文章目录
- 一、引言
-
- [1. 雪崩问题的产生原因](#1. 雪崩问题的产生原因)
- [2. 解决雪崩问题的思路](#2. 解决雪崩问题的思路)
- 二、微服务保护
-
- [1. 服务保护方案](#1. 服务保护方案)
-
- [1.1 请求限流](#1.1 请求限流)
- [1.2 线程隔离](#1.2 线程隔离)
- [1.3 服务熔断](#1.3 服务熔断)
- [2. Sentinel](#2. Sentinel)
-
- [2.1 安装](#2.1 安装)
- [2.2 微服务整合](#2.2 微服务整合)
-
- [2.2.1 请求限流](#2.2.1 请求限流)
- [2.2.2 线程隔离](#2.2.2 线程隔离)
- [2.2.3 服务熔断](#2.2.3 服务熔断)
- [2.2.3 规则持久化](#2.2.3 规则持久化)
-
- ①添加依赖:
- [②修改 bootstrap.yml 配置文件](#②修改 bootstrap.yml 配置文件)
- ③在nacos中添加共享配置
- [3 . 总结](#3 . 总结)
一、引言
微服务架构虽然解决了单体应用的诸多问题,但也带来了新的挑战,其中之一就是雪崩问题(Cascade Failure)。当一个或多个服务出现故障,会引发连锁反应,使得其他依赖这些服务的服务也出现问题,从局部故障变为整体故障,最后就像生活中的雪崩那样,整个系统崩溃。
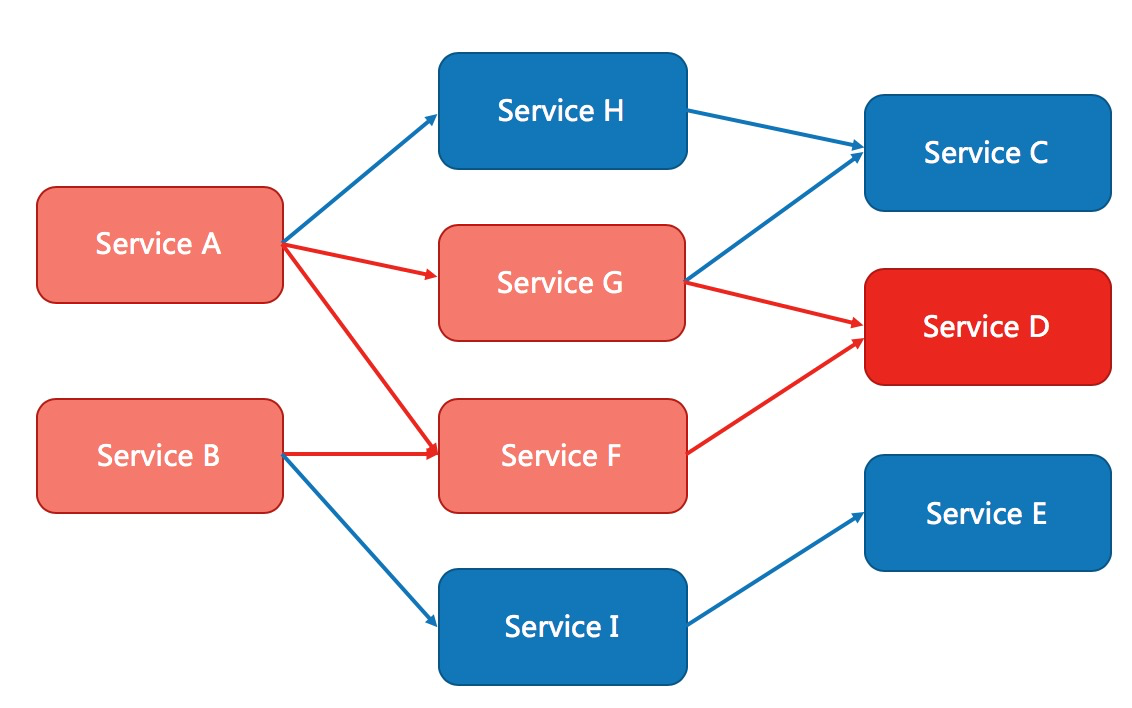
1. 雪崩问题的产生原因
- 服务依赖链条过长:在微服务架构中,服务A可能依赖于服务B,而服务B又依赖于服务C,当服务C出现问题时,整个链条可能都会受到影响。
- 服务过载:某个服务的突然高负载或流量激增,可能导致下游服务的资源耗尽,从而导致更多的服务失败。
- 资源耗尽:某个服务由于内存泄漏或其他原因,导致资源耗尽(如内存、CPU、数据库连接等),从而影响整个系统的状态。
- 网络问题:网络延迟或断连可能导致服务间通信失败,从而引发雪崩效应。
- Bug引起的失败:某个服务中存在未处理的异常,在运行时被触发,导致服务崩溃,依赖该服务的其他服务也因此出现问题。
2. 解决雪崩问题的思路
-
熔断机制(Circuit Breaker)
通过监控服务的调用状况,当检测到调用失败率过高时,自动断开与问题服务的调用连接,防止故障扩散。
应用场景:服务依赖链条过长、网络问题、Bug引起的失败
-
限流(Rate Limiting)
通过限制单个服务的最大请求数来防止因为流量过大而导致的资源耗尽,从而保护服务的可用性。
应用场景:服务过载
-
服务降级(Fallback)
设置备用方案或降级处理,在服务不可用时返回预设的降级响应。
应用场景:服务依赖链条过长、服务过载
-
隔离(Bulkhead Pattern)
通过将服务实例的资源进行隔离,防止单个服务实例的故障影响到其他服务实例。
应用场景:资源耗尽
-
健康检查和监控(Health Check and Monitoring)
实时监控服务的运行状态,通过健康检查及时发现和解决潜在问题。
应用场景:资源耗尽、网络问题、Bug引起的失败
二、微服务保护
1. 服务保护方案
1.1 请求限流
请求限流 是一种常用的保护服务的手段,当系统接收到的请求量超过预设的阈值时,限流器会拒绝或者延迟一些请求,以防止系统过载导致崩溃,是一种预防措施。
请求限流往往会有一个限流器,数量高低起伏的并发请求曲线,经过限流器就变的非常平稳。这就像是水电站的大坝,起到蓄水的作用,可以通过开关控制水流出的大小,让下游水流始终维持在一个平稳的量。
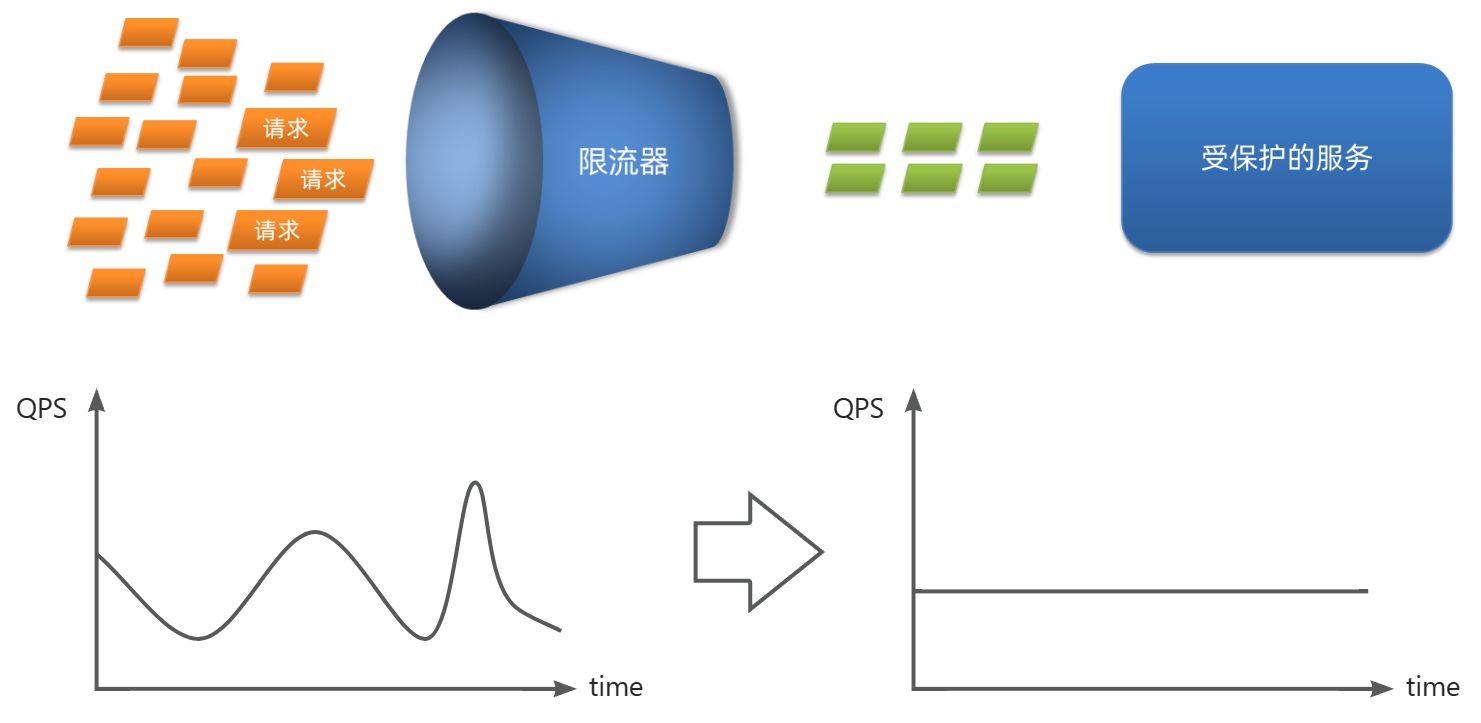
