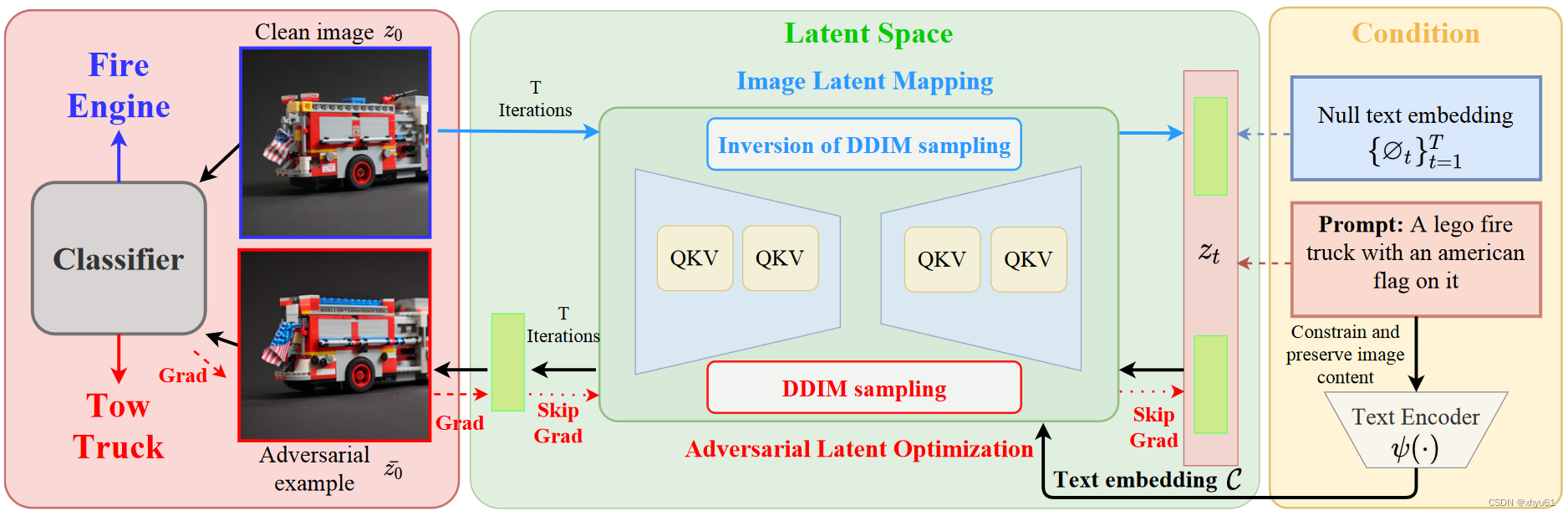
 图2:Adversarial Content Attack的流程。首先使用Image Latent Mapping将图像映射到潜变量空间。然后,用Adversarial Latent Optimization生成对抗性样本。最后,生成的对抗性样本可以欺骗到目标分类模型。
图2:Adversarial Content Attack的流程。首先使用Image Latent Mapping将图像映射到潜变量空间。然后,用Adversarial Latent Optimization生成对抗性样本。最后,生成的对抗性样本可以欺骗到目标分类模型。
3.1 Image Latent Mapping
对于扩散模型,最简单的图像映射是DDIM采样的逆过程,使用prompt P \mathcal{P} P的条件嵌入 C = ψ ( P ) \mathcal{C}=\psi(\mathcal{P}) C=ψ(P),基于常微分方程过程可以在小步长限制下反转:
z t + 1 = α t + 1 α t z t + α t + 1 ( 1 α t + 1 − 1 − 1 α t − 1 ) ⋅ ϵ θ ( z t , t , C ) (2) z_{t+1}=\sqrt{\frac{\alpha_{t+1}}{\alpha_t}}z_t+\sqrt{\alpha_{t+1}}(\sqrt{\frac{1}{\alpha_{t+1}}-1}-\sqrt{\frac{1}{\alpha_t}-1})\cdot\epsilon_\theta(z_t,t,\mathcal{C})\tag{2} zt+1=αtαt+1 zt+αt+1 (αt+11−1 −αt1−1 )⋅ϵθ(zt,t,C)(2)
其中 z 0 z_0 z0是给定的真实图像。图像的描述prompt通常由图像描述模型(如BLIP v2)自动生成。
给定 w w w作为引导比例参数, ∅ = ψ ("") \varnothing=\psi\text{("")} ∅=ψ("")是空文本的嵌入表示,无分类器引导(classifier-free guidance)预测可以表示为:
ϵ ~ θ ( z t , t , C , ∅ ) = w ⋅ ϵ θ ( z t , t , C ) + ( 1 − w ) ⋅ ϵ θ ( z t , t , ∅ ) (3) \tilde{\epsilon}\theta(z_t,t,\mathcal{C},\varnothing)=w\cdot\epsilon\theta(z_t,t,\mathcal{C})+(1-w)\cdot\epsilon_\theta(z_t,t,\varnothing)\tag{3} ϵ~θ(zt,t,C,∅)=w⋅ϵθ(zt,t,C)+(1−w)⋅ϵθ(zt,t,∅)(3)
Stable Diffusion中 w = 7.5 w=7.5 w=7.5。噪声是通过 ϵ θ \epsilon_\theta ϵθ预测出来的,用于去噪过程,因此每一步都会有细微的误差,随着许多步去噪,导致误差累积越来越大,破坏了噪声的高斯分布,诱发不真实的视觉效果。
为减小累计误差,对每一步 t t t优化空文本嵌入 ∅ \varnothing ∅。首先使用 w = 1 w=1 w=1在DDIM的逆过程输出一系列潜变量表示 { z 0 ∗ , ⋯ , z T ∗ } \{z_0^*,\cdots,z_T^*\} {z0∗,⋯,zT∗},其中 z 0 ∗ = z 0 z_0^*=z_0 z0∗=z0。然后对于时间戳 { T , ⋯ , 1 } \{T,\cdots,1\} {T,⋯,1},使用 w = 7.5 w=7.5 w=7.5, z ˉ T = z t \bar{z}T=z_t zˉT=zt在 N N N次迭代中进行了如下优化:
