节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:《大模型面试宝典》(2024版) 发布!
之前介绍了高级 RAG 检索的句子窗口检索策略,今天我们再来介绍另外一种高级检索策略------自动合并检索,它比句子窗口要复杂一些。
但请不用担心,下面的介绍会让你理解其中原理,同时会介绍如何使用 LlamaIndex 来构建一个自动合并检索,最后使用 Trulens 来对检索效果进行评估,并与之前的检索策略进行对比。
自动合并检索介绍
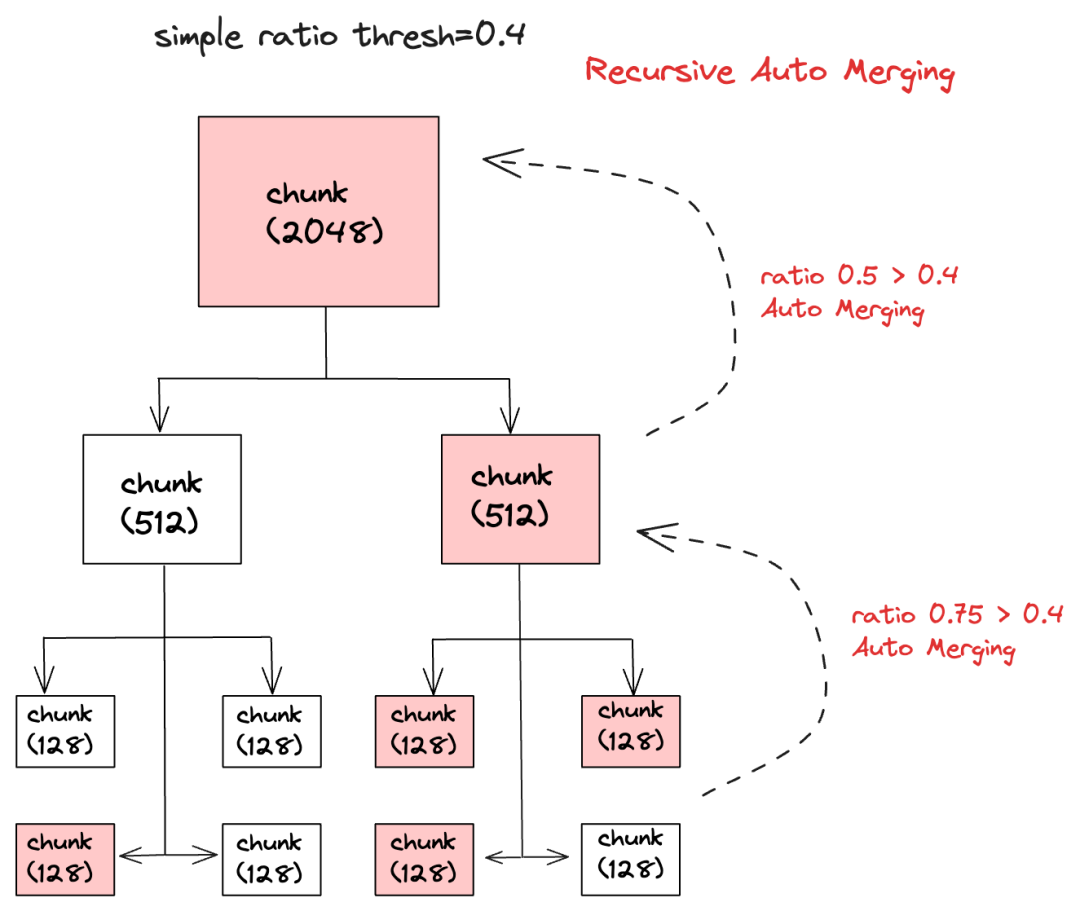
自动合并检索主要是将文档按照块大小拆分成不同层级的节点,这些节点包括父节点和子节点,然后在检索过程中找到相似度高的叶子节点,如果一个父节点中有多个子节点被检索到,那么这个父节点就会被自动合并,最终将父节点的所有文档都作为上下文发送给 LLM(大语言模型),下面是自动合并检索的示意图:
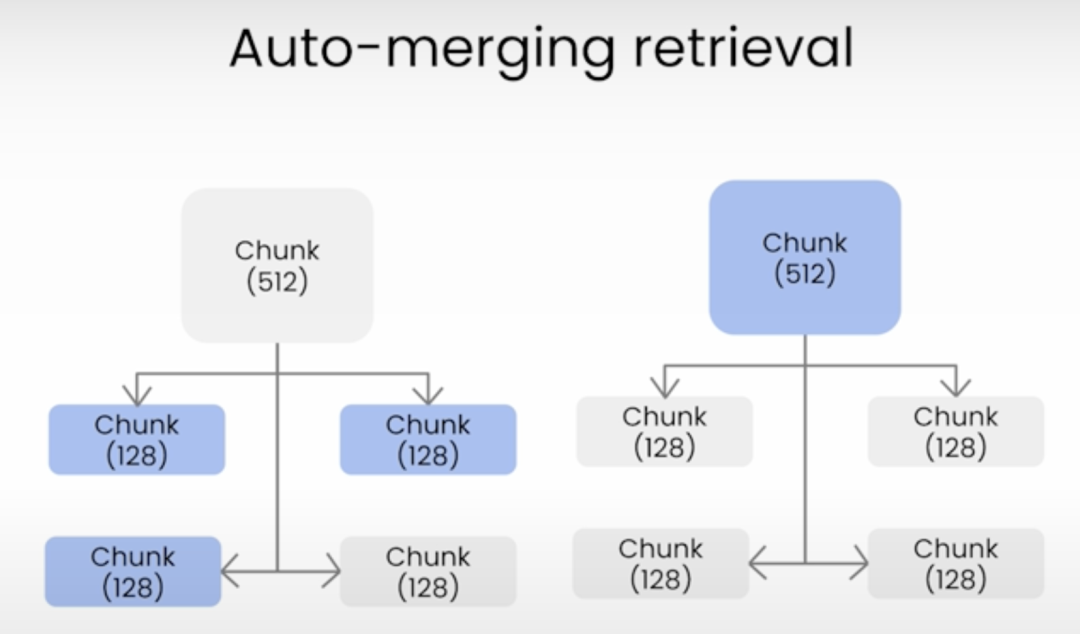
自动合并检索是 LlamaIndex 中的一种高级检索功能,主要有文档拆分和文档合并两个过程,下面我们将通过代码来讲解其中的原理。
文档拆分
在构建一个自动合并检索时,我们首先要创建一个 HierarchicalNodeParser 文档解析器:
python
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import HierarchicalNodeParser
documents = SimpleDirectoryReader("./data").load_data()
node_parser = HierarchicalNodeParser.from_defaults(chunk_sizes=[2048, 512, 128])
nodes = node_parser.get_nodes_from_documents(documents)-
首先我们从
data目录中加载文档 -
然后我们创建一个
HierarchicalNodeParser文档解析器,并设置chunk_sizes为2048, 512, 128 -
再使用文档解析器将文档解析成节点
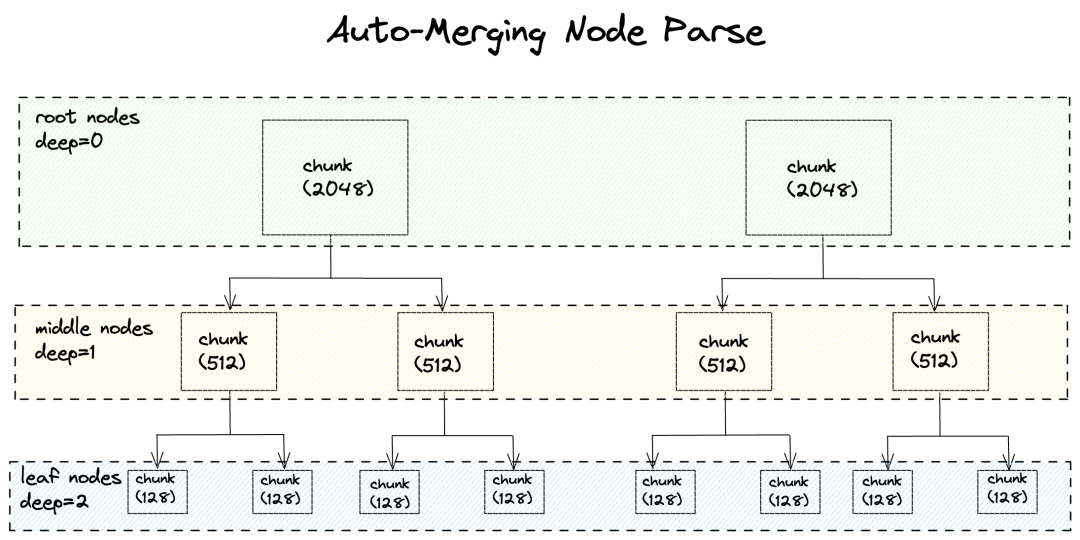
HierarchicalNodeParser 解析器中的参数chunk_sizes默认值是[2048, 512, 128],这表示将文档拆分成 3 个层级,第一个层级的文档大小为 2048,第二个层级的文档大小为 512,第三个层级的文档大小为 128。当然你也可以将层级设置为更少或者更多,比如设置成 2 级,那么chunk_sizes可以是[1024, 128],或者 4 级[2048, 1024, 512, 128]。文档拆分的越小,检索的准确度就会越高,但同时也会造成合并的概率降低,需要根据评估结果来进行调整。