比如我们有一个订单服务,恰逢双十一购物节,订单服务在促销活动期间会受到大量用户的访问,导致系统负载急剧增加,甚至出现服务崩溃的情况。
而如果我们使用限流器限制每秒钟最多只能处理1000个请求,如果请求量超过这个阈值,多余的请求将被拒绝或者延后处理,这样我们可以有效防止因短时间内大量请求涌入而导致的系统过载和崩溃。
1.2 线程隔离
线程隔离 是一种将不同的任务隔离运行在不同的线程池中的方法,防止某一任务的故障蔓延,影响其他任务的正常执行,是一种补救措施。
当一个业务接口响应时间长,而且并发高时,就可能耗尽服务器的线程资源,导致服务内的其它接口受到影响。所以我们必须把这种影响降低,或者缩减影响的范围。线程隔离正是解决这个问题的好办法。
线程隔离的思想来自轮船的舱壁模式:
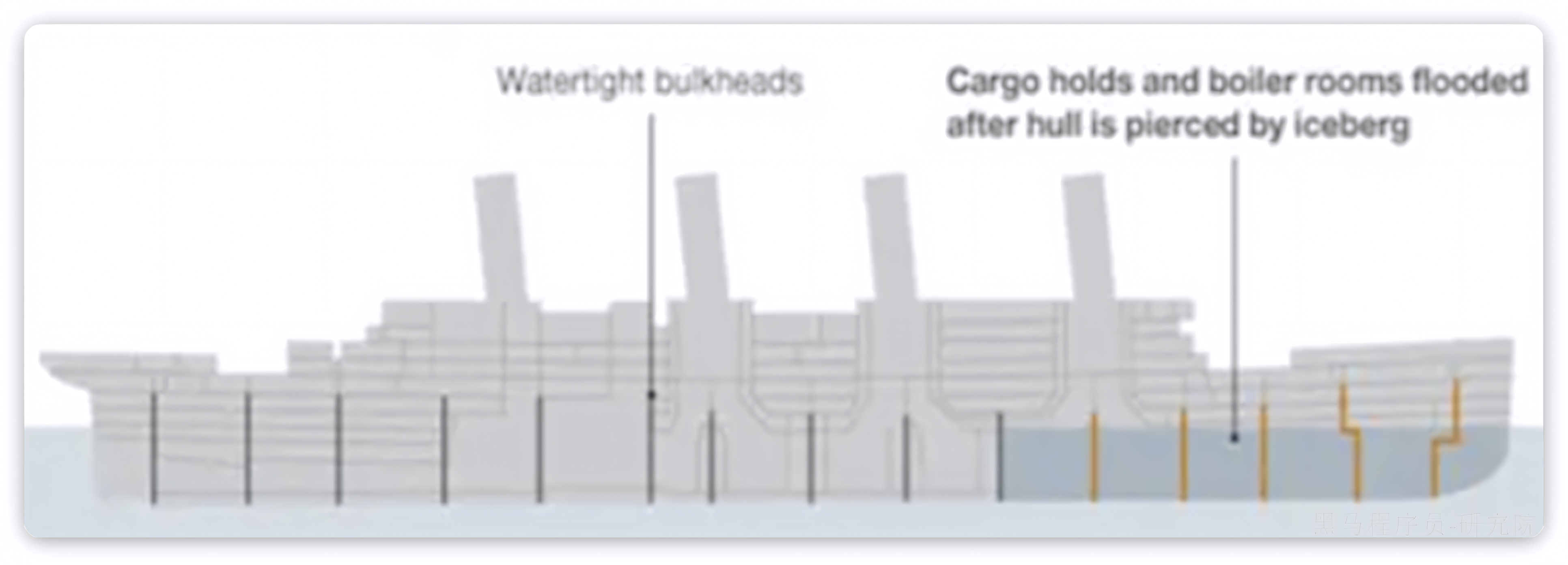
就像一艘轮船被划分为若干个独立的空间(分隔开的水密隔舱),当船体破损时,只会导致损坏的部分隔舱进水,而其他隔舱由于隔离,并不会进水,以确保即使一个隔舱进水,其他隔舱不会进水,从而防止整艘船的沉没。泰坦尼克号沉没的主要原因之一,就是它的舱壁有一个设计上的失败,水可以通过舱壁顶部上的甲板注入,淹没整个船体。
同样,在微服务架构中,我们通过隔离不同的服务及其资源,防止一个服务出现问题时影响到其他服务。
于此类似,为了避免某个接口故障或压力过大导致整个服务不可用,我们可以限定每个业务能使用的线程数,避免耗尽整个Tomcat的资源,因此也叫线程隔离。
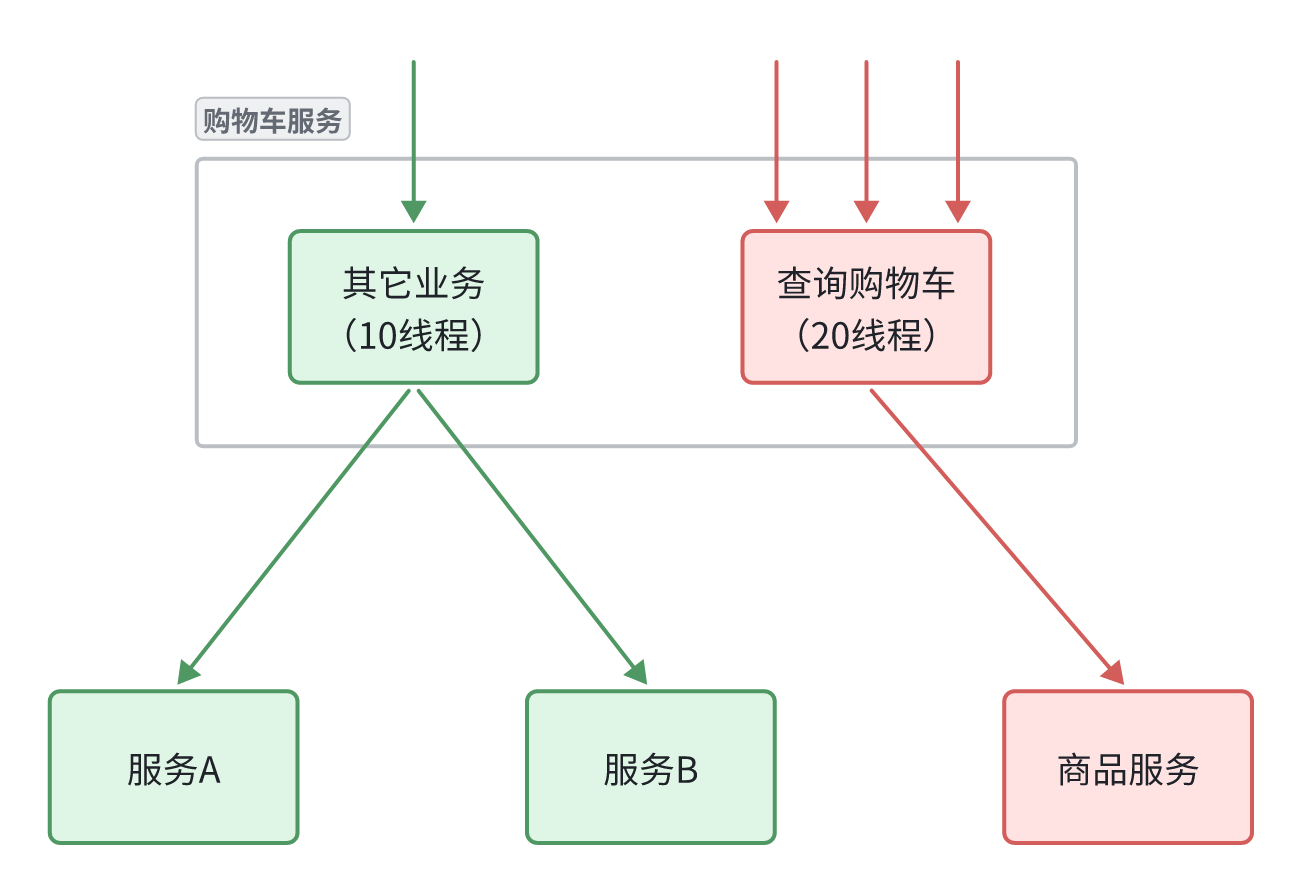
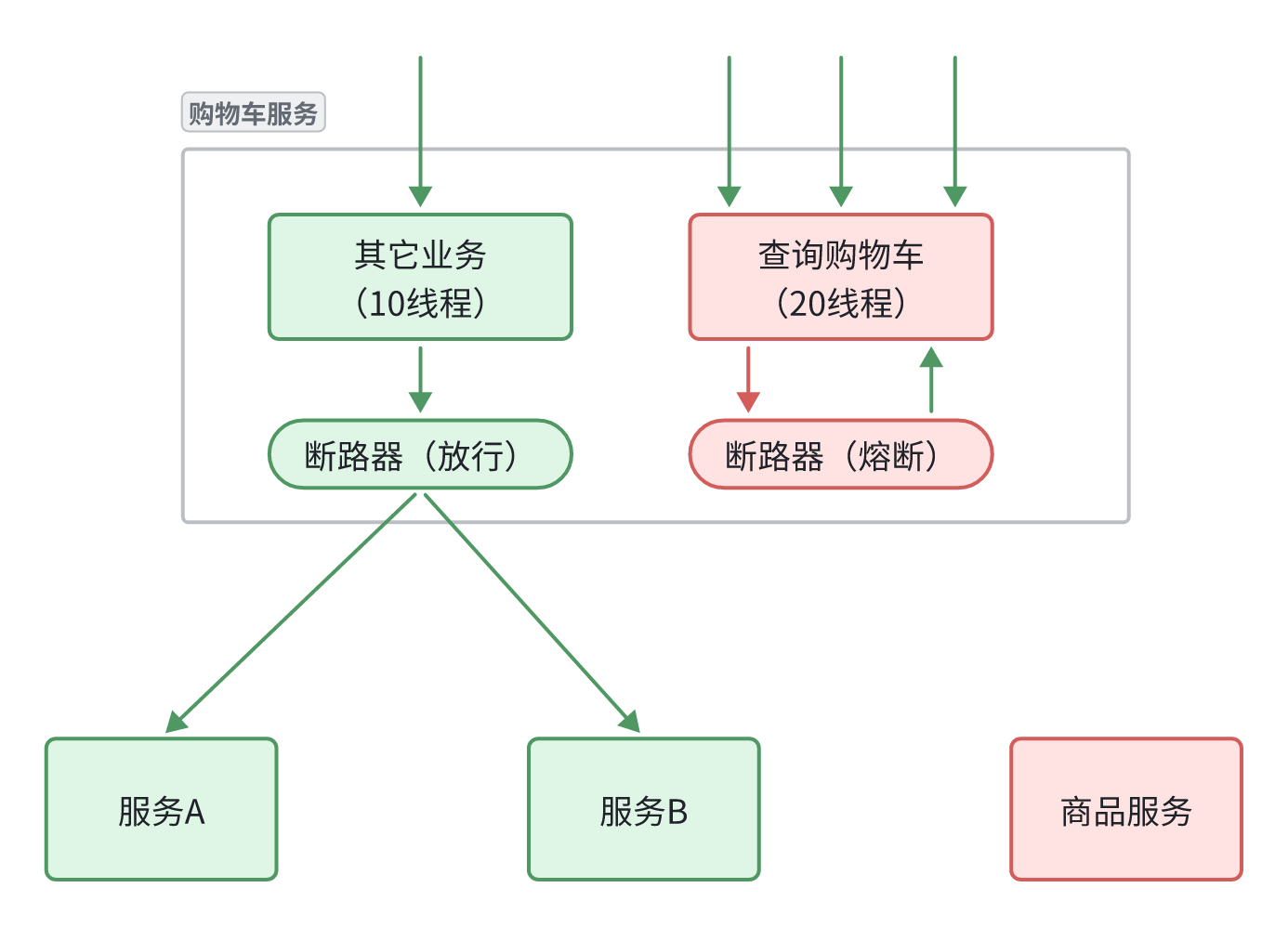
如图所示,我们给查询购物车业务限定可用线程数量上限为20,这样即便查询购物车的请求因为查询商品服务而出现故障,也不会导致服务器的线程资源被耗尽,不会影响到其它接口。
1.3 服务熔断
服务熔断 是一种保护机制,当某个服务的故障率超过预设阈值时,自动断开对该服务的调用,避免故障影响到更多的服务,是一种补救措施。
假如一个商品服务(故障服务)在一段时间内连续超过一定数量的失败请求,我们可以触发熔断,避免购物车服务(服务调用方)频繁调用故障的商品服务导致购物车服务也故障。
所以,我们要做两件事情:
- 编写服务降级逻辑:就是服务调用失败后的处理逻辑,根据业务场景,可以抛出异常,也可以返回友好提示或默认数据。
- 异常统计和熔断:统计服务提供方的异常比例,当比例过高表明该接口会影响到其它服务,应该拒绝调用该接口,而是直接走降级逻辑。
2. Sentinel
针对服务过载、线程隔离以及熔断降级,我们可以使用 Alibaba Sentinel 来提供全面的解决方案。Sentinel 是 Alibaba 开源的一个流量防卫组件,专注于服务端的流量控制、熔断降级以及系统保护
home | Sentinel (sentinelguard.io)
Sentinel和Hystrix对比:
| Sentinel | Hystrix | |
|---|---|---|
| 隔离策略 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于响应时间或失败比率 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持慢启动、匀速器模式 | 不支持 |
| 系统负载保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
Sentinel 的使用可以分为两个部分:
- 核心库(Jar包):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。在项目中引入依赖即可实现服务限流、隔离、熔断等功能。
