
1.stream
- 官方文档的意思, 就是 stream 类型
- 就可以用来模拟实现这种事件传播的机制~~
- stream 就是一个队列(阻塞队列)
- redis 作为一个消息队列的重要支撑
- 属于是 List blpop/brpop 升级版本.
- 用于做消息队列
2.geospatial
- 用来存储坐标 (经纬度)
- 存储一些点之后,就可以让用户给定一个坐标,去从刚才存储的点里进行査找.(按照半径,矩形区域.)
- 这个功能在"地图"应用中非常重要~~
3.HyperLogLog
- 应用场景只有一个,估算集合中的元素个数.
- Set,有一个应用场景,统计服务器的 UV(用户访问的次数)
- 使用 Set 当然可以统计 UV,但是最大的问题在于,如果 UV 数据量非常大,Set 就会消耗很多的内存空间~~
- 假设 Set 存储 userld, 每个 userld 按照8个字节算~~
- MB1亿 UV -> 8亿字节~~=>0.8G =>800MB(HyperLogLog 可以最多使用 12KB 空间,实现上述效果~)(不是 Redis 专有的~)
- 之所以, 要消耗这么大的空间Set 需要存储每个元素.
- 而 HyperLogLog 不存储元素的内容.
- 但是能够记录"元素的特征"从而在新增元素的时候,能够知道当前新增的元素,是一个已经存在的元素,还是一个崭新的第一次出现的元素.
- 用来计数 (记录出当前集合中有多少个不同的元素)但是不能告诉你这些元素都是啥~~
- The Redis HyperLogLog implementation uses up to 12 KB and provides a standard error of
0.81% 
- 这个东西具体还是得分析源码~~核心思路"位操作"=>精确性~~(存在一定的误差)
4.bitmaps(只针对整数)
