AcademicGPT: Empowering Academic Research
AcademicGPT: 增强学术研究能力
paper: https://arxiv.org/pdf/2311.12315
文章目录
- 1.背景动机
- 2.Model
-
- [2.1. Data](#2.1. Data)
- 2.2.Model
- 3.论文阅读
-
- Abstract
- Introduction
- 3.AcademicGPT
-
- [3.1 Data](#3.1 Data)
- [3.2 Modeling](#3.2 Modeling)
- [3.3 Results](#3.3 Results)
- [4 Applications of AcademicGPT](#4 Applications of AcademicGPT)
-
- [4.1 General Academic Question Answering](#4.1 General Academic Question Answering)
- [4.2 AI-assisted Paper Reading](#4.2 AI-assisted Paper Reading)
- [4.3 Paper Review](#4.3 Paper Review)
- [4.4 AI-assisted Title and Abstract Generation](#4.4 AI-assisted Title and Abstract Generation)
- [5 Conclusion](#5 Conclusion)
1.背景动机
现阶段学术领域大模型的需求:
随着知识的迅猛增长和科学发现的惊人速度,文献的增长既意味着人类认识的巨大进步,也意味着研究人员在跟上新见解方面所面临的迫在眉睫的挑战。这个问题在专业领域或细分领域尤为突出。在这些领域中,有针对性的研究、新颖的方法和复杂的发现迅速增加,加剧了学者们迅速理解和吸收这些细分领域的特殊性的难度。这种信息饱和不仅阻碍了知识的顺畅流动,也为跨学科工作设置了障碍。
引出本文提出的AcademicGPT模型所要解决的问题:
包括论文阅读,人工智能辅助方法可以突出关键发现并提供简明摘要;论文润色,先进的工具可以提供语法检查和文体建议,并确保提出的观点清晰连贯;论文审阅,工具可以对论文提出批评意见;基于内容的论文写作,预测和生成模型可以帮助研究人员构建结构合理的叙述和论点,从而节省宝贵的时间
2.Model
- 将阐明用于培养 AcademicGPT 能力的数据集。
- 概述了该模型的架构。
- 报告该模型的实验结果
2.1. Data
学术数据源的构造:
训练数据是基于上述两个目标构建的。
-
包含更多学术数据
-
增加更多中文数据
具体来说,一方面,训练数据应包括高质量的中文和英文数据。另一方面,训练数据应主要来自学术领域,包括学术论文、毕业论文、某些学术领域的内容等。
中文学术数据源构造:
中文数据包括四种类型: 常见抓取、维基、百科和图书。但是,从普通抓取中收集到的数据通常很脏。需要对数据进行清理。中文数据清洗管道包括四个阶段。
- 从一些顶级学术领域抓取 20 万篇文章;
- 使用功能强大的 LLM 对数据进行标注;
- 使用获得的 200K 数据训练 LLM 进行分类;
- 对普通抓取数据进行分类,并从 CC 中清理出 12.7B 标记。
英文学术数据源构造:
首先,抓取了全球 200 所顶尖大学的 100 多万篇论文。对于这类数据,我们使用 Nougat来解析 pdf 文件。
- 抓取 Arxiv论文(其中包含截至 2023 年 5 月的约 226 万篇论文)。
- 使用unpaywall的数据,它是一个包含48,383,164篇免费学术文章的开放数据库,收集了来自50,000多家出版商和资料库的开放存取内容。对于篇幅不太长的论文 PDF,使用自己的 PDF 解析器对这些 PDF 文档进行结构化处理。
- 从 Falcon-Refinedweb(Penedo et al. 一般来说,我们认为 Falcon-Refinedweb的质量不错,我们需要做的是从中筛选出高质量的学术数据。
- 除上述来源外,还使用了维基页面(仅限英文页面)、Semantic Scholar的书目和 PubMed 的论文。
2.2.Model
对于加速训练过程:
- 使用 FlashAttention,它不仅能加快注意力模块的速度,还能节省大量内存;
- Apex RMSNorm,它实现了融合的 cuda 内核。
- 由于 AcademicGPT 是 LLaMA2-70B 的持续训练模型,它使用了一些与 LLaMA2 相同的技术,包括用 RMSNorm代替 LayerNorm,用 SwiGLU代替 GeLU。
