
优化后的工具类代码如下:
java
package com.hpu.senior.util;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class JDBCUtilV2 {
// 1,维护一个连接池对象和一个线程绑定变量的 ThreadLocal 对象
private static DataSource dataSource; // 此处使用DataSource使代码更灵活,多态思想
private static ThreadLocal<Connection> threadLocal = new ThreadLocal<>();
// 项目启动时即通过此静态代码块创建连接池对象,赋值给dataSource引用
static {
try {
Properties properties = new Properties();
InputStream inputStream = JDBCUtil.class.getClassLoader().getResourceAsStream("db.properties");
properties.load(inputStream);
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 对外提供在ThreadLocal中获取连接的方法
*/
public static Connection getConnection(){
try {
// 从ThreadLocal中获取连接
Connection connection = threadLocal.get();
if (connection == null){ // 第一次get时候为null,此时需从连接池获取连接,并存入ThreadLocal中
// 从连接池中获取连接
connection = dataSource.getConnection();
// 将连接保存到ThreadLocal中
threadLocal.set(connection);
}
return connection;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
/**
* 对外提供回收连接的方法
*/
public static void release(){ // connection在ThreadLocal中,所以不需要作为参数传入
try {
Connection connection = threadLocal.get();
if (connection!=null){
threadLocal.remove(); // 从ThreadLocal中移除连接
connection.close(); // 将连接对象还给连接池
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}接下来对优化前后的工具类进行对比测试
① 对优化前的工具类代码进行测试,测试代码如下:
java
@Test
public void testJDBCV2(){
Connection connection1 = JDBCUtil.getConnection();
Connection connection2 = JDBCUtil.getConnection();
Connection connection3 = JDBCUtil.getConnection();
System.out.println(connection1);
System.out.println(connection2);
System.out.println(connection3);
}运行结果如下,三次获取到的连接都不同,这表明这种方式封装的工具类,实际使用时同一个用户线程获取多个连接,导致资源浪费:
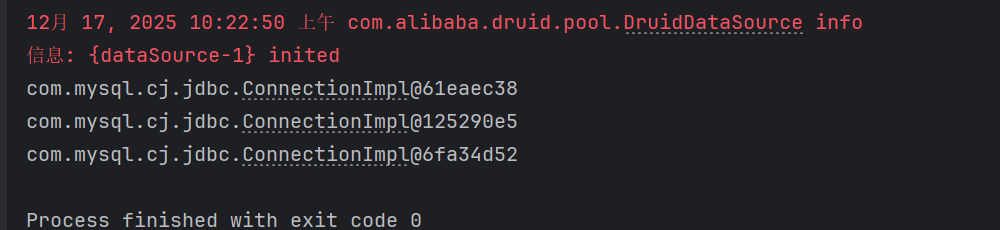
② 对优化后的工具类代码进行测试,测试代码如下:
java
@Test
public void testJDBCpro(){
Connection connection1 = JDBCUtilV2.getConnection();
Connection connection2 = JDBCUtilV2.getConnection();
Connection connection3 = JDBCUtilV2.getConnection();
System.out.println(connection1);
System.out.println(connection2);
System.out.println(connection3);
}代码运行结果如下,三次获取的连接相同,说明使用 Threadlocal 方式可以避免操作多个连接的资源浪费问题:
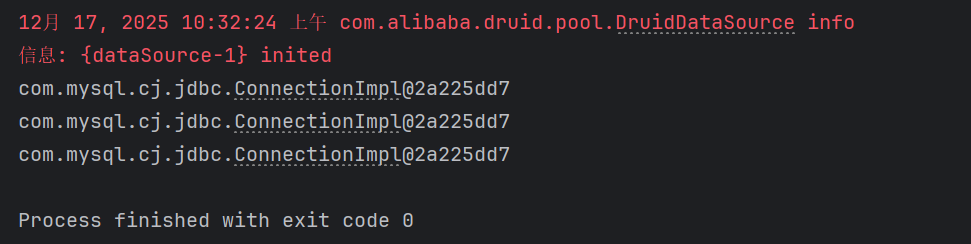
5,BaseDAO
DAO(Data Access Object)是指数据访问对象。Java是面向对象语言,数据在Java中通常以对象的形式存在:
- 一张表对应一个实体类;
- 一张表的操作对应一个DAO对象;
Java操作数据库时,将对同一张表的增删改查操作统一维护起来,维护的这个类就是DAO层;- DAO层只关注对数据库的操作,供业务层Service调用;
首先创建 pojo 目录,以及数据库表 t_emp 对应的 Employee 实体类,代码如下:
java
package com.hpu.senior.pojo;
/**
* 此处我们设置的类名对应的是数据库表的t_后面的单词全写
*/
public class Employee {
private Integer empId; // 对应emp_id
private String empName; // 对应emp_name
private Double empSalary; // 对应emp_Salary
private Integer empAge; // 对应empAge
public Employee() { // 无参构造
}
public Employee(Integer empId, String empName, Double empSalary, Integer empAge) { //全参构造
