介绍
蜂群优化算法(Bee Algorithm, BA)及其变种主要模拟蜜蜂的觅食行为,以解决复杂的优化问题。这类算法通过蜜蜂之间的信息交流和协作来探索解空间,寻找全局最优解。主要应用于参数优化,结构优化,机器学习,数据挖掘等各个领域。
本文示例
本文将应用于数据挖掘,来解决聚类问题
代码
bee_algorithm_clustering
matlab
function bee_algorithm_clustering(data, num_clusters, num_bees, num_iterations, elite_bees, selected_bees, patch_size)
% data: 输入的数据集 (rows: samples, columns: features)
% num_clusters: 聚类数
% num_bees: 总蜜蜂数量
% num_iterations: 最大迭代次数
% elite_bees: 精英蜜蜂数量
% selected_bees: 选定蜜蜂数量
% patch_size: 搜索邻域大小
% 初始化蜜蜂群
[num_samples, num_features] = size(data);
bees = initialize_bees(num_bees, num_clusters, num_features);
% 计算每只蜜蜂的适应度
fitness = evaluate_bees(bees, data);
for iter = 1:num_iterations
% 排序蜜蜂根据适应度
[fitness, idx] = sort(fitness);
bees = bees(idx, :);
% 搜索精英蜜蜂邻域
for i = 1:elite_bees
new_bees = local_search(bees(i, :), patch_size, num_clusters, num_features);
new_fitness = evaluate_bees(new_bees, data);
% 选择适应度更好的蜜蜂
[best_new_fitness, best_idx] = min(new_fitness);
if best_new_fitness < fitness(i)
bees(i, :) = new_bees(best_idx, :);
fitness(i) = best_new_fitness;
end
end
% 搜索选定蜜蜂邻域
for i = (elite_bees+1):selected_bees
new_bees = local_search(bees(i, :), patch_size, num_clusters, num_features);
new_fitness = evaluate_bees(new_bees, data);
% 选择适应度更好的蜜蜂
[best_new_fitness, best_idx] = min(new_fitness);
if best_new_fitness < fitness(i)
bees(i, :) = new_bees(best_idx, :);
fitness(i) = best_new_fitness;
end
end
% 更新其余蜜蜂位置
for i = (selected_bees+1):num_bees
bees(i, :) = initialize_bees(1, num_clusters, num_features);
fitness(i) = evaluate_bees(bees(i, :), data);
end
% 输出当前最优适应度
disp(['Iteration ', num2str(iter), ': Best Fitness = ', num2str(fitness(1))]);
end
% 输出最优聚类中心
best_bee = reshape(bees(1, :), num_clusters, num_features);
disp('Best Cluster Centers:');
disp(best_bee);
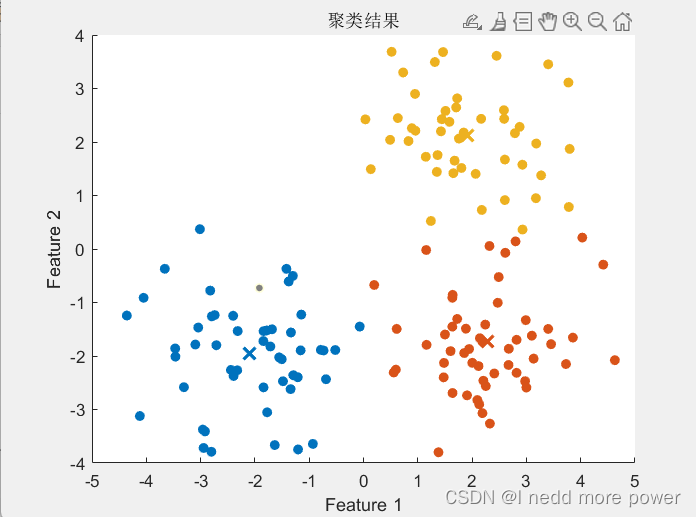
% 绘制聚类结果
distances = pdist2(data, best_bee);
[~, assignments] = min(distances, [], 2);
figure;
hold on;
colors = lines(num_clusters);
for k = 1:num_clusters
scatter(data(assignments == k, 1), data(assignments == k, 2), 36, colors(k, :), 'filled');
