AIGC专栏11------EasyAnimateV2结构详解与Lora训练 最大支持768x768 144帧视频生成
- 学习前言
- 源码下载地址
- EasyAnimate V2简介
-
- 技术储备
-
- Diffusion Transformer (DiT)
- Motion Module
- U-VIT
- Lora
- 算法细节
-
- 算法组成
- 视频VAE
- 视频DIT
- 数据处理
-
- 视频分割
- 视频筛选
- 视频描述
- 模型训练
-
- 视频VAE
- 视频DIT
- EasyAnimate V2的Lora训练
-
- 数据集准备
- 训练sh文件修改
- 开始训练
- 训练结果预测
学习前言
研究了好长时间的文生视频,EasyAnimate到了V2版本,我们将vae修改成了magvit,同时支持图片和视频的训练与预测,另外还引入了U-vit提高训练的稳定性并加快收敛。
现在EasyAnimate最大支持768x768 144帧的视频生成,FPS为24,最长6秒。本文主要进行EasyAnimateV2的 算法详解,并且介绍一下如何通过EasyAnimate训练自己的Lora 。

源码下载地址
https://github.com/aigc-apps/EasyAnimate
感谢大家的关注。
EasyAnimate V2简介
技术储备
Diffusion Transformer (DiT)
DiT基于扩散模型,所以不免包含不断去噪的过程,如果是图生图的话,还有不断加噪的过程,此时离不开DDPM那张老图,如下:
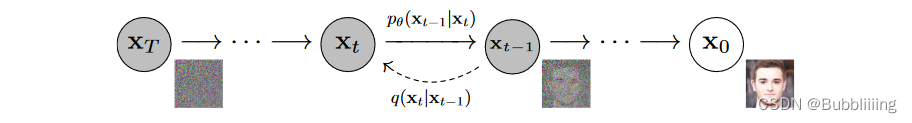
