背景
随着互联网服务的广泛普及与技术应用的深入发展,日志数据作为记录系统活动、用户行为和业务操作的宝贵资源,其价值愈发凸显。然而,当前海量日志数据的产生速度已经远远超出了传统数据分析工具的处理能力,这不仅要求我们具备高效的数据收集和存储机制,更呼唤着强大、灵活且易用的数据分析平台的诞生。在此背景下,Apache Spark,这一专为大规模数据处理而设计的计算引擎,成为了构建高性能日志分析应用的理想选择。阿里云 EMR Serverless Spark 版是一款全托管、一站式的数据处理平台,基于Spark Native Engine构建,专为大规模数据处理和分析设计,提供弹性、高效的服务,让用户无需关注基础设施管理,100%兼容Spark,简化从开发到运维的全链路工作流程。本文将以 OSS 日志处理场景为例,演示使用 EMR Serverless Spark 产品快速搭建日志分析应用。
OSS-HDFS 审计日志简介
阿里云的 OSS-HDFS 服务,是专为大数据处理和云原生数据湖存储设计的产品。该服务由阿里云的JindoFS提供技术支持,旨在无缝桥接阿里云对象存储(OSS)与 HDFS 生态系统,为 Apache Hadoop、Hive、Spark、Flink 等大数据处理框架提供高性能、高兼容性的存储解决方案。在阿里云 OSS 控制台创建一个新的 OSS Bucket 时可以选择开通 HDFS 服务,创建完成后新的 OSS Bucket 即可支持 HDFS 接口访问:

HDFS审计日志(Audit Log)是Hadoop分布式文件系统(HDFS)的一个重要组成部分,它详尽地记录了所有用户对 HDFS 执行的操作信息。这些日志对于系统管理员监控、安全审计以及故障排查至关重要。每当用户通过 HDFS 的 NameNode 执行操作(如读取、写入、删除文件或目录等),NameNode 就会生成一条审计日志记录。类似于开源版 HDFS,OSS-HDFS 默认就支持 auditlog 日志,在根目录下的 /.sysinfo/auditlog 目录下保存了近一个月的审计日志,并且按照日期目录进行切分。