- 在位置嵌入方面,它使用 RoPE代替 Alibi。
- 在标记化方面,它使用 BPE。它使用 DeepSpeed和 Zero。我们的训练基于 gpt-neox框架,其中集成了许多新引入的技能。使用 192 个 A100 GPU 和 40GB 内存完成 120B 数据的训练大约需要 37 天。
对于训练策略:
使用了 AdamW 优化器,β1 和 β2 值分别设置为 0.9 和 0.95,ε = 10-8。我们利用余弦学习率计划,将最终学习率衰减到仅为峰值学习率 1.5e-5 的 1。
使用的批量大小为 10,约为 157 万个 token,其中每个样本包括 4,096 个 token 序列。
为了进行梯度累积,累积了 64 个小批量。为了稳定地训练模型,采用了以下技巧:
-
使用 BF16而非 FP16。
-
对 LayerNorm层使用 FP32。
-
将梯度剪切设置为 0.4,而不是 1.0。
-
对于 LayerNorm 层中的ε,设置为 1e-5。
-
使用了更长的预热时间。
3.论文阅读
Abstract
大型语言模型(LLM)已在各种自然语言处理任务中展现出非凡的能力。然而,许多先进的 LLM 都是为广泛的通用应用而量身定制的。在本技术报告中,我们将介绍专为学术研究而设计的 AcademicGPT。AcademicGPT 是源于 LLaMA2-70B 的持续训练模型。我们的训练语料库主要由学术论文、论文、某些学术领域的内容、高质量中文数据等组成。虽然在数据规模上并不庞大,但 AcademicGPT 标志着我们首次涉足为研究领域量身定制的特定领域 GPT。我们在 MMLU 和 CEval 等几个成熟的公共基准,以及 PubMedQA、SCIEval 和我们新创建的 ComputerScienceQA 等一些专业学术基准上对 AcademicGPT 进行了评估,以证明其从常识能力、中文能力到学术能力的能力。在 AcademicGPT 的基础模型上,我们还开发了多个针对学术领域的应用,包括通用学术问题解答、人工智能辅助论文阅读、论文评审以及人工智能辅助标题和摘要生成。
Introduction
介绍现有的模型在不同领域的发展:
大型语言模型(LLMs)(Brown 等人,2020;Chowdhery 等人,2022;Du 等人,2021;Hoffmann 等人,2022;OpenAI,2023a;Ouyang 等人,2022;Radford 等人,2018,2019;Touvron 等人,2023a,b;Zeng 等人,2022)已经改变了自然语言处理(NLP)和人工智能(AI)。LLM 不仅重新定义了我们理解和生成文本内容的能力,还将其影响扩展到了各个领域。在写作领域,LLM(OpenAI, 2023a)为细致入微的叙述和精确的技术内容注入了活力。在编程领域,他们(Roziere et al., 2023)为复杂的编码问题提供了解决方案,在人类语言和代码之间架起了桥梁。在金融等领域,这些模型(Wu 等人,2023b)解码复杂的数据集,精准预测市场趋势。在医疗保健领域(OpenAI,2023a,b;Singhal 等人,2022),这些模型可协助诊断、提出治疗建议,甚至完成复杂的研究任务。在创意艺术领域,结合多模态大型模型,它们为人工智能驱动的音乐生成、服装设计和其他艺术表现形式打开了大门。总之,LLM 为众多行业带来了变革(Bran 等人,2023;Chen 和 Koohy,2024;Cui 等人,2023;Luo 等人,2022;Rozi`ere 等人,2023;Scarlatos 和 Lan,2023;Singhal 等人,2022;Wu 等人,2023b;Zheng 等人,2023)。
然而,通往这一革命性阶段的征程并非一蹴而就。BERT(Devlin等人,2018年)和GPT-1(Radford等人,2018年)开创了大型模型时代。GPT-3(Brown 等人,2020 年)等模型奠定了基础,其数十亿个参数设定了新的基准。随后的创新包括 ChatGPT(欧阳等人,2022 年)的对话能力、PalM(Chowdhery 等人,2022 年)的多任务处理能力、LLaMA 系列(Touvron 等人,2023 年a,b)的高级语言能力、CodeGeeX 和 CodeL- LaMA(Rozi`ere 等人,2023 年;Zheng 等人,2023 年)、 2023; Zheng et al., 2023)的编程能力、GPT4(OpenAI, 2023a)的通用和专业能力的提高,以及GPT-4V(OpenAI, 2023b; Yang et al., 2023b)的多模型能力,都在不断突破,为人工智能的发展开辟了新的领域。总之,得益于信息传播的便利性,创新的速度已经大大超过了过去。
介绍学术领域的的需求问题:
随着知识的迅猛增长和科学发现的惊人速度,学者和研究人员不断被不断扩大的文献海洋所淹没。这种压倒性的丰富是自相矛盾的,既意味着人类认识的巨大进步,也意味着研究人员在跟上新见解方面所面临的迫在眉睫的挑战。这个问题在专业领域或细分领域尤为突出。在这些领域中,有针对性的研究、新颖的方法和复杂的发现迅速增加,加剧了学者们迅速理解和吸收这些细分领域的特殊性的难度。这种信息饱和不仅阻碍了知识的顺畅流动,也为跨学科工作设置了障碍。掌握这些细分领域错综复杂的细节需要大量时间,从而减缓了整合与创新的步伐。
引出本文要提出的学术垂直领域的大模型:
为研究人员提供有效的工具和方法,使他们能够从浩如烟海的信息中提炼出重要的见解,确保关键的进展和发现得到认可和发扬光大,这一点变得越来越重要。这些工具不仅仅局限于帮助理解,而是涵盖了广泛的研究活动,其中包括论文阅读,人工智能辅助方法可以突出关键发现并提供简明摘要;论文润色,先进的工具可以提供语法检查和文体建议,并确保提出的观点清晰连贯;论文审阅,工具可以对论文提出批评意见;基于内容的论文写作,预测和生成模型可以帮助研究人员构建结构合理的叙述和论点,从而节省宝贵的时间 。
在本技术报告中,我们的贡献主要体现在两个方面。
- 我们介绍 AcademicGPT,这是一个专门为科学研究定制的 GPT 模型。该模型是利用庞大学术语料库的有力证明,它是在拥有 1200 亿个token的学术语料库上训练出来的。处理过的大量数据确保了它在理解错综复杂的科学细微差别时的稳健性和准确性。
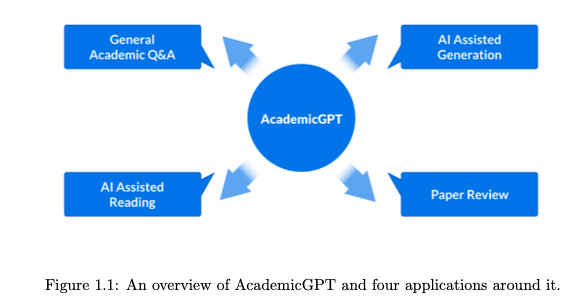
- 如图 1.1 所示,我们基于 AcademicGPT 构建了几个应用,包括通用学术问题解答、人工智能辅助论文阅读、论文评审和人工智能辅助内容生成 。我们的通用学术问答系统是一个配备多轮对话记忆的复杂代理 。在该代理中,
我们的战略规划和应用架构从 ReAct 框架中汲取灵感,整合其原则以实现预期成果。这确保了学术讨论的连续性和情境感知,为有意义、有深度的互动奠定了基础。我们认识到冗长的学术文章所带来的挑战,因此引入了人工智能驱动的解决方案,以简化和增强论文阅读体验,确保研究人员高效地掌握核心概念。我们的论文评审系统以基于 AcademicGPT 的监督微调(SFT)模型为基础,引入了一种评估学术内容的方法。我们的人工智能内容生成器仅根据给定的引言生成摘要和标题等内容。通过操纵输入上下文的顺序,我们的模型在内容创建方面表现出很强的适应性。
从本质上讲,我们与 AcademicGPT 的合作不仅为科学研究引入了一个强大的模型,还展示了其实际应用,有望对学术界产生变革性影响。
本技术报告的结构如下: 第 2 节讨论了一些相关工作。第 3 节介绍 AcademicGPT 模型,并报告其在多个基准测试中的结果。第 4 节介绍基于 AcademicGPT 的四个应用程序。
3.AcademicGPT
介绍AcademicGPT,数据-模型架构-实验:
在本节中,我们将通过研究 AcademicGPT 的数据来源、模型架构和实验结果来深入探讨 AcademicGPT。首先,我们将阐明用于培养 AcademicGPT 能力的数据集。然后,我们概述了该模型的架构。最后,我们报告了该模型在 MMLU(Hendrycks 等人,2020 年)、CEval(Huang 等人,2023 年)、PubMedQA(Jin 等人,2019 年)、SCIEval(Sun 等人,2023 年)以及我们新收集的 ComputerScienceQA 等基准测试中的表现。
3.1 Data
介绍现有数据集并不适合学术领域,并引出academicgpt是为了增强 LLaMA2 的学术研究能力,同时提高其中文能力:
我们在 AcademicGPT 中的目标是增强 LLaMA2 的学术研究能力,同时提高其中文能力。因此,我们的数据收集方式就是围绕这两个目标展开的。众所周知,由于使用的中文语料有限,LLaMA2 理解中文的能力有限。同时,由于 LLaMA2 是一个通用的 LLM,因此没有使用足够的学术数据。现有的一些大规模数据集包括 Pile(Gao 等人,2020 年)、Roots(Lauren ̧con 等人,2022 年)、RedPajama- Data(TogetherAI,2023 年)、Falcon-Refinedweb(Penedo 等人,2023 年)、WudaoCorpora Text(Yuan 等人,2021 年)。这些数据都是为通用目的收集的。
具体介绍学术数据集的构造:
我们的训练数据是基于上述两个目标构建的。
-
包含更多学术数据
-
增加更多中文数据
具体来说,一方面,我们的训练数据应包括高质量的中文和英文数据。另一方面,我们的训练数据应主要来自学术领域,包括学术论文、毕业论文、某些学术领域的内容等。