this.empId = empId;
this.empName = empName;
this.empSalary = empSalary;
this.empAge = empAge;
}
// get和set方法
public Integer getEmpId() {
return empId;
}
public void setEmpId(Integer empId) {
this.empId = empId;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public Double getEmpSalary() {
return empSalary;
}
public void setEmpSalary(Double empSalary) {
this.empSalary = empSalary;
}
public Integer getEmpAge() {
return empAge;
}
public void setEmpAge(Integer empAge) {
this.empAge = empAge;
}
// toString方法
@Override
public String toString() {
return "Employee{" +
"empId=" + empId +
", empName='" + empName + '\'' +
", empSalary=" + empSalary +
", empAge=" + empAge +
'}';
}
}把对数据库表 t_emp 的增删改查操作封装,先定义一个接口作为实现的规范 ,代码如下:
java
package com.hpu.senior.dao;
import com.hpu.senior.pojo.Employee;
import java.util.List;
/**
* EmployeeDao 对应 t_emp 这张表的增删改查操作。
*
* 由于不同数据库的CRUD操作可能不同,所以这里使用接口,让不同的数据库实现不同的方法。
*/
public interface EmployeeDao {
/**
* 查询所有员工信息的操作
*/
List<Employee> selectAll();
/**
* 根据 empId 查询单个员工信息
*/
Employee selectByEmpId(Integer empId);
/**
* 添加一条员工信息
*/
int Insert(Employee employee);
/**
* 修改一条员工信息
*/
int update(Employee employee);
/**
* 删除一条员工信息
*/
int delete(Integer empId);
}dao目录下创建 impl 子包,创建具体的实现类 EmployeeDaoImpl:
实现类中的每个方法的实现都有核心的六个步骤:
- 注册驱动;
- 获取连接;
- 创建SQL语句;
- 为占位符赋值,执行SQL,接收返回结果;
- 处理结果;
- 释放资源;
其中注册驱动、获取连接、释放资源这三个操作已经在工具类中做了封装。思考:能否也把公共的数据库操作的代码也进行封装呢?答案是可以的。这就是所谓的 BaseDAO。
基本上每一个数据表都应该有一个对应的DAO接口及其实现类,对所有表的 CRUD 代码重复度很高,所以可以抽取公共代码。给这些DAO的实现类可以抽取一个公共的父类,复用增删改查的基本操作,我们称之为BaseDAO。
首先在 dao 目录下创建名为 BaseDAO 的Java类。随后写入方法的实现,此处封装三个方法分别是:
- 通用的增删改的方法;
- 通用的查询多行数据方法;
- 通用的查询单行数据方法;
Java 代码如下:
java
package com.hpu.senior.dao;
import com.hpu.senior.util.JDBCUtilV2;
import java.lang.reflect.Field;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.util.ArrayList;
import java.util.List;
/**
* 将共性的数据库操作代码封装在BaseDAO中
*/
public class BaseDAO {
/**
* 通用的增删改的方法
* @param sql 调用者要执行的sql语句
* @param params sql语句中的占位符要赋值的参数
* return 返回受影响的行数
*/
public int excuteUpdate(String sql, Object... params) throws Exception{ // Object... params为可变长参数,可传可不传,可传任意长度的参数
//1,通过封装好的JDBCUtilV2获取数据库连接
Connection connection = JDBCUtilV2.getConnection();
//2,预编译SQL语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//3,为占位符赋值,执行SQL,接受返回结果
if (params != null && params.length > 0){
for (int i = 0; i < params.length; i++) { // 循环赋值
preparedStatement.setObject(i + 1, params[i]); // 注意占位符是从1开始,参数数组是从0开始。使用setObject不把类型写死
}
}
int row = preparedStatement.executeUpdate();
//4,释放资源
preparedStatement.close();
JDBCUtilV2.release(); // 关闭的是connection
//5,返回结果
return row;
}
/**
* 通用的查询数据的方法(多行)
* 查询可分为:多行多列、单行多列、单行单列。比如多行多列可用List<Employee>存储、单行多列可用Employee存储、单行单列可能是用Double、Integer等类型存储