DiT相比于DDPM,使用了更快的采样器,也使用了更大的分辨率,与Stable Diffusion一样使用了隐空间的扩散,但可能更偏研究性质一些,没有使用非常大的数据集进行预训练,只使用了imagenet进行预训练。
与Stable Diffusion不同的是,DiT的网络结构完全由Transformer组成,没有Unet中大量的上下采样,结构更为简单清晰。
在EasyAnimate中,我们将Motion Module网格化后引入到DIT中,借助DIT的强大生成能力,生成视频效果也还不错。
Motion Module
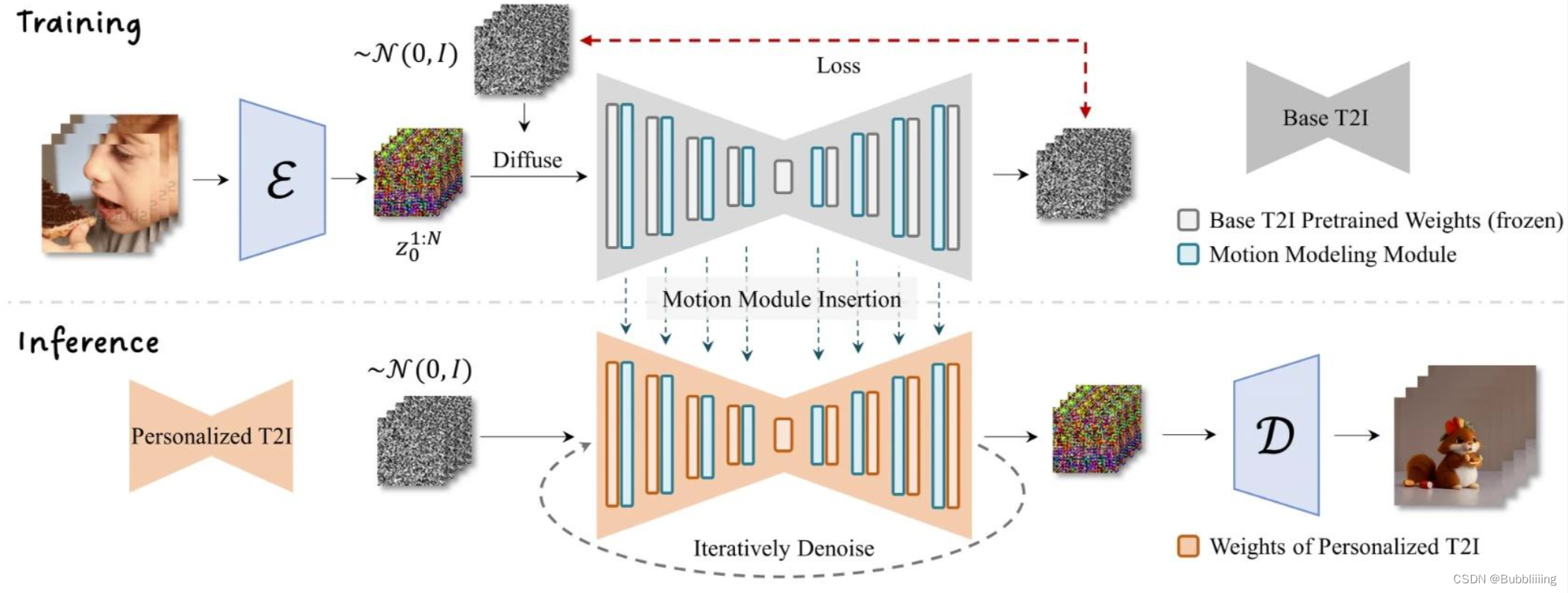
AnimateDiff是一个可以对文生图模型进行动画处理的实用框架,其内部设计的Motion Module无需进行特定模型调整,即可一次性为大多数现有的个性化文本转图像模型提供动画化能力。
EasyAnimate参考AnimateDiff使用Motion Module保证视频的连续性。
Motion Module只关注特征点在时间轴上的特征信息,以提炼出合理的运动先验,在AnimateDiff中只更新了运动模块的参数,所以Motion Module是一个可插入的结构,可以用在不同的微调backbone中。
在EasyAnimate中,为了更好的生成效果,我们将backbone连同motion module一起finetune,同时联合图片和视频一起finetune。在一个pipeline中即实现了图片的生成,也实现了视频的生成。
U-VIT
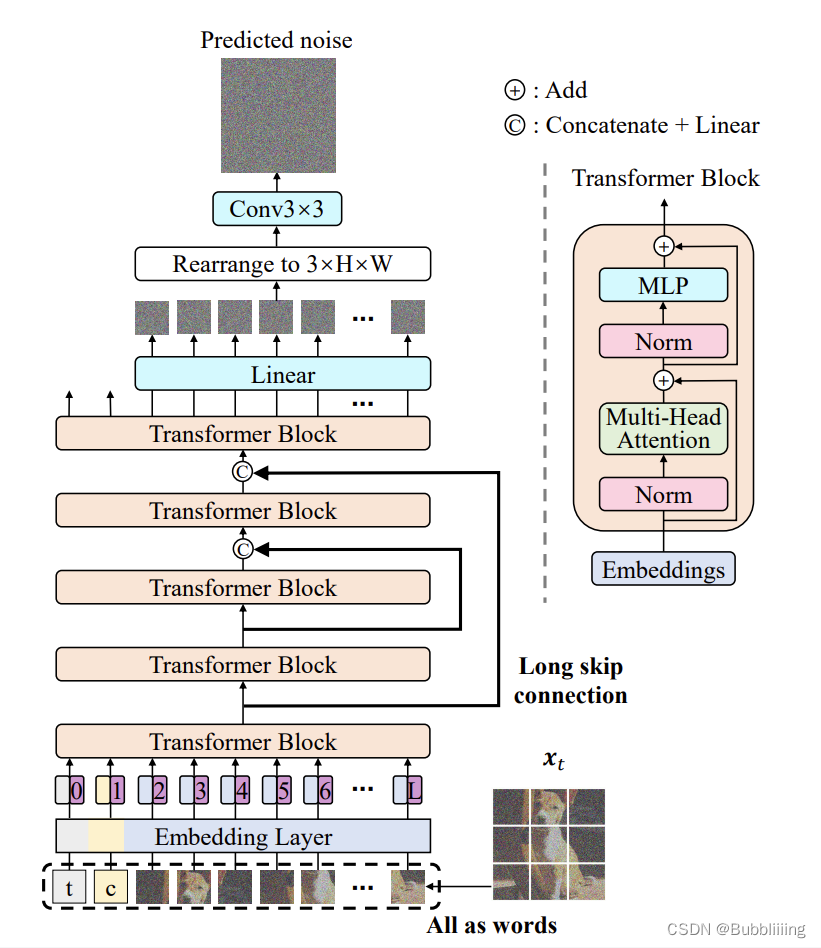