中文数据集的构造来源:
我们的中文数据包括四种类型: 常见抓取(CC)、维基、百科和图书。但是,从普通抓取(CC)中收集到的数据通常很脏,其中包含大量广告、色情信息、暴力和其他有毒信息。我们需要对数据进行清理。我们的中文数据清洗管道包括四个阶段。
- 我们从一些顶级学术领域抓取 20 万篇文章;
- 我们使用功能强大的 LLM 对数据进行标注。我们用来标注数据的提示如图 3.1 所示;
- 我们使用获得的 200K 数据训练 LLM 进行分类;
- 我们对普通抓取数据进行分类,并从 CC 中清理出 12.7B 标记。
英文数据集的构造来源:
在收集学术英语数据时,我们注重收集更高质量的数据。我们的学术数据由多个来源组成。
首先,我们抓取了全球 200 所顶尖大学的 100 多万篇论文。我们认为,与传统的会议论文或期刊论文相比,论文数据具有自洽性。相反,会议论文和期刊论文通常是不一致的,需要更多的专家经验才能理解。由于论文的内容通常很长。对于这类数据,我们使用 Nougat(Blecher 等人,2023 年)来解析 pdf 文件。
- 我们抓取 Arxiv论文(其中包含截至 2023 年 5 月的约 226 万篇论文)。
- 我们使用unpaywall 2的数据,它是一个包含48,383,164篇免费学术文章的开放数据库,收集了来自50,000多家出版商和资料库的开放存取内容。对于篇幅不太长的论文 PDF,我们使用自己的 PDF 解析器对这些 PDF 文档进行结构化处理。
- 我们从 Falcon-Refinedweb(Penedo et al. 一般来说,我们认为 Falcon-Refinedweb 3 的质量不错,我们需要做的是从中筛选出高质量的学术数据。
- 除上述来源外,我们还使用了维基页面(仅限英文页面)、Semantic Scholar 4 的书目和 PubMed 的论文。
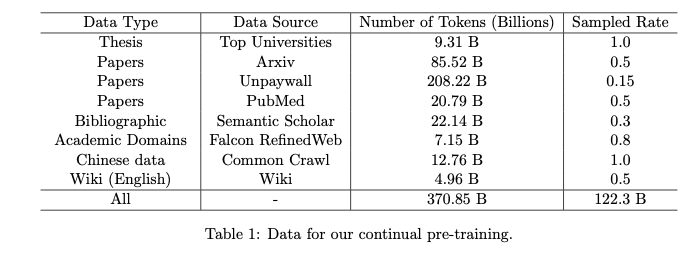
表 1 列出了本文收集和使用的数据的详细信息。大部分数据都是研究论文、学位论文和其他一些学术数据。
3.2 Modeling
介绍loss学习目标:
神经网络本质上是一个函数逼近问题。给定 i∈1,N 的大量数据 (xi, yi),我们的目标是学习一个函数 F(-),以最小化以下损失函数:
l o s s = 1 N ∑ i = 1 N L ( F ( x ∗ i ; W ) , y ∗ i ) , \begin{equation} loss=\frac{1}{N}\sum_{i=1}^{N}\mathcal{L}\left(F\left(\boldsymbol{x}*{i}; \boldsymbol{W}\right),\boldsymbol{y}*{i}\right), \tag{1} \end{equation} loss=N1i=1∑NL(F(x∗i;W),y∗i),(1)
在训练阶段之后,推理基本上是一个插值过程。
模型能力:
模型能力。为了使模型具有较强的近似能力,我们需要保证网络具有较大的 Lipschitz 常量,其定义如下:
∥ F ( x ∗ 1 ; W ) − F ( x ∗ 2 ; W ) ∥ ≤ L 0 ∥ x ∗ 1 − x ∗ 2 ∥ \begin{equation} \|F(\boldsymbol{x}*{1};\boldsymbol{W})-F(\boldsymbol{x}*{2};\boldsymbol{W})\| \leq L_{0}\|\boldsymbol{x}*{1}-\boldsymbol{x}*{2}\| \tag{2} \end{equation} ∥F(x∗1;W)−F(x∗2;W)∥≤L0∥x∗1−x∗2∥(2)
大的 Lipschitz 常量意味着模型具有更强的非线性,因此具有更强的近似能力。例如,与 Convolution(LeCun 等人,1998 年)网络相比,Transformer 架构(Vaswani 等人,2017 年)的 Lipschitz 常数要大得多,因此具有强大的表示能力。通过了解每个模块的雅各布矩阵及其相应的 Lipschitz 常数,我们可以从理论上估计网络的代表性能力。读者可参考 Qi 等人(2023)的详细分析。
训练稳定性:
训练稳定性。然而,较大的 Lipschitz 常数可能会导致训练不稳定。因此,为了保证网络有一个稳定的训练过程,我们需要保持
x l , ∂ L ∂ x l < R , for l ∈ 1 , L . \begin{equation} \boldsymbol{x}^{l},\frac{\partial\mathcal{L}}{\partial\boldsymbol{x}^{l}}< \mathcal{R},\text{ for }l\in1,L. \tag{3} \end{equation} xl,∂xl∂L<R, for l∈1,L.(3)
