🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
**💫个人格言: "如无必要,勿增实体"**

文章目录
- Python中的决策树算法探索
-
- 引言
- [1. 决策树基础理论](#1. 决策树基础理论)
-
- [1.1 算法概述](#1.1 算法概述)
- [1.2 构建过程](#1.2 构建过程)
- [2. Python中实现决策树的库介绍](#2. Python中实现决策树的库介绍)
-
- [2.1 Scikit-Learn](#2.1 Scikit-Learn)
- [2.2 XGBoost & LightGBM](#2.2 XGBoost & LightGBM)
- [3. 实战案例分析](#3. 实战案例分析)
-
- [3.1 数据准备与预处理](#3.1 数据准备与预处理)
- [3.2 模型构建与训练](#3.2 模型构建与训练)
- [3.3 预测与评估](#3.3 预测与评估)
- [4. 模型评估与调优方法](#4. 模型评估与调优方法)
-
- [4.1 评估指标](#4.1 评估指标)
- [4.2 调优策略](#4.2 调优策略)
- [5. 局限性与未来展望](#5. 局限性与未来展望)
-
- [5.1 局限性](#5.1 局限性)
- [5.2 未来展望](#5.2 未来展望)
- 结语
Python中的决策树算法探索
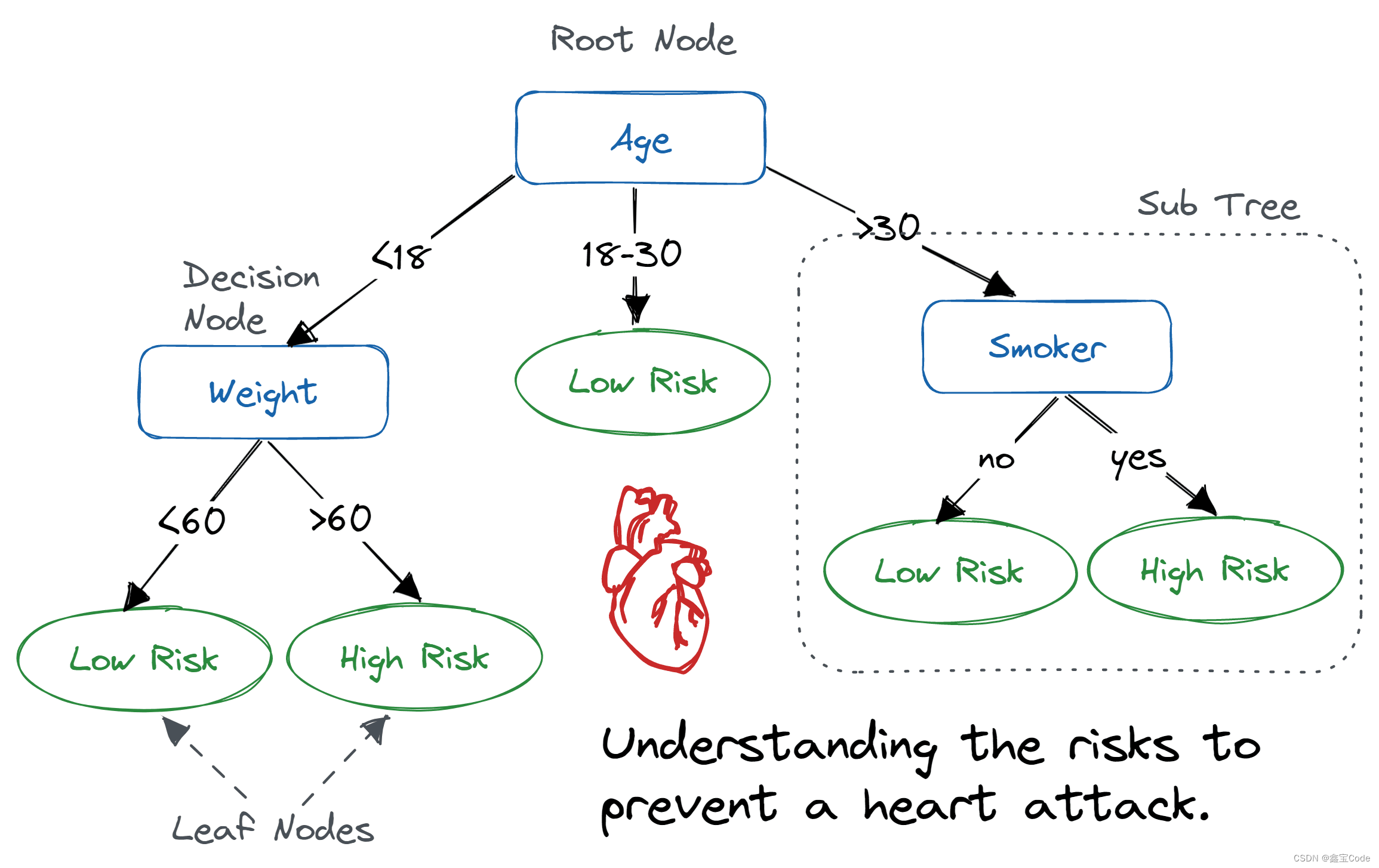
引言
决策树作为机器学习中的一种基础且强大的算法,因其易于理解和实现、能够处理分类和回归任务的特性而广受欢迎。本文旨在深入浅出地介绍决策树算法的基本原理,并通过Python编程语言实践其应用,帮助读者掌握如何利用Python构建及优化决策树模型。本文预计分为以下几个部分:决策树基础理论、Python中实现决策树的库介绍、实战案例分析、模型评估与调优方法,以及决策树算法的局限性与未来展望。
1. 决策树基础理论
1.1 算法概述
决策树是一种树形结构,其中每个内部节点表示一个特征上的测试,每个分支代表一个测试结果,而每个叶节点则代表一种类别或输出值。通过一系列的特征判断,决策树从根到某个叶节点的路径就对应了一个实例的分类或回归预测。
1.2 构建过程
- 特征选择:信息增益、基尼不纯度等指标用于衡量特征的重要性。
- 树的生成:递归地选择最优特征进行分割,直到满足停止条件(如节点纯净度达到阈值、达到最大深度等)。
- 剪枝:为防止过拟合,通过预剪枝和后剪枝减少树的复杂度。
2. Python中实现决策树的库介绍
2.1 Scikit-Learn

Scikit-Learn是Python中最广泛使用的机器学习库之一,提供了简单易用的API来实现决策树算法。主要类包括DecisionTreeClassifier用于分类任务,DecisionTreeRegressor用于回归任务。