获取根节点和叶子节点
LlamaIndex 提供了几个工具函数来帮助我们获取节点中不同层级的节点,首先我们看下如何获取根节点和叶子节点:
python
from llama_index.core.node_parser import get_leaf_nodes, get_root_nodes
print(f"total len: {len(nodes)}")
root_nodes = get_root_nodes(nodes)
print(f"root len: {len(root_nodes)}")
leaf_nodes = get_leaf_nodes(nodes)
print(f"leaf len: {len(leaf_nodes)}")
# 显示结果
total len: 66
root len: 4
leaf len: 52-
get_leaf_nodes和get_root_nodes这 2 个方法都是传入一个节点列表 -
可以看到总的节点数是 66,根节点是 4,叶子节点是 52
-
根节点加上叶子节点的总数是 56(4+52),和总节点数 66 并不匹配,所以剩下的节点是中间层级的节点,我们可以推算出中间节点数是 10(66-56)
-
如果你的文档层级是 2 级,那么根节点和叶子节点数加起来的总数就等于总节点数
获取不同层级节点
我们再用其他工具函数来验证我们的推理是否正确,这里我们需要使用到 get_deeper_nodes 函数:
python
from llama_index.core.node_parser import get_deeper_nodes
deep0_nodes = get_deeper_nodes(nodes, depth=0)
deep1_nodes = get_deeper_nodes(nodes, depth=1)
deep2_nodes = get_deeper_nodes(nodes, depth=2)
print(f"deep0 len: {len(deep0_nodes)}")
print(f"deep1 len: {len(deep1_nodes)}")
print(f"deep2 len: {len(deep2_nodes)}")
# 显示结果
deep0 len: 4
deep1 len: 10
deep2 len: 52- get_deeper_nodes 方法第一个参数是节点列表,第二参数是要查询的层级,0 表示第 1 层级,也就是根节点
