神经网分析
- 机器学习处理的是数据,通过学习输入的数据,从而建立模型,以便预测新的数据的输出

按照类型可以进行如下分类
-
监督分类
-
非监督分类
-
强化学习
神经元

生物学中,人的大脑是由多个神经元互相连接形成网络而构成的。也就是说,一个神经元从其他神经元接收信号,也向其他神经元发出信号。大脑就是根据这个网络上的信号的流动来处理各种各样的信息的。

如果用数学公式来表示信号的传递,可以通过变量 x x x来表示输入信号,当有信号输入时, x = 1 x=1 x=1; 当无输入信号时, x = 0 x=0 x=0;

如果有多个输入信号, x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3,每个信号具有各自的权重 ω 1 \omega_1 ω1、 ω 2 \omega_2 ω2、 ω 3 \omega_3 ω3
那么输入信号之和可以如下表示:
ω 1 X 1 + ω 2 X 2 + ω 3 X 3 \omega_1X_1+\omega_2X_2+\omega_3X_3 ω1X1+ω2X2+ω3X3

可以使用如上所示的简化图,这样很容易就能画出大量的神经元,用箭头方向区分输入和输出。为了与生物学的神经元区分开来,我们把经过这样简化、抽象化的神经元称为神经单元(unit)
近两年,由于深度学习网络的非线性计算能力以及深度挖掘数据潜力的优势,在海洋、气象领域产生了许多应用。包括ConvLSTM、GRU等

内容介绍
我将从从以下几个方面进行介绍
- 前向传播
- 后向传播 / 梯度下降
- 损失函数
- 激活函数
- 卷积
- 池化
前向传播
什么是神经网络model呢?
-
它实际上是一组参数 θ \theta θ 指定的函数 f f f
-
下面是一个关于 x x x的线性预测函数,包含权重 ω \omega ω和偏差 b b b
-
存在偏差的原因之前在回归分析中也介绍过,原因在于当使用一个线性函数来将预测因子 x x x进行线性组合时,观测值与估测值之间是存在一个随机误差的,因此添加一个 b b b
以下函数表示多个输入值 x x x 与其权重 ω \omega ω 和偏置 b b b 之间的线性组合关系,其实可以理解为一个一元线性回归方程
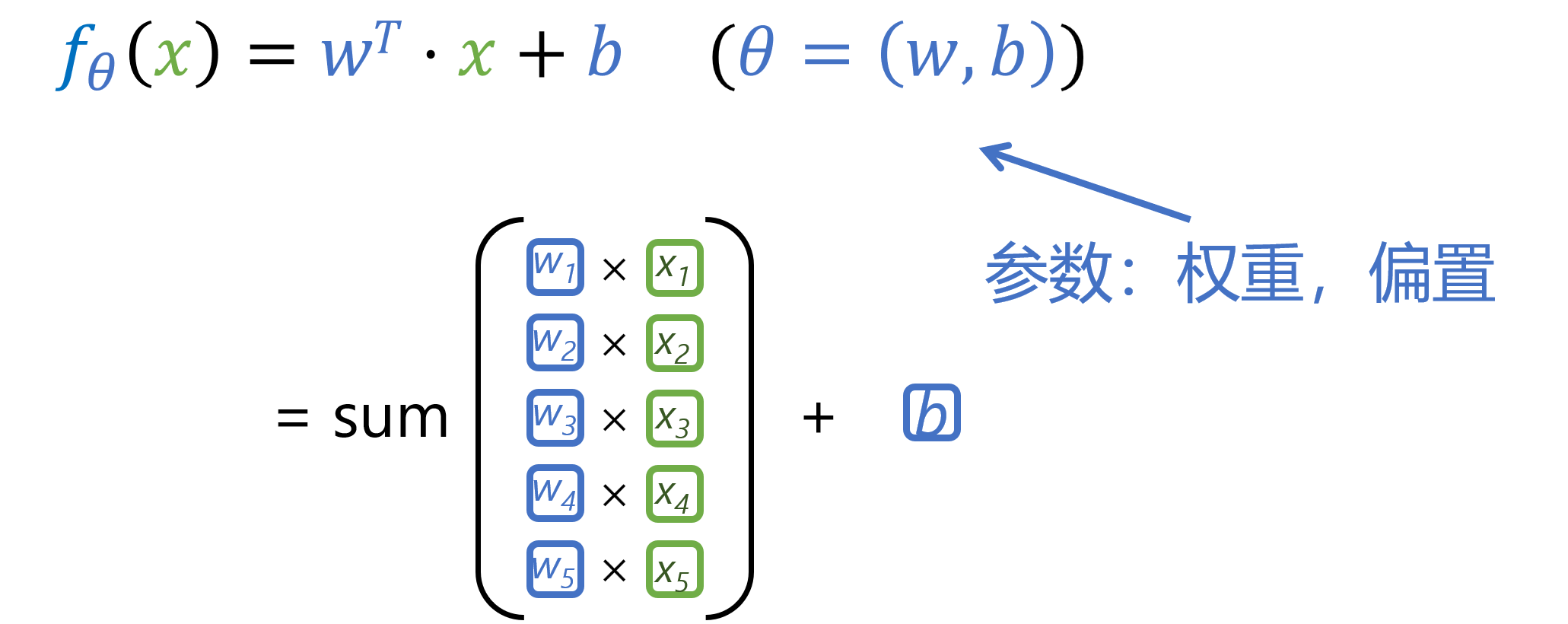
现在来回答什么是神经网络?
- 神经网络由带有神经元(即计算单元)的隐藏层组成,单个神经元将一组输入映射为一个输出数,或者𝑓:𝑅^𝐾→𝑅

