本文转载自:在 LLM 架构中应用多专家模型 2024年 3月 14日 By Kyle Kranen and Vinh Nguyen
https://developer.nvidia.cn/zh-cn/blog/applying-mixture-of-experts-in-llm-architectures/
文章目录
一、概述
多专家模型 (MoE) 大型语言模型 (LLM) 架构最近出现了,无论是在 GPT-4 等专有 LLM 中,还是在开源版本的社区模型中,如 Mistral Mixtral 8x7B。
Mixtral 模型的强劲相对性能引起了极大的兴趣,并引发了许多关于 MoE 及其在 LLM 架构中使用的问题。
那么,什么是 MoE,为什么它很重要?
多专家模型是神经网络的架构模式,它将层或运算 (例如线性层、MLP 或注意力投影) 的计算拆分为多个"专家"子网络。
这些子网络各自独立执行自己的计算,并组合其结果以创建 MoE 层的最终输出。
MoE 架构可以是密集的,这意味着每个专家都用于每个输入,也可以是稀疏的,这意味着每个输入都使用一个专家子集。
本文主要探讨MoE在LLM架构中的应用。
如需了解MoE在其他领域的应用,请参阅使用稀疏的专家混合模型扩展视觉、适用于多语言ASR流式传输的专家级混合转换器以及FEDformer:用于长期序列预测的频率增强型分解转换器。
二、LLM 架构领域的专家齐聚一堂
本节提供一些背景信息,并重点介绍在 LLM 架构中使用 MoE 的优势。
1、模型容量
模型容量 可以定义为模型能够理解或表达的复杂程度。
通常情况下,(经过充分训练的) 具有更多参数的模型过去证明具有更大的容量。
如何将 MoE 分解为容量?
参数较多的模型通常具有更大的容量,而 MoE 模型可以通过将模型的各个层替换为 MoE 层 (其中专家子网络的大小与原始层相同),从而有效地增加相对于基础模型的容量。
研究人员已经对MoE模型的准确性进行了调查,该模型使用与全密集模型相似数量的标记进行训练(MoE大小:E+P参数与全密集大小相比:EP参数)。
尽管这仍然是一个活跃的研究领域,但全密集模型的表现普遍优于MoE模型。
有关更多详细信息,请参阅 适用于路由语言模型的统一扩展定律。
这就提出了一个问题,为什么不直接使用密集模型?
这里的答案在于稀疏 MoE,具体来说,稀疏 MoE 在每个使用的参数上都更高效。
请考虑 Mixtral 8x7B 是一个使用 8 位专家 MoE 的模型,其中每个令牌仅使用 2 位专家。
在这种情况下,在模型中单个令牌的任何给定前向传递中,批量中任何给定令牌使用的参数数量都要低得多 (共使用 460 亿个参数,其中使用 120 亿个参数)。
与使用所有 8 位专家或类似大小的全密集模型相比,这需要的计算量更少。
给定在训练中将令牌分批在一起,则使用大多数 (如果不是所有) 专家。
这意味着在此模式中,与相同大小的密集模型相比,稀疏 MoE 使用的计算量较少,且内存容量相同。
在一个 GPU 小时数备受追逐、时间和成本高昂的世界里,大规模训练全密集模型显得尤为昂贵。
据报道,Meta 训练的 Lama 2 模型集(全密集)耗费了 330 万 NVIDIA A100 预训练的 GPU 小时数。
具体来说,在 1024 个 GPU 上以全容量运行 330 万个 GPU 小时,不包括任何停机时间,大约需要 134 天。
这还不包括任何实验、超参数扫描或训练中断。
2、MoE 在降低成本的同时训练更大的模型
MoE 模型通过提高每个权重的触发器效率来降低成本,这意味着在具有固定时间或计算成本限制的机制下,可以处理更多令牌,并可以进一步训练模型。
鉴于具有更多参数的模型需要更多样本才能完全收,这基本上意味着我们可以在固定预算下训练比密集模型更好的 MoE 模型。
3、 MoE 可降低延迟
在大量提示和批量(其中计算是瓶颈)的情况下,MoE 架构可用于降低第一个令牌的服务延迟。
随着用例(例如 检索增强生成 (RAG) 和自主智能体可能需要多次调用模型,从而增加单次调用延迟。
三、MoE 架构的工作原理是什么?