可以看到deep0节点数是 4,相当是根节点,deep2的节点数是 52,相当是叶子节点,而deep1就是中间层级的节点,共有 10 个,和我们推理的结果是一致的。
获取子节点
LlamaIndex 还提供了 get_child_nodes 函数来获取节点的子节点:
python
from llama_index.core.node_parser import get_child_nodes
middle_nodes = get_child_nodes(root_nodes, all_nodes=nodes)
leaf_nodes = get_child_nodes(middle_nodes, all_nodes=nodes)
print(f"middle len: {len(middle_nodes)}")
print(f"leaf len: {len(leaf_nodes)}")
# 显示结果
middle len: 10
leaf len: 52-
get_child_nodes 方法第一个参数是要获取子节点的节点列表,第二个参数是所有节点
-
这里我们先获取根节点下的所有子节点,得到 10 个子节点,这些节点也就是中间层级节点
-
然后我们再获取这些中间节点下的所有子节点,得到 52 个子节点,这些节点也就是叶子节点
当然我们也可以获取某个节点下的子节点,比如获取第一个根节点的子节点:
python
root0_child_nodes = get_child_nodes(root_nodes[0], all_nodes=nodes)
print(f"root0 child len: {len(root0_child_nodes)}")
# 显示结果
root0 child len: 2这表示第一个根节点下有两个子节点,这 2 个子节点也是中间层级节点。
节点文档内容
每个父节点的文档内容包含了它所有子节点的文档内容:
python
print(f"deep1[0] node: {deep1_nodes[0].text}")
child = get_child_nodes([deep1_nodes[0]], all_nodes=nodes)
print(f"child[0] node of deep1[0]: {child[0].text}")