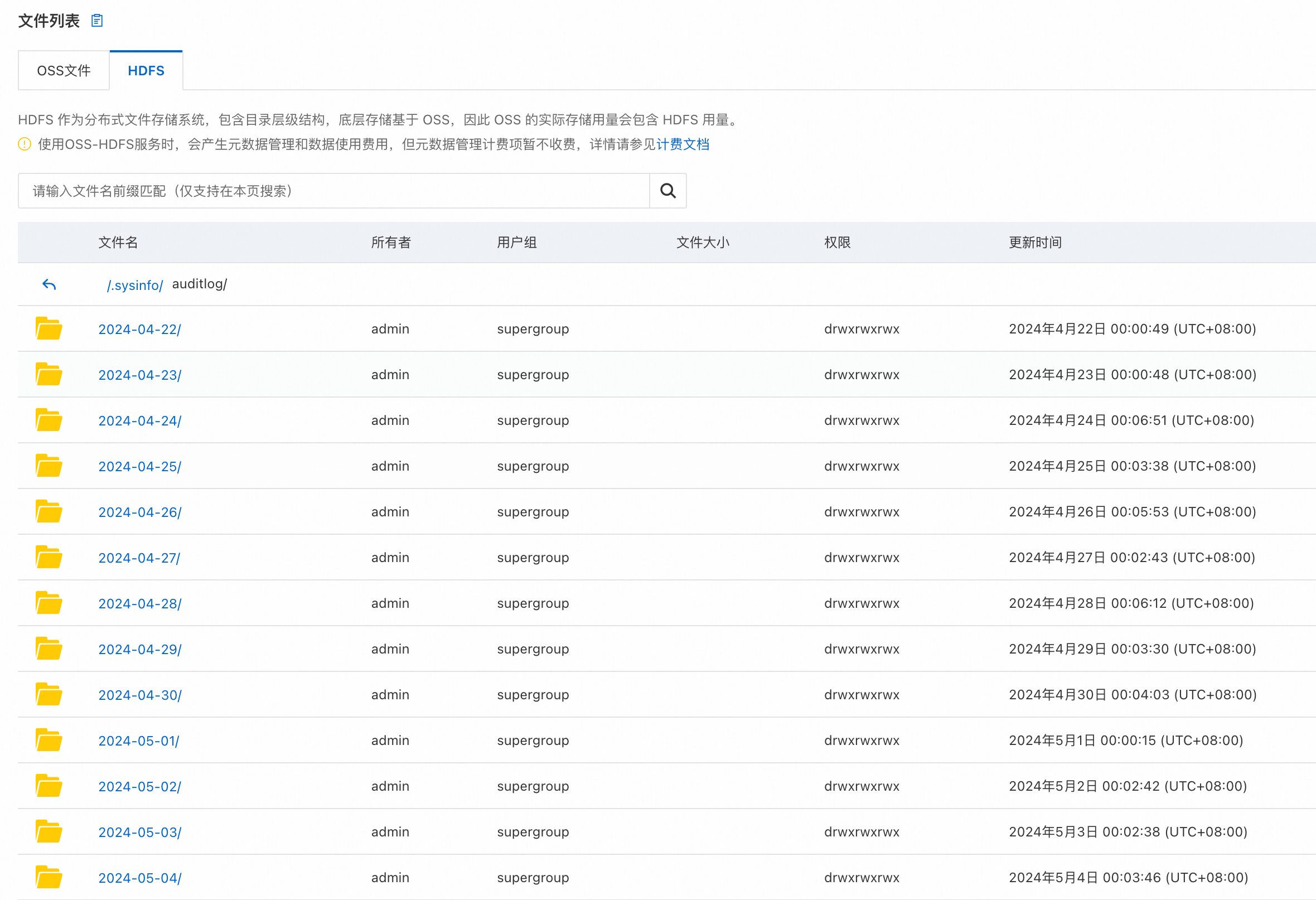
审计日志条目通常包含一些关键信息,比如操作时间、操作人、操作成功与否、来源IP、操作命令、操作目标文件等。下面三条日志分别记录了delete、getfileinfo和mkdir操作详情:
2024-05-14 00:12:37.746 allowed=true ugi=hadoop (auth:UNKNOWN) ip=172.16.0.99 cmd=delete src=/tmp/hive/hadoop/c7e1564c-7f3f-4fe9-b993-1d56e1ddcd47 dst=<null> perm=<null> proto=rest
2024-05-14 00:07:36.652 allowed=true ugi=hadoop (auth:UNKNOWN) ip=172.16.0.99 cmd=getfileinfo src=/tmp/hive/hadoop/34567e8a-a5f2-4f6b-802c-ca4db2cc1d58 dst=<null> perm=<null> proto=rest
2024-05-14 00:12:37.316 allowed=true ugi=hadoop (auth:UNKNOWN) ip=172.16.0.99 cmd=mkdirs src=/tmp/hive/hadoop/c7e1564c-7f3f-4fe9-b993-1d56e1ddcd47/_tmp_space.db dst=<null> perm=hadoop:supergroup:rwx------ proto=restEMR Serverless Spark 工作空间简介
使用 EMR Serverless Spark 产品之前,需要了解工作空间相关的概念,工作空间是 EMR Serverless Spark 为业务开发划分的基本单元,是任务、资源和权限的集合。接下去就可以参考产品的快速入门文档来体验:
-
阿里云账号角色授权:开通工作空间的前置操作
-
创建Spark工作空间:需要提前开通 OSS 和 DLF 等阿里云服务