上述等式意味着激活度及其梯度应限定在数值表示范围内(如 FP16、FP32 或 BF16)。
训练策略:
我们的训练策略 为了训练 AcademicGPT,我们使用了 AdamW 优化器(Loshchilov 和 Hutter,2017 年),β1 和 β2 值分别设置为 0.9 和 0.95,ε = 10-8。我们利用余弦学习率计划,将最终学习率衰减到仅为峰值学习率 1.5e-5 的 1。我们使用的批量大小为 10,约为 157 万个 token,其中每个样本包括 4,096 个 token 序列。为了进行梯度累积,我们累积了 64 个小批量。为了稳定地训练模型,我们采用了以下技巧:
-
我们使用 BF16(Kalamkar 等人,2019 年)而非 FP16。
-
我们对 LayerNorm(Ba 等人,2016 年)层使用 FP32。
-
我们将梯度剪切设置为 0.4,而不是 1.0。
-
对于 LayerNorm 层中的ε,我们设置为 1e-5。
-
我们使用了更长的预热时间(Loshchilov 和 Hutter,2016 年)。
上述技巧要么是为了扩大数值表示的范围 R,要么是为了限制模块或整个网络的李普奇斯特常数 L0 的快速增长。这样,我们就能保证公式 2 在训练过程中始终成立。
加速训练:
为了加快训练过程,我们还集成了一些先进的新技术,包括 FlashAttention(Dao,2023 年),它不仅能加快注意力模块的速度,还能节省大量内存;Apex RMSNorm,它实现了融合的 cuda 内核。由于 AcademicGPT 是 LLaMA2-70B 的持续训练模型,它使用了一些与 LLaMA2 相同的技术,包括用 RMSNorm(Zhang 和 Sennrich,2019 年)代替 LayerNorm,用 SwiGLU(Shazeer,2020 年)代替 GeLU。在位置嵌入方面,它使用 RoPE(Su 等人,2021 年)代替 Alibi(Press 等人,2021 年)。在标记化方面,它使用 BPE(Sennrich 等人,2015 年)。它使用 DeepSpeed(Rasley 等人,2020 年)和 Zero(Rajbhandari 等人,2020 年)。我们的训练基于 gpt-neox (Black 等人,2022 年)框架,其中集成了许多新引入的技能。使用 192 个 A100 GPU 和 40GB 内存完成 120B 数据的训练大约需要 37 天。
3.3 Results
我们在多个基准上对 AcademicGPT 进行了评估。首先,我们在一些通用基准上评估了我们的模型,包括 MMLU(Hendrycks 等人,2020 年)和 CEval(Huang 等人,2023 年)。我们的目标是评估持续训练是否会降低原始 LLaMA2 模型(Touvron 等人,2023b)的性能,并评估 AcademicGPT 在持续训练后的中文能力。其次,我们评估了 AcademicGPT 在一些学术基准上的能力,包括 PubMedQA(金等人,2019)、SCIEval(孙等人,2023)和 ComputerScienceQA。ComputerScienceQA是我们新创建的数据集,用于评估模型在计算机科学领域的能力。默认情况下,当我们提到 LLaMA1 和 LLaMA2 时,我们指的是 LLaMA1- 65B 和 LLaMA2-70B。
关于 MMLU 的结果。我们考察了 AcademicGPT 在 MMLU 上的能力。MMLU 测试集涵盖 57 项任务,包括初等数学、美国历史、计算机科学、法律等。要在该测试中获得高准确率,模型必须具备广泛的世界知识和解决问题的能力。通过全面评估模型对学术和专业理解的广度和深度,MLU 可用于分析模型在多项任务中的表现,并找出重要的不足之处。
按照一些标准的评估方法(Chowdhery et al.,2022;OpenAI,2023a;Touvron et al.,2023a,b),我们使用 5 次拍摄设置进行评估。在表 2 中,我们报告了 MMLU 测试集 57 个类别的平均性能,并将 AcademicGPT 与 LLaMA1(65B)、LLaMA2(70B)、ChatGPT(gpt-3.5-turbo- 0613)进行了比较。表 3 显示了 AcademicGPT 和 LLaMA2 在多门课程中的成绩。
我们可以发现,LLaMA2 的持续训练不会降低平均成绩。平均而言,我们发现在持续训练中使用了大量数据的几个类别上,其结果会有所改善,但在持续训练中数据覆盖面不广的一些类别上,其性能会略有下降。