min ∅ t ∣ ∣ z t − 1 ∗ − z t − 1 ( z ˉ t , t , C , ∅ ) ∣ ∣ 2 2 (4) \min{\varnothing_t}||z_{t-1}^*-z_{t-1}(\bar{z}t,t,\mathcal{C},\varnothing)||2^2\tag{4} ∅tmin∣∣zt−1∗−zt−1(zˉt,t,C,∅)∣∣22(4)
z t − 1 ( z ˉ t , t , C , ∅ ) = α t − 1 α t z ˉ t + α t − 1 ( 1 α t − 1 − 1 − 1 α t − 1 ) ⋅ ϵ ~ θ ( z t , t , C , ∅ ) (5) z{t-1}(\bar{z}t,t,\mathcal{C},\varnothing)=\sqrt{\frac{\alpha{t-1}}{\alpha_t}}\bar{z}t+\sqrt{\alpha{t-1}}(\sqrt{\frac{1}{\alpha{t-1}}-1}-\sqrt{\frac{1}{\alpha_t}-1})\cdot\tilde{\epsilon}_\theta(z_t,t,\mathcal{C},\varnothing)\tag{5} zt−1(zˉt,t,C,∅)=αtαt−1 zˉt+αt−1 (αt−11−1 −αt1−1 )⋅ϵ~θ(zt,t,C,∅)(5)
在每一步的最后,将 z ˉ t − 1 \bar{z}{t-1} zˉt−1更新为 z t − 1 ( z ˉ t , t , C , ∅ t ) z{t-1}(\bar{z}_t,t,\mathcal{C},\varnothing_t) zt−1(zˉt,t,C,∅t)。最后得到原始图像在潜变量空间内的表示,包含噪声 z ˉ T \bar{z}_T zˉT,空文本嵌入 ∅ t \varnothing_t ∅t和文本嵌入 C = ψ ( P ) \mathcal{C}=\psi(\mathcal{P}) C=ψ(P)。
3.2 Adversarial Latent Optimization
本节提出了一种针对潜变量的优化方法,最大化在非限制对抗样本上的攻击性能。经过image latent mapping后得到的潜变量空间中,空文本嵌入 ∅ t \varnothing_t ∅t确保了重建的图像的质量,条件嵌入 C \mathcal{C} C保证了图像的语义信息。同时优化两种嵌入并不现实,考虑到噪声 z ˉ T \bar{z}_T zˉT很大程度上表示了潜变量空间中图像的信息,因此选择优化噪声 z ˉ T \bar{z}_T zˉT。但是这种优化的复杂梯度计算和取值范围溢出的问题仍然是挑战。
基于image latent mapping生成的潜变量,将扩散模型中的去噪过程Eq.5定义为 Ω ( ⋅ ) \Omega(\cdot) Ω(⋅),其包含 T T T次迭代:
Ω ( z T , T , C , { ∅ t } t = 1 T ) = z 0 ( z 1 ( ⋯ , ( z T − 1 , T − 1 , C , ∅ T − 1 ) , ⋯ , 1 , C , ∅ 1 ) , 0 , C , ∅ 0 ) (6) \Omega(z_T,T,\mathcal{C},\{\varnothing_t\}{t=1}^T)=z_0(z_1(\cdots,(z{T-1},T-1,\mathcal{C},\varnothing_{T-1}),\cdots,1,\mathcal{C},\varnothing_1),0,\mathcal{C},\varnothing_0)\tag{6} Ω(zT,T,C,{∅t}t=1T)=z0(z1(⋯,(zT−1,T−1,C,∅T−1),⋯,1,C,∅1),0,C,∅0)(6)