- 控制台 (Dashboard):亦称 Sentinel 服务器。基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器,Dashboard 主要负责管理推送规则、监控、管理机器信息等。
为了方便监控微服务,我们先把Sentinel的控制台搭建出来。
2.1 安装
- 下载jar包
下载地址:Release v1.8.7 · alibaba/Sentinel (github.com)
如果觉得下载慢可以从镜像下载地址下载:https://mirror.ghproxy.com/https://github.com/alibaba/Sentinel/releases/download/1.8.7/sentinel-dashboard-1.8.7.jar
- 运行
将jar包放在任意非中文、不包含特殊字符的目录下,重命名为
sentinel-dashboard.jar:
然后在命令行运行如下命令(端口如果冲突可以换其他端口):
shell
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar其它启动时可配置参数可参考官方文档:
启动配置项 · alibaba/Sentinel Wiki (github.com)
- 访问
访问http://localhost:8090页面,就可以看到sentinel的控制台了:

输入账号和密码,默认都是:sentinel
登录后,即可看到控制台,默认会监控sentinel-dashboard服务本身:
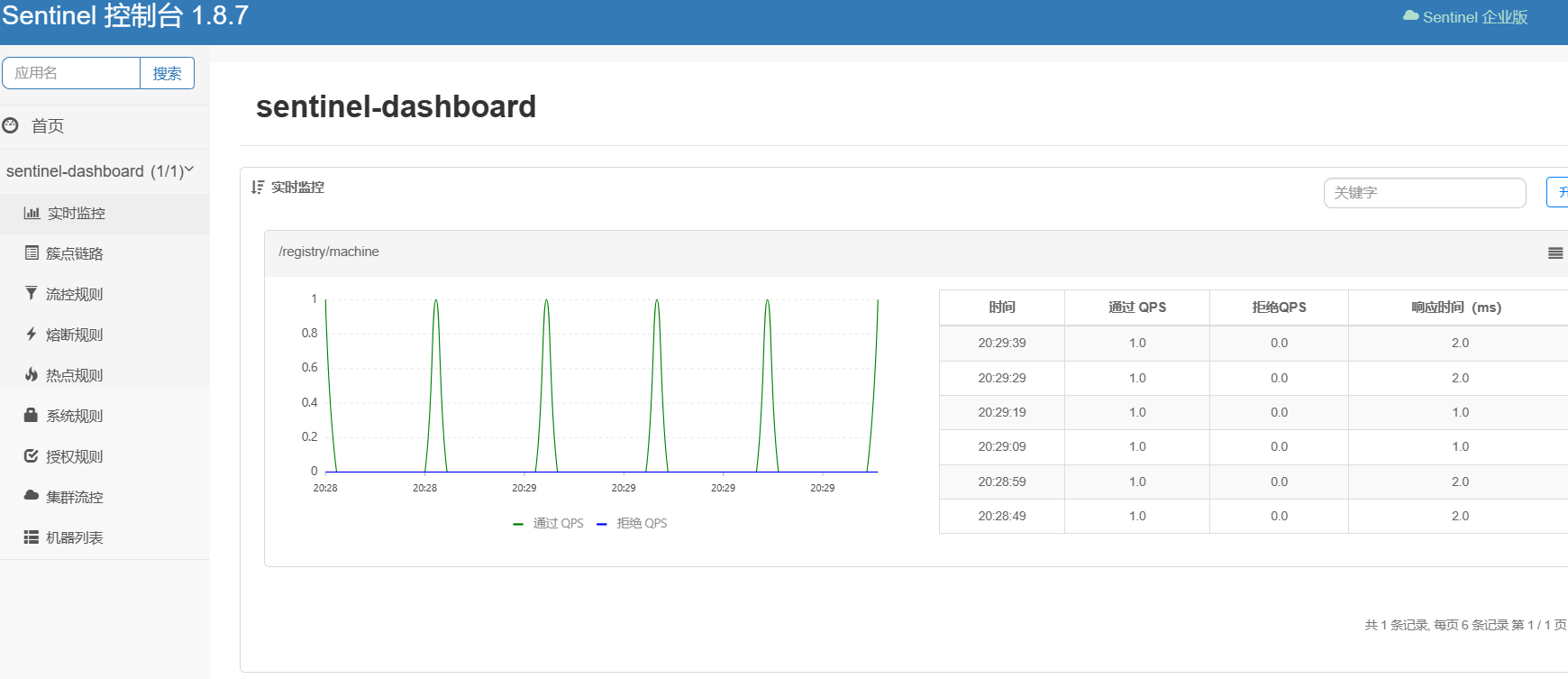
控制台页面分析:
- 实时监控: 展示当前应用的实时流量情况,包括 QPS、线程数等信息。
- 簇点链路: 展示服务的调用链路,帮助用户快速定位问题。
- 流控规则: 用于配置流量控制规则,例如限制每秒请求数、并发线程数等。
- 熔断规则: 用于配置熔断降级规则,当服务出现异常时,可以快速熔断,避免级联故障。
- 热点规则: 用于配置热点参数限流,例如限制某个用户每秒的请求数。
- 系统规则: 用于配置系统级别的保护规则,例如限制 CPU 使用率、Load 等。
- 授权规则: 用于配置访问权限控制,例如限制某些 IP 访问。
- 集群流控: 用于配置集群级别的流量控制。
- 机器列表: 展示当前应用接入的所有机器。
2.2 微服务整合
-
添加
Sentinel依赖xml<!--sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency>- 添加配置文件
yamlspring: cloud: sentinel: transport: dashboard: localhost:8090 # Sentinel控制台地址,用于与控制台链接,便于控制台推送规则,监控和管理应用程序的流量控制和熔断策略。-
访问添加
Sentinel的服务端口,之后查看Sentinel控制台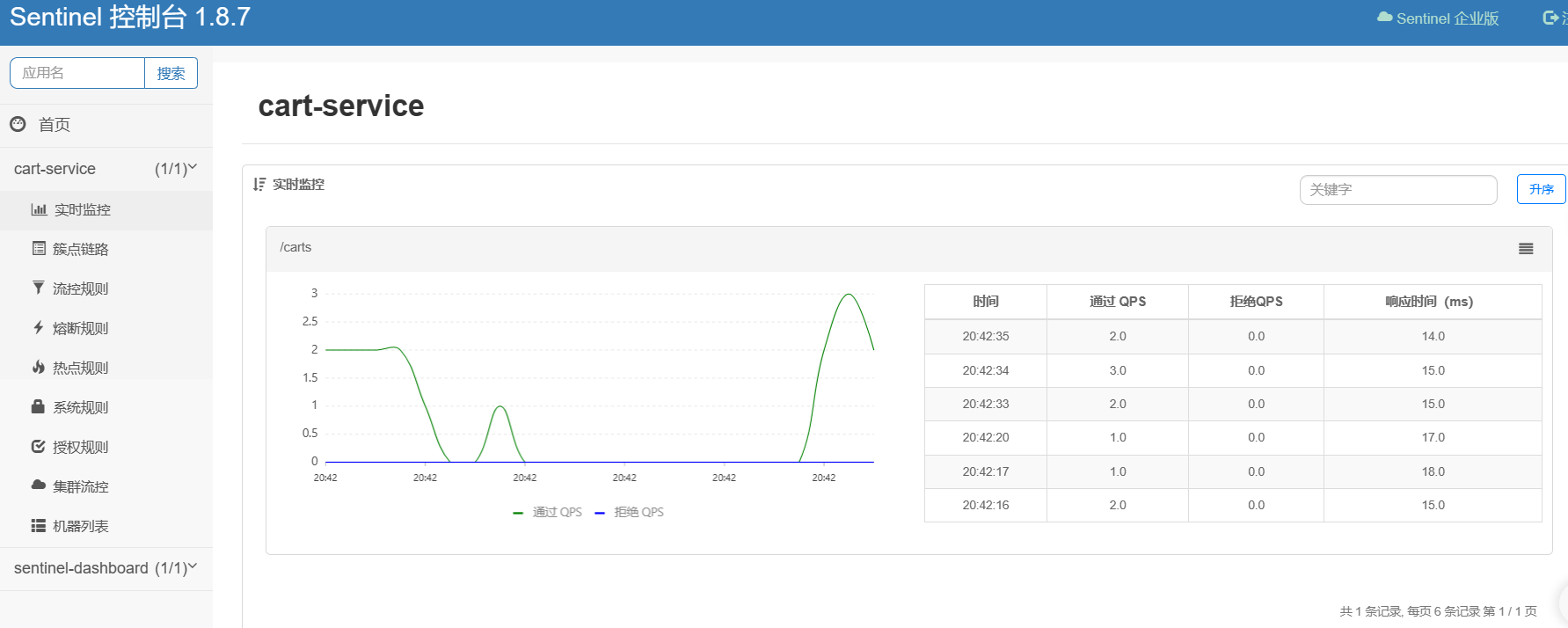
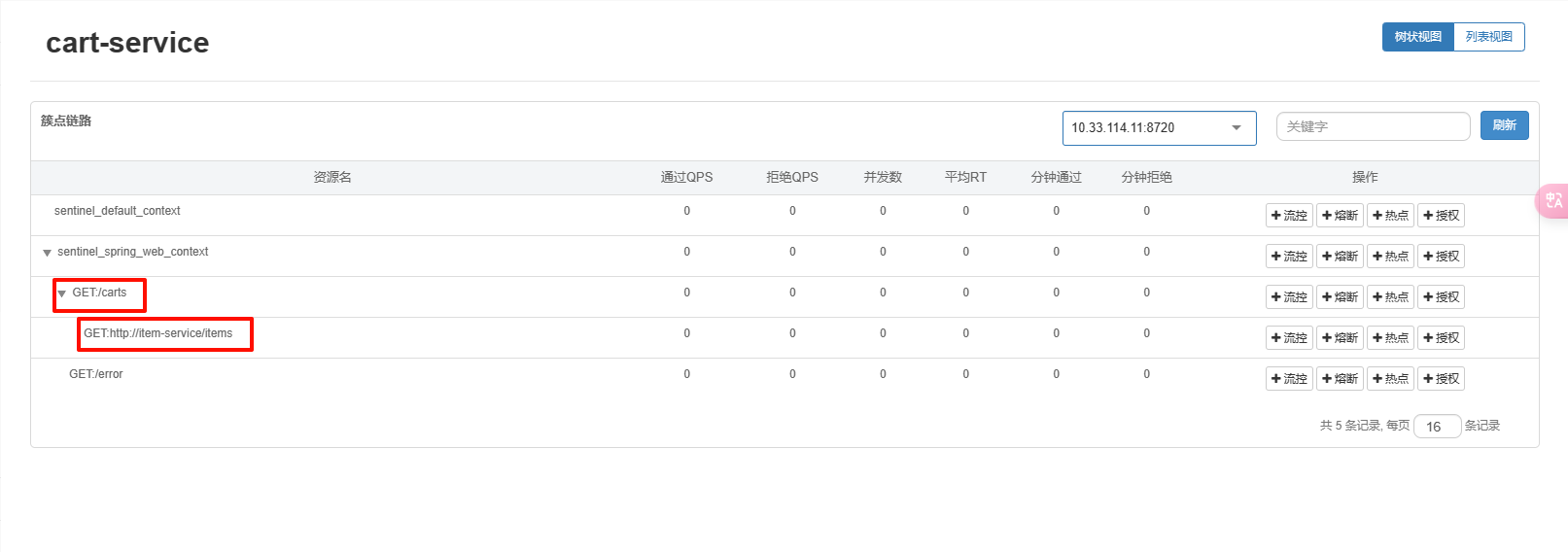
簇点链路
簇点链路,就是单机调用链路。是一次请求进入服务后经过的每一个被Sentinel监控的资源链。默认Sentinel会监控SpringMVC的每一个Endpoint(http接口)。限流、熔断等都是针对簇点链路中的资源设置的。而资源名默认就是接口的请求路径。
如果你的项目的API接口风格采用的是Restful风格,由于请求路径一般都相同,这会导致点资源名称重复,因此需要修改配置。
