1.2什么是数据挖掘
数据挖掘是从大量数据中挖掘有趣模式和知识的过程。
数据源包括数据库、数据仓库、Web、其他信息存储库或动态地流入系统的数据。
- 数据清理(消除噪声和删除不一致数据)
- 数据集成(多种数据源可以组合在一起)
- 数据选择(从数据库中提取与分析任务相关的数据)
- 数据变化(通过汇总或聚焦操作,把数据变换和统一成适合挖掘的形式)
- 数据挖掘(基本步骤,使用智能方法提取数据模式)
- 模式评估(根据某种兴趣度量度,识别知识的真正有趣模式)
- 知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)
1.3数据仓库
数据仓库是一个从多个数据源收集的信息存储库
特点
- 面向主题
- 集成的数据
- 不可更新
- 随时间不断变化
数据立方体
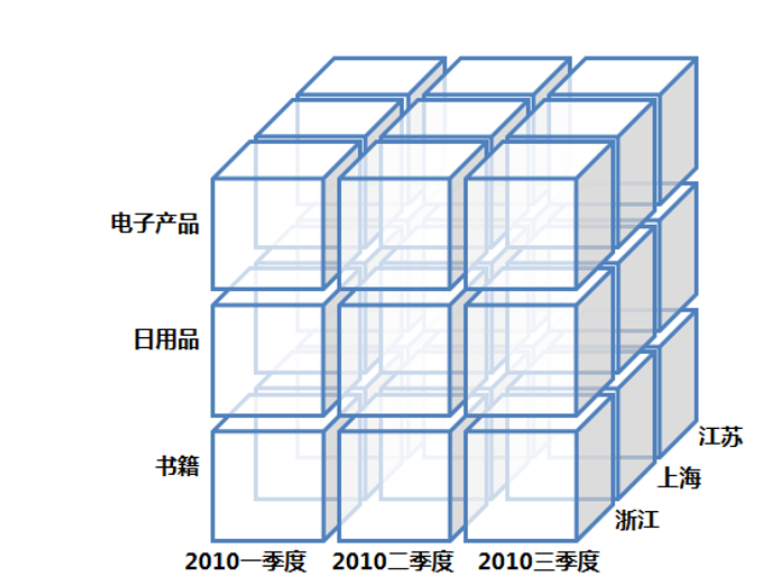
OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以上面的数据立方体为例来逐一解释下:
钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据。
比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市......这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合。
如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
1.4可以挖掘什么类型的模式
类/概念描述:特征化与区分
1. 数据特征化
对同类的数据进行汇总,输出方式为饼图、条图等
2. 数据区分
将两个同一属性但不同值的对象进行比较
挖掘频繁模式、关联和相关性
模式
- 频繁项集:频繁出现的东西
- 频繁子序列:顾客倾向购买电脑然后购买鼠标
- 频繁子结构:子结构有不同的结构形式
关联
- 单维关联规则:x->z
- 多维关联规则:x,y->z
相关性
属性-值
用于预测分析的分类与回归(了解)
决策树、神经网络、相关分析
聚类分析
聚类是根据类内事物的相似性最大、类间事物的相似性最小的原则把数据对象进行聚类或分组
聚类与分类不同,它们的区别如下:
- 分类需要训练数据集,属于有监督的学习;而聚类不需要训练数据集,属于无监督的学习。
- 在进行分类以前,已知道数据的分类情况;而进行聚类以前,对目标数据的分类情况一无所知。常用的聚类方法包括统计分析方法、机器学习方法、神经网络方法等
离群点分析
异常
所有模式都是有趣的吗
数据挖掘的知识有三个重要问题需要回答:
- 什么样的模式是有价值(感兴趣)的?价值度量
- 挖掘系统能产生所有有价值的模式吗?算法的完全性问题
- 数据挖掘到的模式是否都是有价值的知识?优化问题