由此,重新构建的模型可表示为 z ˉ 0 = Ω ( z T , T , C , { ∅ t } ) \bar{z}0=\Omega(z_T,T,\mathcal{C},\{\varnothing_t\}) zˉ0=Ω(zT,T,C,{∅t})。结合Eq.7,对抗性目标优化可以表示为:
max δ L ( F θ ( z ˉ 0 , y ) ) , s . t . ∣ ∣ δ ∣ ∣ ∞ ≤ κ , z ˉ 0 = Ω ( z T + δ , T , C , { ∅ t } ) (7) \max\delta \mathcal{L}(\mathcal{F}_\theta(\bar{z}0,y)),\ s.t.||\delta||\infty\leq\kappa,\ \bar{z}_0=\Omega(z_T+\delta,T,\mathcal{C},\{\varnothing_t\})\tag{7} δmaxL(Fθ(zˉ0,y)), s.t.∣∣δ∣∣∞≤κ, zˉ0=Ω(zT+δ,T,C,{∅t})(7)
其中 z ˉ 0 \bar{z}_0 zˉ0是自然图像, δ \delta δ是潜变量空间中的对抗性扰动。
损失函数包含两部分:
- 交叉熵损失 L c e \mathcal{L}_{ce} Lce,用于引导对抗性样本误导分类器;
- 均方误差损失 L m s e \mathcal{L}_{mse} Lmse,用于引导对抗性样本在 l 2 l_2 l2距离上尽可能接近真实的干净样本。
由此,完整的损失函数 L \mathcal{L} L可以表示为:
L ( F θ ( z ˉ 0 ) , y , z 0 ) = L c e ( F θ ( z ˉ 0 ) , y ) − β ⋅ L m s e ( z ˉ 0 , z 0 ) \mathcal{L}(\mathcal{F}\theta(\bar{z}0),y,z_0)=\mathcal{L}{ce}(\mathcal{F}\theta(\bar{z}0),y)-\beta\cdot\mathcal{L}{mse}(\bar{z}_0,z_0) L(Fθ(zˉ0),y,z0)=Lce(Fθ(zˉ0),y)−β⋅Lmse(zˉ0,z0)
本文中 β = 0.1 \beta=0.1 β=0.1,损失函数的目标是最大化交叉熵损失冰最小化和干净样本的 l 2 l_2 l2距离。为保证 z 0 z_0 z0和 z ˉ 0 \bar{z}0 zˉ0的一致性,假设当 δ \delta δ很小时(即 ∣ ∣ δ ∣ ∣ ∞ ≤ κ ||\delta||\infty\leq\kappa ∣∣δ∣∣∞≤κ时), δ \delta δ不会改变 z 0 z_0 z0和 z ˉ 0 \bar{z}_0 zˉ0的一致性,关键在于产生最大分类损失的 δ \delta δ。
类似于传统的对抗攻击,使用基于梯度的技术,通过 δ ≃ η ∇ z T L ( F θ ( z ˉ 0 ) , y ) \delta\simeq\eta\nabla_{z_T}\mathcal{L}(\mathcal{F}\theta(\bar{z}0),y) δ≃η∇zTL(Fθ(zˉ0),y)来估计噪声 δ \delta δ,其中 η \eta η是发生在梯度方向上的扰动量。利用链式规则对 ∇ z T L ( F θ ( z ˉ 0 ) , y ) \nabla{z_T}\mathcal{L}(\mathcal{F}\theta(\bar{z}0),y) ∇zTL(Fθ(zˉ0),y)进行展开,可以得到如下的导数项:
∇ z T L ( F θ ( z ˉ 0 ) , y ) = ∂ L ∂ z ˉ 0 ⋅ ∂ z ˉ 0 ∂ z 1 ⋅ ∂ z 1 ∂ z 2 ⋯ ∂ z T − 1 ∂ z T (9) \nabla{z_T}\mathcal{L}(\mathcal{F}_\theta(\bar{z}_0),y)=\frac{\partial\mathcal{L}}{\partial\bar{z}_0}\cdot\frac{\partial\bar{z}0}{\partial z_1}\cdot\frac{\partial z_1}{\partial z_2}\cdots\frac{\partial z{T-1}}{\partial z_T}\tag{9} ∇zTL(Fθ(zˉ0),y)=∂zˉ0∂L⋅∂z1∂zˉ0⋅∂z2∂z1⋯∂zT∂zT−1(9)
Skip Gradient
尽管梯度是可导的,通过此式推导出完整的计算图是不可行的。
- ∂ L ∂ z ˉ 0 \frac{\partial\mathcal{L}}{\partial\bar{z}_0} ∂zˉ0∂L是分类器关于重构图像 z ˉ 0 \bar{z}_0 zˉ0的导数,并提供对抗梯度方向。
- ∂ z t ∂ z t + 1 \frac{\partial z_t}{\partial z_{t+1}} ∂zt+1∂zt,每一次导数的计算都代表一次反向传播的计算。
- 一个完整的去噪过程累积了 T T T个计算图,导致内存溢出。
本文提出了Skip Gradient来估计 ∂ L ∂ z ˉ 0 ⋅ ∂ z ˉ 0 ∂ z 1 ⋅ ∂ z 1 ∂ z 2 ⋯ ∂ z T − 1 ∂ z T \frac{\partial\mathcal{L}}{\partial\bar{z}_0}\cdot\frac{\partial\bar{z}0}{\partial z_1}\cdot\frac{\partial z_1}{\partial z_2}\cdots\frac{\partial z{T-1}}{\partial z_T} ∂zˉ0∂L⋅∂z1∂zˉ0⋅∂z2∂z1⋯∂zT∂zT−1。去噪过程旨在消除DDIM采样中加入的高斯噪声,DDIM利用重参数化技巧,在任意第 t t t步下进行闭式采样:
z t = α t z 0 + 1 − α t ε , ε ∼ N ( 0 , I ) (10) z_t=\sqrt{\alpha_t}z_0+\sqrt{1-\alpha_t}\varepsilon,\ \varepsilon\sim\mathcal{N}(0,I)\tag{10} zt=αt z0+1−αt ε, ε∼N(0,I)(10)
对Eq.10变形,得到 z 0 = 1 α t z t − 1 − α t α t ε z_0=\frac{1}{\sqrt{\alpha_t}}z_t-\sqrt{\frac{1-\alpha_t}{\alpha_t}}\varepsilon z0=αt 1zt−αt1−αt ε。由此,得到 ∂ z 0 ∂ z t = 1 α t \frac{\partial z_0}{\partial z_t}=\frac{1}{\sqrt{\alpha_t}} ∂zt∂z0=αt 1。Stable Diffusion中,步长 t t t最多是1000,因此有 lim t → 1000 ∂ z 0 ∂ z t = lim t → 1000 1 α t ≈ 14.58 \lim_{t\rightarrow 1000}\frac{\partial z_0}{\partial z_t}=\lim_{t\rightarrow 1000}\frac{1}{\sqrt{\alpha_t}}\approx 14.58 limt→1000∂zt∂z0=limt→1000αt 1≈14.58。