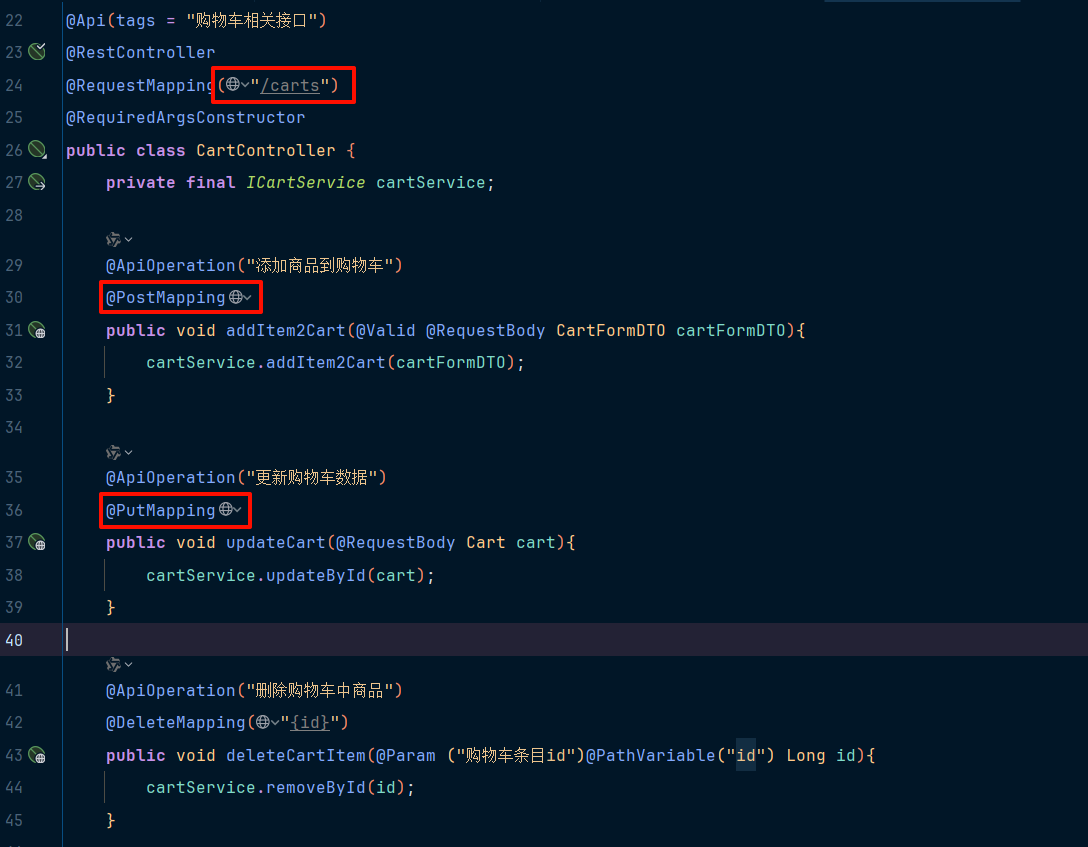
修改配置,把请求方式+请求路径作为簇点资源名称:
yaml
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
http-method-specify: true # 开启请求方式前缀再次访问该服务的各个接口,之后查看Sentinel控制台:
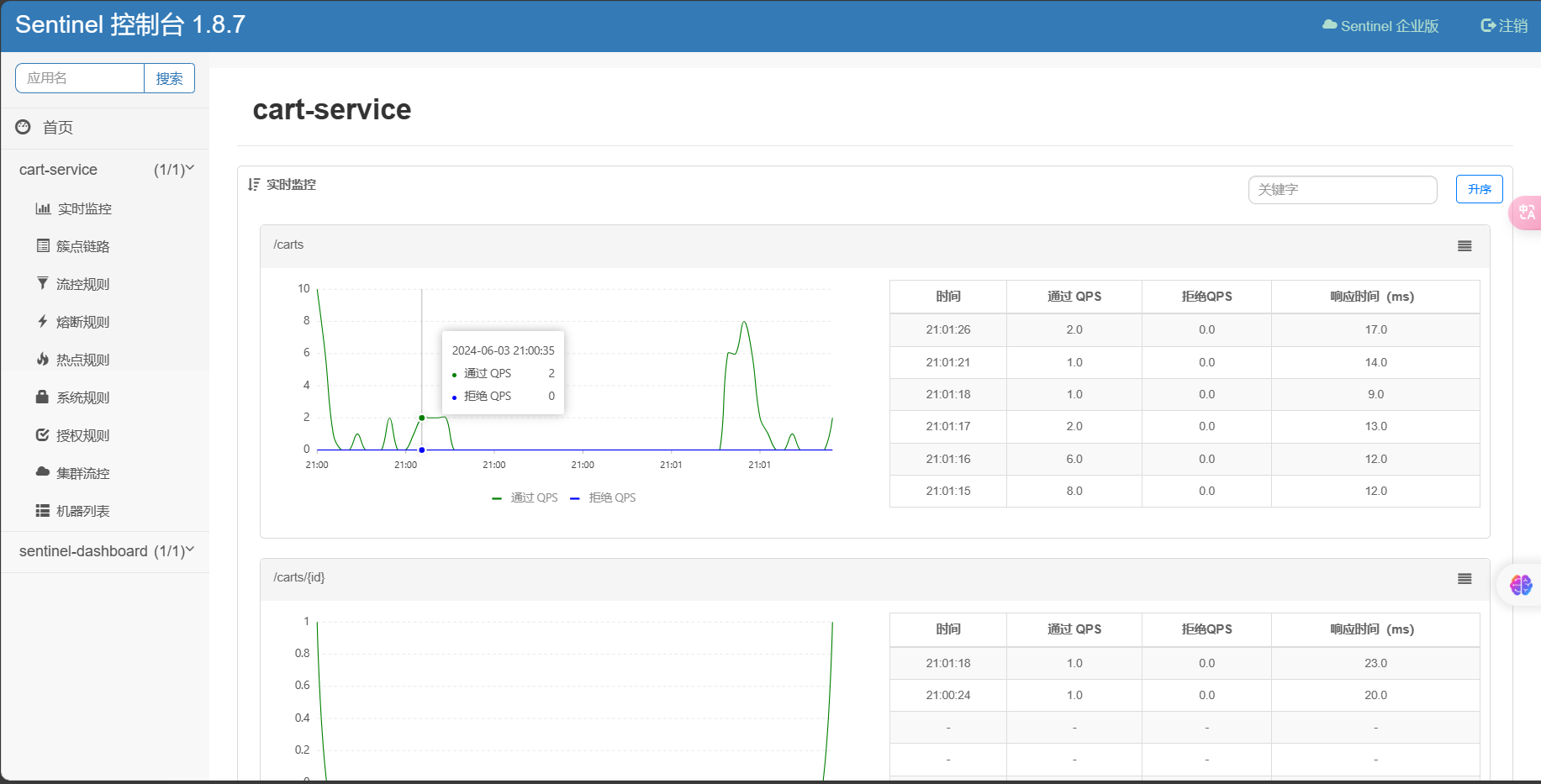
2.2.1 请求限流
在簇点链路后面点击流控按钮,即可对其做限流配置:
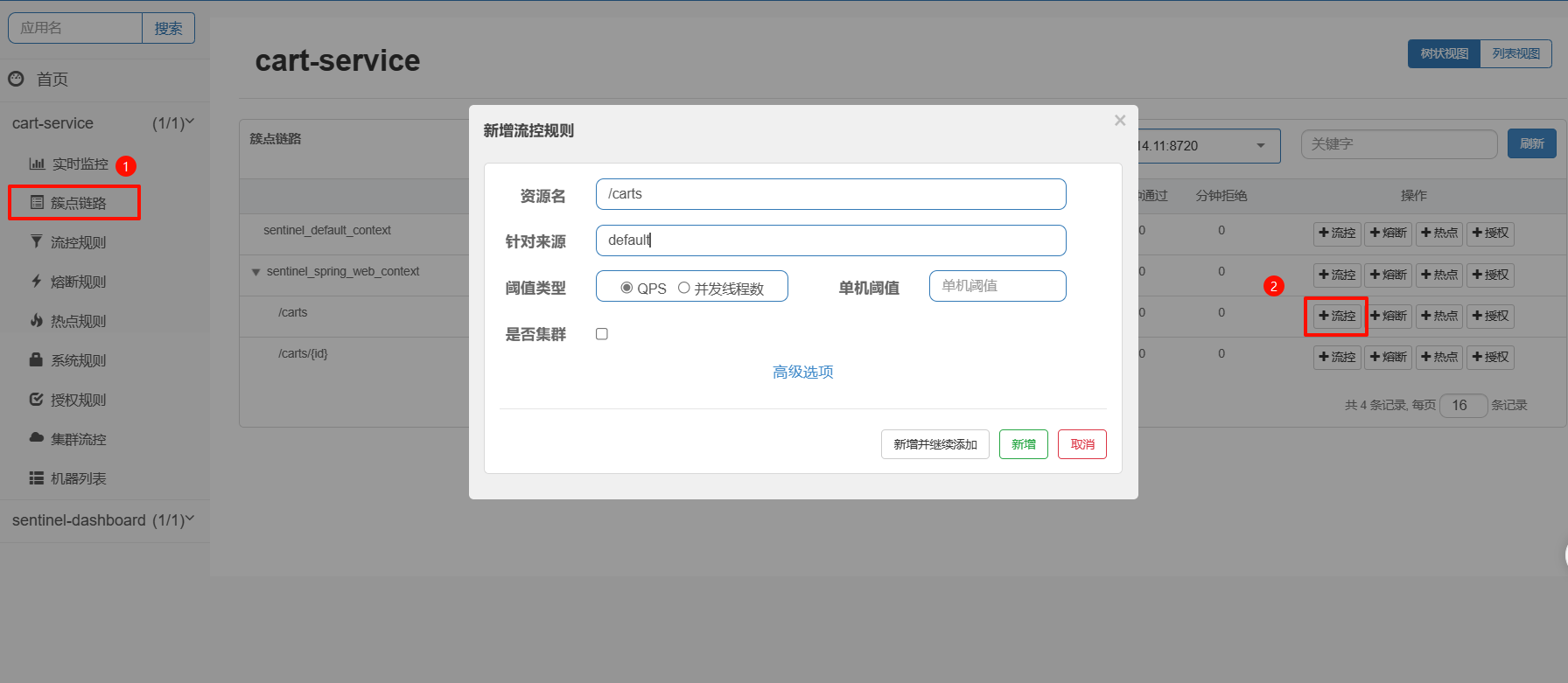
分析:
-
资源名
- 这是限流规则所作用的具体资源。图中,资源名为
/carts,表示该限流规则是针对/carts这个资源设置的。资源名一般是服务的 URL 地址或业务方法名。
- 这是限流规则所作用的具体资源。图中,资源名为
-
针对来源
- 表示该限流规则针对的是哪个调用来源。
default,表示不限具体的调用来源,也即对所有调用该资源的请求都适用此规则。
- 表示该限流规则针对的是哪个调用来源。
-
阈值类型
- 这里可以选择限流的类型,通常有 QPS(每秒查询次数)或并发线程数。默认的是类型是
QPS,表示采用每秒最大请求数来进行限流控制。
- 这里可以选择限流的类型,通常有 QPS(每秒查询次数)或并发线程数。默认的是类型是
-
单机阈值
- 设置每秒最多允许的请求数(或并发线程数)。如果实际请求数超过该阈值,多余的请求将被拒绝或延迟处理。例如填入1000表示每秒最多允许1000次请求。
-
是否集群
- 表示是否启用集群流控。如果启用,Threshold 将按集群模式进行分布式统计和计算。
-
高级选项
- 可以展开设置一些高级参数,比如流控模式、冷启动时间等。
而如果想要对接口限流进行测试,可以使用jmeter这个软件,里面有详细的教程(可以只下载文档):
链接:https://pan.baidu.com/s/1Y_qxYVVEns6qBsvltyyOXg?pwd=tutu
提取码:tutu
或者直接去官方网站下载安装包(度盘限的真狠):
Apache JMeter - 下载 Apache JMeter --- Apache JMeter - Download Apache JMeter
或者去国内镜像下载:
这里我们使用QPS限流策略,每秒最多请求数设为6,使用jmeter测试后查看控制台:
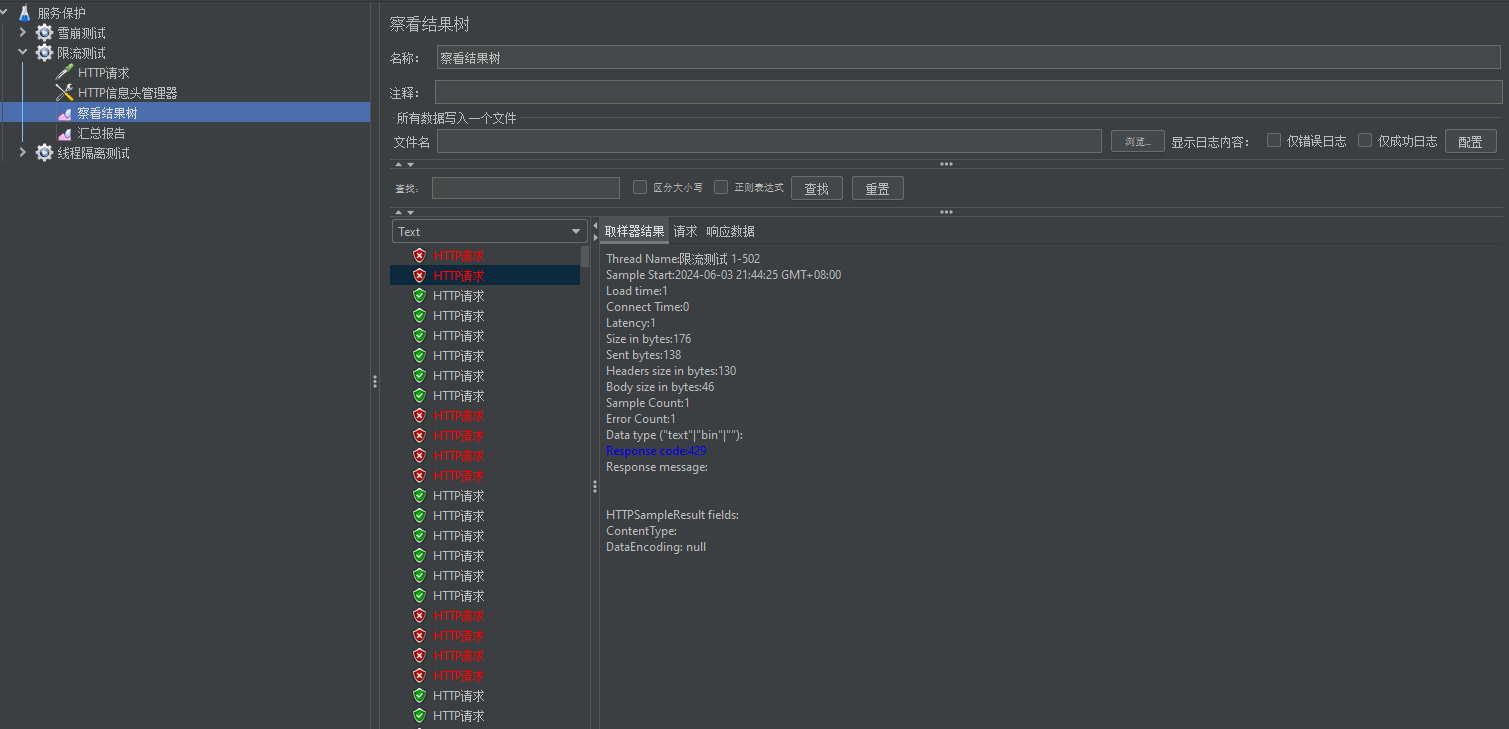
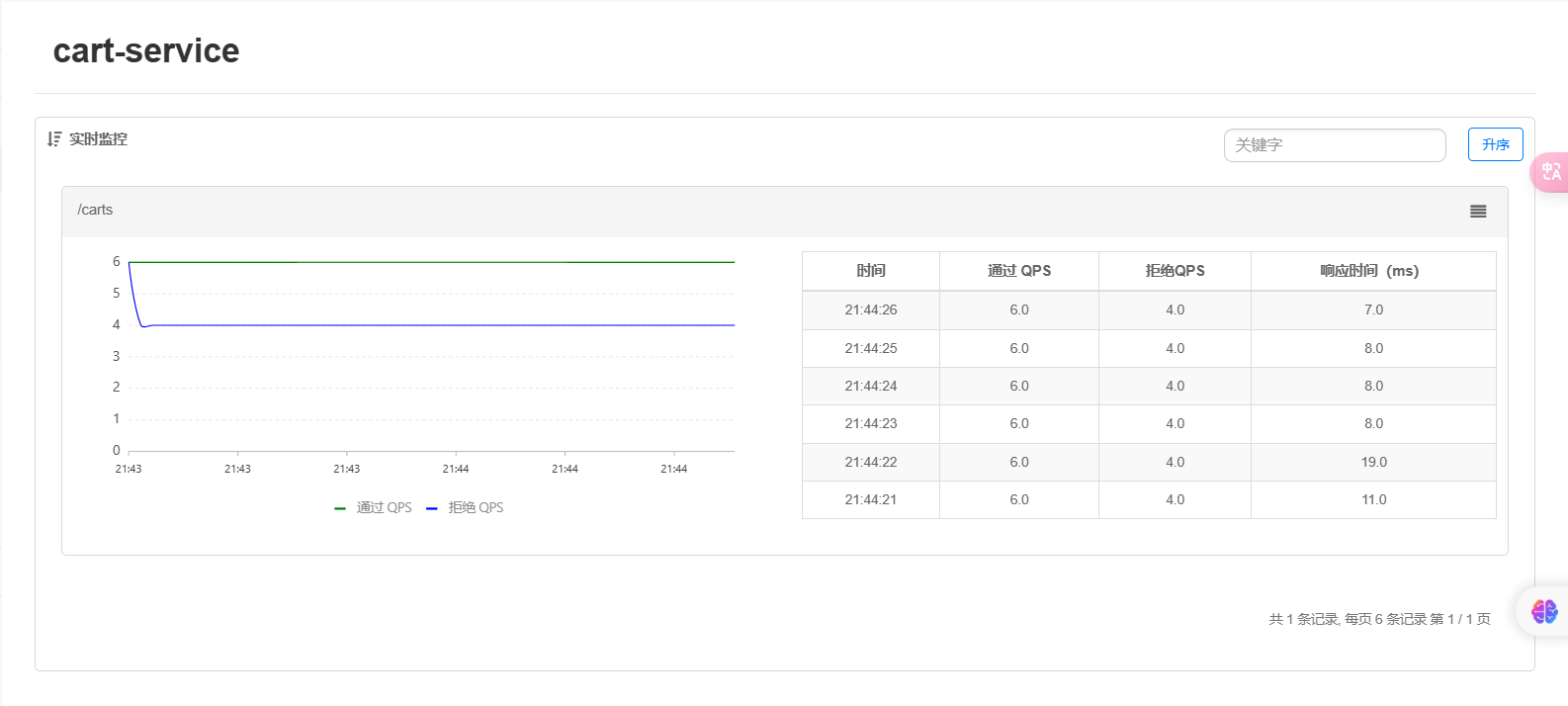 可以看到10个请求其中有4个被拒绝,符合我们的QPS限流策略。
可以看到10个请求其中有4个被拒绝,符合我们的QPS限流策略。
2.2.2 线程隔离
限流可以降低服务器压力,尽量减少因并发流量引起的服务故障的概率,但并不能完全避免服务故障。一旦某个服务出现故障,我们必须隔离对这个服务的调用,避免发生雪崩。
①OpenFeign整合Sentinel
由于微服务的各个服务之间经常使用OpenFeign进行请求,要FeignClient接口做线程隔离,需要将OpenFeign整合Sentinel
修改服务调用方的application.yml文件,开启Feign的sentinel功能:
yaml
feign:
sentinel:
enabled: true # 开启feign对sentinel的支持重启服务会发现要服务调用方要调用的接口FeignClient自动变成了一个簇点资源:
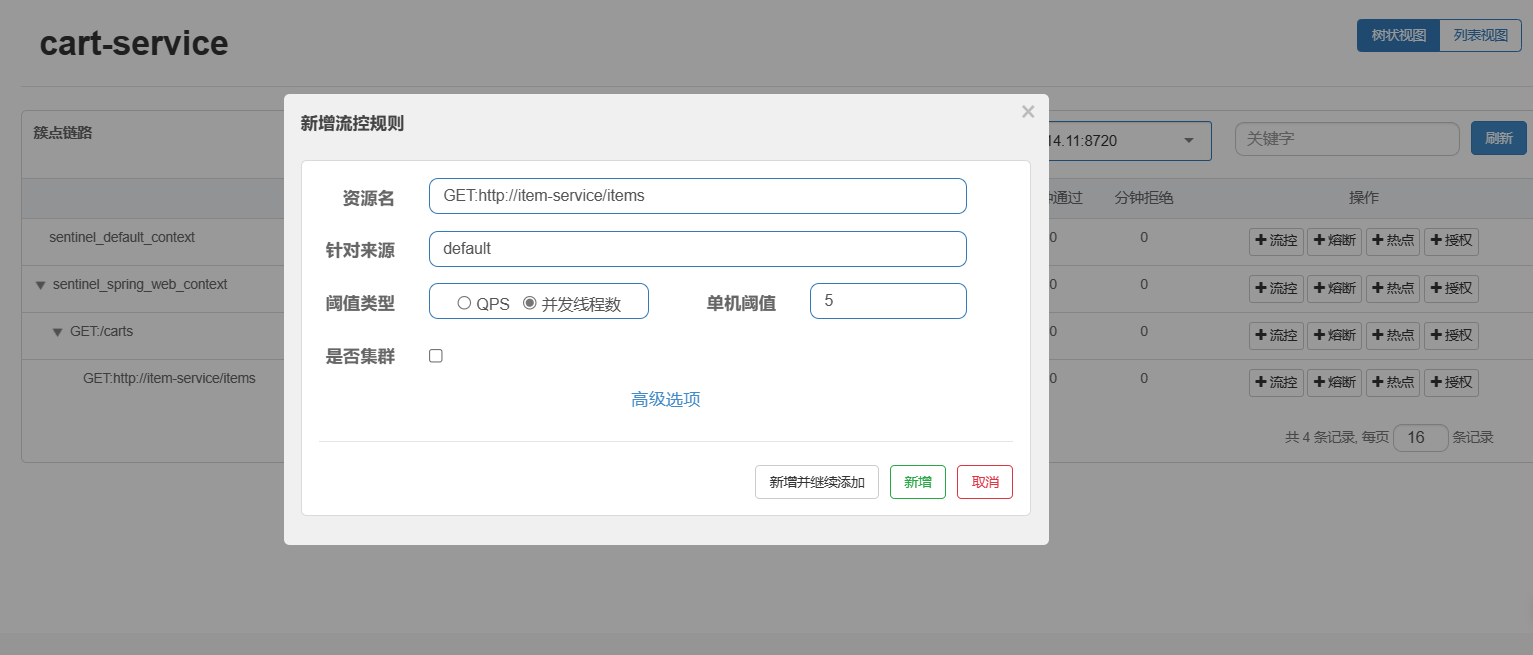
②配置线程隔离