-
SQL任务快速入门:接下去的 EMR Serverless Spark 任务开发会使用 SQL 任务
EMR Serverless Spark 任务开发
下面我们来演示如何通过EMR Serverless Spark搭建一个日志分析应用。日志分析的一个很常见的需求是分析前一天访问 OSS-HDFS Bucket 的来源IP,比如希望找到有来自某些IP的异常突发流量,或者在事后调查敏感文件是否被异常IP所访问。因为SQL是在数据分析中最常用的工具,所以使用 Spark SQL 来分析OSS-HDFS的审计日志。前面我们已经通过《SQL任务快速入门》对 SparkSQL 类的任务有了简单的了解,这部分内容会针对数据仓库源数据层、明细层、汇总层分别创建一个 SQL 任务。
源数据层
首先是日志文件的来源,我们要建立一个源数据层(ODS)的表,因为审计日志已经被归档到OSS-HDFS的系统目录里,所以我们可以通过Spark SQL建一个CSV外表:
-
表路径指向系统目录 oss://..oss-dls.aliyuncs.com/.sysinfo/auditlog/ (在操作的时候需要将 BUCKET_NAME 和 REGION_ID 替换为实际使用的 OSS Bucket 名称和所在地域)
-
日志条目中的不同字段用制表符(tab)分隔,所以指定 sep = '\t'
-
{ds} 是 Serverless Spark开发和调度平台使用的内置变量,代表业务日期(T-1)。比如在2024年5月21日运行的SQL任务,业务时间是指前一天,{ds}=2024-05-20(在这里无需手动替换 ds 值)
DROP TABLE IF EXISTS s_oss_hdfs_audit_tmp;
CREATE TABLE s_oss_hdfs_audit_tmp (
tm string,
allowed string,
ugi string,
ip string,
cmd string,
src string,
dst string,
perm string,
proto string