2.2 XGBoost & LightGBM
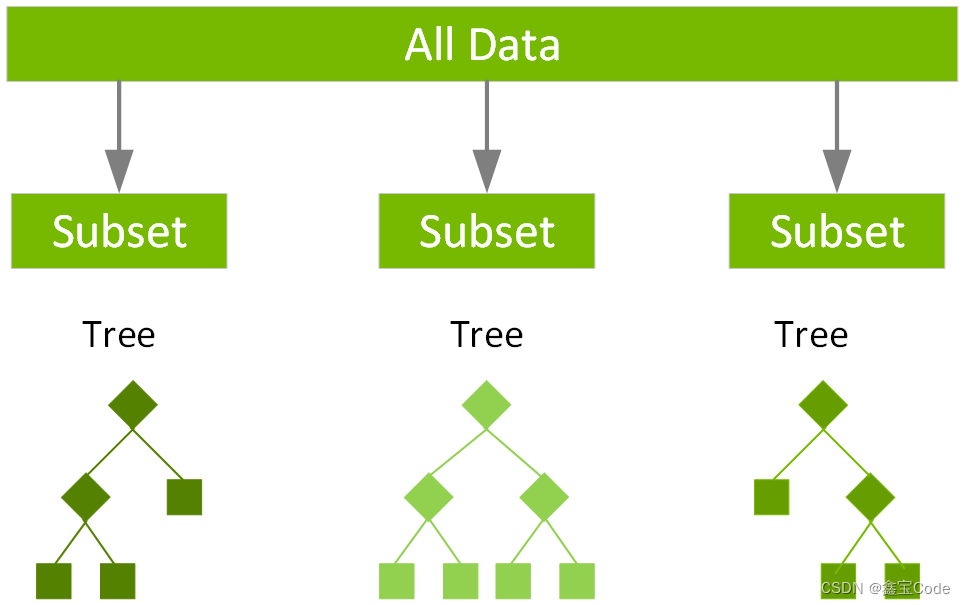
XGBoost和LightGBM是两个高级的梯度提升框架,它们虽不是直接的决策树库,但通过集成多棵决策树实现了更强大的学习能力。这些库特别适合大规模数据集和高维度特征空间。
3. 实战案例分析
3.1 数据准备与预处理
以经典的Iris数据集为例,首先导入必要的库并加载数据:
python
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)3.2 模型构建与训练
接着,创建决策树分类器并拟合数据:
python
dt_classifier = DecisionTreeClassifier(random_state=42)
dt_classifier.fit(X_train, y_train)3.3 预测与评估
对测试集进行预测,并评估模型性能:
python
from sklearn.metrics import accuracy_score
y_pred = dt_classifier.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))4. 模型评估与调优方法
4.1 评估指标
- 准确率是最直观的评价标准,但对于类别不平衡的数据集可能不适用。
- 混淆矩阵提供更详细的分类情况。
- ROC曲线与AUC值对于二分类问题尤其有用。
4.2 调优策略
- 调整树的深度与复杂度 :通过设置
max_depth、min_samples_leaf等参数控制模型复杂度。 - 交叉验证 :使用
GridSearchCV或RandomizedSearchCV寻找最佳参数组合。 - 特征重要性分析:利用决策树提供的特征重要性进行特征选择。
5. 局限性与未来展望
5.1 局限性
- 易于过拟合,特别是在树深较大时。
- 对连续特征的处理不如其他模型灵活。
- 可解释性虽然强,但当树变得非常复杂时,解释也会变得困难。
5.2 未来展望
- 集成学习:结合多种决策树的模型(如随机森林、梯度提升树)可以进一步提高预测性能。
- 自动化与可解释性的平衡:研究如何在保持高效与准确的同时,提高决策树模型的可解释性。
- 深度学习融合:探索决策树与深度神经网络的结合方式,挖掘两者优势。
结语
决策树算法以其直观、灵活的特点,在众多领域展现出强大的应用潜力。通过Python及其丰富的机器学习库,我们可以轻松实现并优化决策树模型,解决实际问题。随着技术的不断进步,决策树及其衍生算法将继续在数据科学领域扮演重要角色。希望本文能为读者在决策树的学习与应用上提供有价值的参考。