# 显示结果
deep1[0] node: 自从宇宙魔方于1942年被人类发现后针对其展开过无数次探索,栖息于宇宙中的强大外星势力也从此开始盯住地球,被它们营救的洛基负责率领齐塔瑞军团。在地球,由神盾局建立的一所科研基地[注 14]中进行着神盾局与美国国家航空航天局和美国空军合作的"天马项目"[注 15],试图提炼出魔方的能量并加以利用,但却造成魔方的能量数值持续攀升。神盾局探员菲尔·考森和玛丽亚·希尔受尼克·弗瑞局长的命令疏散基地,而魔方却于地下实验室自行开启传送门将洛基传送过来。洛基杀光所有护卫后,用他手上的一把能灌输能量的权杖洗脑并操纵弗瑞的亲信克林特·巴顿和协助神盾局着手魔方项目的科学家埃里克·塞尔维格格,在他们的陪同下带着魔方坐车逃离基地。没过多久,流出的能量爆发造成基地完全坍塌,弗瑞为了应对外来威胁而命令所有人备战。
child[0] node of deep1[0]: 自从宇宙魔方于1942年被人类发现后针对其展开过无数次探索,栖息于宇宙中的强大外星势力也从此开始盯住地球,被它们营救的洛基负责率领齐塔-
我们首先打印中间层级第一个节点的文档内容
-
然后再获取这个中间节点第一个子节点,并打印其文档内容
-
可以看到父节点的文档内容包含了子节点的文档内容
文档合并
文档合并是自动合并检索的重要组成部分,文档合并的效果决定了提交给 LLM 的上下文内容,从而影响了最终的生成结果。
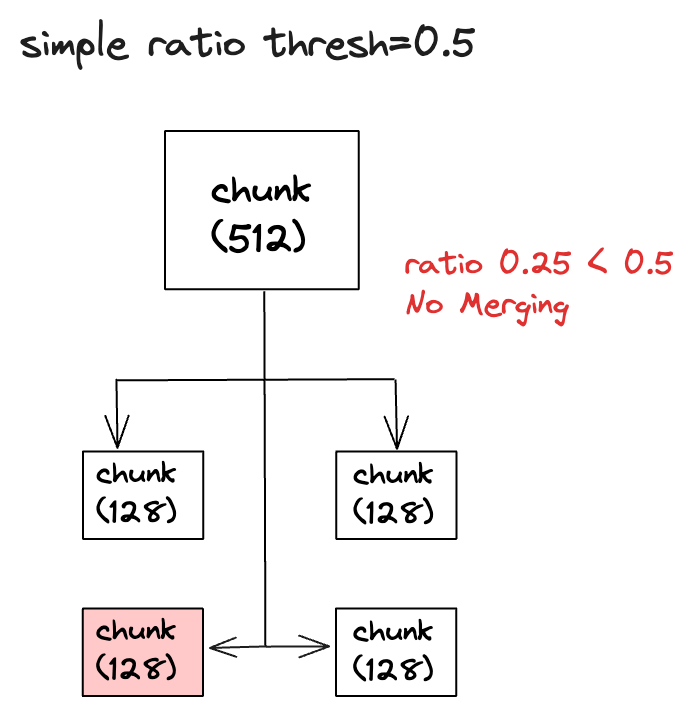
首先自动合并检索会根据问题对所有叶子节点进行检索,这使得检索的准确率比较高,在自动合并检索中有一个参数叫simple_ratio_thresh,它的默认值是 0.5,表示自动合并文档的阀值,如果在一个父节点中,子节点被检索到的比例小于这个阀值,那么自动合并功能将不会生效,这样提交给 LLM 的上下文就只会包含检索到的叶子节点。反之如果大于这个阀值,文档就会自动合并,最终提交给 LLM 的上下文就会包含这个父节点的内容。
比如父节点有 4 个子节点,检索时发现只有 1 个子节点,那么子节点被检索到的比例就是 0.25(1/4),小于阀值 0.5,所以自动合并功能不会生效,最终提交给 LLM 的上下文就只会包含那个检索到的子节点。
如果父节点有 4 个子节点,检索时发现有 3 个子节点,那么子节点被检索到的比例就是 0.75(3/4),大于阀值 0.5,所以自动合并功能会生效,最终提交给 LLM 的上下文就是父节点的内容。
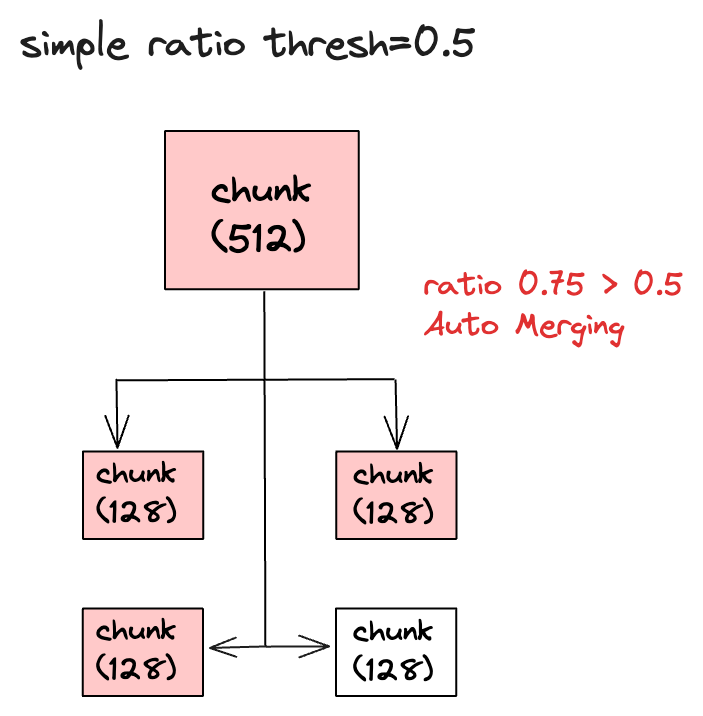
而且自动合并的功能是一个不断重复的过程,这表示自动合并会从最底层的节点开始合并,然后一直合并到最顶层的节点,最终得到所有合并后的文档,重复的次数取决于文档解析器拆分文档的层级,比如chunk_sizes是[2048, 512, 128],那么文档拆分后的层级是 3,如果每一层的自动合并都被触发的话,就会自动合并 2 次。
自动合并使用
下面我们再来看看自动合并检索在实际 RAG 项目中的使用,文档数据我们还是使用之前维基百科上的复仇者联盟1电影剧情来进行测试。