看上面的 Z Z Z,是不是和多元线性回归模型非常类似呢?
- 只不过为了表示其非线性能力,在线性组合 Z Z Z上增加了一个非线性激活函数 σ \sigma σ,然后最终输入为 a a a.
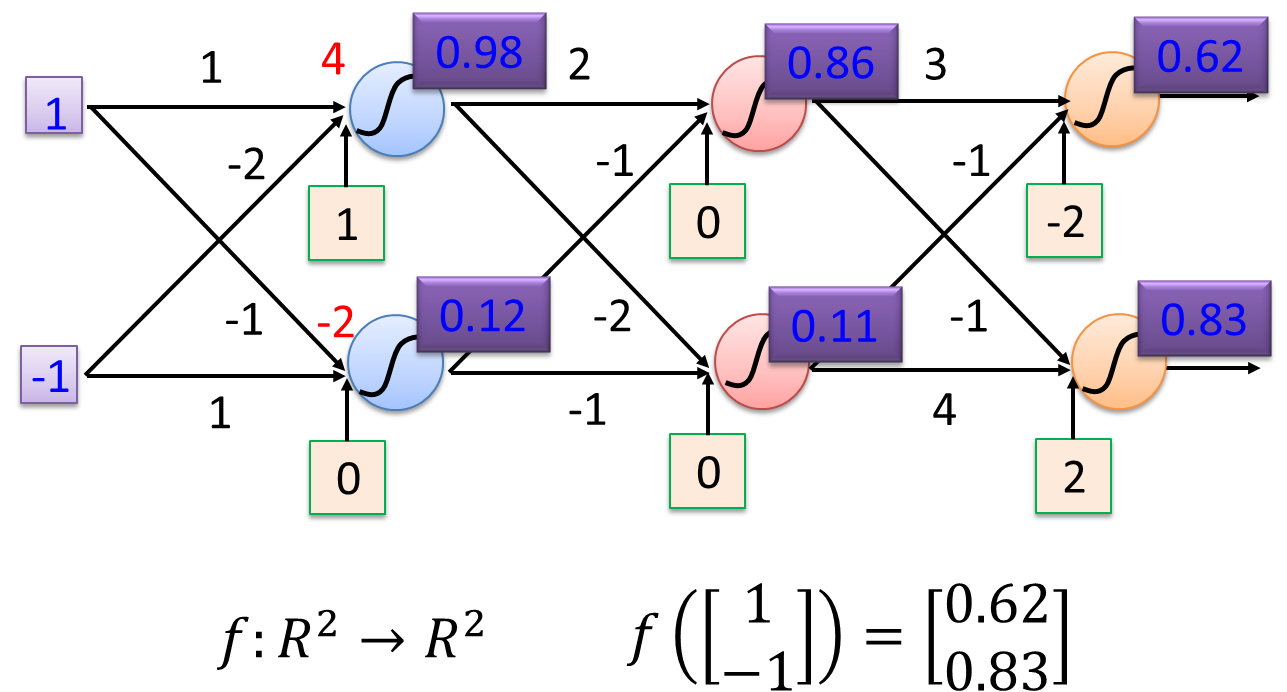
一个简单的例子
假设现在有两个输入值
输入值为: x 1 = 1 , x 2 = − 1 输入值为: x_1=1, \quad\quad x_2=-1 输入值为:x1=1,x2=−1
对应的权重为:
w 11 = 1 , w 12 = − 1 , w 21 = − 1 , w 22 = 1 w_{11}=1, \quad\quad w_{12}=-1, \quad\quad w_{21}=-1, \quad\quad w_{22}=1 w11=1,w12=−1,w21=−1,w22=1
偏置为:
b 1 = 1 , b 2 = 0 b_1=1, \quad\quad b_2=0 b1=1,b2=0
那么 x 1 x_1 x1的线性组合为
z 1 = w 11 ∗ x 1 + w 21 ∗ x 2 + b 1 = ( 1 ∗ 1 ) + ( − 1 ) ∗ ( − 2 ) + 1 = 4 z_1 = w_{11}*x_1 + w_{21}*x_2 +b_1 = (1*1) + (-1)*(-2) + 1 = 4 z1=w11∗x1+w21∗x2+b1=(1∗1)+(−1)∗(−2)+1=4
z 2 = w 12 ∗ x 1 + w 22 ∗ x 2 + b 2 = 1 ∗ ( − 1 ) + ( − 1 ) ∗ 1 + 0 = − 2 z_2 = w_{12}*x_1 + w_{22}*x_2 +b_2 = 1*(-1) + (-1)*1 + 0 = -2 z2=w12∗x1+w22∗x2+b2=1∗(−1)+(−1)∗1+0=−2
再假设对于线性组合 z z z添加一个非线性函数 σ \sigma σ,非线性函数为sigmodif 函数: σ ( z ) = 1 / ( 1 + e − z ) \sigma(z) = 1/(1+ e^{-z}) σ(z)=1/(1+e−z)
所以最终输出结果为
\\sigma(z_1) = 1/(1+ e\^{-z_1}) = 0.98, \\quad\\quad \\sigma(z_2) = 1/(1+ e\^{-z_2}) = 0.12
sigmoid 可以通过简单的python函数来验证
python
def sigmoid(x)
sigma = 1/(1+np.exp(-1*x))
return sigma
如果包含多个隐藏层呢?可以通过矩阵的形式来表示以上输入输出。
输入向量 1 − 1 T , 输出为 0.62 0.83 T \text{输入向量}1\\quad-1^T,\text{输出为}0.62\\quad0.83^T 输入向量1−1T,输出为0.620.83T
- 处理多维输入和输出时,矩阵运算非常有用。如以下所示,关于输入值 x x x和权重 ω \omega ω以及偏置 b b b的线性组合再加上非线性函数 σ \sigma σ的表现形式,以及输出结果。
- 通过矩阵计算更加的高效,这也是计算机在实际运行时的形式

当然了,上面的表现形式是一层神经网络的矩阵表达形式,如果我们将第一层输出的结果表示为 a 1 a_1 a1,然后将第一层的输出结果作为下一层的输入向量。如下所示:
多层NN神经网络,计算第一层的输出
- 输入向量 x x x,权重矩阵 W 1 W_1 W1,偏置向量 b 1 b_1 b1,输出向量 a 1 a_1 a1
- 将 a 1 a_1 a1作为下一层的输入向量 X 1 X_1 X1