MoE 模型有两个关键组件。
首先,构成混合模型的"专家"子网络,用于密集和稀疏 MoE.其次,稀疏模型使用路由算法来确定哪些专家会处理哪些标记。
在密集和稀疏 MoE 的某些公式中,MoE 可能包含一个加权机制,用于执行专家输出的加权平均值。
在本文中,我们将重点介绍稀疏案例。
在许多已发表的论文中,MoE 技术应用于 Transformer 模块内的多层感知器 (MLP).在这种情况下,Transformer 模块内的 MLP 通常被一组专家 MLP 子网络取代,这些子网络会结合其结果,使用平均值或求和生成 MLP MoE 输出。
研究还表明,MoE 的概念可以推广到 Transformer 架构的其他部分。
最近的论文 SwitchHead: 利用混合专家注意力加速 Transformer 建议 MoE 也可应用于投影层,这些层将输入转换为 Q、K 和 V 矩阵,以供注意力运算使用。
其他论文则建议将条件执行 MoE 概念应用于注意力头本身。
在特定输入的情况下,路由网络(或算法)用于确定哪些专家被激活。
路由算法可以是简单的(在张量平均值中统一选择或合并),也可以是复杂的,如在采用专家选择路由的多专家组合中所述。
在决定给定路由算法对问题的适用性的许多因素中,我们经常讨论两个核心因素:特定路由机制下的模型准确性和特定机制下的负载均衡。
选择正确的路由算法可以在准确性和触发器效率之间进行权衡。
完美的负载均衡路由算法可能会降低每个令牌的准确性,而最准确的路由算法可能会在专家之间分配不均的令牌。
许多提议的路由算法旨在最大化模型准确性,同时最小化任何给定专家提出的瓶颈。
虽然 Mixtral 8x7B 使用 Top-K 算法来路由令牌,但诸如 采用专家选择路由的多专家组合 引入概念,以确保专家不会被过度引导。
这可以防止瓶颈的形成。
四、试验 Mixtral 模型
在实践中,每位专家都会学习什么?他们专注于低级语言结构 (例如标点符号、动词、形容词等),还是精通高级概念和领域 (例如编码、数学、生物学和法律)?
为了进行实验,我们使用了Mixtral 8x7B 模型,该模型包含32个顺序Transformer块,每个块中的MLP层被替换为稀疏MoE块,每个MoE块包含8个专家,每个令牌只激活其中两个专家。
其他层,包括自注意力层和归一化层,由所有令牌共享。