自动合并检索示例
我们来看下如何使用 LlamaIndex 构建自动合并检索:
python
from llama_index.core.node_parser import (
HierarchicalNodeParser,
get_leaf_nodes,
)
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.core.settings import Settings
from llama_index.core.storage.docstore import SimpleDocumentStore
from llama_index.core.retrievers import AutoMergingRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
node_parser = HierarchicalNodeParser.from_defaults(chunk_sizes=[2048, 512, 128])
documents = SimpleDirectoryReader("./data").load_data()
nodes = node_parser.get_nodes_from_documents(documents)
leaf_nodes = get_leaf_nodes(nodes)
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
embed_model = OpenAIEmbedding()
Settings.llm = llm
Settings.embed_model = embed_model
Settings.node_parser = node_parser
docstore = SimpleDocumentStore()
docstore.add_documents(nodes)
storage_context = StorageContext.from_defaults(docstore=docstore)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=12)
retriever = AutoMergingRetriever(
base_retriever,
storage_context,
simple_ratio_thresh=0.3,
verbose=True,
)
auto_merging_engine = RetrieverQueryEngine.from_args(retriever)-
首先我们定义了
HierarchicalNodeParser文档解析器来解析文档,这在前面已经介绍过了,这里不再赘述 -
然后我们使用 OpenAI 的 LLM 和 Embedding 模型进行答案生成和向量生成
-
再创建
storage_context来保存所有节点nodes,后面的自动合并检索会根据叶子节点来找其相关的父节点,所以这里需要保存所有节点 -
接下来我们先构建一个基础检索
base_index,这个检索会根据问题对所有叶子节点leaf_nodes进行检索,找到匹配度最高的similarity_top_k个节点,这里我们将获取 12 个匹配度最高的叶子节点 -
我们再构建一个自动合并检索
AutoMergingRetriever,这个检索会根据基础检索的结果来进行合并操作,这里我们设置了simple_ratio_thresh为 0.3,即当检索子节点比例大于这个阀值的节点就会进行自动合并。verbose参数设置为 True,表示输出合并的过程 -
最后我们使用
RetrieverQueryEngine来创建一个检索引擎
接下来我们就可以使用这个检索引擎来回答问题了:
python
question = "奥创是由哪两位复仇者联盟成员创造的?"
response = auto_merging_engine.query(question)
print(f"response: {str(response)}")
print(f"nodes len: {len(response.source_nodes)}")
# 显示结果
> Merging 5 nodes into parent node.
> Parent node id: 80d1eeed-3447-4987-b05d-49fd4b6aabd4.
> Parent node text: 神盾局解散后,由托尼·斯塔克、史蒂芬·罗杰斯、雷神、娜塔莎·罗曼诺夫、布鲁斯·班纳以及克林特·巴顿组成的复仇者联盟负责全力搜查九头蛇的下落,这次透过"盟友"提供的情报而进攻位于东欧的国家"索科维...
> Merging 4 nodes into parent node.
> Parent node id: 2e719ad1-89fe-4d00-add4-e0296b19eab3.
> Parent node text: 复仇者们到达后跟他们正面交锋,但大多数人被旺达用幻象术迷惑,看到各自心中最深层的"阴影";唯独托尔看见在家乡阿萨神域发生的不明景象。旺达同时迷惑班纳的大脑,使其丧失理智而变成绿巨人跑到约翰内斯堡...
> Merging 2 nodes into parent node.
> Parent node id: c1e7e8a1-d50b-4a35-9b0d-beec29993d1a.