CEval 上的结果。为了评估 AcademicGPT 在中文方面的能力,我们在 CEval 基准上对其进行了评估,并将其与其他几种方法进行了比较。
CEval 是一个中文测评工具包,旨在从多个角度快速评估和了解一个模型的能力,尤其是其世界知识和推理能力。该测评源于真实的中国人考试,涵盖初中、高中、大学和专业阶段,包括科学、技术、工程、人文和社会科学在内的 52 个学科。我们在模型开发过程中使用了有效的 CEval 评估集,该评估集由全部 52 个科目的 1346 道题目组成。在评估过程中,我们采用了 5 次评估设置。评估结果见表 4。
从表 4 中我们可以看出,通过适量整合教科书和百度百科(维基百科的中文版)中的中文普通爬虫内容,我们将 AcademicGPT 在 CEval 上的性能从原来 LLaMA2 的 50.8% 提升到了 55.1%。在我们的并行评估中,经过中文增强的 AcademicGPT 在学术阅读辅助和翻译等场景中的表现明显优于其原始版本。
PubMedQA 的结果。PubMedQA(Jin等人,2019)5是一个从PubMed摘要中收集的生物医学问题解答数据集。PubMedQA 的任务是根据相应的摘要回答研究问题的三个选项:是/否/可能。它由 1k 个专家标注的、61.2k 个未标注的和 211.3k 个人工生成的 QA 实例组成。每个实例由四个部分组成:问题、上下文、长答案和断言。问题可以是现有研究文章的标题,也可以是由标题衍生出的内容。上下文是相应的摘要,不包括其结论。长答案是摘要的结论,大概是对研究问题的回答。最后是一个 "是/否/可能 "的论断,对结论进行总结。
在评估中,我们只使用了 1k 个专家标注的实例。我们使用 5 次拍摄进行评估。不同模型的结果如表 5 所示。
从表 5 可以看出,在 PubMedQA 数据集上,我们的方法比 LLaMA1、LLaMA2、ChatGPT3.5 和 GPT4 取得了更好的结果。我们认为,这可能是因为我们的持续训练数据中包含了更多与医学相关的语料。
SCIEval 的结果。SCIEval 6(Sun 等人,2023 年)是一个基于布鲁姆分类法的科学评价系统,旨在评估模型在基础知识、知识应用、科学计算和研究能力方面的表现。数据主要来源于苏格拉底问答 7,并整合了多个公共数据集,涵盖生物、化学和物理三个学科。我们使用SCIEval的验证集进行测试,只关注验证集中的客观题--共1,187道题,其中生物380道,化学643道,物理164道。
与之前的方法(Sun 等人,2023 年)一样,我们利用了 3 次上下文学习评估。我们将 Aca- demicGPT 与 ChatGPT3.5 和在 SCIEval 上测试过的原始 LLaMA2(Touvron 等人,2023b)进行了比较。结果见表 6。
从表 6 中可以看出,AcademicGPT 将 LLaMA2 的平均准确率从 63.6 提高到了 68.8,也超过了 ChatGPT 的 67.9 分。我们可以看到,与 ChatGPT 相比,AcademicGPT 在物理方面表现更好,但在化学方面表现不佳。
ComputerScienceQA 的结果。ComputerScienceQA 评估基准基于 PapersWithCode 8 建立。Papers WithCode 展示了机器学习研究的趋势以及相应的实现代码。
PapersWithCode 包括两个部分: "数据集 "和 "方法"。方法 "部分主要是对研究论文中详细技术的描述,而 "数据集 "部分则是对数据集的描述。这些信息由一个开放社区策划和审核。从方法论的角度来看,PapersWithCode 涉及七个主要领域,每个领域都包含多个分类层。例如,在 "注意/注意机制/注意模式 "下,我们可以找到对各种方法概念的描述,如 "步进式注意"、"固定因素化注意"、"滑动窗口注意 "等。从数据集的角度来看,PapersWithCode 涵盖了一系列模式,如图像、文本、视频、音频等,提供了计算机科学领域数据集的整体和实时概览。截至 2023 年 9 月,我们的计算机科学质量保证包括 1,885 种方法和 7,801 个数据集。每个子领域由多个主题组成,每个主题包含一系列方法。例如,在 "自我注意 "下,从数据集的角度来看,就存在大量不同的自我注意机制实现,包括线性注意、稀疏注意、快速注意、点积注意、L2 相似性注意等。
下面,我们将介绍我们的构建策略。对于 "方法 "题型
-
获取方法描述并对其进行处理:将方法描述与方法名称和全名进行大小写不敏感匹配,并用"() "替换,以防止信息泄露。删除所有 HTTP(s)链接,以避免数据泄露。
-
将问题提示拟为 问题 以下哪个选项是对 "method.get('full name', method'name')" 的描述?