在训练过程中,我们发现纯DIT结构在训练视频时不算稳定,经常存在损失突然上升的情况,并且由于视频的特征层较大,拟合速度较慢。
参考U-vit,我们将跳连接结构引入到EasyAnimate当中,通过引入浅层特征进一步优化深层特征,并且我们0初始化了一个全连接层给每一个跳连接结构,使其可以作为一个可插入模块应用到之前已经训练的还不错的DIT中。
Lora
由《LoRA: Low-Rank Adaptation of Large Language Models》 提出的一种基于低秩矩阵的对大参数模型进行少量参数微调训练的方法,广泛引用在各种大模型的下游使用中。
EasyAnimate有良好的拓展性,我们可以对文生图模型训练Lora后应用到文生视频模型中。
算法细节
算法组成
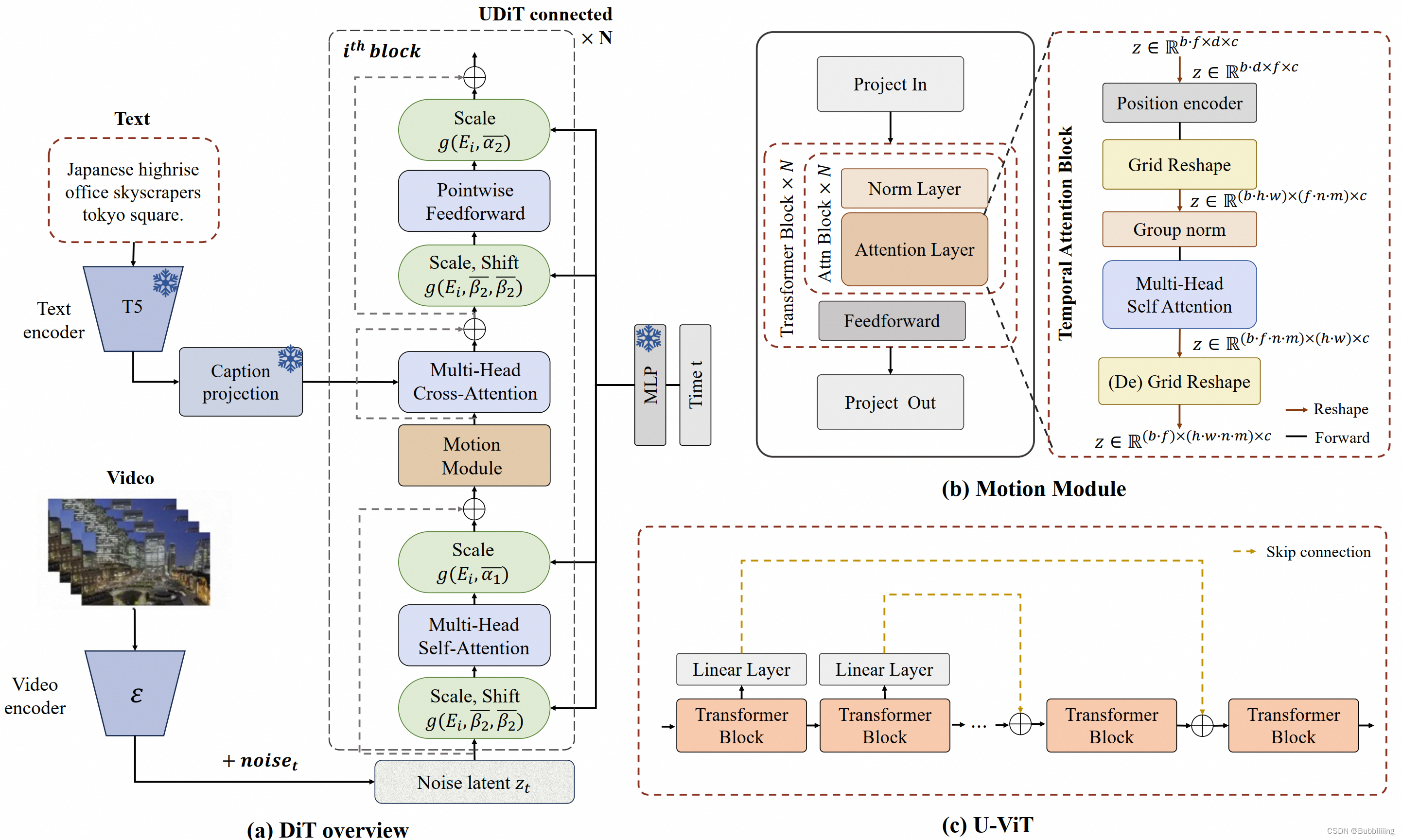
我们使用了PixArt-alpha作为基础模型,并在此基础上引入额外的运动模块(motion module)来将DiT模型从2D图像生成扩展到3D视频生成上来。其框架图如下:
下图概述了EasyAnimate的管道。它包括Text Encoder、Video VAE(视频编码器和视频解码器)和Diffusion Transformer(DiT)。T5 Encoder用作文本编码器。其他组件将在以下部分中详细说明。
视频VAE
在早期的研究中,基于图像的VAE已被广泛用于视频帧的编码和解码,如AnimateDiff、ModelScope2V和OpenSora。在Stable Dif fusion使用VAE实现将每个视频帧编码为单独的潜在特征,从而将帧的空间维度显著缩小到宽度和高度的八分之一。但这种编码技术忽略了时间信息,将视频降级为静态图像表示。
