本篇主要介绍SQL优化的相关内容。
目录
[三、order by优化](#三、order by优化)
[四、gruop by优化](#四、gruop by优化)
对于每一次来自客户端的请求,我们通常都需要访问一次数据库,而访问数据库又是比较耗时的,因此我们如果能够掌握一定的SQL优化的技巧并熟练运用的话,就能大大缩减一条请求的响应时间,下面让我们来了解一下常见的SQL优化技巧。
一、数据插入
我们在执行插入操作时,需要进行一次磁盘IO将数据插到磁盘的相应位置,如果只插入一行记录还好,但如果要插入很多行数据呢?这意味着需要进行很多次磁盘IO,从而消耗大量的时间,这显然是不科学的。下面我们来了解三种更为高效的多行数据插入的方式。
批量插入多行
我们可以在一次insertSQL中批量插入多行数据,语法如下:
insert into 表名 values(数据),(数据),(数据);
这样我们只需要一次磁盘IO就能完成多行数据的插入。
通过事务插入
我们可以开启一个事务来进行多行数据的插入操作,这样只要将事务提交一次,就能完成批量数据行的插入。
start transcation;
insert语句
.....
commit;
Load指令
如果插入的数据量高达几百万行,显然前面两种方式也是不合适的,因此,我们需要通过Load指令来完成这种百万级的数据插入。
首先,我们首先要准备一个文件,里面包含要插入的数据
然后检查MySQL是否有开启 从本地文件中读取数据,具体为查看local _ infile参数的值,

值为1为开启,为0则为关闭,如果关闭可以通过set或者修改配置文件来开启。
开启之后,我们就可以通过load指令来完成百万级插入了,语法如下:
load data local infile '文件路径' into table 表名 fileds terminated by '文件中每个字段之间的分割符' lines terminated by '行分割符';
二、主键优化
在前面我们介绍索引的时候,主键索引的叶子节点里包含了整个行数据,而行数据又是包含在页逻辑结构中,而一个页的大小又是固定的16k,因此,一个页中能够存储的行数据是有限的,因此,如果主键是按乱序的数据进行插入的话,就有可能会出现页分类的现象,具体如下:
页分裂
首先我们来看一下主键顺序插入的情况:
主键顺序插入时,会先把一个页的空间放满,然后再放到另一个页中,这些页之间用指针连接
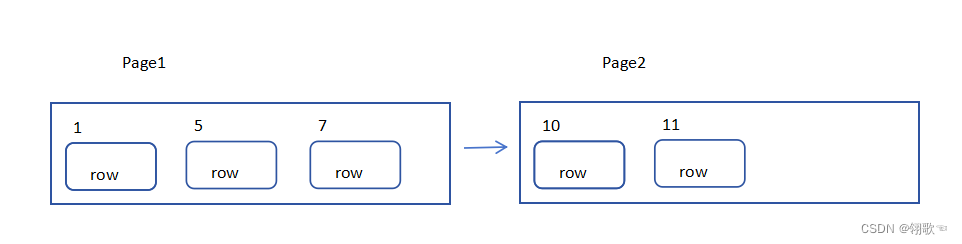
此时如果再插入一个主键值为13的数据,直接将数据放到主键为11的数据行后面即可。
如果是乱序插入会是什么情况呢?
我们在上图数据的基础上,再插入一个6,此时为了保证顺序,就需要把6插入到5的后面,但5后面已经有数据7了,因此无法进行插入此时,就会触发页分裂,page1会以5和7之间的间隙进行分裂,将分裂后半部分的数据放到一个新页中,然后将6插到5的后面,最后重新调整这几个页的顺序

