在一个社交媒体平台赋予用户成为内容创作者力量的时代,数字领域见证了前所未有的信息传播激增,到2023年,近82%的互联网流量是视频内容。因此,像抖音和YouTub这样的平台已经成为主要的信息来源。一个显著的统计数据凸显了这些平台的巨大影响:仅在YouTube上,用户每天就共同观看超过十亿小时的视频内容。++++视频内容的病毒性质是一把双刃剑:它促进了新闻的快速传播,同时也加速了有害言论的传播。++++
我们推荐一个先进的多模态多任务框架,用于视频内容中的毒性检测,利用大型语言模型(LLMs),并结合了进行情感和严重性分析的附加任务。ToxVidLLM结合了三个关键模块------编码器模块、跨模态同步模块和多任务模块------构建了一个为复杂视频分类任务定制的通用多模态LLM。
1 有害代码混合多模态(ToxCMM)数据集
选择YouTube作为主要数据源,++++重点是代码混合语言对话,主要是印地语和英语++++ 。为了收集相关内容,我们使用YouTube API抓取印度网络系列和印地语"烤"视频,将下载的视频细分为更小的子视频,以便在句子级别进行注释,并最大化包含有害内容。数据集包含931个视频,采用印地语-英语代码混合格式。
++++使用了配置有OpenAI库中单词时间戳的Whisper转录模型为每个视频生成文字转录++++ 。然后我们通过手动删除由于语音中断或结巴导致不清楚的单词和符号来提高文字转录的质量。从视频中提取单个话语涉及记录它们的开始和结束时间。
1.1 数据注释
为了更好地阐明注释过程,我们将注释部分分为两个子部分:(i) 注释培训和(ii) 主要注释。注释培训:三位博士学者监督注释过程,他们精通有害和冒犯内容,实际注释由三位精通印地语和英语的本科生进行。
++++数据集++++ ++++考虑了两个毒性类别(非毒性/毒性)、三个情感类别(积极/中立/消极)以及每个视频样本的严重性得分在三点量表上(0、1、2)++++ 。得分0表示没有毒性迹象,1表示帖子包含毒性迹象,但并不严重,2分表示帖子包含强有力的毒性证据(例如,身体威胁或兴奋自杀)。
1.2 数据集统计
数据集总共包含4021个话语,其中1697个被归类为有害,其余2324个被标记为非有害。ToxCMM数据集的类别统计数据如表1所示。该数据集中的每个话语平均包含8.68个单词,平均持续时间为8.89秒。平均而言,数据集中的每个话语包含约68.20%的印地语单词,这意味着超过三分之二的单词是印地语,其余的单词是英语。
2 方法论
给定一个表示为V的话语视频片段,++++我们的任务基本上是一个分类问题++++ ++++,++++ ++++目标是确定视频是否包含有害内容,以及为其分配情感和严重性标签++++ 。每个视频V表示为一系列帧F = {f1, f2, ... fn},附带相关的音频A,以及视频的文字转录T = {w1, w2, ... wm},由一系列单词组成,构建一个基于深度学习的视频分类器,表示为C:C(T; F; A) → y,其中y表示给定任务的视频的实际标签。我们将基于LLM的多模态多任务框架ToxVidLLM划分为三个不同的组件:即编码器模块、跨模态同步模块和多任务模块。
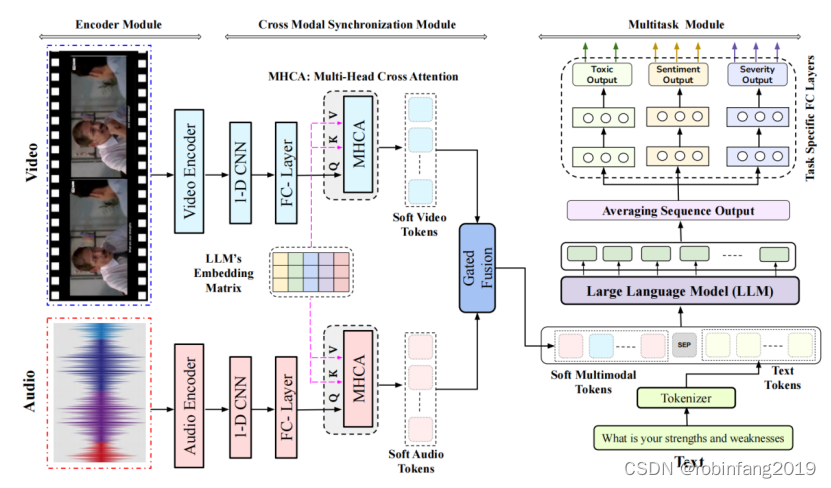
2.1 编码器模块
2.1.1 文本编码器
模型选择: 在 HingBERT 模型系列中进行实验,包括 HingMBERT、HingRoBERTa、HingGPT 和 IndicBERT。HingBERT 系列模型专门针对印地语和英语混合语(Hinglish)进行预训练,能够有效地处理混合语言文本。