* 多种情况采用不同的方式处理,因此:
* ①返回的类型可设置为泛型,调用时将此次查询的结果类型告知BaseDAO即可
* ②返回的结果可用List接受,可存储一个结果也可存储多个结果
* ③通过反射进行结果的封装,要求调用时告知BaseDAO要封装对象的类对象
*/
public <T> List<T> excuteQuery(Class<T> clazz, String sql, Object... params) throws Exception{
//1,通过封装好的JDBCUtilV2获取数据库连接
Connection connection = JDBCUtilV2.getConnection();
//2,预编译SQL语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//3,为占位符赋值,执行SQL,接受返回结果
if (params != null && params.length > 0){
for (int i = 0; i < params.length; i++) { // 循环赋值
preparedStatement.setObject(i + 1, params[i]); // 注意占位符是从
}
}
//4,执行查询,返回结果集
ResultSet resultSet = preparedStatement.executeQuery();
//5,处理结果集(注意此处是通用方法,可能查的是员工表、教师表或学生表,那就不能通过列名进行数据获取)
ResultSetMetaData metaData = resultSet.getMetaData(); //获取结果集中的元数据对象。其中包含了列的数量、列名、列的类型等信息
int columnCount = metaData.getColumnCount(); //getColumnCount可以得到有多少列
List<T> list = new ArrayList<>(); // 保存结果
while (resultSet.next()){
// 循环一次代表有一个数据,通过反射创建一个对象
T t = clazz.newInstance();
// 为对象的属性赋值
for (int i = 1; i <= columnCount; i++){
// 根据下标获取列的值
Object value = resultSet.getObject(i);
// 获取到的value值就是t这个对象的某一个属性值
String fieldName = metaData.getColumnLabel(i); // 获取当前拿到的列的名字(要注意保持此处的fieldName和实体类属性名字的对应)
//通过类对象和fieldName获取要封装的对象的属性
Field field = clazz.getDeclaredField(fieldName);
//突破private封装
field.setAccessible(true);
field.set(t, value); // 反射为t对象进行赋值
}
list.add(t);
}
resultSet.close();
preparedStatement.close();
JDBCUtilV2.release();
return list;
}
/**
* 通用查询单行数据方法,在上面查询的集和结果中获取第一个结果。简化了获取单行单列数据、单行多列数据
*/
public <T> T excuteQueryBean(Class<T> clazz, String sql, Object... params) throws Exception{
List<T> list = excuteQuery(clazz, sql, params); // 调用上面定义的excuteQuery方法
if (list == null || list.size() == 0){
return null;
}
return list.get(0);
}
}接下来我们久咳哟基于封装好的逻辑,补全 EmployeeDaoImpl 的方法实现,实现CRUD
java
package com.hpu.senior.dao.impl;
import com.hpu.senior.dao.BaseDAO;
import com.hpu.senior.dao.EmployeeDao;
import com.hpu.senior.pojo.Employee;
import java.util.List;
public class EmployeeDaoImpl extends BaseDAO implements EmployeeDao {
/**
* 查询所有员工
*/
@Override
public List<Employee> selectAll() {
try {
// 注意SQL语句这个地方要设置别名和类的属性名一致(要和BaseDAO中查询的处理逻辑一致)
String sql = "select emp_id empId,emp_name empName, emp_salary empSalary, emp_age empAge from t_emp";
return excuteQuery(Employee.class, sql, null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public Employee selectByEmpId(Integer empId) {
try {
// 注意SQL语句这个地方要设置别名和类的属性名一致(要和BaseDAO中查询的处理逻辑一致)
String sql = "select emp_id empId,emp_name empName, emp_salary empSalary, emp_age empAge from t_emp where emp_id = ?";
return excuteQueryBean(Employee.class, sql, empId); // 返回的是一个结果