) USING csv
OPTIONS (
path 'oss://<BUCKET_NAME>.<REGION_ID>.oss-dls.aliyuncs.com/.sysinfo/auditlog/${ds}',
sep '\t'
);
把这个SQL文件(s_oss_hdfs_audit_tmp.sql)保存后,点击发布。
数仓明细层
其次,我们要基于这个ODS外表创建一张数据仓库明细层(DWD)表,以Parquet格式存储,并按天进行分区。我们需要对 ODS 表进行简单的清洗和转换,比如把access_time从字符串转换成timestamp类型,将字段内容 ip=172.16.0.99 转换为 IP 地址 172.16.0.99 等。这个SQL里同样使用了 ${ds} 内置变量。
CREATE TABLE IF NOT EXISTS dwd_oss_hdfs_audit_di (
access_time timestamp,
allowed string,
ugi string,
ip string,
cmd string,
src string,
dst string,
perm string,
proto string,
dt string
)
USING parquet
PARTITIONED BY (dt);
INSERT OVERWRITE TABLE dwd_oss_hdfs_audit_di partition (dt = '${ds}')
SELECT
to_timestamp(tm),
split_part(allowed, '=', 2),
split_part(ugi, '=', 2),
split_part(ip, '=', 2),
split_part(cmd, '=', 2),
split_part(src, '=', 2),
split_part(dst, '=', 2),
split_part(perm, '=', 2),
split_part(proto, '=', 2)
FROM
s_oss_hdfs_audit_tmp;把这个SQL文件(dwd_oss_hdfs_audit_di.sql)保存后,点击发布。