正确选项源于该方法的描述,而干扰选项则源于同一域集合中其他方法的描述。
我们的方法主要受银河系(Galactica)(泰勒等人,2022 年)论文的启发,旨在衡量模型在掌握计算机科学领域的方法和数据集方面的能力。这种构建方法的优点包括
- 全面覆盖当前计算机科学领域的主流知识和目标,
- 多选题的形式简化了创建过程,便于准确评估。
总之,我们共整理了 9,686 个问题,其中 1,885 个与方法有关,7,801 个与数据集有关。有关方法和数据集的样本可参见图 3.2。
在评估过程中,我们采用了三步评估法。我们将我们的方法与 ChatGPT 和 LLaMA2 的原生架构进行了对比。结果见表 7。
从表 7 中我们可以看出,AcademicGPT 的性能比原来的 LLaMA2 好得多,从 79.9% 提高到 83.5%。与 ChatGPT 相比,它的性能也更好。
4 Applications of AcademicGPT
在 AcademicGPT 的基础上,我们构建了多个应用,包括一般学术问题解答、人工智能辅助论文阅读、论文评审以及人工智能辅助标题和摘要生成。从本质上讲,在 AcademicGPT 的坚实基础上,我们不仅增强了该模型的功能,还创建了几种可增强学术研究能力的工具。图 1.1 显示了我们的整体框架。

4.1 General Academic Question Answering
与一般问题解答相比,学术问题解答要求更加严格。我们的学术问题解答系统是一个由 LLM 驱动的代理(Karpas 等人,2022;Schick 等人,2023;Shen 等人,2023;Weng,2023;Wu 等人,2023a;Xi 等人,2023),它由以下模块组成:**一个由 AcademicGPT 驱动的引擎(充当大脑)、一个计划和行动模块、记忆和工具。该系统可以利用各种学术工具的力量,为不同类型的问题(如论文检索、概念澄清或多篇论文比较)和论文推荐量身定制。**图 4.1 显示了学术 GPT 代理的概况。下面,我们将详细介绍各个模块。
AcademicGPT引擎。如图 4.1 所示,引擎是系统的大脑。从本质上讲,我们的 AcademicGPT 驱动引擎是一个经过指令调整的 AcademicGPT。引擎应具备以下两种能力:
- 理解和执行指令
- 知道何时使用工具、使用哪种工具以及如何使用工具。
为使我们的模型具备上述两种能力,我们的指令微调数据应包括两类数据:一般指令微调数据和工具使用指令数据。我们的指令微调数据主要包括我们对开源数据的进一步清理,包括清理后的 Wizard 9、LIMA 10、alpaca 的中英文版本(Taori et al.),以及我们构建的 384 工具使用说明。
规划与行动。利用 LLMs 的能力作为我们代理的大脑,系统可以对各种问题进行思考和制定策略。在 LLMs 之后,有许多研究(Shinn 等人,2023 年;Wang 等人,2022 年;Wei 等人,2022 年;Yao 等人,2022 年)专注于提高模型的规划和推理能力,包括思维链(CoT)(Wei 等人,2022 年)、自我一致性(Wang 等人,2022 年)、反思(Shinn 等人,2023 年)和 ReAct(Yao 等人,2022 年)。我们的方法采用了 ReAct。ReAct 扩展了行动空间,将特定任务的离散行动与语言结构相结合。这种融合将推理和行动无缝地整合到 LLM 中。ReAct 方法是推理和后续行动的综合。这种方法的概念是基于对人类行为的敏锐观察:人类倾向于在多步骤任务的各个步骤之间进行推理。我们对其进行了调整,使 LLMs 能够发出 "内心独白",将后续行动与这一清晰的推理相协调,从而模仿人类的认知过程。这种方法在不同的数据集上进行了测试,取得了最先进的结果,提高了 LLMs 的可信度,减少了其无意义输出的倾向。
与 ReAct(Yao 等人,2022 年)不同的是,我们的操作输出是 JSON 格式,详细说明了所使用的 API 及其各自的参数。如图 4.2 所示,我们可以从以下提示中进一步了解这些参数。
内存。所有历史多轮对话的上下文都被视为模型的短期记忆。而通过模糊关键词搜索检索到的学术知识图谱则作为长期记忆。
工具利用。代理中可以使用许多工具,包括搜索引擎、知识图谱(KG)、矢量知识库等。在我们的系统中,我们使用了以下工具: 知识图谱和必应搜索引擎。对于知识图谱,我们使用了基于弹性搜索(ES)的知识图谱,它将作者、标题、摘要、出版日期、机构、引文和参考文献等信息整合到一个 ES 设置中,该工具提供跨字段和逻辑排序的模糊搜索功能。在该工具的基础上,我们增加了一些功能,包括推荐相似论文。该功能可根据参考文献和关键词精确推荐多篇类似论文。对于必应搜索引擎,我们还特别处理了一些网站,如 "PapersWithCode"。该网站允许检索最前沿的学术知识,如跨数据集的最新成果及其相关论文。模型的输入提示中详细阐述了每个应用程序接口的功用、应用场景和参数。
图 4.3、图 4.4 和图 4.5 展示了三种情况。可以看出,我们的系统在论文推荐、概念解释等方面表现出色。

4.2 AI-assisted Paper Reading
人工智能辅助论文阅读是一种有效的工具,可以通过互动问答的形式帮助读者并解释他们的困惑。对于人工智能辅助论文阅读而言,由于论文全文通常较长,因此需要具有较长上下文窗口的 LLM。然而,从头开始训练具有较长上下文窗口的 LLM 需要大量投资。在本技术报告中,为了实现人工智能辅助阅卷的能力,我们采用了两阶段管道。在第一阶段,我们继续进行预训练,并使用动态 ntk-aware 方法扩展到更大的上下文窗口。在第二阶段,我们使用监督微调模式,在 LongAlpaca-12k 数据集上训练模型。下面,我们将详细介绍这两个阶段。