按照上面的逻辑,依次迭代,计算所有层的输出
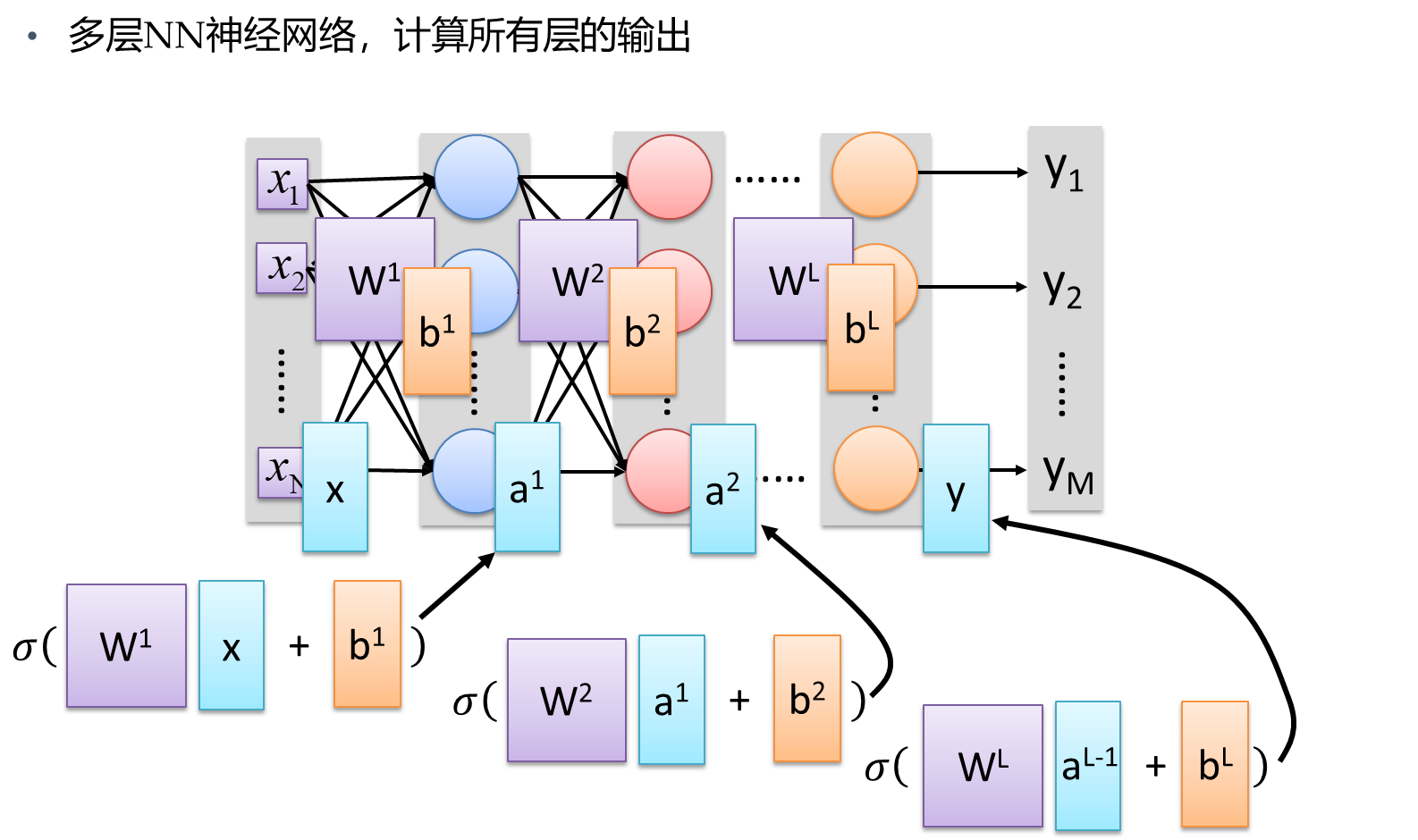
- 然后将所有层表现为函数的形式,将函数 f f f 将输入 x x x 映射到输出 y y y,即 𝑦=𝑓(𝑥)
综上所述,机器学习或者说深度学习的一个最主要的目的就是:
- 训练模型以学习一组最佳参数𝜃(根据标准)
- 神经网络的参数 包括来自所有层的权重矩阵 w w w 和偏差向量 b b b
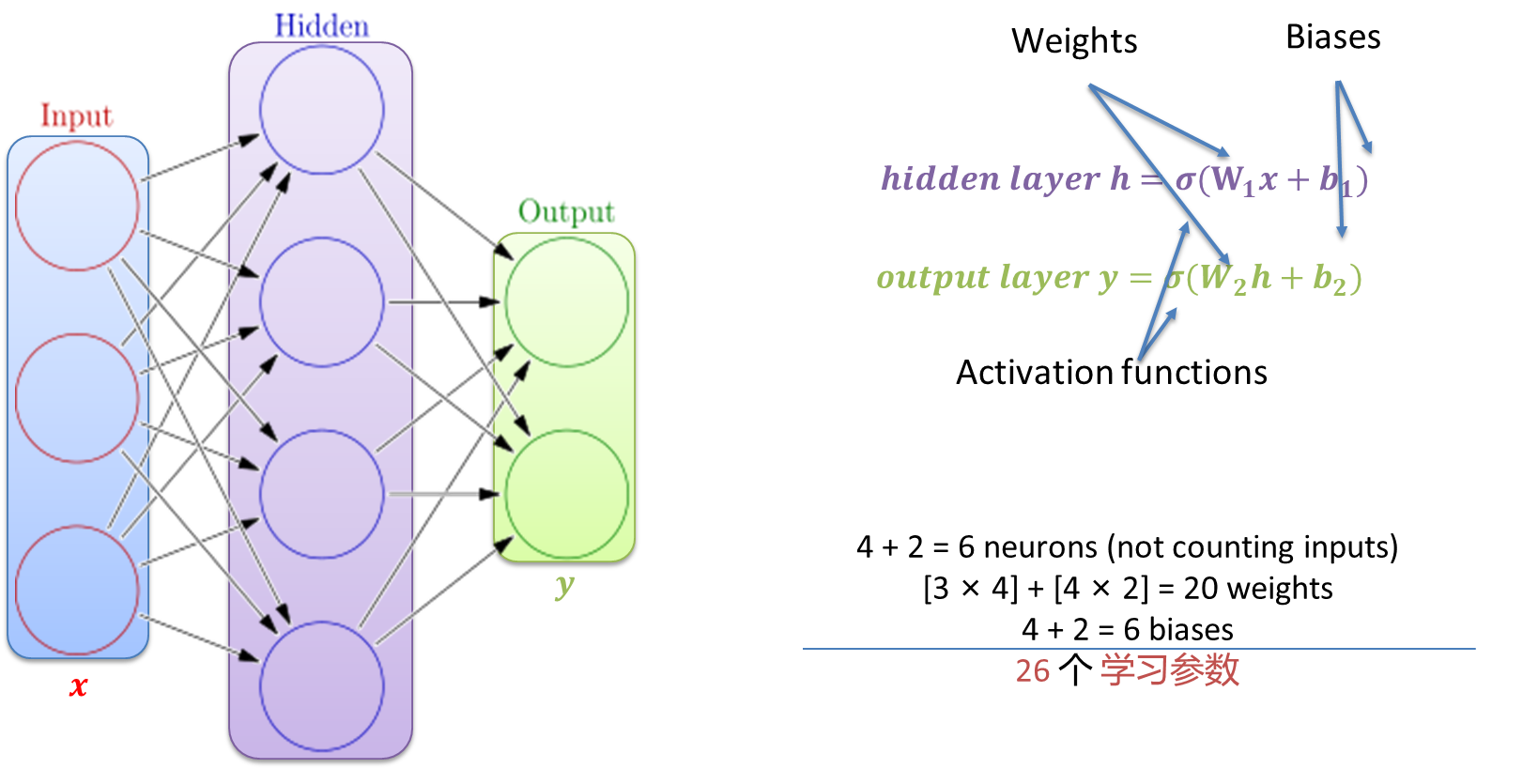
如何计算学习参数的数量呢?
- 学习参数包括:权重以及偏置,下面是一个计算示例
- 包含3 个输入层 x x x, 4 个隐藏层, 2 个 输出层
激活函数
- 激活函数我理解为将输入向量和权重、偏置进行线性组合的基础上,为了表现模型的非线性能力,添加一个非线性函数,将这个非线性函数称为激活函数,一般是在输出层之前。
下面以一个简单的激活函数示例,激活函数为sigmoid function,该函数为非线性函数,可以将输入的数组映射到 0 , 1 0,1 0,1范围内
下面是将线性组合后的三个结果 z 1 z_1 z1, z 2 z_2 z2, z 3 z_3 z3添加激活函数之后得到的结果:

其中,sigmoid激活函数的分布形式为:

当然, sigmoid在分类任务中一般适用于二分类任务;那么,对于多分类分类任务,我们一般会使用softmax激活函数,其计算方式也非常简单。
- 假设有三个输入 z 1 z_1 z1, z 2 z_2 z2, z 3 z_3 z3,添加激活函数后得到三个结果,然后将每个激活单元除以三个激活单元之和,得到每个激活单元的占比,这样就可以得到多分类的一个占比,然后可以自己进行相应的分类。

为什么要存在激活函数?
-
需要非线性激活来学习复杂(非线性)数据表示
- 否则,神经网络将只是一个线性函数(例如 W_1 W_2 𝑥=𝑊𝑥 )
- 具有大量层(和神经元)的神经网络可以近似更复杂的函数
- 更多的神经元改善了表征(但是,可能会过度拟合)