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public int Insert(Employee employee) {
try {
String sql = "insert into t_emp(emp_name,emp_salary,emp_age) values(?,?,?)";
return excuteUpdate(sql, employee.getEmpName(), employee.getEmpSalary(), employee.getEmpAge());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public int update(Employee employee) {
try {
String sql = "update t_emp set emp_salary = ? where emp_id = ?";
return excuteUpdate(sql, employee.getEmpSalary(), employee.getEmpId());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public int delete(Integer empId) {
try {
String sql = "delete from t_emp where emp_id = ?";
return excuteUpdate(sql, empId);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}6,事务
6.1,事务概述
据库事务就是一种SQL语句执行的缓存机制,不会单条执行完毕就更新数据库数据,最终根据缓存内的多条语句执行结果统一判定:一个事务内所有语句都成功即为事务成功,可以触发commit提交事务来结束事务,更新数据;一个事务内任意一条语句失败,即为事务失败,可以触发rollback回滚结束事务,数据回到事务之前状态。
事务的特性:
- 原子性(Atomicity)是指事务是一个不可分割的工作单位,事务中的操作要么都发生, 要么都不发生;
- 一致性(Consistency)即事务必须使数据库从一个一致性状态变换到另外一个一致性状。(比如两人各1000元余额,他们之间进行转账,不管怎么转最终余额总和不能超过2000);
- 隔离性(Isolation)是指隔离性指一个事务执行时,其操作和数据对其他并发事务相互隔离,互不干扰;
- 持久性(Durability)是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的, 接下来的其他操作和数据库故障不应该对其有任何影响;
事务的提交方式:
- 自动提交:每条语句自动存储一个事务中,执行成功自动提交,执行失败自动回滚;
- 手动提交:手动开启事务,添加语句,手动提交或者手动回滚;
如果想查看数据的提交方式,可以执行如下SQL语句进行查询:
sql
SHOW VARIABLES LIKE 'autocommit';运行结果如下:(ON代表自动提交;OFF代表自动提交已关闭)

每个连接对象,默认的事务提交方式都是自动提交。可以通过如下SQL语句设置为手动提交:
sql
SET autocommit = FALSE;提交事务和回滚事务的SQL语句如下:
sql
-- 提交事务
COMMIT;
--回滚事务
ROLLBACK;JDBC 中事务实现的关键代码如下:
java
try{
connection.setAutoCommit(false); //关闭自动提交
//所有操作执行正确,提交事务
connection.commit();
}catch(Execption e){
//出现异常,则回滚事务!
connection.rollback();
}要注意的是,其中:
- preparedStatement 负责增删改查的数据库动作;
- connection 负责操作事务;
6.2,工具类优化
由于涉及到事务操作,我们还需要对之前封装的工具类 JDBCUtilV2 做对应的优化。
首先需要优化释放连接方法,如果代码里设置了关闭事务自动提交,最终将数据库连接归还连接池之前还需要还原为默认的自动提交状态,优化后的Java代码如下:
java
/**
* 对外提供回收连接的方法
*/
public static void release(){ // connection在ThreadLocal中,所以不需要作为参数传入
try {
Connection connection = threadLocal.get();
if (connection!=null){
threadLocal.remove(); // 从ThreadLocal中移除连接
// 如果开启了事务的手动提交,操作完毕后归还连接池之前,还需要将事务的自动提交改为True
connection.setAutoCommit(true);
connection.close(); // 将连接对象还给连接池
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}然后BaseDAO中的增删改方法 excuteUpdate 也需要进行优化
资源关闭的时候需要进行判断:
-
如果当前 connection 连接关闭了自动提交,说明进行了手动事务控制。
此时无需释放连接,而是由外部显式控制事务的提交、回滚和连接释放; -
如果当前 connection 连接未关闭自动提交,说明没有进行手动事务控制。 则最终需要调用前面定义的 release 方法释放连接;
优化后的 excuteUpdate() 方法定义如下
java
/**
* 通用的增删改的方法
* @param sql 调用者要执行的sql语句
* @param params sql语句中的占位符要赋值的参数
* return 返回受影响的行数
*/
public int excuteUpdate(String sql, Object... params) throws Exception{ // Object... params为可变长参数,可传可不传,可传任意长度的参数
//1,通过封装好的JDBCUtilV2获取数据库连接