> Parent node text: 奥创发布机械大军,在位于城市正中央的教堂里启动靠振金造的陆地合成器,使整座城市陆地上升,企图透过陨石撞击方式灭绝人类后由机器人取代。班纳潜入基地救出娜塔莎,娜塔莎将他从高处推落释放出绿巨人支持战...
response: 奥创是由托尼·斯塔克和布鲁斯·班纳这两位复仇者联盟成员创造的。
nodes len: 4在没有经过自动合并之前,我们让基础检索获取了 12 个匹配度最高的叶子节点,在输出结果中可以看到,这 12 个节点经过了 3 次合并操作,最终我们得到了 4 个节点,这些节点中既包含叶子节点,也包含合并过后的父节点。
检索效果对比
我们再使用Trulens2来评估自动合并检索的效果:
python
tru.reset_database()
rag_evaluate(base_engine, "base_evaluation")
rag_evaluate(sentence_window_engine, "sentence_window_evaluation")
rag_evaluate(sentence_window_engine, "auto_merging_evaluation")
Tru().run_dashboard()执行代码后,我们可以在浏览器中看到 Trulens 的评估结果:
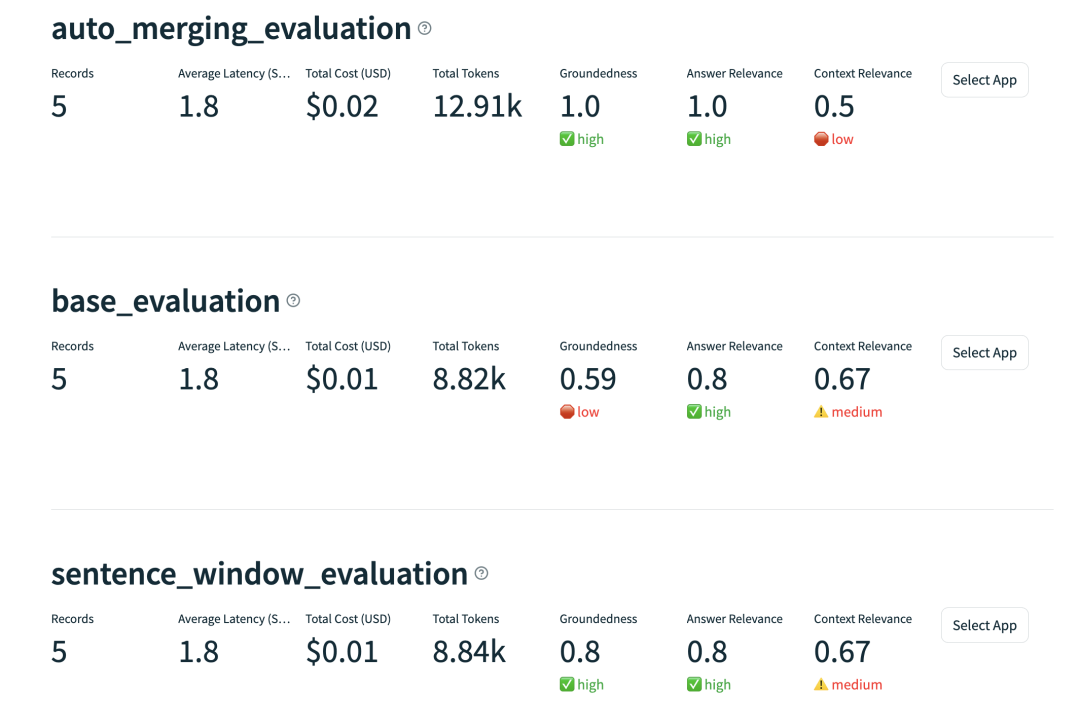
在评估结果中,我们可以看到自动合并检索相比其他两种检索的效果要好,但这不表示自动合并检索会一直比其他检索好,具体的评估效果还要看原始的输入文档,以及检索的参数设置等,总之,具体的评估效果要根据实际情况来评估。
总结
自动合并检索是高级 RAG 检索的一种方法,文档拆分和文档合并的思想是该方法的主要特点,本文介绍了自动合并检索的原理和实现方法,并使用 Trulens 来评估了自动合并检索的效果,希望可以帮助大家更好地理解和使用自动合并检索。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要获取最新面试题、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
用通俗易懂方式讲解系列
参考:
1复仇者联盟: https://en.wikipedia.org/wiki/Avenger
2Trulens: https://www.trulens.org/