你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益:
- 了解大厂经验
- 拥有和大厂相匹配的技术等
希望看什么,评论或者私信告诉我!
文章目录
- 一、前言
- 二、优化
-
- [2.1 分析 Iceberg lookup 部分源码](#2.1 分析 Iceberg lookup 部分源码)
- [2.2 切换到 paimon 维表](#2.2 切换到 paimon 维表)
- [2.3 paimon 维表原理分析](#2.3 paimon 维表原理分析)
- [2.4 是不是一定要通过 iceberg 替换 paimon 才能降低内存](#2.4 是不是一定要通过 iceberg 替换 paimon 才能降低内存)
- 三、总结
一、前言
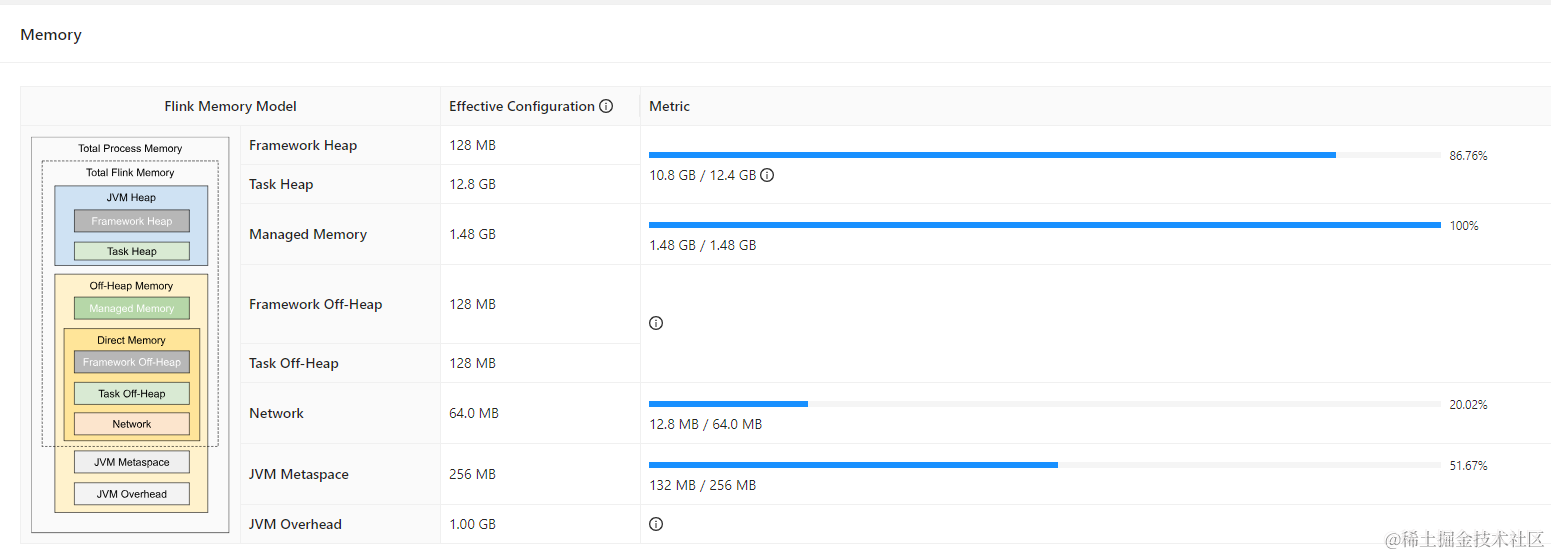
线上实时任务,通过 FlinkSQL 关联 Iceberg 维表,维表大搞有 60w,首先通过 FlinkSQL关联 Iceberg 维表上线了,经过一番调优后:TaskManager Memory 给到了 16G,但通过监控可以轻易的发现 Heap 没下来过 10GB
二、优化
2.1 分析 Iceberg lookup 部分源码
因为 Iceberg 的 lookup 是公司内部自己实现的,就不贴源码了,但核心一点就是,look up 维表 cache 的数据会存在内存中,这就是为什么堆内存没有下来过 10GB
2.2 切换到 paimon 维表
TaskManager Memory 给到了 4G,程序运行的轻轻松松,另外为了增加 rocksdb 性能,也适当的增加了 rocksdb 的内存
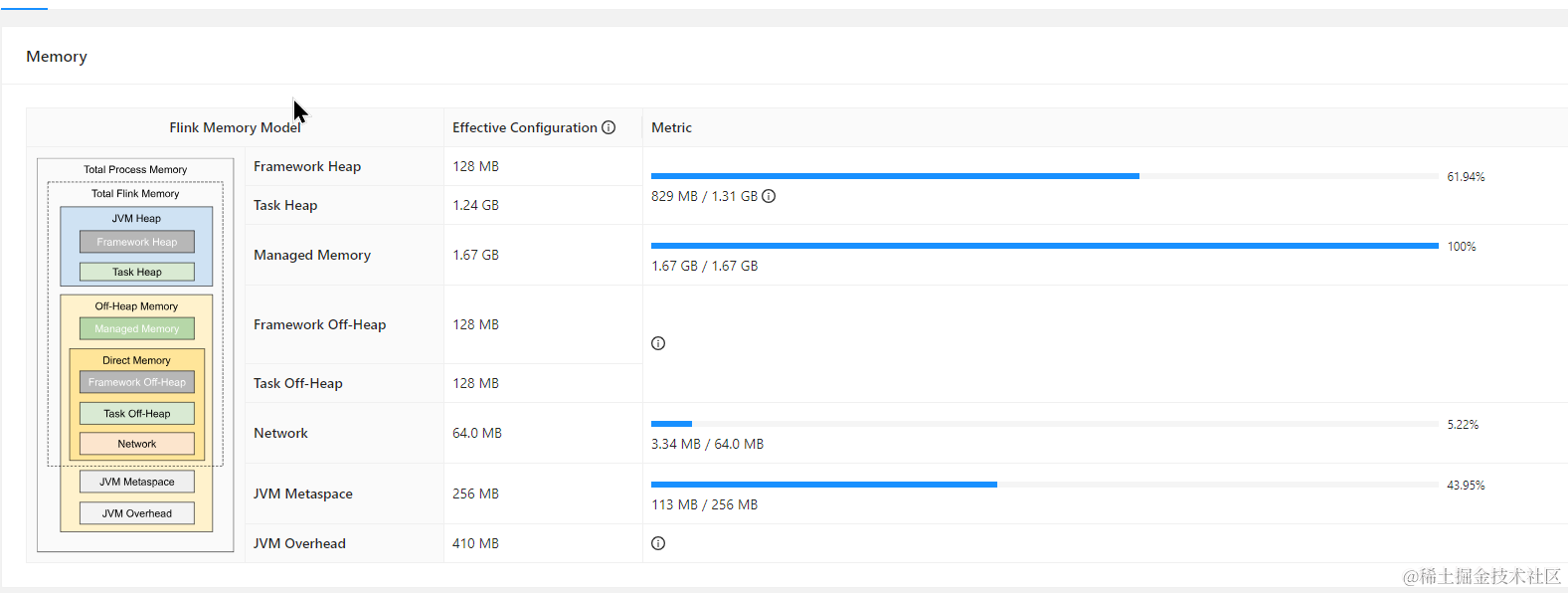
为了替换 paimon 后内存可以下降那么多呢?
2.3 paimon 维表原理分析
首先来看一下 FlinkSQL look up paimon 的维表的源码,这里我们以 flink1.15 为例。
下载完 paimon 源码后,找到 moudle paimon-flink-1.15
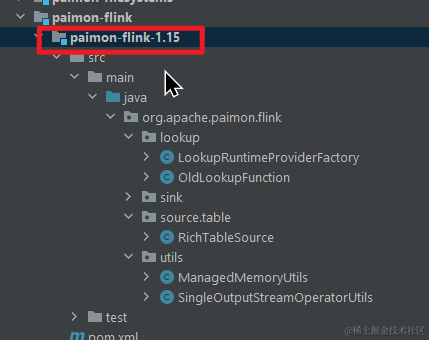
通过 OldLookupFunction 类中的
java
public void eval(Object... values) {
function.lookup(GenericRowData.of(values)).forEach(this::collect);
}可以知道调用的 FileStoreLookupFunction.lookup 方法
java
public Collection<RowData> lookup(RowData keyRow) {
try {
checkRefresh();
InternalRow key = new FlinkRowWrapper(keyRow);
if (partitionLoader != null) {
InternalRow partition = refreshDynamicPartition(true);
if (partition == null) {
return Collections.emptyList();
}
key = JoinedRow.join(key, partition);
}
List<InternalRow> results = lookupTable.get(key);