勾选"并发线程数限制",也就是说这个接口最多使用5个线程。如果该接口每秒处理2个请求,则5个线程的实际QPS在10左右,而超出的请求自然会被拒绝。
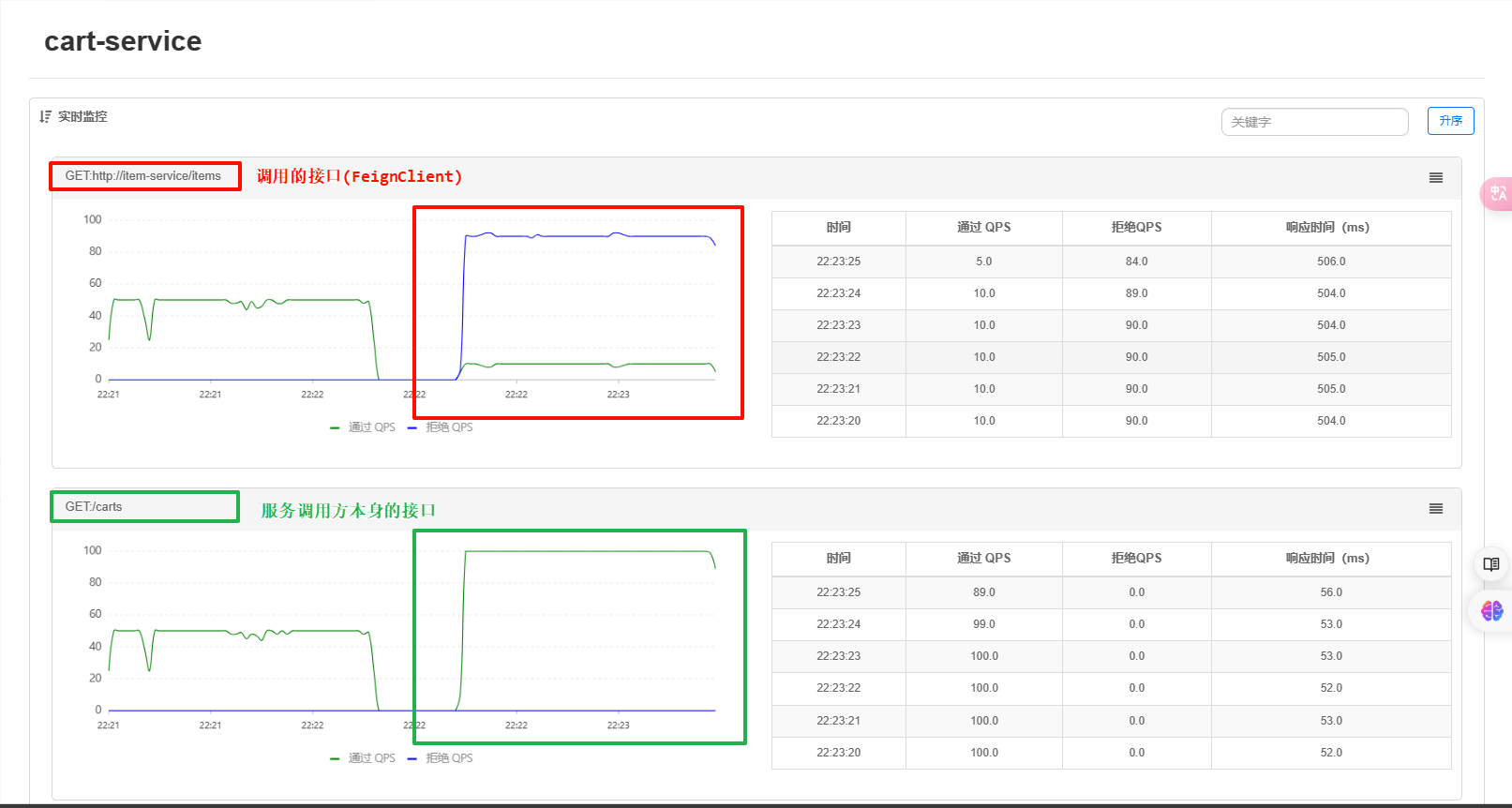
再次使用jemeter进行测试:
很容易就能发现端口的QPS完全不同,服务调用方本身的接口的QPS为100,而被调用的接口的QPS为10(接口每秒处理2个请求,则5个线程的实际QPS在10左右)。
2.2.3 服务熔断
熔断是解决雪崩问题的重要手段。思路是由断路器 统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
在前面,我们使用线程隔离对服务调用方进行隔离,保护了微服务的其它接口。但由于线程隔离导致被调用服务QPS较低,导致接口吞吐能力有限,这也导致了下面几个问题:
第一,超出的QPS上限的请求就只能抛出异常,从而导致上游服务中想要请求该接口获取资源的接口请求失败。但从业务角度来说,即便上游服务没有请求成功,上游服务也应该展示给用户,用户体验更好。也就是给请求失败设置一个降级处理逻辑。
第二,由于下游接口的延迟较高(模拟的500ms),从而导致上游服务接口的响应时间也变的很长。这样不仅拖慢了上游服务,消耗了上游服务的更多资源,而且用户体验也很差。对于下游服务中这种不太健康的接口,我们应该直接停止调用,直接走降级逻辑,避免影响到当前服务。也就是将下游服务的该接口熔断。
①编写降级逻辑
触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,用户体验会更好。
给FeignClient编写失败后的降级逻辑有两种方式:
- 方式一:FallbackClass,无法对远程调用的异常做处理
- 方式二:FallbackFactory,可以对远程调用的异常做处理,我们一般选择这种方式。
这里我们演示方式二的失败降级处理。
步骤一:
这里默认已经在上游服务配置文件中将OpenFeign整合了Sentinel:
yamlfeign: sentinel: enabled: true # 开启feign对sentinel的支持
在相应的FeignClient所在模块定义降级处理类,实现FallbackFactory:
java
import feign.hystrix.FallbackFactory;
import org.springframework.stereotype.Component;
@Component
public class ItemServiceFallbackFactory implements FallbackFactory<ItemServiceClient> {
@Override
public ItemServiceClient create(Throwable throwable) {
return new ItemServiceClient() {
@Override
public Item getItemById(Long id) {
// 降级之后返回的默认数据
Item defaultItem = new Item();
defaultItem.setId(id);
defaultItem.setName("默认Item");
defaultItem.setDescription("由于系统负载,这是一个默认的Item描述。");
return defaultItem;
}
};
}
}分析:
ItemServiceFallbackFactory实现了FallbackFactory接口,而FallbackFactory接口允许我们创建一个 Fallback 实例,此实例可以用于处理远程调用失败后的逻辑。create(Throwable throwable)方法是FallbackFactory接口中的唯一方法,用于生成一个ItemServiceClient的降级处理实现。在调用失败时,该方法会接收到一个Throwable对象,表示调用失败的原因。- 在