在第 1 阶段,我们使用 NTK(Chen 等,2023a;Peng 等,2023)将窗口大小扩大到 32K,并继续在从我们的数据集中抽取的 5B 样本上进行训练,如表 1 所示。在第二阶段,我们使用 LongAlpaca-12k 数据集(Chen 等,2023b,c)进行完全监督微调。LongAlpaca-12k 数据集包括 9k 个长 QA 条目和从原始羊驼数据集中采样的另外 3k 个短 QA 条目。这种混合确保了模型在响应较短指令时的熟练程度不受影响。与传统的 Alpaca 结构一致,长 QA 数据采用了以下提示进行微调:1)指令:为模型布置任务的字符串。例如,它可能会指示模型在检查一本书或一篇研究论文的某个片段后回答一个查询。他们将内容和查询多样化,以确保指令的广泛性。2) 输出:提供给定指令响应的字符串。
在工程学中,我们还可以使用一些其他方法来扩展窗口大小。一种选择是训练一个小模型,如 LLaMA-7B 来提取上下文信息,然后使用我们的 AcademicGPT 生成最终答案。
在图 4.6 和图 4.7 中,我们展示了人工智能辅助阅读系统的两个案例。
4.3 Paper Review
数据收集与清理。我们的论文评论数据来自 OpenReview 11。我们从 OpenReview 搜集了 29119 篇论文和 79000 条评论。之后,我们过滤掉了 7115 篇不包含 PDF 或评论的论文。此外,我们还删除了一些特定字符串,如 "正在作为 ICLR 2023 会议论文进行评审 "和 "匿名作者论文正在接受双盲评审",并删除了 PDF 解析失败的内容。在审稿清理方面,我们删除了换行过多的审稿、短于 100 字节或长于 2000 字节的审稿,以及与置信度最低的决定不一致的审稿。
如Review Advisor(Yuan等人,2022)12,我们从 "清晰度"、"平均比较"、"动机"、"原创性"、"可复制性"、"合理性"、"实质内容 "等七个方面进行考虑,并使用其开源代码对数据进行注释。最后,我们获得了 22,213 篇论文和 67,874 条评论意见作为训练数据,500 篇论文和 1,513 条评论意见作为测试数据。
SFT 详情。我们的 SFT 数据格式如图 4.11 所示。我们在 AcademicGPT 上对论文评论模型进行了微调。在 LLaMA2 和 AcademicGPT 中,最大长度为 8,192,而不是原来的 4,096。我们使用的批量大小集为 128,微调了 3 个 epoch。
指标。我们采用了三个指标进行评估。第一个是最终推荐结果的准确性;如果推荐结果与元审查推荐结果一致,则认为推荐结果正确,否则认为推荐结果不正确。第二个指标涉及与前面提到的七个方面相关的准确性;如果我们报告的方面在元综述中也被提及,则被认为是准确的,否则就是不正确的。例如,如果在 M 个预测中,有 K 个是正确的,那么准确率就是 MK。第三个指标是召回率。例如,如果元在所有评估论文中提到 N 个评估项目,而我们召回了 L 个,那么召回率就是 NL。本报告中使用的评价指标是由 Review Advisor(Yuan 等人,2022 年)提出的。结果如表 8 所示。
从表 8 中可以看出,我们的最终推荐准确率为 68%。在论文 Review Adviser(Yuan 等人,2022 年)中,作者认为当时的语言模型不具备论文审稿能力。我们的观点是,论文审稿脚本具有一定的审稿能力,可以作为作者的参考意见。但是,与人类审稿人相比仍有明显差距。
在图 4.8、图 4.9 和图 4.10 中,我们展示了三个论文审稿案例。
4.4 AI-assisted Title and Abstract Generation
研究论文的精髓往往体现在标题和摘要中。它们不仅是研究内容的缩影,而且在吸引读者注意力方面发挥着关键作用。因此,标题和摘要必须准确、清晰。
在技术报告中,受读者理解过程的启发,我们将数据表述设计为 "引言 实验结果 <开始生成>标题:内容;摘要:内容"。其中意大利字体的内容是可选的。""是触发生成过程的特殊标记。
为确保方法的稳健性,我们从包含 100 万篇研究论文的庞大语料库中提取了数据。我们的方法采用监督训练模式,利用标注数据的力量来指导模型的学习。
我们在图 4.12 和图 4.13 中展示了两个生成案例。这些图展示了模型根据新的测试数据
在新测试数据的基础上生成连贯、相关的标题和摘要的能力,凸显了我们的方法在帮助学术界方面的潜力。
5 Conclusion
在本技术报告中,我们阐述了我们在学术研究领域取得的两项主要进展。首先,我们介绍了专为学术研究定制的 LLM AcademicGPT。它在 1200 亿个代币上进行了训练,彰显了大量学术数据集的潜力,确保了在把握科学奥妙方面的高度精确性。其次,我们将AcademicGPT的能力进一步应用到一系列应用中,从细致入微的通用学术问答系统到人工智能辅助阅读和内容创建。我们的问答工具借助 ReAct 框架,通过保持上下文来丰富学术对话。此外,我们在简化高密度学术文本和审阅论文方面的举措,也将人工智能定位为研究人员不可或缺的工具。值得注意的是,我们的人工智能在内容生成(如摘要)方面展现出的适应性突出了它的多功能性。总之,AcademicGPT 及其相关应用代表了将先进的人工智能技术与学术研究需求相结合的一次飞跃。通过这些努力,我们预计学术领域的信息处理、交互和生成方式将发生重大转变。