- 使用 bit 位来表示整数.
- 0000 0000 0000 0000 0000 0000 0000 0000
- 位图本质上, 就还是一个 集合.属于是 Set 类型针对整数的特化版本~~(节省空间~~)
- HyperLogLog ~.
更省空间呀!!
既可以存储数字,也可以存储字符串~.不存储元素内容,只是计数效果~~ - hyperloglog 存储元素的时候,提取特征的过程
是不可逆的!!(信息量丢失了) - bitmap,类型存储元素了!!
5.bitfields
- C 进阶,自定义数据类型 =>结构体在内存中的布局
- 位段 (不是 段位) =>也叫做位域
- struct Test {
int a:8;
int b:16;
int c:8; - 此处的数字,就描述这个成员实际占几个 bit 位!!
位域 本质上是让我们精确进行位操作的一种方法~~ - 上述 Redis 中的 bitfield 和C中的位域,非常相似的!!
- bitfield 可以理解成一串二进制序列(字节数组)
- 同时可以把这个字节数组中的某几个位,赋予特定的含义, 并且可以进行 读取/修改/算术运算 相关操作~~
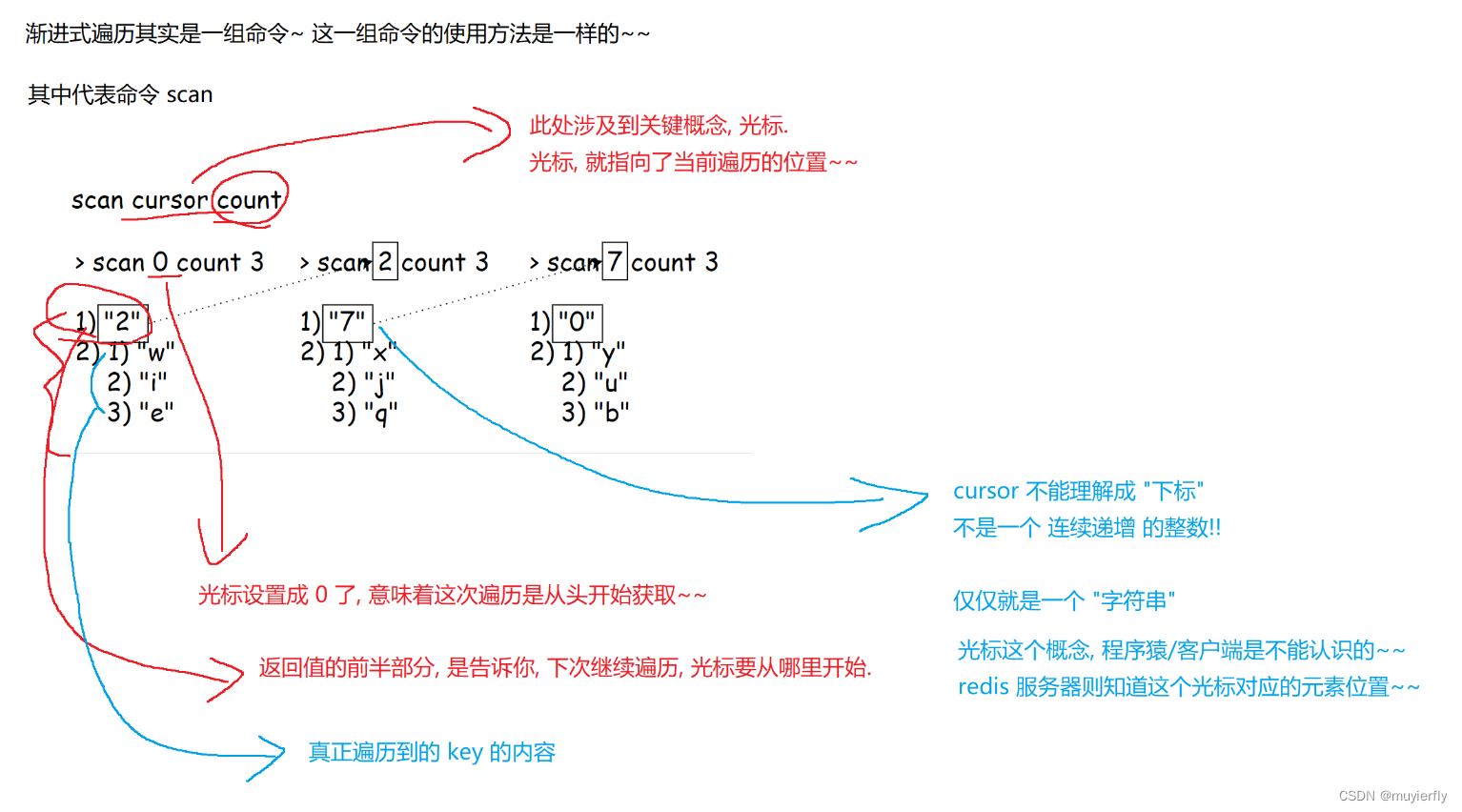
6.渐进式遍历
Redis 使⽤ scan 命令进⾏渐进式遍历键,进⽽解决直接使⽤ keys 获取键时可能出现的阻塞问
题。每次 scan 命令的时间复杂度是 O(1),但是要完整地完成所有键的遍历,需要执⾏多次 scan。
- keys keys *一次性的把整个 redis 中所有的 key 都获取到.(**这个操作比较危险.**可能会一下子得到太多的 key, 阻塞 redis 服务器!)
- 通过渐进式遍历,就可以做到,既能够获取到所有的 key, 同时又不会卡死服务器~
- 不是一个命令,把所有的 key 都拿到.
