声明:本篇所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本篇博客所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本篇内容而引起的任何法律责任,作者不承担任何责任。使用本篇的内容即表示您同意本免责声明的所有条款和条件。
调教kimi,写出来如下的代码,测试通过。具体网站请仔细看代码注释。
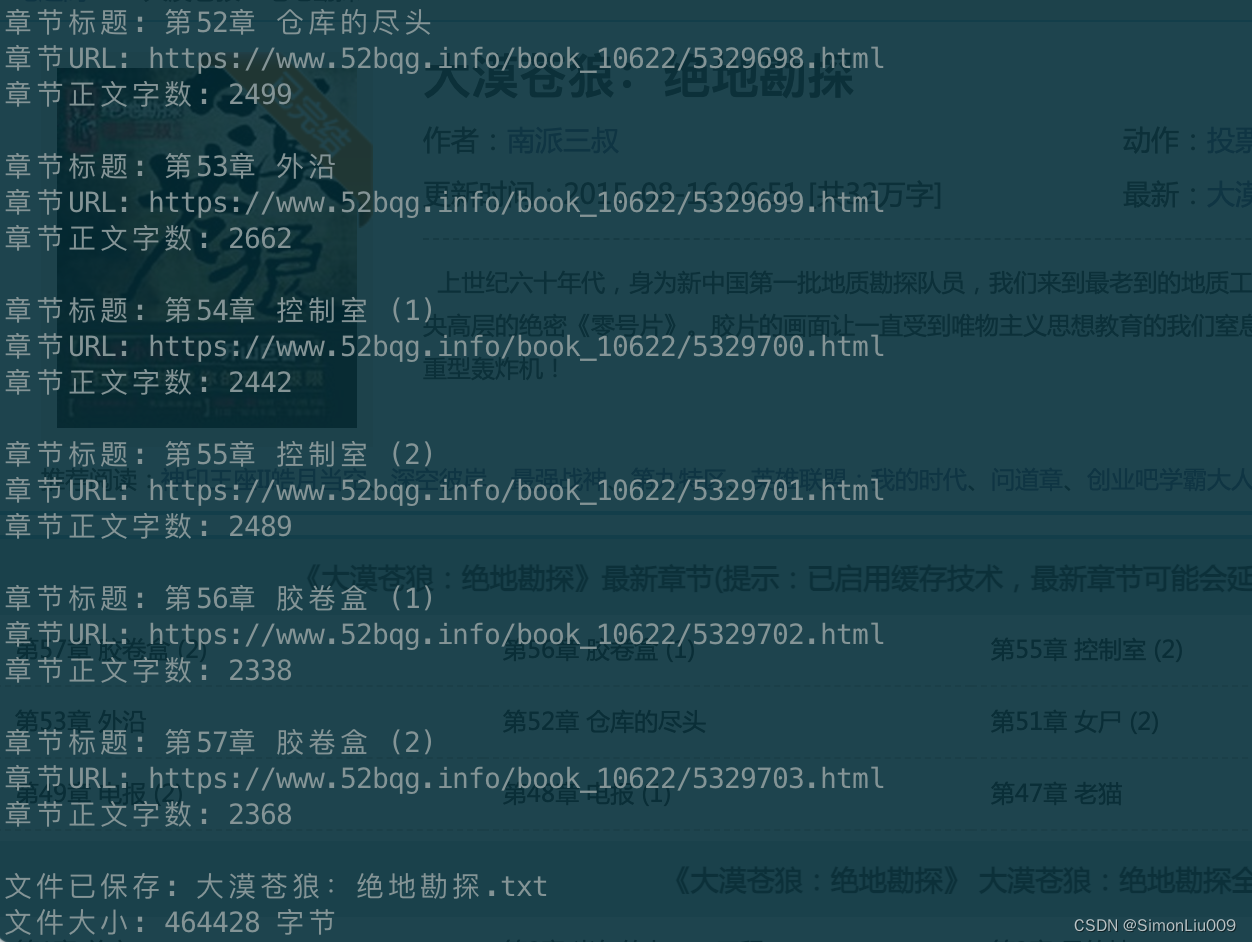
效果入下:
python
#!/usr/bin/env python
# -*- coding:utf-8 -*-
###
# File: /Users/simonliu/Documents/book/novel.py
# Project: /Users/simonliu/Documents/book
# Created Date: 2024-05-29 22:50:33
# Author: Simon Liu
# -----
# Last Modified: 2024-05-30 10:16:39
# Modified By: Simon Liu
# -----
# Copyright (c) 2024 SimonLiu Inc.
#
# May the force be with you.
# -----
# HISTORY:
# Date By Comments
# ---------- --- ----------------------------------------------------------
###
import requests
from bs4 import BeautifulSoup
import re
import os
# 自定义请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}
def get_book_title(chapter_list_url):
response = requests.get(chapter_list_url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 从<meta property="og:title" content="......"/>标签中提取书名
meta_tag = soup.find('meta', property="og:title")
if meta_tag and "content" in meta_tag.attrs:
return meta_tag['content']
return "Unknown Book Title"
def get_chapter_content(chapter_url):
response = requests.get(chapter_url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 从<div id="content">标签中提取正文
content_div = soup.find('div', id="content")
if content_div:
# 获取正文文本,并删除以"笔趣阁 www.52bqg.info"开头的那一行内容
chapter_text = content_div.get_text(separator='\n')
chapter_text = re.sub(r'^笔趣阁 www\.52bqg\.info.*\n', '', chapter_text, flags=re.M)
return chapter_text
else:
return "正文内容未找到"
def get_chapter_links(chapter_list_url):
response = requests.get(chapter_list_url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
chapter_links = soup.find_all('a', href=True)
chapters = []
chapter_pattern = re.compile(r'第(\d+)章')
for link in chapter_links:
link_text = link.text.strip()
match = chapter_pattern.search(link_text)
if match:
chapter_number = int(match.group(1))
if chapter_number >= 1: # 确保是第1章或之后的章节
chapters.append((link_text, link['href']))
first_chapter_index = next((i for i, (title, _) in enumerate(chapters) if '第1章' in title), None)
if first_chapter_index is not None:
chapters = chapters[first_chapter_index:]
return chapters
def save_chapters_to_file(chapters, book_title):
filename = book_title + '.txt'
with open(filename, 'w', encoding='utf-8') as file:
for title, chapter_relative_url in chapters:
chapter_url = chapter_list_url.rstrip('/') + '/' + chapter_relative_url.strip()
chapter_text = get_chapter_content(chapter_url)
# 打印章节信息到控制台
print(f'章节标题: {title}')
print(f'章节URL: {chapter_url}')
# 计算中文汉字的字数
chinese_chars = re.findall(r'[\u4e00-\u9fff]+', chapter_text)
total_chars = sum(len(re.sub(r'[\n\t ]', '', line)) for line in chinese_chars)
print(f'章节正文字数: {total_chars}\n')
# 写入章节标题和正文到文件
file.write(title + '\n')
file.write(chapter_text)
file.write('\n') # 添加空行以分隔章节
# 打印txt文件的名称和大小
filesize = os.path.getsize(filename)
print(f'文件已保存: {filename}')
print(f'文件大小: {filesize} 字节')
def main():
global chapter_list_url
# 用户输入小说的章节列表页面URL
chapter_list_url = input("请输入小说的章节列表页面URL: ")
# 获取并打印书名
book_title = get_book_title(chapter_list_url)
print(f'书名: {book_title}')
# 获取章节链接
chapters = get_chapter_links(chapter_list_url)
# 保存章节到文件
save_chapters_to_file(chapters, book_title)
if __name__ == "__main__":
main()