作用: 将视频字幕中的文本转换为嵌入表示,捕捉文本内容的语义信息。
2.1.2 音频编码器
模型选择: 使用两个最先进的(SOTA)模型,即Whisper和MMS。
- Whisper: 由 OpenAI 开发,是一个多语言语音识别模型,在大型音频数据集上进行训练,能够有效地识别和理解语音内容。
- MMS (Massively Multilingual Speech): 由 Facebook AI 开发,是一个用于语音识别的预训练模型,能够在多种语言上进行训练和使用。
作用: 将视频中的音频信号转换为嵌入表示,捕捉语音内容的信息,例如说话人的语气、语调等。
2.1.3 视频编码器
模型选择: 使用了两个基于 Transformer 的视频模型:VideoMAE 和 Timesformer。
- VideoMAE: 使用掩码自编码器进行自监督视频预训练,能够有效地捕捉视频中的时空信息。
- Timesformer: 将 Transformer 架构扩展到视频理解任务,能够有效地捕捉视频中的时间关系。
作用: 将视频帧转换为嵌入表示,捕捉视频内容的信息,例如场景、动作、表情等。
2.2 跨模态同步模块
++++跨模态同步模块是 ToxVidLLM 模型中至关重要的一环,它负责将来自不同模态(视频、音频、文本)的特征进行对齐++++ ,以便更好地融合信息并提升毒性检测的性能。
2.2.1 编码阶段
首先,使用预训练模型分别对视频和音频进行编码,提取其特征表示:
- 视频编码: 使用 VideoMAE 或 Timesformer 等模型,捕捉视频中的空间和时间信息。
- 音频编码: 使用 Whisper 或 MMS 等模型,提取音频信号中的语义信息。
经过编码后,视频和音频的特征表示分别记为 Zv 和 Za。
2.2.2 抽象特征提取
为了降低计算成本并限制前缀中的 token 数量,使用 1 维卷积层 (Conv) 对 Zv 和 Za 进行压缩,使其长度缩短到固定的值 SL'。
接着,使用全连接层 (FC) 调整特征维度,使其与 LLM 的 token 嵌入矩阵维度 dt 相匹配。
经过抽象特征提取后,视频和音频的特征表示分别记为 Cv 和 Ca。
2.2.3 多头交叉注意力 (MHCA)
为了将视频和音频的特征表示与文本特征表示对齐,使用 MHCA 机制。
MHCA 机制将 Cv 和 Ca 作为 Query (Q),将文本特征表示 Et 作为 Key (K) 和 Value (V)。
通过比较 Q 和 K,计算注意力权重,并使用加权求和的方式更新 Q,从而将视频和音频的特征表示映射到文本嵌入空间。
经过 MHCA 处理后,视频和音频的特征表示分别记为 Csv 和 Csa。
2.2.4 门控融合
为了更好地融合视频和音频的特征,使用门控融合策略。
门控融合通过学习权重矩阵 Pv 和 Pa,以及标量偏置 bg,将 Csa 和 Csv 进行线性组合。
2.3 多任务模块
++++任务模块是 ToxVidLLM 模型中的核心部分,它负责同时进行毒性检测、严重程度分析和情感分析三个任务++++ 。
2.3.1 输入
多任务模块的输入包括来自跨模态同步模块的融合特征表示 Jva,以及文本特征表示 Et。
为了更好地融合文本和融合特征,将 Jva 和 Et 通过特殊 token SEP 进行连接,形成一个多模态输入序列。
2.3.2 LLM 处理
使用预训练的 LLM 模型(如 HingRoberta 或 HingGPT)对多模态输入序列进行处理。
LLM 模型会生成一个序列输出,每个 token 对应一个向量表示。