当然,还有其他的激活函数,如下所示:
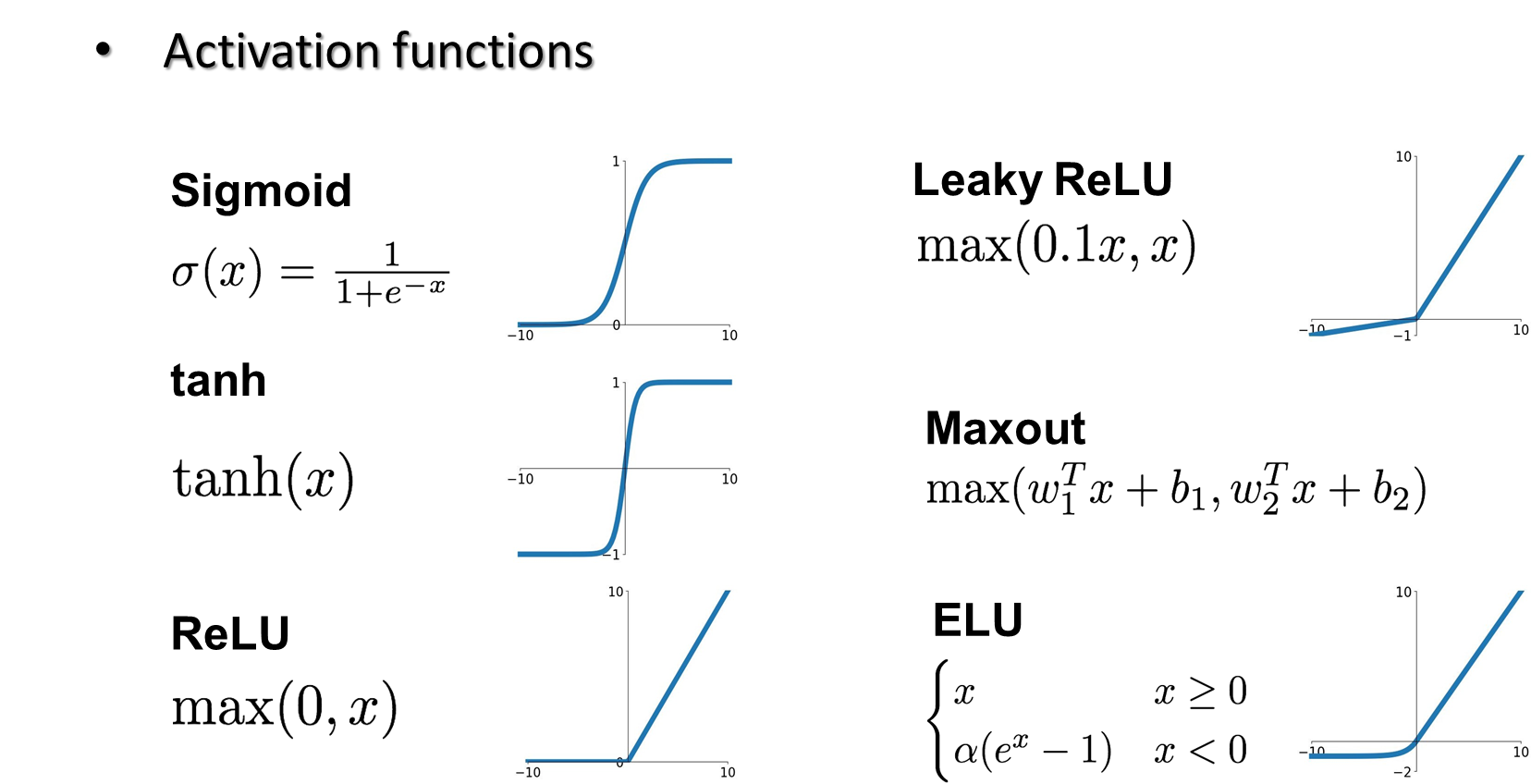
其中,一般使用比较多的是ReLU,该函数有以下优点(来自gpt):
-
ReLU是一个非线性的激活函数,能够在神经网络中引入非线性映射,从而使网络能够学习和表示更加复杂的函数关系。 -
相对于其他常用的激活函数(如
sigmoid和tanh),ReLU具有稀疏激活性,即当输入为负数时输出为零,这意味着在训练过程中,部分神经元会变得不活跃,从而降低了参数的相关性,有助于减少过拟合 -
ReLU的计算非常简单,只需要判断输入是否大于零并输出相应的值,因此在前向传播和反向传播过程中的计算开销较小,尤其在深度神经网络中,这种计算效率的提高非常重要。 -
在深度神经网络中,使用
sigmoid或tanh等激活函数容易导致梯度消失或梯度爆炸问题,而ReLU的导数在正区间恒为1,可以一定程度上缓解梯度消失问题,有助于更有效地进行梯度传播 -
ReLU在正区间的梯度恒为1,这使得在反向传播过程中梯度可以稳定地传播,不会出现梯度爆炸或梯度消失的情况,从而有助于更好地训练深度神经网络
下面我简单使用python演示了一个逻辑回归二分类任务
-
找到红蓝点的分界线 | 通过逻辑回归
- 定义逻辑回归的假设函数:
sigmoid(z) - 定义梯度下降函数来更新参数
- 使用梯度下降训练参数
- 绘制估计参数等高线图
- 定义逻辑回归的假设函数:
-
随机设置一些散点,然后根据横纵坐标之和对于散点进行二分类