从图中可以看出来,页分裂会导致页空间更加零散,从而降低了空间利用率,并且页分裂相对来说会比较耗时 。
相对页分裂还有页合并的情况,具体如下:
页合并
在MySQL中删除数据时,不会立马直接将数据删除,而是会先把要删除的数据进行标记,如果页中被标记的行的占比超过一个阈值(通常为50%),就会对页中的数据进行物理删除,然后再将后面页中的数据合并进来,这就是页合并:
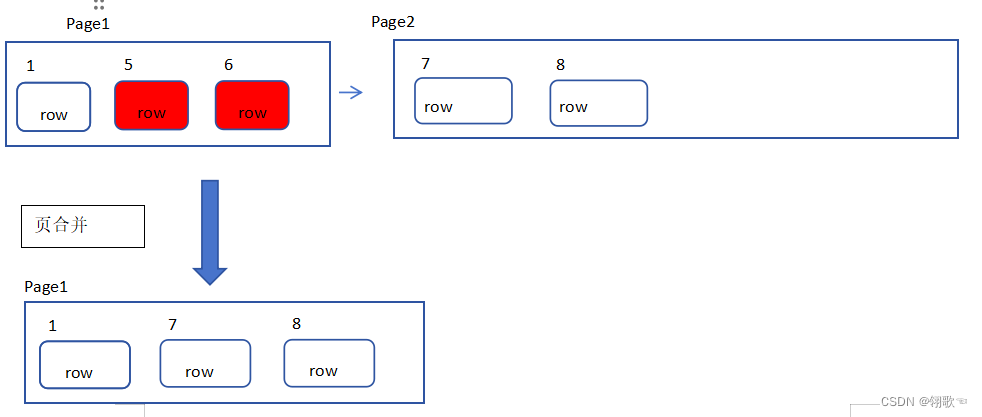
页合并的阈值是可以设置的,通过MERGE_THRESHOLD参数设置。
从上述页合并的流程可以看出,页合并可以在一定程度上增加页空间的利用率。
总的来说,对于主键优化的核心就是保证在主键插入时保证顺序插入,其次最好不要去修改主键。
三、order by优化
在MySQL中有两种数据排序的方式,一种是不走索引的全表扫描数据,然后将数据放入排序缓冲区中排序,最后再返回排序结果(Using filesort),还有一种则是直接通过走索引返回排序的数据(Using index),显然走索引的性能要远好于不走索引。因此我们在进行排序查询时,最好是进行走索引的排序查询,那如何查看到底是走了索引还是没走索引呢?我们可以通过explian的extra列来查看。例如,我们执行下面这条SQL:

可以发现由于age字段没有创建索引,从而查询时是Using filesort。我们创建好索引后,再查看一次

可以发现,Using index了
数据在索引中通常都是进行升序排序的,但有时我们也会需要查询降序排列,因此此时我们查询时就会导致反向扫描(Backward index scan),在MySQL8.x后的版本中,我们可以直接建立降序索引(索引数据降序排列),语法如下:
create index 索引名 on 表名(字段名 desc);
有时我们也需要对多个字段进行排序,那么此时最好根据这多个字段创建联合索引,并且在创建联合索引时需要根据查询时字段是要求降序查询,还是升序查询来决定是不是要创建降序索引。在排序查询中使用联合索引时,同样需遵从最左前缀法则。
如果某些SQL只能进行Using filesort,那么我们可以通过将排序缓冲区设置的更大一点来达到优化的效果,修改排序缓冲区的大小,可以通过修改参数sort_buffer_size的值来实现
四、gruop by优化
对于分组操作的优化主要也是使用索引,如果不使用索引则会全表扫描然后再分组,相对来说性能是比较低的,因此,通常情况下,建议给需要分组查询的字段创建索引。如果查询中是以多个字段进行分组,则可以适当创建对应的联合索引,需要注意的是,这里的联合索引也是需要遵从最左前缀法则,不然索引失效,任然会进行全表扫描。
五、limit优化
在执行limit进行分页查询时,性能会随着limit起始行的增加而降低,例如,在执行limit(20000,10)时需要将前20010条数据进行扫描,然后排序,最后返回20000到20010这10条数据,而limit(100,10)则只需要扫描并排序110条数据就能进行返回,性能要高很多。对于limit的优化,我们可以考虑从覆盖索引方面着手,对于回表操作进行优化,具体如下:
我们还是执行limit(20000,10)先通过主键索引查询出(20000,20010)的id,然后通过子查询的方式找出与该id对应的数据,具体如下:
select * from 表名 , (select id from 表名 order by id limit 20000,10) 别名 where 表名(别名).id = 子查询别名.id;
六、count优化
在MySQL中对于count()的使用通常有以下几种方式,count(*),count(数字),count(字段),count(主键)这四种方式按照执行性能从高到低的顺序如下:
- count(*):不取值,直接按行进行累加
- coun(主键):会取出每一行的主键值,交给服务层,服务层收到值后按行累加
- count(数字):不取值,对于每一行,服务层都会放入一个'1'进去,然后按行累加
- count(字段):会取该字段值,并判断是否为null,值为null,不累加,不为null,则累加,如果字段有not null约束则不进行判断,没有则还是会进行判断
因此在使用count时,尽量结合情况使用性能更好的count()的执行方式。
七、update优化
在MySQL中支持行级锁,在执行update语句时,会为update操作的数据行 加上一个行级锁,让其它MySQL的用户无法操作这一行,直到事务提交,才能释放该行级锁,但这这行级索是针对索引的,它锁住的是索引中的记录,因此,如果子段没有创建索引,则不会对该行加行级锁,而是直接加表锁,从而导致,其它要操作这张表的用户全都阻塞了。因此在进行update操作时尽量给update的字段创建索引,从而避免整张表被锁住。