scatter(best_bee(k, 1), best_bee(k, 2), 100, colors(k, :), 'x', 'LineWidth', 2);
end
title('聚类结果');
xlabel('Feature 1');
ylabel('Feature 2');
hold off;
end
function bees = initialize_bees(num_bees, num_clusters, num_features)
% 随机初始化蜜蜂位置
bees = rand(num_bees, num_clusters * num_features);
end
function fitness = evaluate_bees(bees, data)
% 评估每只蜜蜂的适应度 (SSE)
[num_bees, ~] = size(bees);
[num_samples, ~] = size(data);
num_clusters = size(bees, 2) / size(data, 2);
fitness = zeros(num_bees, 1);
for i = 1:num_bees
centers = reshape(bees(i, :), num_clusters, size(data, 2));
distances = pdist2(data, centers);
[~, assignments] = min(distances, [], 2);
fitness(i) = sum(sum((data - centers(assignments, :)).^2));
end
end
function new_bees = local_search(bee, patch_size, num_clusters, num_features)
% 局部搜索生成新蜜蜂
new_bees = repmat(bee, patch_size, 1);
perturbations = randn(patch_size, num_clusters * num_features) * 0.1;
new_bees = new_bees + perturbations;
end说明
bee_algorithm_clustering 函数:该函数是蜂群优化算法的主函数,用于执行聚类任务。
data:输入的数据集。
num_clusters:要找到的聚类中心的数量。
num_bees:蜜蜂总数。
num_iterations:最大迭代次数。
elite_bees:精英蜜蜂的数量。
selected_bees:选定蜜蜂的数量。
patch_size:搜索邻域的大小。
初始化蜜蜂群:使用随机位置初始化蜜蜂
评估适应度:使用均方误差(SSE)评估每只蜜蜂的适应度
局部搜索:对精英蜜蜂和选定蜜蜂进行局部搜索,生成新的蜜蜂并评估其适应度
更新蜜蜂位置:根据适应度更新蜜蜂的位置
输出结果:输出最佳聚类中心
使用以下代码生成数据集,然后保存名为run_bee_algorithm_clustering,运行
matlab
% 生成数据集
rng(1); % 设置随机种子以便重复实验
num_samples_per_cluster = 50;
cluster1 = bsxfun(@plus, randn(num_samples_per_cluster, 2), [2, 2]);
cluster2 = bsxfun(@plus, randn(num_samples_per_cluster, 2), [-2, -2]);
cluster3 = bsxfun(@plus, randn(num_samples_per_cluster, 2), [2, -2]);
data = [cluster1; cluster2; cluster3];
% 绘制数据集
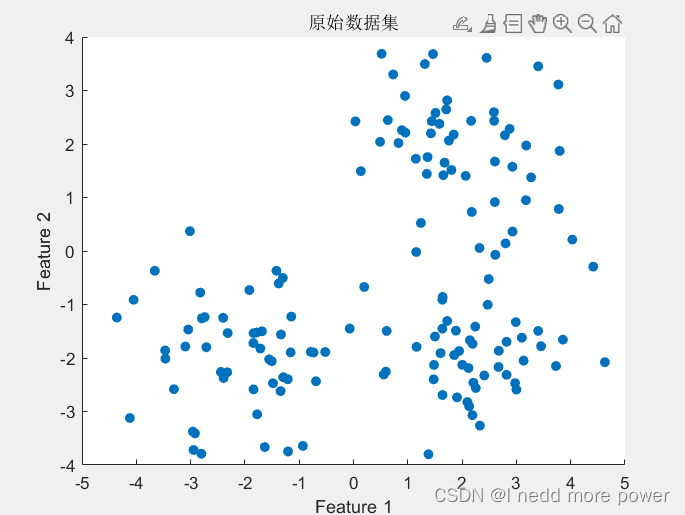
figure;
scatter(data(:, 1), data(:, 2), 'filled');
title('原始数据集');
xlabel('Feature 1');
ylabel('Feature 2');
% 参数设置
num_clusters = 3;
num_bees = 50;
num_iterations = 100;
elite_bees = 5;
selected_bees = 15;
patch_size = 10;
% 运行蜂群优化算法进行聚类
bee_algorithm_clustering(data, num_clusters, num_bees, num_iterations, elite_bees, selected_bees, patch_size);说明
生成数据集:生成一个包含三类数据点的二维数据集
效果