create方法中,返回了一个匿名内部类实现ItemServiceClient接口的降级处理逻辑。当 Feign 客户端的远程调用失败时,将调用这个降级处理器的方法。 - 这里是
getItemById方法的降级实现,当请求远程getItemById方法失败时,返回一个默认的Item对象。
通过这种方式,即使远程服务不可用,上游服务仍然可以返回友好的默认数据,避免直接暴露问题,并提升用户体验。
步骤二:
注册配置,在 FeignClient 接口中添加注解,指明降级处理类:
java
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient(name = "item-service", fallbackFactory = ItemServiceFallbackFactory.class)
public interface ItemServiceClient {
@GetMapping("/items/{id}")
Item getItemById(@PathVariable("id") Long id);
}这样上游服务就不会受到下游服务的影响,延迟会变得很低,这就是给请求失败设置的降级处理逻辑。
②配置熔断规则
在前面我们知道:对于下游服务中这种不太健康的接口,我们应该直接停止调用,直接走降级逻辑,避免影响到当前服务。也就是将下游服务的该接口熔断 。当下游服务恢复正常时再允许调用。这其实就是断路器的工作模式。
Sentinel中的断路器不仅可以统计某个接口的慢请求比例 ,还可以统计异常请求比例 。当这些比例超出阈值时,就会熔断该接口,即拦截访问该接口的一切请求,降级处理;当该接口恢复正常时,再放行对于该接口的请求。
断路器的工作状态切换有一个状态机来控制:
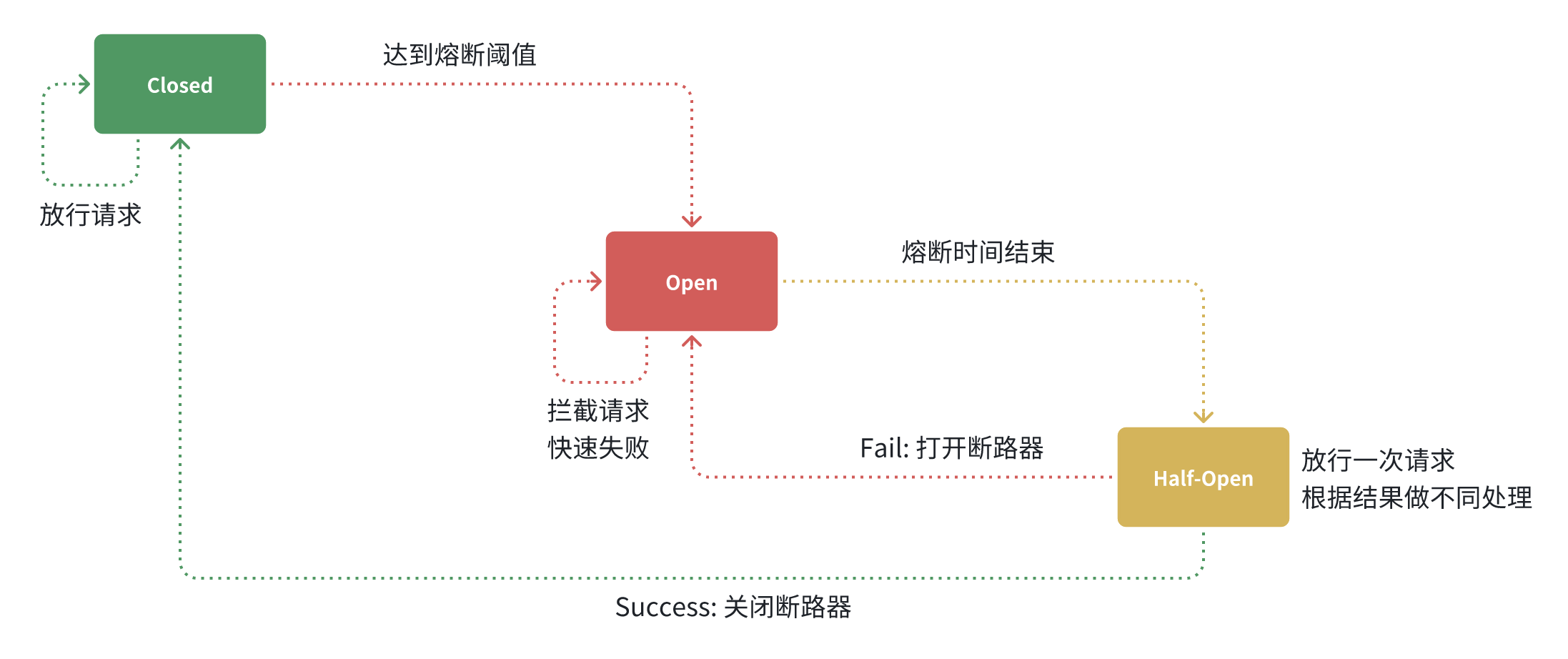
状态机包括三个状态:
- closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
- open :打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态持续一段时间后会进入half-open状态
- half-open :半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 请求成功:则切换到closed状态
- 请求失败:则切换到open状态
接下来配置熔断规则,在上游服务下拉栏中选择下游接口进行配置:
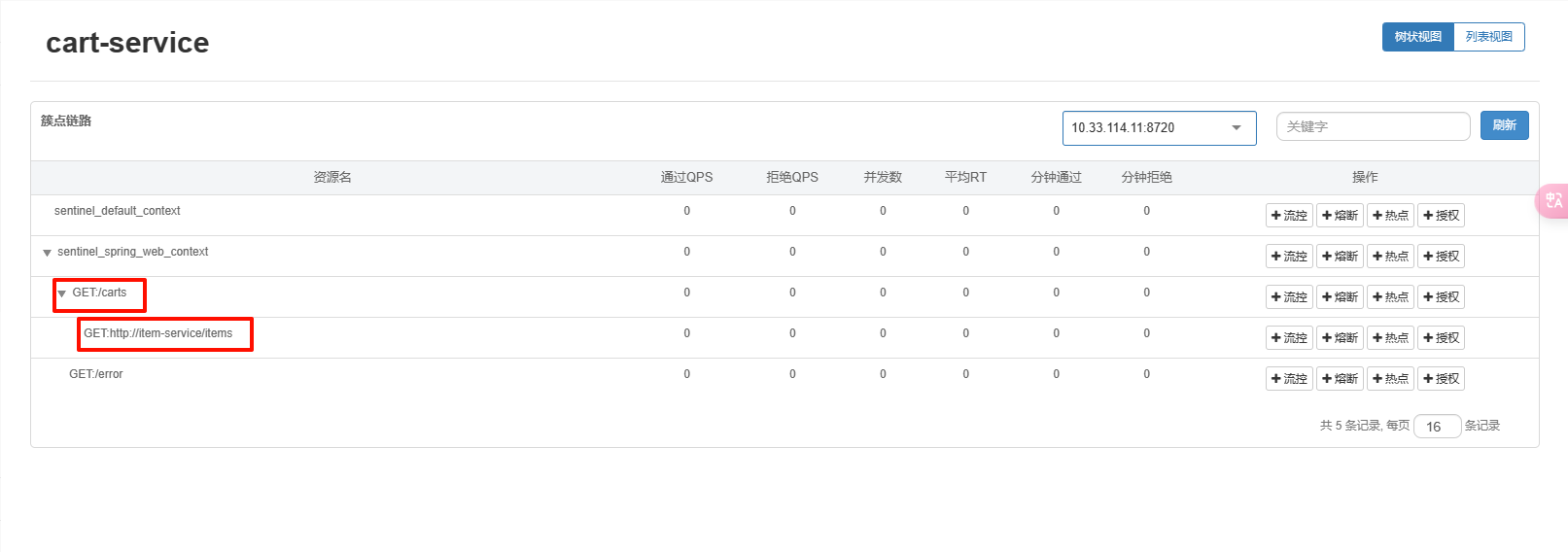
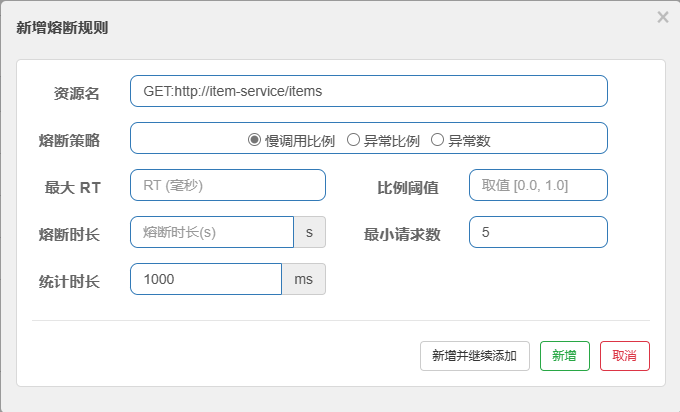
- 熔断策略
- 有三种熔断策略可供选择:
- 慢调用比例:根据调用响应时间来触发熔断。
- 异常比例:根据调用异常比例来触发熔断。
- 异常数:根据调用异常数来触发熔断。
- 有三种熔断策略可供选择:
- 最大 RT
- 最大 RT 是指响应时间,如果请求的响应时间超过这个值即认为是慢调用。
- 例如,设为
500毫秒,表示响应时间超过 500 毫秒的请求被视为慢调用。
- 比例阈值
- 当慢调用的比例达到这个阈值时触发熔断。取值范围在
[0.0, 1.0]之间。 - 例如设为
0.5,表示慢调用比例达到 50% 时触发熔断。
- 当慢调用的比例达到这个阈值时触发熔断。取值范围在
- 熔断时长