List<RowData> rows = new ArrayList<>(results.size());
for (InternalRow matchedRow : results) {
rows.add(new FlinkRowData(matchedRow));
}
return rows;
} catch (OutOfRangeException e) {
reopen();
return lookup(keyRow);
} catch (Exception e) {
throw new RuntimeException(e);
}
}通过 checkRefresh 方法,一路跟踪到 FileStoreLookupFunction.refresh 方法
java
private void refresh() throws Exception {
lookupTable.refresh();
}这里呢,我们就以没有主键的 paimon 表为例,继续追踪,追踪到 FullCacheLookupTable.refresh 方法,让,后继续追踪,最后到了 FullCacheLookupTable.refreshRow 方法 ,继续追踪直到 NoPrimaryKeyLookupTable.refreshRow 方法
java
protected void refreshRow(InternalRow row, Predicate predicate) throws IOException {
joinKeyRow.replaceRow(row);
if (row.getRowKind() == RowKind.INSERT || row.getRowKind() == RowKind.UPDATE_AFTER) {
if (predicate == null || predicate.test(row)) {
state.add(joinKeyRow, row);
}
} else {
throw new RuntimeException(
String.format(
"Received %s message. Only INSERT/UPDATE_AFTER values are expected here.",
row.getRowKind()));
}
}在这里我们可以看到 cache 的数据存到的 state 中,继续看 state 是如何实现的
java
RocksDBListState<InternalRow, InternalRow> state也就是说,维表的cache被存到了 rocksdb 中,这一块内存在 Flink 中属于 off-heap,并且通过 manager menory 控制。
rocksdb这一块,如果不太了解的话,可以理解为 mysql,mysql 里面可以存放 TB 级的数据,但它的占用的内存却很少,rocksdb 也是类似的
2.4 是不是一定要通过 iceberg 替换 paimon 才能降低内存
答案是否定了,开头提到了之所以 iceberg 维表占用内存大,主要的原因是因为内部的实现方式:cache 到内存中了。
三、总结
本文通过实际案例,详细介绍了如何通过替换维表实现FlinkSQL任务内存占用的优化。作者通过分析Iceberg lookup部分源码,发现其cache的数据会存在内存中,导致内存占用过大。作者将维表替换为paimon,通过分析paimon维表的原理,发现其cache的数据存储在rocksdb中,从而实现了内存占用的降低。本文对于需要进行FlinkSQL任务内存优化的读者具有一定的参考价值。