数仓汇总层
最后,我们对数仓明细层数据做一个简单的分析,取出前一天请求量最大的20个IP地址,我们会创建一张 DWS 汇总表:
CREATE TABLE IF NOT EXISTS dws_oss_hdfs_ip_ana (
ip string,
cnt bigint,
dt string
)
USING parquet
PARTITIONED BY (dt);
INSERT OVERWRITE TABLE dws_oss_hdfs_ip_ana partition (dt = '${ds}')
SELECT
ip,
count(*) cnt
FROM
dwd_oss_hdfs_audit_di
WHERE
dt = '${ds}'
GROUP BY ip
ORDER BY cnt DESC
LIMIT 20;把这个SQL文件(dws_oss_hdfs_ip_ana.sql)保存后,点击发布。
EMR Serverless Spark 任务编排
创建工作流
在前面的章节中,我们已经分别在数据仓库源数据层、明细层、汇总层各创建一个 SQL 任务,这些任务都处于"已发布"状态。接下去我们需要创建一个工作流把这三个SQL任务进行适当的编排,并且让工作流能在每天的固定时间进行调度。在 Serverless Spark 工作空间的导航栏中找到"任务编排"链接,点击"创建工作流"后进入新建工作流 oss_hdfs_auditlog 的配置界面。在这个界面里需要填写工作流名称和资源队列,同时可以选择调度类型是"调度器",调度周期是每天的 00:05。
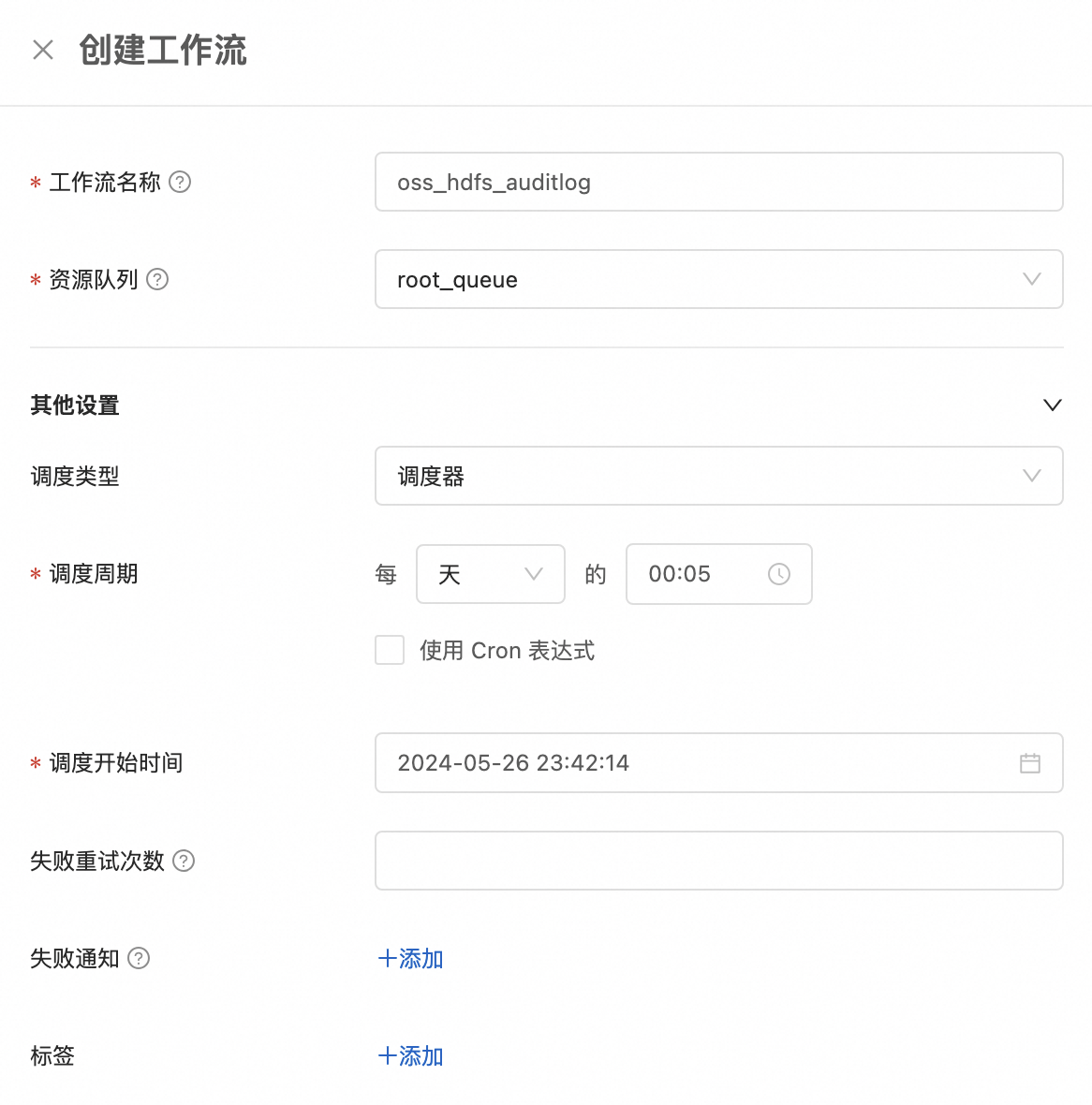
编辑节点
在编辑工作流的页面,鼠标左键双击节点,或者单击下方的添加节点,进入节点编辑页面。我们需要按顺序选择s_oss_hdfs_audit_tmp、dwd_oss_hdfs_audit_di、dws_oss_hdfs_ip_ana节点,加入到工作流中。
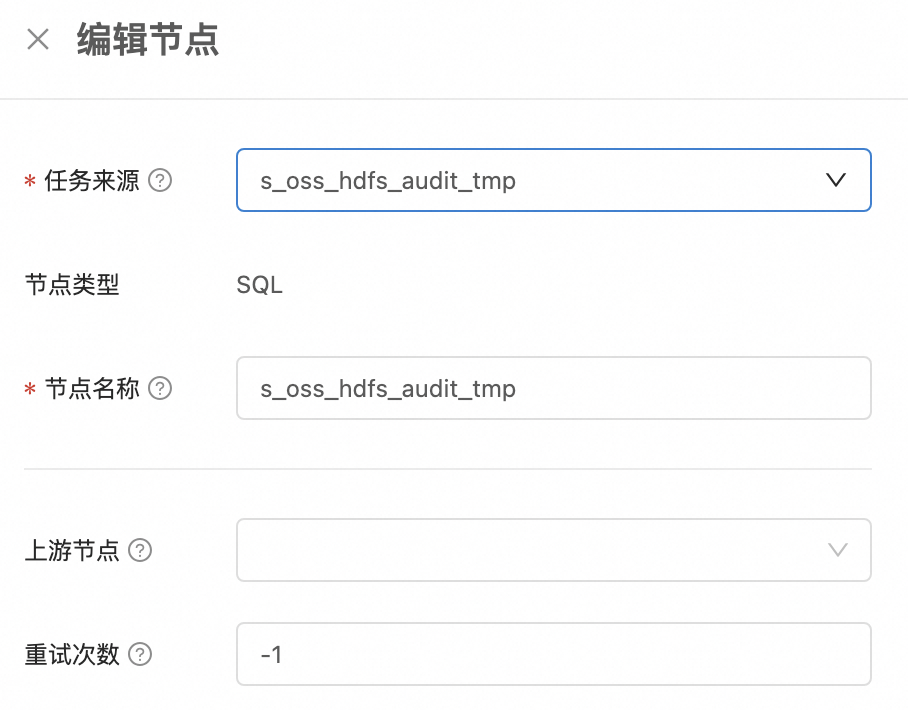