- 设置熔断持续的时间,即熔断发生后的休眠期,在此期间请求将会直接失败。
- 例如设为
5秒,表示一旦触发熔断,这个接口将在接下来的 5 秒内直接返回降级处理结果。
- 最小请求数
- 表示触发熔断机制的最小请求数量。如果请求数不足这个数量,即使比例达到阈值也不会触发熔断。
- 默认设置为 5,表示在熔断检测计算的时间窗口内,至少必须有 5 个请求才会进行熔断判断。
- 统计时长
- 表示进行统计的时间窗口大小,以毫秒为单位。
- 默认设置为 1000 毫秒,也即 1 秒。这是统计时间窗口的长度,熔断策略将在这个时间窗口内计算和统计。
比如:
如果配置成下面这样:
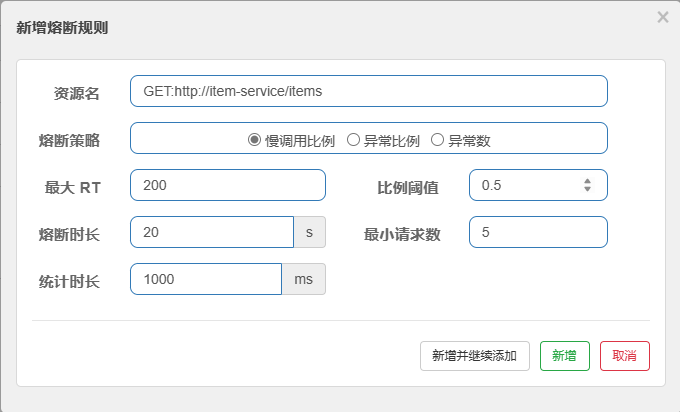
实际效果:
如果该接口在 1 秒内超过 50% 的请求响应时间超过 200 毫秒,同时请求数至少有 5 个,则触发熔断。此时,接口将在接下来的 20 秒内直接返回降级处理结果,相当于在这 20 秒内停止向目标接口发送真实请求,从而保护下游服务避免进一步的压力。
2.2.3 规则持久化
由于每次重启应用,Sentinel 规则将消失在生产环境中,我们需要确保 Sentinel 的配置规则在应用重启后仍然有效。为了达成这一目标,可以使用 Nacos 来持久化 Sentinel 规则,当我们刷新 REST 地址时,Sentinel 控制台的流控规则可以从 Nacos 中读取并继续生效。
①添加依赖:
xml
<!-- Sentinel 持久化相关 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>②修改 bootstrap.yml 配置文件
yaml
spring:
application:
name: cart-service
profiles:
active: dev
cloud:
nacos:
server-addr: 192.168.56.101:8848
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
# 添加以下内容------------------------------------
sentinel:
datasource:
ds0:
nacos:
server-addr: 192.168.56.101:8848 # Nacos 服务地址
dataId: ${spring.application.name}-degrade-rules.json # 数据 ID
groupId: DEFAULT_GROUP # 分组
data-type: json # 数据格式
rule-type: degrade # 规则类型,这里指定为 degrade,表示是熔断降级规则③在nacos中添加共享配置
这里添加的是熔断规则,如果采用限流规则可以看这个:
json[ { "resource": "GET:http://item-service/items", "limitApp": "default", "grade": 1, "count": 1, "strategy": 0, "controlBehavior": 0, "clusterMode": false } ]
resource: 资源名,表示要保护的资源,对应代码中配置的资源名,例如某个接口的路径。limitApp: 流控针对的调用来源,表示只有来自哪些应用的调用才会被限流。
default表示不区分调用来源,所有调用都会被限流。- 也可以设置为具体的应用名,例如
user-service,表示只有来自user-service应用的调用才会被限流。grade: 限流级别,可选值包括:
0:线程数限流,限制并发线程数。1:QPS 限流,限制每秒请求数(这里使用的就是 QPS 限流)。count: 限流阈值,根据grade 的不同含义也不同:
- 当
grade为 0 时,表示最大并发线程数。- 当
grade为 1 时,表示每秒允许通过的请求数,这里设置为10,表示每秒最多允许通过 10 个请求。strategy: 流控策略,可选值包括:
0:直接拒绝策略,超过阈值直接拒绝后续请求。1:关联资源限流策略,当关联资源的流量达到阈值时,对当前资源进行限流。2:链路限流策略,统计整个调用链路上的流量,对超过阈值的请求进行限流。controlBehavior: 流控效果,可选值包括:
0:快速失败,超过阈值直接拒绝后续请求。1:Warm Up 预热模式,逐渐增加流量,避免系统过载。2:排队等待模式,将超过阈值的请求放入队列中等待,直到有资源可用。clusterMode: 是否开启集群限流模式,false表示不开启,true表示开启。
json
[
{
"resource": "GET:http://item-service/items",
"count": 0.5,
"grade": 0,
"timeWindow": 20,
"minRequestAmount": 5,
"statIntervalMs": 10000,
"slowRatioThreshold": 0.5
}
]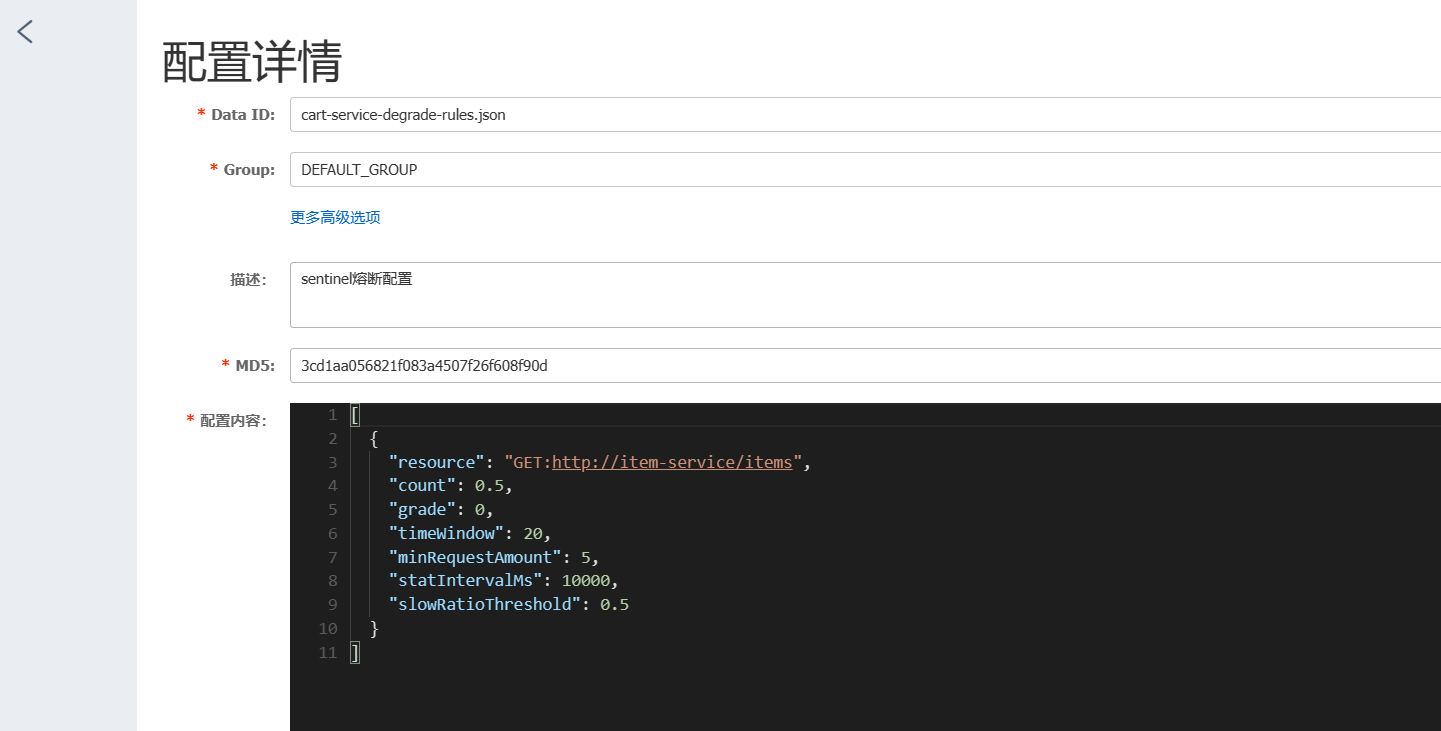
字段解释:
resource:- 资源名称,表示熔断规则应用于的具体资源。
count:- 触发熔断的阈值,数值的含义取决于熔断策略的类型(grade)。
- 如果
grade是 0(慢调用比例),则count表示慢调用占比的阈值,即当慢调用比例达到 50% 时触发熔断。 - 如果
grade是 1(异常比例),则count表示异常请求占比的阈值。 - 如果
grade是 2(异常数),count表示触发熔断的异常请求数阈值。
- 如果
- 触发熔断的阈值,数值的含义取决于熔断策略的类型(grade)。
grade:- 熔断策略类型:
0:表示按异常比例触发熔断。1:表示按慢调用比例触发熔断。2:表示按异常数触发熔断。
- 熔断策略类型:
timeWindow:熔断持续的时间窗口,单位为秒。表示当熔断条件满足时,该资源将进入熔断状态,并在20秒内直接拒绝请求或执行降级处理。minRequestAmount:触发熔断判定的最小请求数。统计时窗口内请求数量需至少达到该值时才会根据熔断策略进行判定。statIntervalMs:统计时间窗口,单位为毫秒。slowRatioThreshold:慢调用比例触发熔断的阈值,这个值跟count是同样用途,用于定义慢调用比例(如果grade是 1)。一般情况下这个值和count值一致。
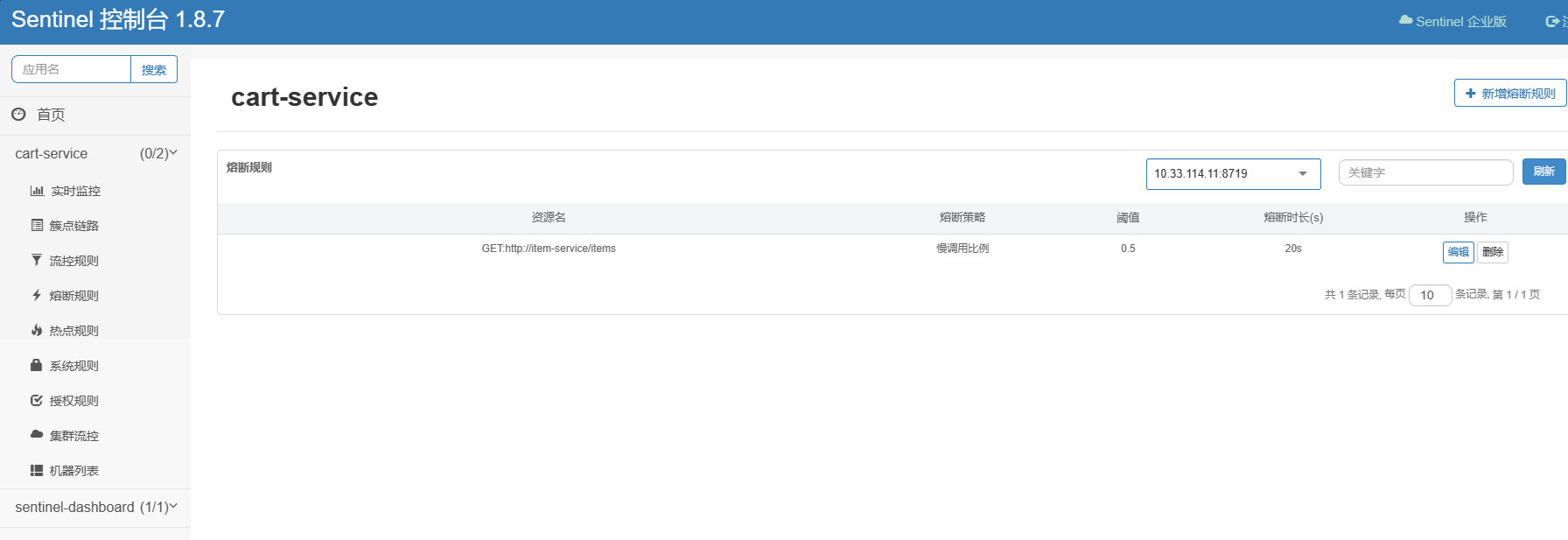
重新启动服务,测试。请求一下相应的接口,然后查看Sentinel 控制台,发现控制台多出来了一个熔断规则:
3 . 总结
通过本篇文章,我们简单地了解了如何使用 Alibaba Sentinel 进行微服务保护,并且详细讲解了三种主要的服务保护策略------请求限流、线程隔离以及服务熔断。其实Sentinel相关的知识内容还有很多很多(太多了!),所以这里就简单讲解一下,提供一些基本的用法,希望对大家有所帮助!
参考文章:
为故障设计微服务架构 - RisingStack Engineering
微服务之微服务保护(Sentinal) - Martin8866 - 博客园 (cnblogs.com)
dashboard | Sentinel (sentinelguard.io)
微服务架构 | 5.2 基于 Sentinel 的服务限流及熔断-阿里云开发者社区 (aliyun.com)