值得注意的是,当读取 8x7B 的名称时,可以想象专家是 8 个独立的完整网络,每个网络都有 70 亿个参数,每个令牌都由这 8 个完整网络中的一个完全端到端处理 (图 1)。
这种设计将生成一个 8x7B=56B 的模型。
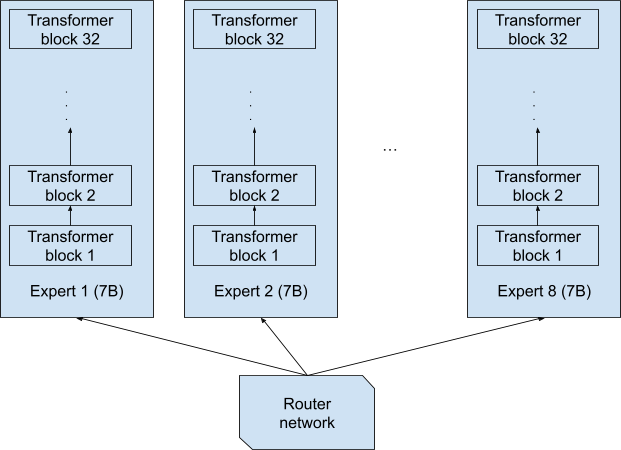
图 1.Mixtral 8x7B 模型的可能解释
虽然这无疑是合理的设计,但并不是 Mixtral 8x7B 中使用的设计。
图 2 描述了实际设计,每个令牌都处理了 70 亿个参数。
请注意,令牌及其副本 (由第二专家在每层处理) 总共仅处理 129 亿个参数,而不是 2x7B=14B.由于共享层的原因,整个网络仅处理 470 亿个参数,而不是 8x7B=56B 参数。
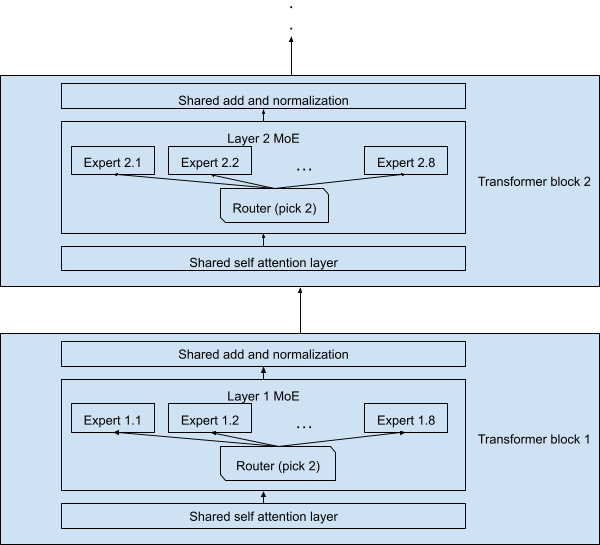
图 2.简化的 Mixtral 8x7B 模型架构
因此,每个通过网络的令牌都必须通过类似格点的结构, 可能的网络实例化。
可能的网络实例化。
如果我们将每个实例化都视为"全栈专家"(处理端到端令牌的专家),是否有可能了解它们提供的专业知识?遗憾的是,由于 28%=32%是一个非常大的数字 (+2+10%=46%),它比用于训练 LLM 的所有数据 (大多数 LLM 的数据为+3T 到 10T 令牌) 大几个数量级,因此同一实例化很少会处理任何两个令牌。