- 下面还有一个二项式回归结果

给出线性回归演示的python代码
python
import os
import xarray as xr
import glob
import numpy as np
import cartopy.feature as cfeature
from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter
import cmaps
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import matplotlib.ticker as mticker
import datetime
# Get current date
current_date = datetime.datetime.now().strftime("%Y-%m-%d")
# Get current file name
current_filename = os.path.basename(__file__)
# Your code continues here
# ================================================================================================
# Author: %(Jianpu)s | Affiliation: Hohai
# Email : %(email)s
# Last modified: Created on %(current_date)s
# Filename: %(current_filename)s
# Description:
# =================================================================================================
# 生成随机数据
np.random.seed(0)
x1 = np.random.randn(100)
x2 = np.random.randn(100)
X = np.c_[np.ones(x1.shape[0]), x1, x2]
y = (x1 + x2 >= 0).astype(int)
plt.figure(dpi=200)
plt.scatter(x1,x2)
# 定义Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义梯度下降函数
def gradient_descent(X, y, theta, learning_rate, num_iterations):
m = len(y)
cost_history = [] # 用于存储每次迭代的损失
for i in range(num_iterations):
z = np.dot(X, theta)
h = sigmoid(z)
cost = (-1 / m) * np.sum(y * np.log(h) + (1 - y) * np.log(1 - h))
cost_history.append(cost)
gradient = np.dot(X.T, (h - y)) / m
theta -= learning_rate * gradient
return theta, cost_history
# 可视化数据
index_pos = np.where(x1 + x2 >= 0)
index_neg = np.where(x1 + x2 < 0)
x1_pos = x1[index_pos]
x2_pos = x2[index_pos]
x1_neg = x1[index_neg]
x2_neg = x2[index_neg]
plt.figure(dpi=200)
plt.scatter(x1_pos, x2_pos, color='r', label="x1 + x2 >= 0")
plt.scatter(x1_neg, x2_neg, color='b', label="x1 + x2 < 0")
plt.xlabel('x1')
plt.ylabel('x2')
plt.xlim([-3, 3])
plt.ylim([-3, 3])
plt.legend()
plt.grid()
plt.show()
# 定义Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义梯度下降函数
def gradient_descent(X, y, theta, learning_rate, num_iterations):
m = len(y)
cost_history = [] # 用于存储每次迭代的损失
for i in range(num_iterations):
z = np.dot(X, theta)
h = sigmoid(z)
cost = (-1 / m) * np.sum(y * np.log(h) + (1 - y) * np.log(1 - h))
cost_history.append(cost)
gradient = np.dot(X.T, (h - y)) / m
theta -= learning_rate * gradient
return theta, cost_history
# 初始化参数
theta = np.zeros(X.shape[1])
# 设置学习率和迭代次数
learning_rate = 0.01
num_iterations = 8000
# 使用梯度下降进行训练
theta, cost_history = gradient_descent(X, y, theta, learning_rate, num_iterations)
plt.figure(dpi=200)
# 绘制损失函数下降曲线
plt.plot(cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function Decrease Over Time')
plt.grid()
plt.show()
# 绘制等高线图
x1_vals = np.linspace(-3, 3, 100)
x2_vals = np.linspace(-3, 3, 100)
X1, X2 = np.meshgrid(x1_vals, x2_vals)
Z = sigmoid(theta[0] + theta[1] * X1 + theta[2] * X2)
plt.figure(dpi=200)
plt.contourf(X1, X2, Z, levels=[0, 0.5, 1], colors=['blue', 'red'], alpha=0.3)
plt.scatter(x1_pos, x2_pos, color='r', label="x1 + x2 >= 0")
plt.scatter(x1_neg, x2_neg, color='b', label="x1 + x2 < 0")
plt.xlabel('x1')
plt.ylabel('x2')
plt.xlim([-3, 3])
plt.ylim([-3, 3])
plt.legend()
plt.grid()
plt.show()上面介绍了前向传播Forward Propagation和激活函数:
-
前向传播
- 通过网络计算输出,并计算损失函数的值
后向传播
-
计算损失的梯度(Loss Gradient)
- 对损失函数的输出相对于模型参数(权重和偏置)求导,得到梯度
-
反向传播梯度(Backward Propagation of Gradients)
- 使用链式法则,将梯度从输出层向输入层反向传播,逐层计算每个参数的梯度。
-
更新参数(Update Parameters)
- 使用优化算法按照学习率(如梯度下降)更新参数
-
后向传播可以帮助我们更好的理解每一个权重是如何影响损失函数的结果 L o s s Loss Loss
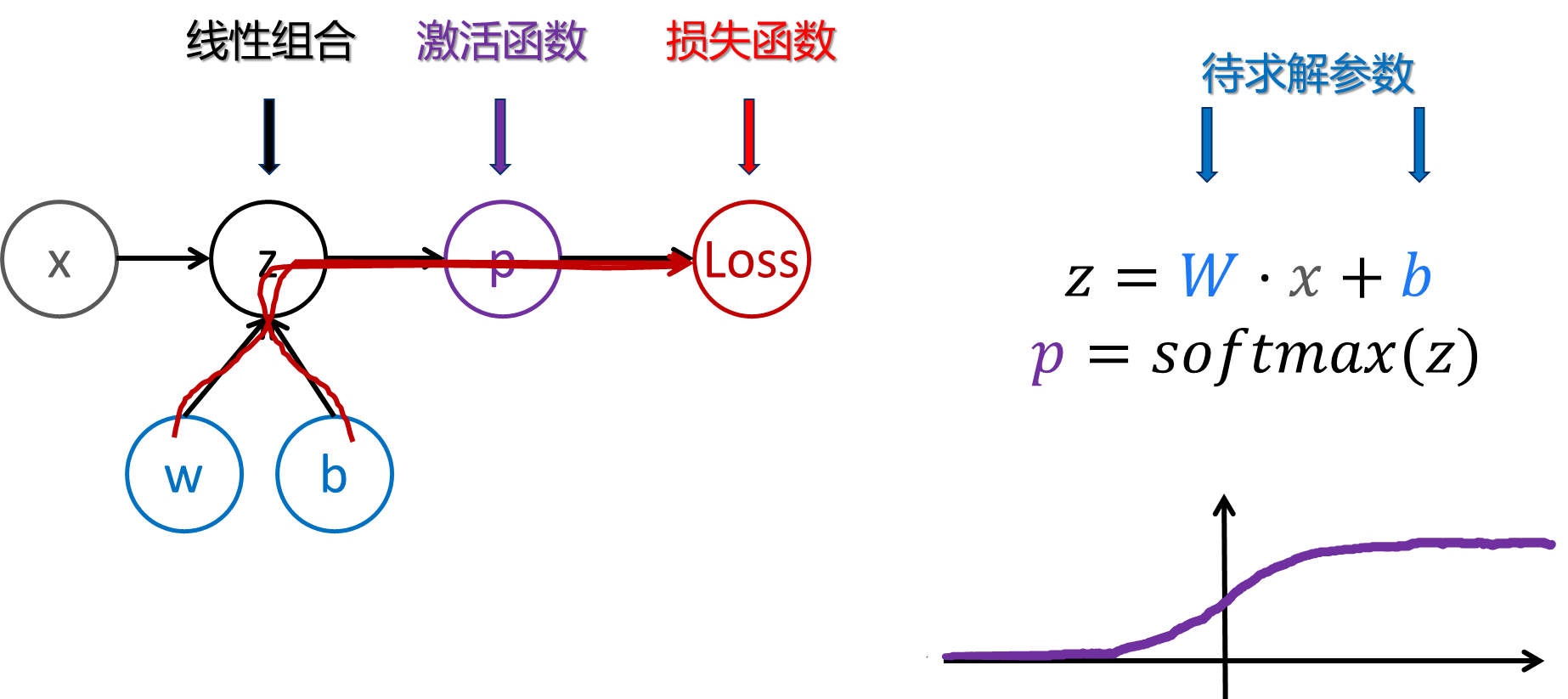
那么,如何看影响参数对于 L o s s Loss Loss的影响呢?
- 其实很简单,和之前回归分析中求解回归系数一个道理,
Loss实际是关于输入x,权重 ω \omega ω,偏置b的线性组合,加上激活函数和损失函数得到Loss结果,那么只需要将Loss对于参数和偏置分布进行求偏导即可。