传统的基于图像的VAE的一个显著问题是它无法在时间维度上进行压缩 ,这不仅无法关注到细微的帧间信息 ,并且导致潜在的latent的shape很大 ,进一步导致GPU VRAM的激增。这些挑战严重阻碍了这种方法在长视频创作中的实用性。因此,视频VAE的挑战在于如何有效地压缩时间维度。
此外,我们的同时需要使用图像和视频对VAE进行训练。先前的研究表明,将图像集成到视频训练Pipeline中可以更有效地优化模型架构,从而改进其文本对齐并提高输出质量。
视频VAE的一个著名例子是MagViT,大家均认为其被用于Sora框架。我们最初在EasyAnimate中采用MagViT。它采用Casual 3D Conv。在使用普通3D Conv之前,该块在时间轴前引入填充,从而确保每一帧可以利用它先前的信息来增强因果关系,同时不考虑到后帧的影响 。另外MagViT还允许模型同时处理图像和视频。尽管它在视频编码和解码方面很优雅,但在超长视频序列上进行训练时,它仍面临挑战,这主要是GPU VRAM的限制。当视频增大时,MagViT所需的内存往往甚至超过A100 GPU的可用内存 ,这使得对大视频(例如1024x1024x40)进行一步解码变得不可行。这个挑战突出了分批处理的必要性,它有助于增量解码,而不是试图一步解码整个序列。
对于分批处理,我们首先在空间维度上(宽度和高度上)试验切片机制。然而,这可能导致一个视频不同块上有不一致的光照 。随后,我们转向沿时间维度(时间上)进行切片。通过这种方法,一组视频帧被分为几个部分,每个部分都被单独编码和解码,如图所示。但由于MagViT的独特机制,3D Conv前需要进行前向填充,对应的潜在latent中,每个部分的第一个latent由于填充特征仅包含较少的信息。这种不均匀的信息分布是一个可能阻碍模型优化的方面 。此外,MagViT使用这种批处理策略还影响处理过程中视频的压缩率。