总结而言, ∂ z 0 ∂ z t \frac{\partial z_0}{\partial z_t} ∂zt∂z0可以被看做常数 ρ \rho ρ,Eq.9可以变为 ∇ z T L ( F θ ( z ˉ 0 ) , y ) = ρ ∂ L ∂ z ˉ 0 \nabla_{z_T}\mathcal{L}(\mathcal{F}_\theta(\bar{z}_0),y)=\rho\frac{\partial\mathcal{L}}{\partial\bar{z}_0} ∇zTL(Fθ(zˉ0),y)=ρ∂zˉ0∂L。综上所述,Skip Gradients估计了去噪过程的梯度,减少了计算和存储需求。
Differentiable Boundary Processing
扩散模型没有严格限制 z ˉ 0 \bar{z}_0 zˉ0的数值取值范围, z T z_T zT的修改可能会导致其取值范围被超出。由此引入differentiable boundary processing ϱ ( ⋅ ) \varrho(\cdot) ϱ(⋅)。 ϱ ( ⋅ ) \varrho(\cdot) ϱ(⋅)将超出 0 , 1 0,1 0,1范围的数值压缩到 0 , 1 0,1 0,1中:
ϱ ( x ) = { tanh ( 1000 x ) / 10000 x < 0 x 0 ≤ x < 1 tanh ( 1000 ( x − 1 ) ) / 10001 x > 1 (11) \varrho(x) = \begin{cases} \tanh(1000x)/10000 \qquad & x<0 \\ x \qquad & 0\leq x<1 \\ \tanh(1000(x-1))/10001 \qquad & x > 1 \end{cases}\tag{11} ϱ(x)=⎩ ⎨ ⎧tanh(1000x)/10000xtanh(1000(x−1))/10001x<00≤x<1x>1(11)
接下来定义 Π κ \Pi_\kappa Πκ为对抗扰动 δ \delta δ在 κ \kappa κ球面上的投影。引入动量 g g g,将优化对抗性潜变量为:
g k ← μ ⋅ g k − 1 + ∇ z T L ( F θ ( ( ϱ ( z ˉ 0 ) , y ) ) ) ∣ ∣ ∇ z T L ( F θ ( ( ϱ ( z ˉ 0 ) , y ) ) ) ∣ ∣ 1 (12) g_k\leftarrow \mu\cdot g_{k-1}+\frac{\nabla_{z_T}\mathcal{L}(\mathcal{F}\theta((\varrho(\bar{z}0),y)))}{||\nabla{z_T}\mathcal{L}(\mathcal{F}\theta((\varrho(\bar{z}0),y)))||1}\tag{12} gk←μ⋅gk−1+∣∣∇zTL(Fθ((ϱ(zˉ0),y)))∣∣1∇zTL(Fθ((ϱ(zˉ0),y)))(12)
δ k ← Π κ ( δ k − 1 + η ⋅ sign ( g k ) ) (13) \delta_k\leftarrow\Pi\kappa(\delta{k-1}+\eta\cdot\text{sign}(g_k))\tag{13} δk←Πκ(δk−1+η⋅sign(gk))(13)
综上所述,adversarial latent optimization采用跳跃梯度来确定去噪过程的梯度,结合可微边界处理来调节对抗样本的取值范围,根据梯度进行迭代优化。结合图像潜在映射,算法1中说明了adversarial content attack的详细过程。