上面是一层的计算方式,理解清楚的话其实多层神经网络的计算方式同理

下面我将在黑板上举例来演示一个具体的计算过程。
当然,在计算机实际计算时,不需要计算每一个偏导的结果,只需要向后传播梯度即可,这样可以加快计算效率

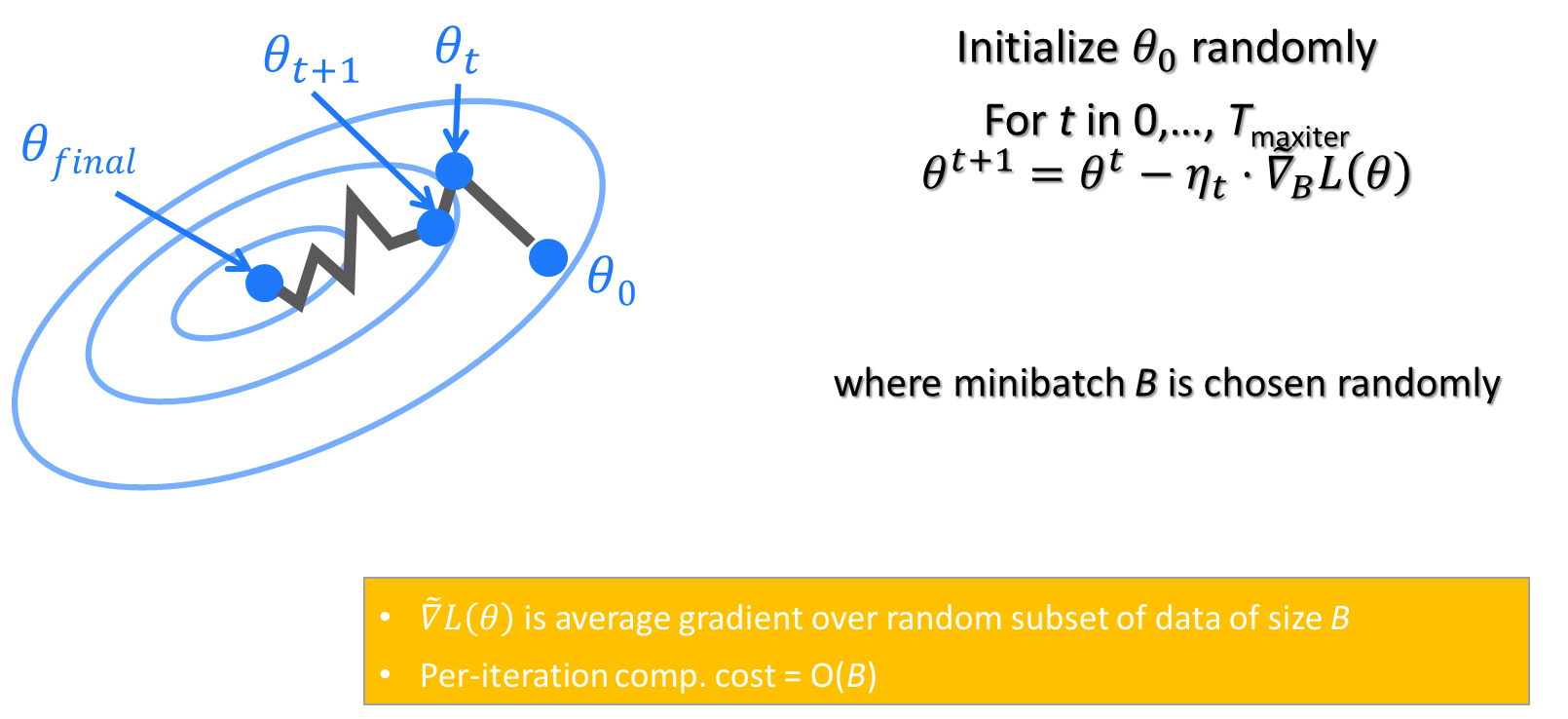
梯度下降
在计算 L o s s Loss Loss过程后,我们需要
根据输入数据x,通过前向传播求解神经网络模型的计算结果 y ^ \hat {y} y^,将模型的结果 y ^ \hat {y} y^与真实结果 Y Y Y 进行对比 ∣ y ^ − Y ∣ |\hat {y} - Y| ∣y^−Y∣,计算差距即损失 L o s s Loss Loss。为了调整参数使得两者的损失 L o s s Loss Loss变小,直至满足我们设置的最小误差精度。
那么,如何来调整参数,使得Loss变小呢?
- 即通过梯度下降法,进行迭代计算
梯度下降算法的步骤:
-
- 随机初始模型参数
-
- 计算初始参数的损失函数的梯度 θ 0 : ∇ L ( θ 0 ) \boldsymbol{\theta}^0{:}\nabla\mathcal{L}(\theta^0) θ0:∇L(θ0)
-
- 更新参数: θ n e w = θ 0 − α ∇ L ( θ 0 ) \theta^{new}=\theta^0-\alpha\nabla\mathcal{L}(\theta^0) θnew=θ0−α∇L(θ0)
- α α α 为学习率
-
- 转到步骤 2 并重复(直到达到终止标准)
梯度下降的过程就像是站在山坡上的一个人,想要找到山底最低点的位置。这个人通过观察当前位置的斜率(即梯度),然后朝着斜率下降最陡的方向移动一步。重复这个过程,直到找到山底,也就是损失函数的最小值

- 根据随机的初始模型参数,最终找到使损失达到最小的模型参数

当然,这个方法也存在一些缺点
-
当达到损失表面的局部最小值时,梯度下降算法停止
- GD 不保证达到全局最低值

除了局部极小值问题之外,GD 算法在平台期可能会非常慢,并且可能会卡在鞍点处
学习率
-
梯度告诉我们损失增长最快的方向,但它并没有告诉我们应该沿着相反的方向走多远
-
选择学习率(也称为步长)是神经网络训练最重要的超参数设置之一
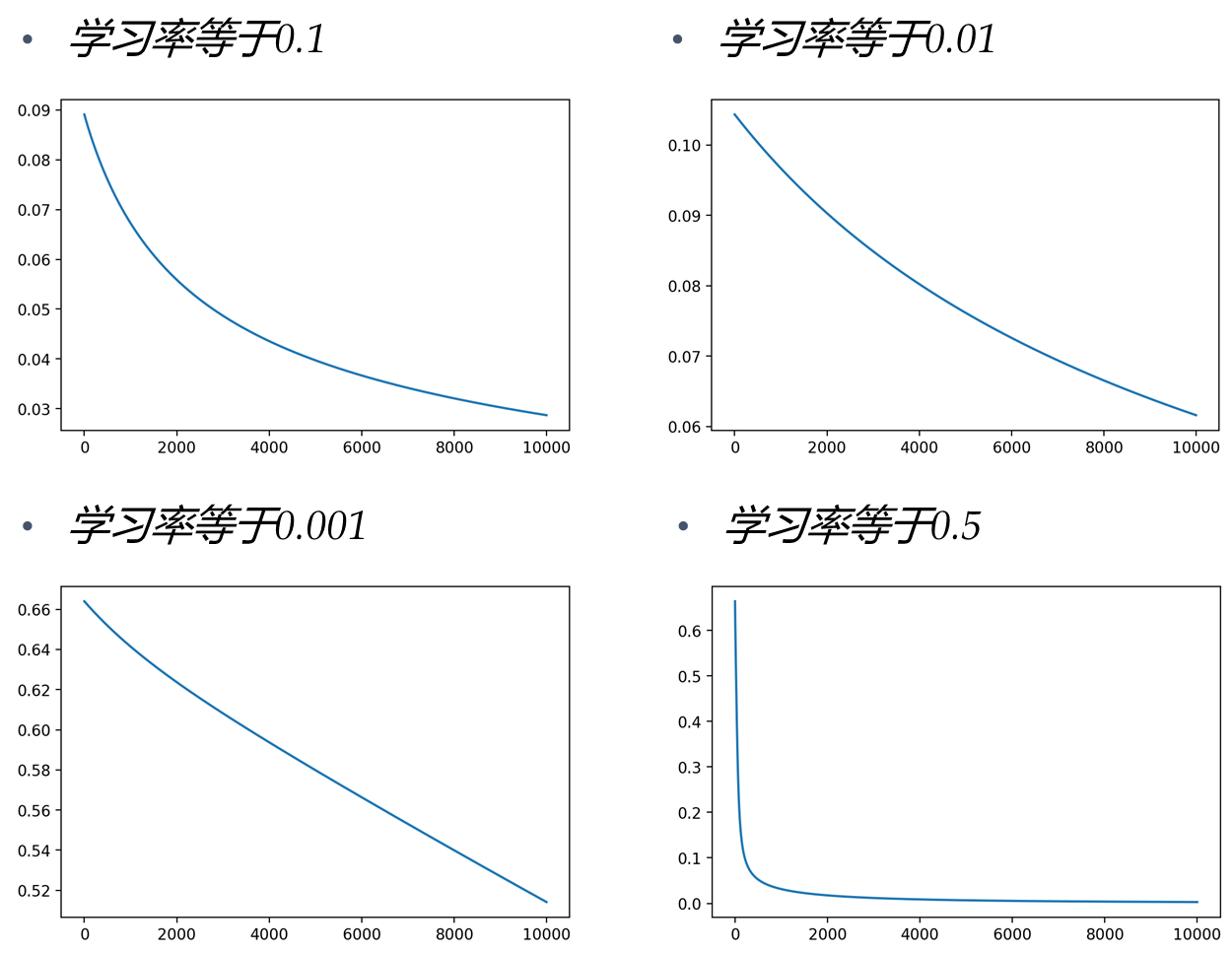
选择合适的学习率对于我们的模型训练效果是显著的,当然,不当的学习率对于模型的计算也会有较大影响,下面是学习率过小或者过大的情况:

对于同一个训练任务,通过改变学习率,对于训练损失会产生较大的影响,下面也是一个自己编写的简单结果。
当然,这里建议一般使用小批量梯度下降,即分batch进行梯度下降
- 避免数据量过大,分批次传入
- 更快的收敛速度、内存效率、更好的泛化能力
下面是不同的batch对于模型收敛速度的影响
- 理论上来看,在内存不爆掉的情况下,尽可能地多batch的传入

通过控制其他超参数不变,只改变batch的大小
- 下面是不同
batch对于损失曲线的影响
可以发现,当batch=1024时,loss曲线更收敛

一般可以通过loss曲线来判断模型的模拟性能
如下面这张图:
- 训练数据的曲线最终收敛,但是在验证数据上到后面飞起来了
- 这说明模型的泛化能力较弱,出现过拟合情况可能

下面这个图片展示了不同学习率对于训练损失曲线的影响,也可以根据损失曲线反过来评估设置的学习率是否合理
-
高学习率:损失增加或稳定得太快
-
学习率低:损失下降太慢(需要很多轮才能达到解决方案)

卷积
- 通过卷积层来实现特征提取以及尺寸裁剪
假如输入数据是一个5x5的二维矩阵,为其添加一个3x3的卷积核,以一个步长进行卷积
- 卷积的实现就是卷积核以一定的步长在原始输入矩阵上的点对应相乘再求和
最终得到一个3x3的特征图矩阵,这就实现了卷积的过程,可以发现在步长为1时,特征图的尺寸大小和卷积核的大小是相同的
反卷积
- 前面说卷积可以用来减小图片的尺寸,那么如何将图片尺寸放大呢?
这里将在黑板上给大家演示
假如现在有一个2x2的原始矩阵,给他一个3x3的卷积核,将原始矩阵上的每一个点和卷积核上点相乘,这样就能得到4个3x3的特征矩阵,如果按照步长为3这个四个特征矩阵进行拼接,这样就得到了6x6的矩阵。这样就实现了反卷积的过程,类似于 UNet 模型就使用这种方法。
池化
池化层可以缩小卷积特征的空间尺度,降低计算资源,去除噪声。包括
- 最大池化
- 平均池化
如下显示的是最大池化,假设原始矩阵为4x4,给定一个2x2的池化层,以步长为2进行滑动。将每一个池化层覆盖的原始矩阵中的最大值提取出来作为原始4x4矩阵里面的最显著特征,于是就得到了一个2x2的蕴含局部区域显著信号的输出矩阵。
- 描述起来可能有点绕开,看下面的示意图就可以更清楚的了解
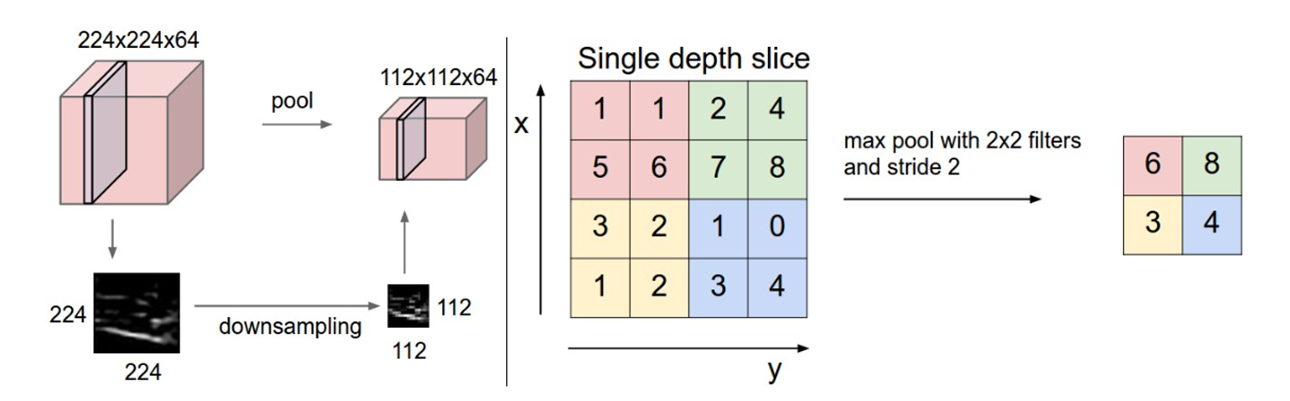
- 平均池化就是每一个2x2小区域的求和再求平均,也很好理解
以卷积层和池化层可以搭建一个简单的卷积神经网络,存在以下优点
- 局部连接、权值共享、层级结构