2.3.3 任务特定层
将 LLM 的序列输出进行平均池化,得到一个全局特征表示。
将全局特征表示分别输入到三个任务特定的全连接层,每个层对应一个任务(毒性检测、严重程度分析、情感分析)。
每个任务特定层会输出一个向量表示,该向量包含了该任务所需的信息。
2.3.4 输出层
将三个任务特定层的输出分别输入到输出层,进行 softmax 操作,得到三个任务的预测概率分布。
最终,根据预测概率分布,可以得到每个视频的毒性标签、严重程度标签和情感标签。
2.4 加权交叉熵损失函数
ToxVidLLM 模型进行了多任务学习,同时进行毒性检测、严重程度分析和情感分析三个任务。为了平衡不同任务之间的权重,使用了加权交叉熵损失函数:Loss_f = ∑(β_k * Loss_k)
- Loss_f 表示最终的损失值。
- Loss_k 表示第 k 个任务的交叉熵损失值。
- β_k 表示第 k 个任务的权重,由模型在训练过程中学习得到。用于控制不同任务对最终损失的贡献程度。例如,如果毒性检测任务比其他任务更重要,可以将 β_k 设置得更高,从而使模型在训练过程中更加关注毒性检测任务的预测精度。
3 结论
3.1 模态编码器选择
在音频编码器方面,++++Whisper 模型在所有实验设置中均优于 MMS 模型++++ ,证明了其在处理音频数据方面的优越性能。
在视频编码器方面,++++VideoMAE 模型在所有实验设置中均优于 TimeSformer 模型++++ ,证明了其在提取视频特征方面的有效性。
在文本编码器方面,++++HingRoBERTa 模型在所有实验设置中均优于其他模型++++ ,证明了其在处理 Hindi-English 混合代码文本方面的优势。
3.2 单模态、双模态和三模态的比较
- 单模态实验表明,++++文本模态在毒性检测任务中始终优于视频和音频模态++++ ,突出了文本信息在视频毒性检测中的重要性。
- 双模态实验表明,++++文本+音频配置始终优于其他两种组合++++ ,证明了音频信息对毒性检测任务的补充作用。
- 三模态实验表明,++++三模态配置在所有任务中都取得了最佳性能++++ ,证明了文本、音频和视频信息在视频毒性检测中的互补作用。
3.3 ToxVidLLM 模型的优势
- ToxVidLLM 模型在所有实验中都显著优于基线模型,证明了其有效性。
- ToxVidLLM 模型的多任务学习机制能够有效提升毒性检测任务的性能。
- ToxVidLLM 模型的 MHCA 和门控融合机制能够有效地融合不同模态的特征,从而提升模型的性能。
4 相关知识
4.1 MHCA 进行跨模态同步
ToxVidLLM 模型选择使用 MHCA 进行跨模态同步,而不是其他方法,主要基于以下几个原因:
4.1.1 文本信息的重要性
在视频内容中,文本信息往往比音频和视频信息更能直接反映说话者的意图和情绪。
MHCA 可以有效地将文本信息作为引导,帮助模型理解和融合其他模态的信息。
4.1.2 统一表示空间
MHCA 可以通过计算不同模态之间的注意力权重,将它们映射到一个统一的表示空间中。
这有助于模型在不同模态之间建立关联,并更准确地识别毒性内容。
4.1.3 优于其他方法
++++与简单的拼接方法相比,MHCA 可以避免模态信息之间的冲突,并赋予不同模态不同的权重。++++
++++与其他注意力机制相比,MHCA 可以更有效地捕获不同模态之间的长期依赖关系。++++
4.1.4 实验验证
在 ToxVidLLM 的消融研究中,移除 MHCA 模块会导致模型性能显著下降,这进一步证明了 MHCA 在跨模态同步中的重要性。