因此,我们将研究每个层专家专门研究的是什么,而不是每个完整的专家组合。
五、实验结果
我们使用大规模的多任务语言理解(MMLU)基准测试来评估模型的性能。
该基准测试包括涉及57个主题的多项选择题,涵盖了广泛的领域,如抽象代数、世界信仰、专业法、解剖学、天文学和商业道德等。
我们记录了第1层、第16层和第32层8位专家中每个专家的令牌专家作业。
在解析数据后,有几项观察值得注意。
1、负载均衡
得益于负载均衡,专家可以获得均衡的负载,但最忙碌的专家仍可获得比最忙碌的专家多 40 -- 60%的令牌。
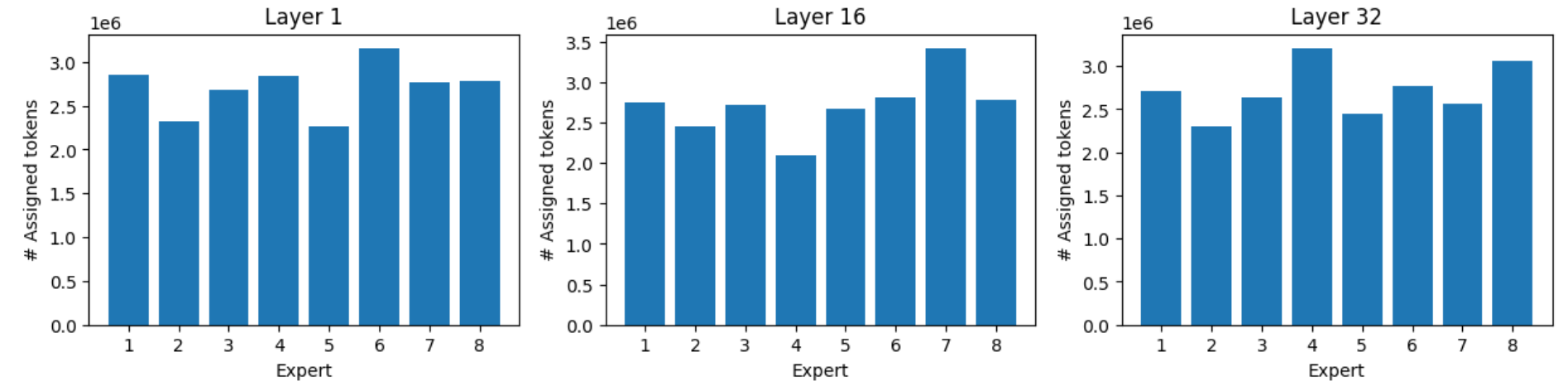
图 3.所有 MMLU 主题的专家加载分布
2、领域专家任务分配
某些领域比其他领域更能激活某些专家。
在第 32 层中,其中一个示例是抽象代数,它比其他示例更多使用专家 3 和专家 8、
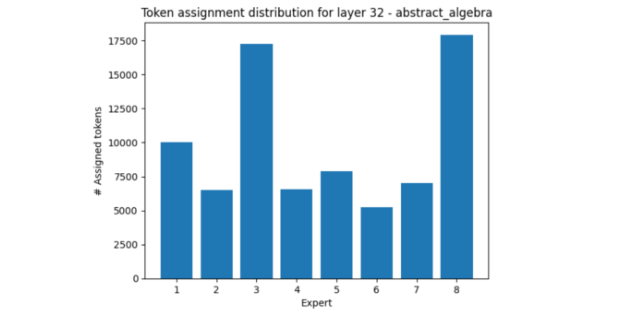
图 4.在第 32 层中,抽象代数的令牌分布情况