深度学习的流程
一般分为回归 任务和分类任务
分类任务常用的损失函数为:Cross-entropy ; 输出层的激活函数为:softmax

回归任务常用的损失函数为:MSE或MAE ; 输出层的激活函数为:Linear (Identity) or Sigmoid Activation

简单画了一个完整的深度学习任务流程:
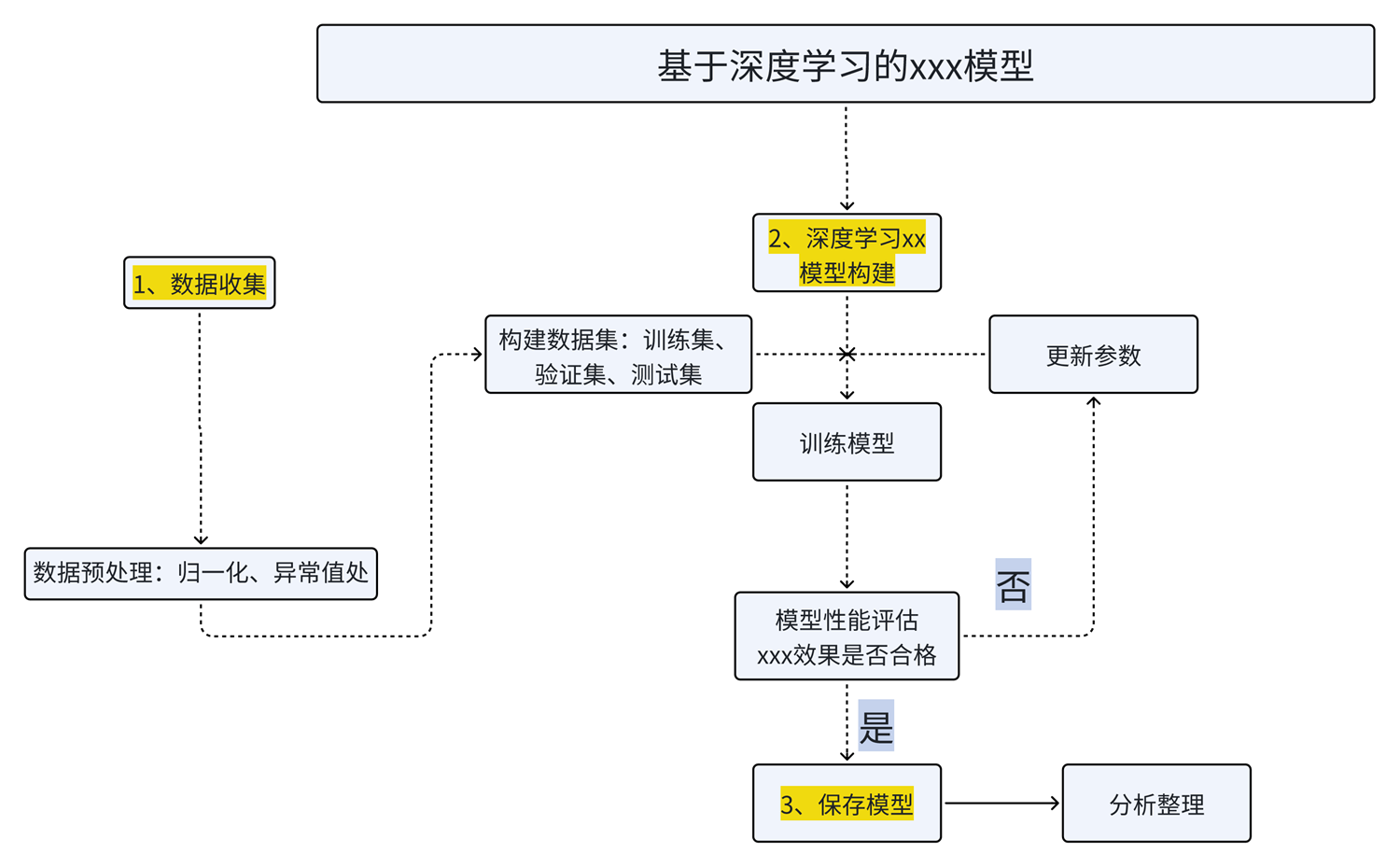
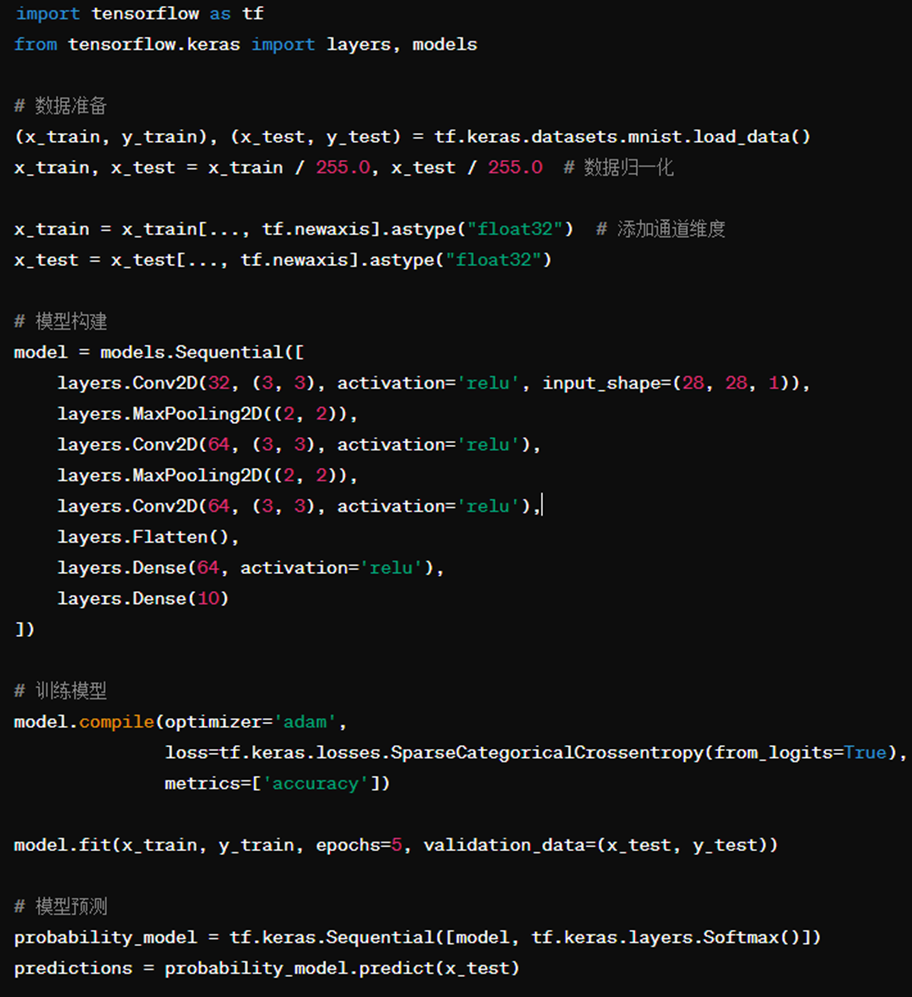
随便让gpt写了一个训练流程,还是挺完整的:
-
数据准备:加载MNIST手写数字数据集并进行预处理,包括归一化和添加通道维度。
-
模型构建:构建一个包含卷积层、池化层和全连接层的CNN模型。
-
训练模型:使用Adam优化器和交叉熵损失函数对模型进行训练。
-
模型预测:使用训练好的模型对测试数据进行预测,并使用Softmax函数将输出转换为概率分布。
数据预处理
-
Mean subtraction, 获得以0为中心的正太分布
-
Normalization, 标准化
- 将每个特征除以其标准差
- 放缩数据到0,1 或 -1,1
标准化的目的是,对于输入的数据以及标签之前的量级可能不一致,不一致影响模型的收敛速度;为了使其量级一致,提高计算效率。
过拟合 | 欠拟合
Underfitting
- 该模型过于"简单",无法表示所有相关的类别特征
- 例如,参数太少的模型
- 在训练集上产生高误差,在验证集上产生高误差
Overfitting
- 模型过于"复杂"并且拟合了数据中不相关的特征(噪声)
- 例如,参数过多的模型
- 在训练误差上产生低误差,在验证集上产生高误差


- 该模型可能非常适合训练数据,但无法推广到新的示例(测试或验证数据)
解决过拟合方法
- 早停

- Dropout - 在训练过程随机丢弃一些单元

-
减少参数量 - 参数共享(convnets, recurrent neural nets)
-
正则化 - 惩罚模型的权重参数,以限制它们的大小,从而降低模型的复杂度 ∑ j = 1 d W j 2 \sum_{j=1}^dW_j^2 ∑j=1dWj2
-
batch normalization
深度学习的框架
-
Pytorch
-
tensorflow
-
caffe2
...

示例
下面举一个运行CNN进行ENSO预报的经典文章
- 基于深度学习CNN结构的预报技巧显示:采用深度学习方法产生的 ENSO 预报技巧的提前时间长达一年半。


总结
通过本次介绍,需要了解一些知识点
-
深度|机器学习任务目标:什么是输入?什么是标签 | 输出?
-
深度学习模型是什么? - 输入数据映射到一些数字
-
什么是损失函数? - 衡量一个模型的效果
-
如何训练一个模型? - 基于经验损失总和的小批量 SGD
-
验证 - 训练的模型是否过拟合
终于,把非线性回归和神经网络的内容都整理完了。画了一周半时间来推导公式和做PPT,密密麻麻推导过程也记了十几页纸。上台前以为自己已经推的很清楚了,到了实际上台讲解的时候发现还是紧张的冒汗。。。果然看懂了和讲清楚之间还是有一段路要走。翻转课堂整一次还是太累了,不过在实际推导公式、听其他同学讲解以及老师补充的过程对于相关知识点也把握更清楚。anyway,总算是给他讲完了,连上三节课可真不容易。马上躺平ing...
深度学习的数学 作者:日涌井良幸、涌井贞美 译者:杨瑞龙 https://www.ituring.com.cn/book/2593
Ham, YG., Kim, JH. & Luo, JJ. Deep learning for multi-year ENSO forecasts. Nature 573, 568--572 (2019). https://doi.org/10.1038/s41586-019-1559-7
部分材料来自网络搜集和个人整理