而是每执行一次命令,只获取到其中的一小部分~~这样的话保证当前这一次操作不会太卡~~
要想得到所有的 key 就需要多次遍历了~~多次执行渐进式遍历命令(化整为零~)
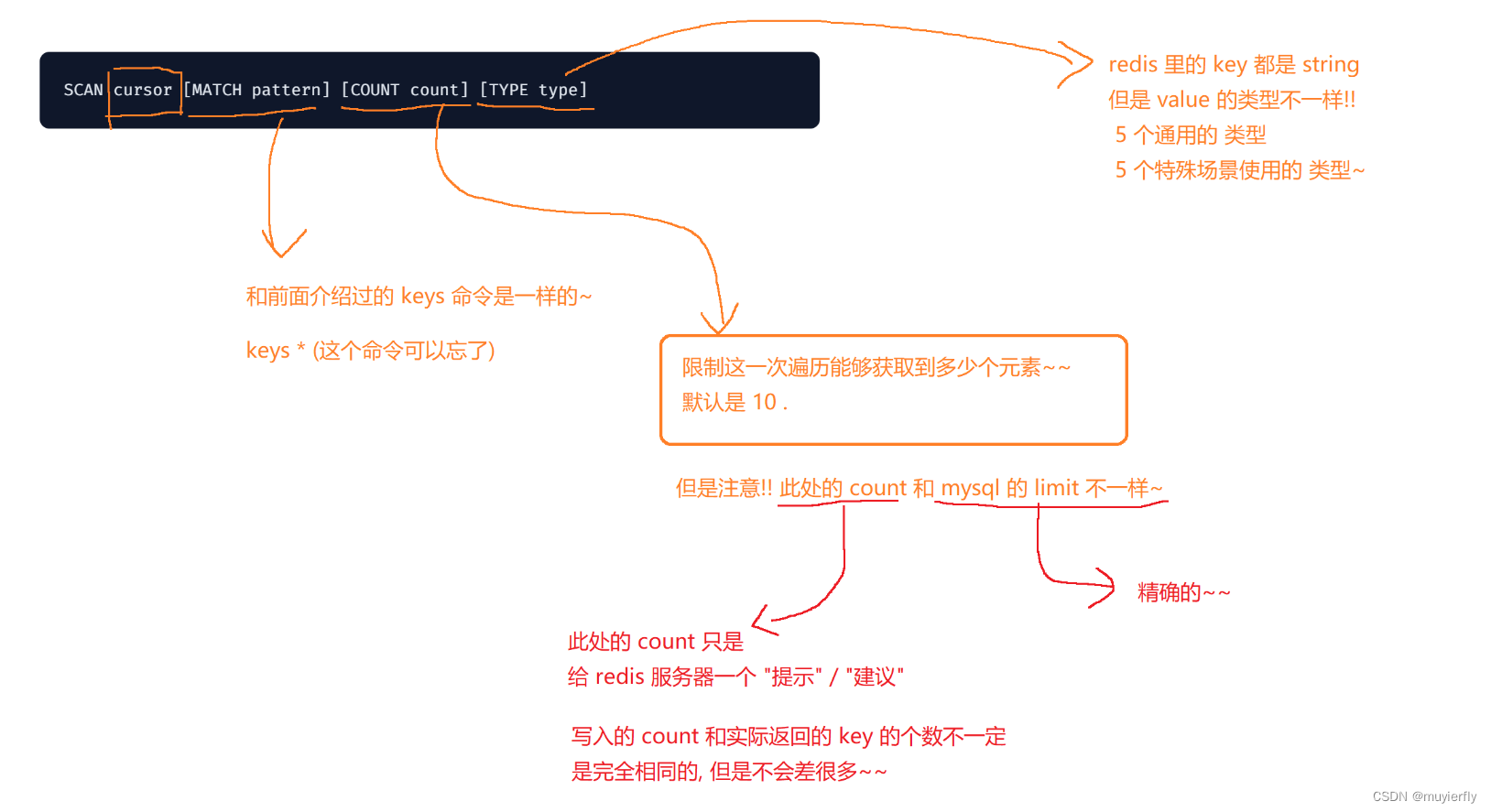
6.1 scan
以渐进式的⽅式进⾏键的遍历。
语法:
SCAN cursor MATCH pattern COUNT count TYPE type
命令有效版本:2.8.0 之后
时间复杂度:O(1)
返回值:下⼀次 scan 的游标(cursor)以及本次得到的键。
⽰例:
redis 127.0.0.1:6379> scan 0
- "17"
- "key:12"
- "key:8"
- "key:4"
- "key:14"
- "key:16"
- "key:17"
- "key:15"
- "key:10"
- "key:3"
- "key:7"
- "key:1"
redis 127.0.0.1:6379> scan 17- "0"
- "key:5"
- "key:18"
- "key:0"
- "key:2"
- "key:19"
- "key:13"
- "key:6"
- "key:9"
- "key:11"
- count 这里的 数字,不是说每次遍历都得设置成一样~~
- 这里的渐进式遍历,在遍历过程中,不会在服务器这边存储任何的状态信息此处的遍历是随时可以终止的~~不会对服务器产生任何的副作用~~
- 渐进性遍历 scan 虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、删除),可能导致遍历时键的重复遍历或者遗漏,这点务必在实际开发中考虑。