另一方面,专业法领域主要激活专家 4,而相对来说使专家 3 和专家 8 静音。
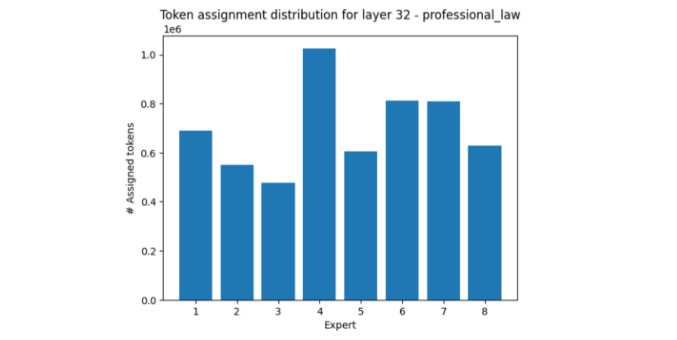
图 5.在专业定律的第 32 层中,令牌在专家上的分布
另一个引人入胜的例子是世界性的教会,专家 7 收到的令牌比专家 8 少 5 倍多。
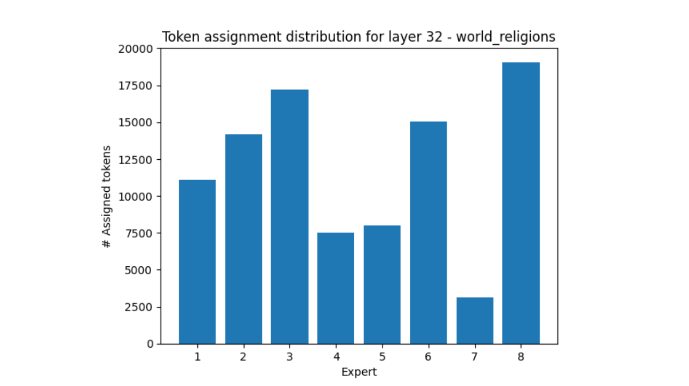
图 6.针对世界性教会,在第 32 层中,令牌在专家上的分布
这些实验结果表明,专家的负载分布倾向于在不同的主题范围内保持一致。
但是,当所有样本都完全属于某个主题时,可能会出现很大的分布不平衡。
3、专家推荐的最佳令牌
图 7 中的"cloud"(云) 一词显示了每位专家最频繁处理的令牌。

图 7.专家处理的最常见令牌
4、按令牌划分的首选专家
每个令牌是否都有首选专家?每个令牌似乎都有一组首选专家,如下示例所示。
令牌":"和所有":"令牌的专家分配在第 1 层由专家 1 和 7 处理,在第 32 层由专家 3 和 8 处理 (图 8)。
图 9、10 和 11 显示了各种令牌的专家分配。
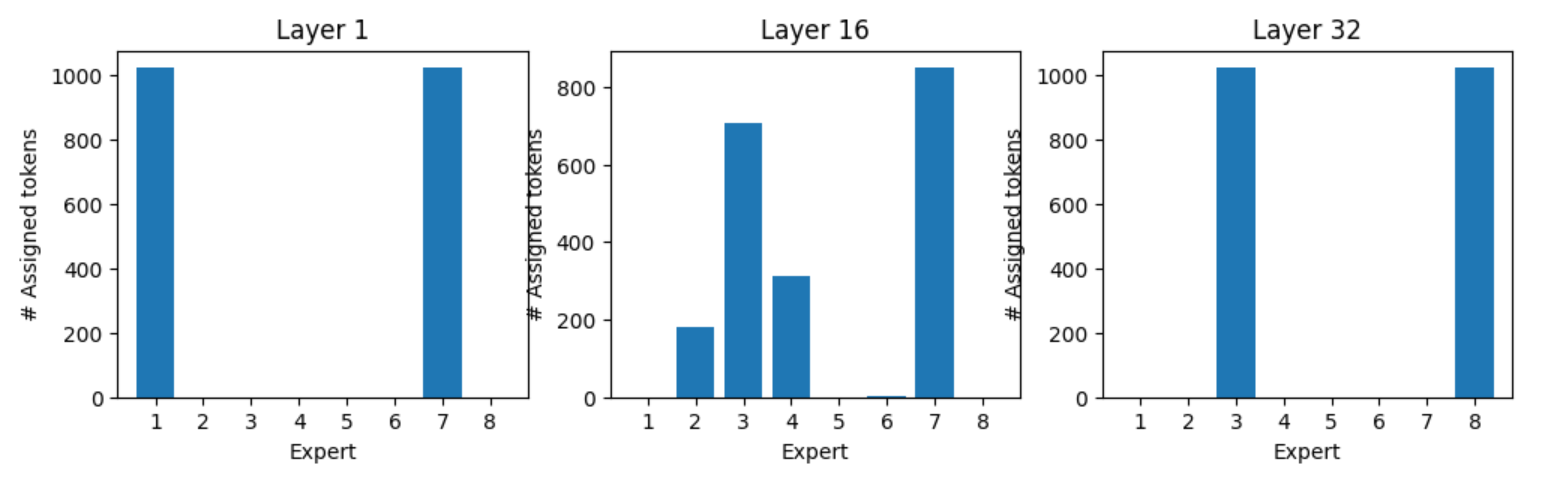