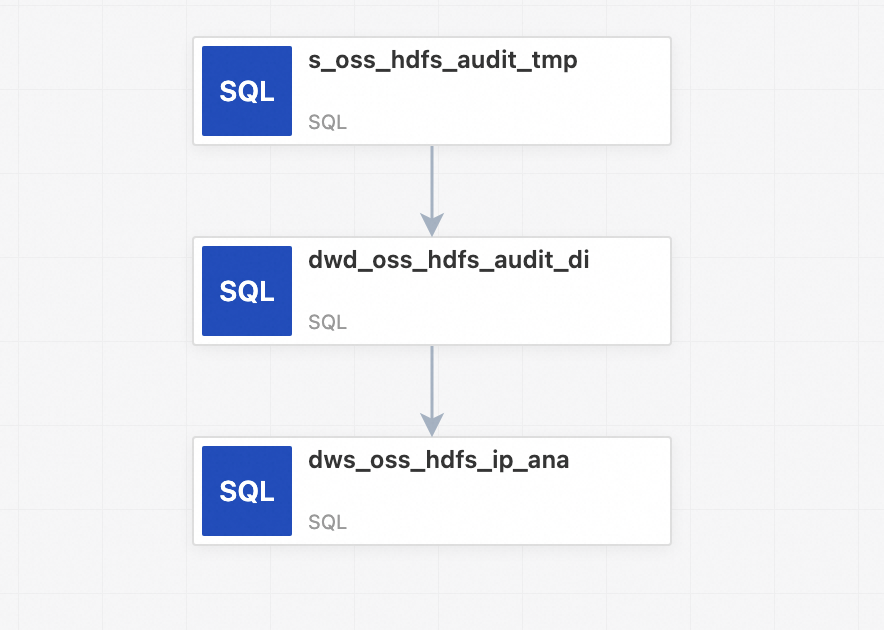
同时也需要配置节点依赖关系,比如 dwd_oss_hdfs_audit_di 节点的上游节点是 s_oss_hdfs_audit_tmp,dws_oss_hdfs_ip_ana 节点的上游节点是 dwd_oss_hdfs_audit_di。

三个节点编辑完成之后,自动生成如下 DAG,完成工作流的编辑。
发布工作流
在工作流编辑页面右上角,点击"发布工作流",在输入发布信息后点击"确认",完成工作流的发布。

发布工作流之后自动跳转回到工作流列表,我们可以看到新创建的工作流。打开"调度状态"开关,之后工作流会根据调度器的设置进行按天调度。

点击工作流名称,进入工作流调度实例列表,在这里可以看到每次调度运行的成功或失败的任务节点,也可以点击右上角的"手动运行"按钮进行一次手动调度。
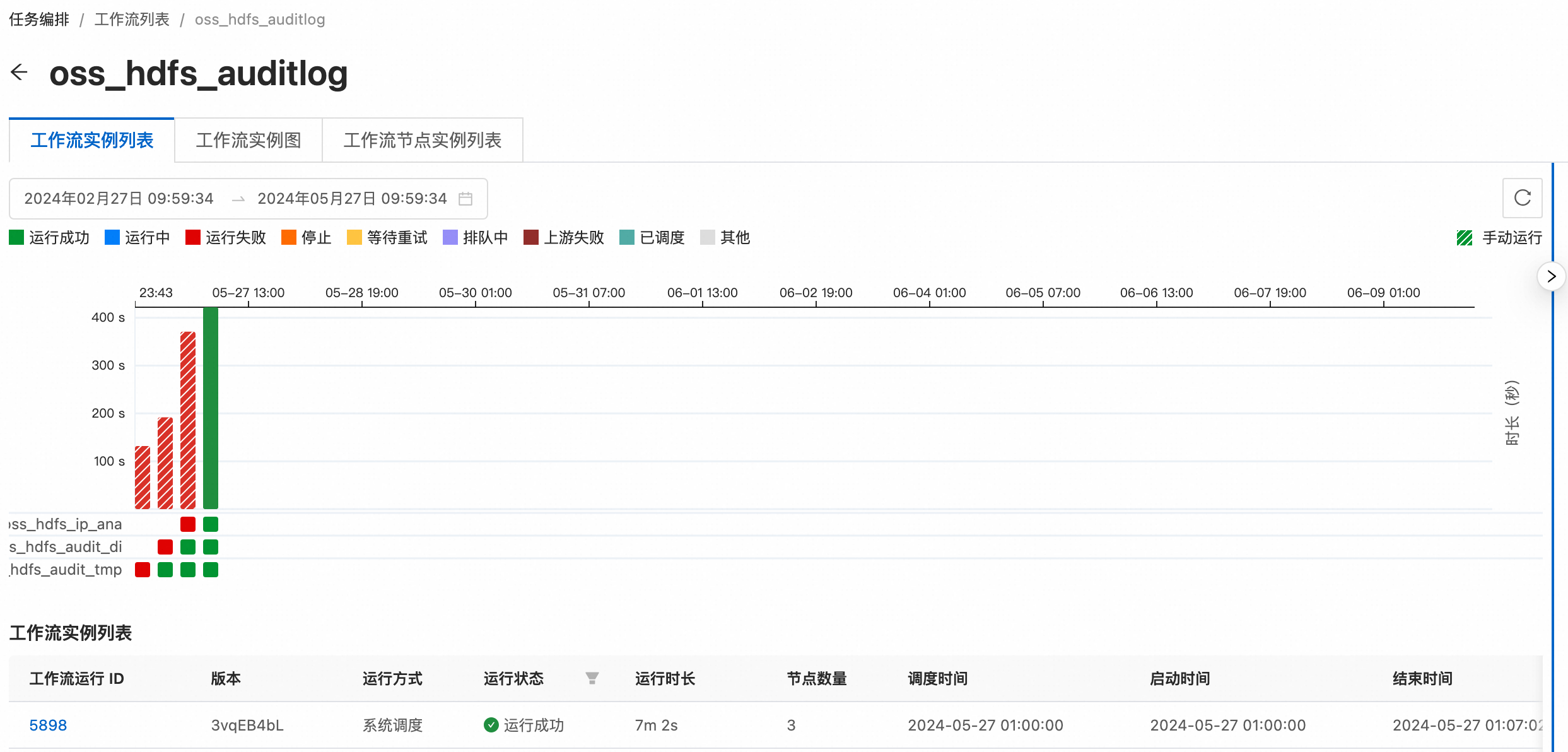
在每天凌晨的定时调度完成之后或者一次手动调度成功之后,我们可以回到 SQL 任务开发界面,在编辑器中输入如下 SQL 查询语句,可以快速获取到前一天请求 OSS-HDFS 数量最多的前 20 个 IP 地址:SELECT * FROM dws_oss_hdfs_ip_ana where dt = '${ds}';我们可以得到类似下面的 SQL 运行结果:

总结
本文演示了使用 Serverless Spark 产品搭建一个日志分析应用的全流程,包括数据开发和生产调度以及交互式查询等场景。**EMR Serverless Spark 在 2024年5月正式开启公测,在公测期间可以免费使用最高 100 CU 计算资源,欢迎试用。**如果您在使用 EMR Serverless Spark 版的过程中遇到任何疑问,可钉钉扫描以下二维码加入钉钉群(群号:58570004119)咨询。

快速跳转
-
EMR Serverless Spark 版官网:https://www.aliyun.com/product/bigdata/serverlessspark