Connection connection = JDBCUtilV2.getConnection();
//2,预编译SQL语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//3,为占位符赋值,执行SQL,接受返回结果
if (params != null && params.length > 0){
for (int i = 0; i < params.length; i++) { // 循环赋值
preparedStatement.setObject( i + 1, params[i]); // 注意占位符是从1开始,参数数组是从0开始。使用setObject不把类型写死
}
}
int row = preparedStatement.executeUpdate();
//4,释放资源
preparedStatement.close();
if (connection.getAutoCommit()){
JDBCUtilV2.release();
}
//5,返回结果
return row;
}6.3,转账事务的代码实现
① 先在JDBC数据库中创建 t_bank 表并插入数据,用于演示,SQL代码如下:
sql
-- 继续在JDBC的库中创建t_bank表
CREATE TABLE t_bank(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '账号主键',
account VARCHAR(20) NOT NULL UNIQUE COMMENT '账号',
money INT UNSIGNED COMMENT '金额,不能为负值') ;
INSERT INTO t_bank(account,money) VALUES
('zhangsan',1000),('lisi',1000);表内数据如下:
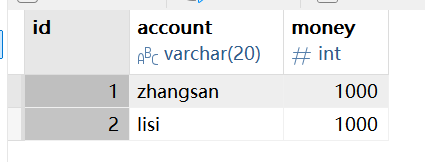
② 为此表的操作写一个DAO接口,定义加钱和减钱操作,Java代码如下:
java
public interface BankDao{
/**
* 添加金额
* @param id 给谁加钱
* @param money 加多少钱
* @return 添加成功返回1,添加失败返回0
*/
int addMoney(Integer id,Integer money);
/**
* 减少金额
* @param id 给谁减钱
* @param money 减多少钱
* @return 减成功返回1,减失败返回0
*/
int subMoney(Integer id,Integer money);
}③ Impl子包中写此接口的实现类 BankDAOImpl ,Java代码如下:
java
package com.hpu.senior.dao.impl;
import com.hpu.senior.dao.BankDAO;
import com.hpu.senior.dao.BaseDAO;
/**
* 对应t_bank表的实现类
*/
public class BankDAOImpl extends BaseDAO implements BankDAO {
@Override
public int addMoney(Integer id, Integer money) {
try {
String sql = "update t_bank set money = money + ? where id = ?";
return excuteUpdate(sql, money, id);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public int subMoney(Integer id, Integer money) {
try {
String sql = "update t_bank set money = money - ? where id = ?";
return excuteUpdate(sql, money, id);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}④ 写一个测试类测试转账业务:
java
/**
* 测试转账事务
*/
@Test
public void testTransaction(){
BankDAO bankDAO = new BankDAOImpl();
Connection connection = null;
try {
//1,获取连接,并进行手动事务控制
connection = JDBCUtilV2.getConnection();
connection.setAutoCommit(false);
//2,执行转账操作
bankDAO.addMoney(1, 100);
bankDAO.subMoney(2, 100);
//3,前面的多次操作无异常则提交事务
connection.commit();
} catch (Exception e) { // 有异常则会先执行回滚,然后抛捕获
try {
connection.rollback();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
throw new RuntimeException(e);
} finally {
JDBCUtilV2.release(); // 手动事务控制情况下要关闭
}
}运行结果如下,转账执行成功 :

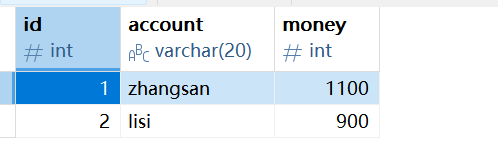
如果修改上述代码在转账的流程中增加异常,比如转账操作的代码改为:
java
bankDAO.addMoney(1, 100);
// 增加异常,再次进行测试
int i = 10/0;
bankDAO.subMoney(2, 100);再次进行转账测试,执行之后发现抛出异常、查看数据库发现数据不变:
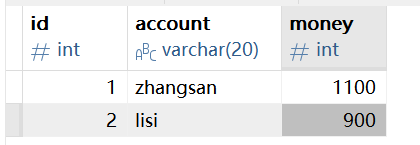
这说明,转账事务过程中出现异常之后,成功执行了回滚逻辑。
而代码中采用的 Threadlocal 完美保证当前事务中多次数据库操作使用的是同一个连接。