图 8.令牌":"的专家分配
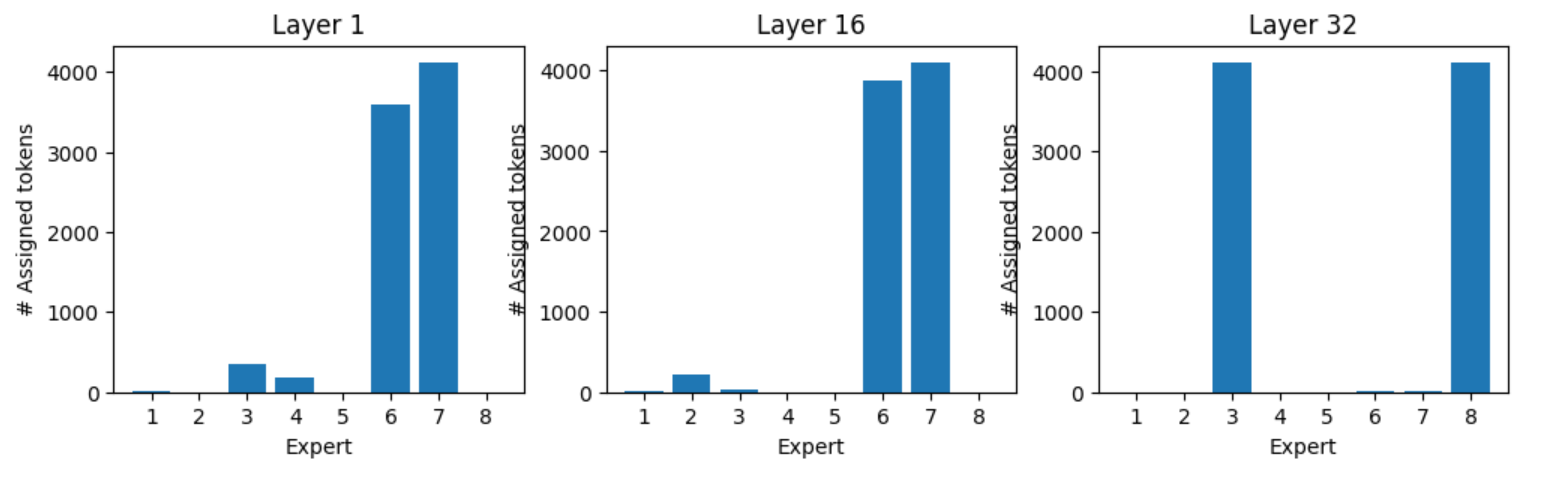
图 9.令牌"。"的专家分配
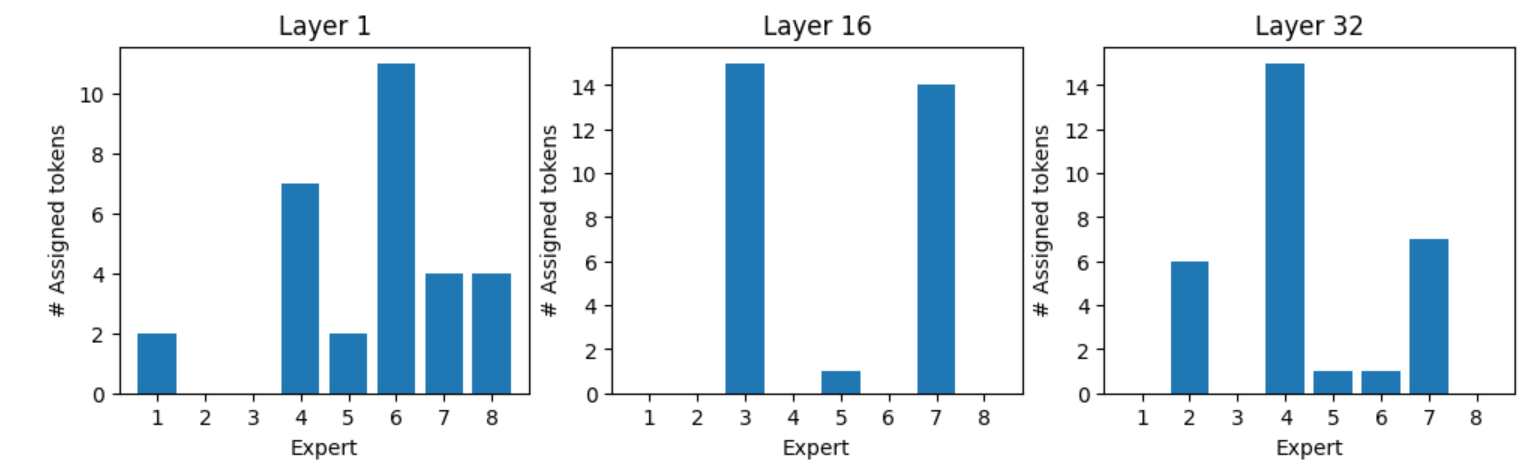
图 10.专家分配令牌"what"
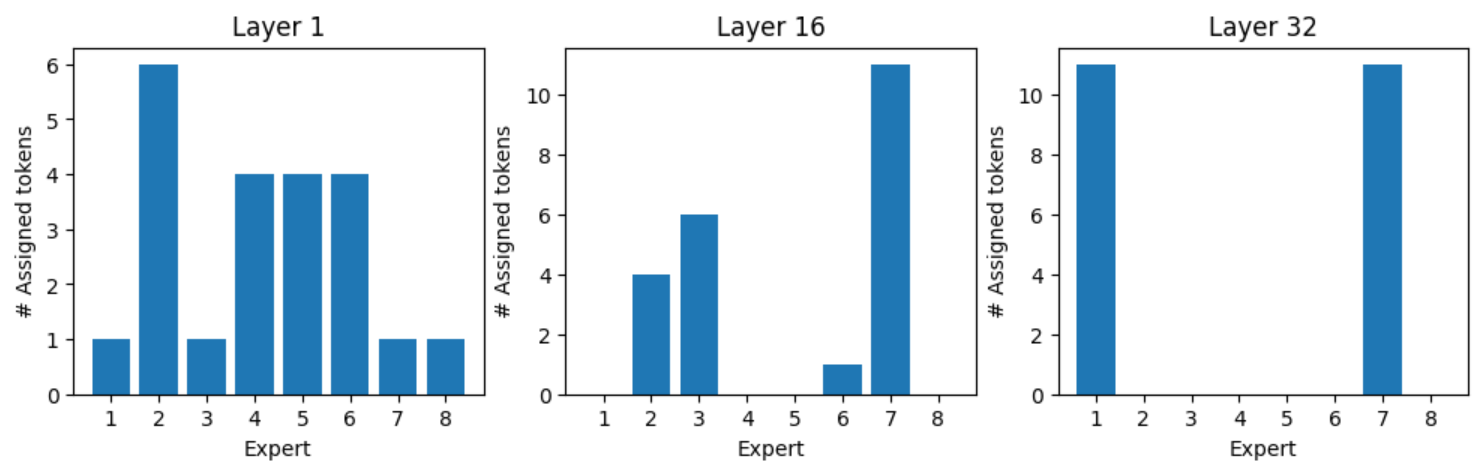
图 11.令牌"Who"的专家分配
六、总结
MoE 模型为模型预训练吞吐量提供了明显的优势,支持在与密集模型相同的计算量上训练更具表现力的稀疏 MoE 模型。
这将在相同的计算预算下生成更具竞争力的模型。
MoE 模型可以针对整个网络或现有网络中的特定层。
通常,应用带有路由的稀疏 MoE 以确保仅使用部分专家。
我们的实验探索了令牌的分配方式以及专家之间的相对负载平衡。
这些实验表明,尽管采用了负载平衡算法,但仍然存在很大的分布不平衡,这可能会影响推理效率低下,因为一些专家提前完成工作,而另一些则过载。
这是一个值得关注的积极研究领域。
您可以尝试 Mixtral 8x7B 指令模型 以及其他 AI 基础模型,这些模型可以在 NVIDIA NGC 目录中找到。
2024-05-28(二)