探索Lora:微调大型语言模型和扩散模型的低秩适配方法
随着深度学习技术的快速发展,大型语言模型(LLMs)和扩散模型(Diffusion Models)在自然语言处理和计算机视觉领域取得了显著的成果。然而,这些模型的规模和复杂性使得它们的微调过程既耗时又费力。Lora(Low-Rank Adaptation)作为一种创新的方法,能够高效地对这些大模型进行微调。本文将详细介绍Lora的背景、原理、公式、代码实现及其效果。
背景
在深度学习中,大型模型通常需要大量的数据和计算资源进行训练。然而,在实际应用中,我们常常需要针对特定任务对预训练的大模型进行微调。传统的微调方法需要更新所有模型参数,耗费大量的计算资源和存储空间。
Lora方法通过低秩适配(Low-Rank Adaptation)实现高效微调,仅需更新少量参数,从而大大降低了计算资源和存储需求。这使得Lora成为对大型模型进行微调的一种极具吸引力的方法。
原理

Lora可以说是解决这样两个问题:模型需要全部参数微调吗?模型微调程度的衡量标准是什么?在图中,左小角就是原始模型,右上角就是模型全参数微调,而矩形面积中的点就是各种Lora。
Lora的核心思想是利用低秩矩阵分解来近似模型参数的变化。在微调过程中,Lora不直接更新模型的原始权重矩阵,而是通过添加一个低秩矩阵来调整模型。
具体来说,假设我们有一个预训练的权重矩阵 ( W ),在微调过程中,我们引入两个低秩矩阵 ( A ) 和 ( B ),使得新的权重矩阵 ( W' ) 表示为:
W' = W + \\Delta W
其中, ( \Delta W = A B^T ) 。这里, ( A ) 和 ( B ) 是低秩矩阵,其秩远小于 ( W ) 的秩。这意味着我们只需要更新 ( A ) 和 ( B ) ,而不是整个 ( W ) 矩阵,从而大大减少了需要更新的参数数量。
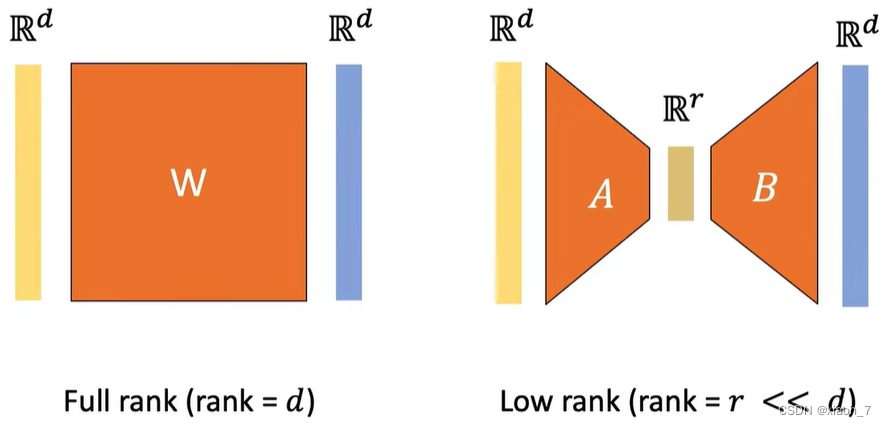
如图,如果完全微调整个模型的话,参数量就是d^2,而改用Lora,参数量就是2rd,而r是远远小于d的。
公式
假设原始权重矩阵 ( W ) 的尺寸为 ( d \times k ),我们引入两个低秩矩阵 ( A ) 和 ( B ) ,其中 ( A ) 的尺寸为 ( d \times r ) ,( B ) 的尺寸为 ( k \times r ) ,且 ( r \ll \min(d, k) )。则新的权重矩阵 ( W' ) 表示为:
W' = W + A B\^T
在训练过程中,我们只需要优化 ( A ) 和 ( B ) ,而保持 ( W ) 不变。这样,通过调整较少的参数,便可以实现对大模型的有效微调。
代码实现
下面是一个简单的示例代码,演示如何在PyTorch中实现Lora方法对一个预训练模型进行微调:
python
import torch
import torch.nn as nn
import torch.optim as optim
class LoraLayer(nn.Module):
def __init__(self, original_layer, rank):
super(LoraLayer, self).__init__()
self.original_layer = original_layer
self.rank = rank
self.A = nn.Parameter(torch.randn(original_layer.weight.size(0), rank))
self.B = nn.Parameter(torch.randn(original_layer.weight.size(1), rank))
def forward(self, x):
delta_W = torch.mm(self.A, self.B.t())
return self.original_layer(x) + torch.mm(x, delta_W.t())
# 假设我们有一个预训练的线性层
original_layer = nn.Linear(768, 768)
lora_layer = LoraLayer(original_layer, rank=4)
# 优化器只更新A和B矩阵
optimizer = optim.Adam([lora_layer.A, lora_layer.B], lr=1e-3)
# 示例训练过程
def train_step(input, target):
optimizer.zero_grad()
output = lora_layer(input)
loss = nn.MSELoss()(output, target)
loss.backward()
optimizer.step()
return loss.item()
# 示例输入和目标
input = torch.randn(32, 768)
target = torch.randn(32, 768)
# 训练一个步骤
loss = train_step(input, target)
print(f'Training loss: {loss}')效果
Lora方法通过引入低秩矩阵分解,有效地减少了模型微调过程中需要更新的参数数量。研究表明,在许多任务中,Lora能够在保持模型性能的同时,显著减少计算和存储开销。
具体效果上,在自然语言处理任务(如机器翻译、文本生成)和计算机视觉任务(如图像分类、目标检测)中,Lora均表现出优异的性能。与传统微调方法相比,Lora的参数更新量减少了数个数量级,但依然能够达到甚至超过原始模型的性能。
总结
Lora是一种创新且高效的微调大型模型的方法。通过低秩矩阵分解,Lora能够在保持模型性能的同时,显著减少计算资源和存储需求。本文介绍了Lora的背景、原理、公式、代码实现及其效果,希望能帮助你更好地理解和掌握这一方法。随着大型模型在各个领域的广泛应用,Lora的出现为我们提供了一种高效、实用的微调解决方案。
版权声明
本博客内容仅供学习交流,转载请注明出处。