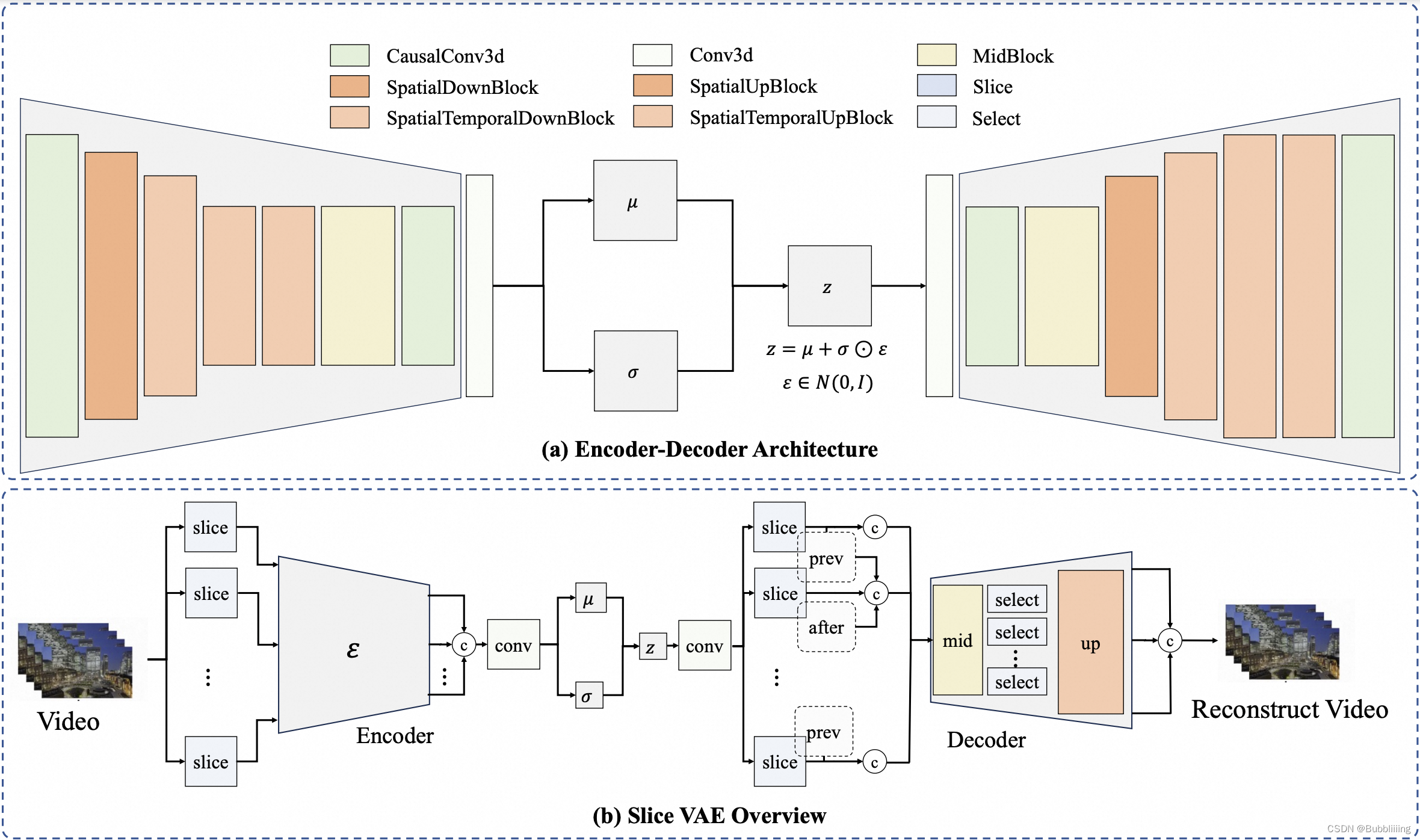
在这个基础上,我们提出了Slice VAE,该VAE在面临不同输入时使用不同的处理策略,当输入的是视频帧时,则在高宽与时间轴上进行压缩 ,当输入为512x512x8的视频帧时,将其压缩为64x64x2的潜在latent ;当输入的是图片时,则仅仅在高宽上进行压缩,当输入为512x512的图片时,将其压缩为64x64x1的潜在latent。
为了进一步提高解码的性能,我们在不同的时间轴批次之间实现特征共享 ,如图(b)所示。在解码过程中,特征与它们的前一个和后一个特征相连 ,从而产生更一致的特征并实现比MagViT更高的压缩率。通过这种方式,编码的特征封装了时间信息,这反过来又节省了计算资源,同时提高了生成结果的质量。
视频DIT
参考AnimateDiff,我们设计了Motion Module运动模块,运动模块专门设计用于嵌入时间信息。通过在时间维度上集成注意力机制,该模型获得了时间轴上的先验知识,这对生成视频运动至关重要。
另外,我们在EasyAnimateV2中引入了U-VIT,在训练过程中,我们观察到深层DIT的训练经常是不稳定的,模型的损失有时候会从0.05急剧增加到0.2,最终增加到1.0。为了加强模型优化过程,避免DIT层反向传播过程中的梯度坍塌,我们在相应的Transform Block之间使用了跳连接,这种基于UNet的框架对于Stable Diffusion模型来说是有效的。为了将这种修改无缝集成到现有的扩散变换器架构中,而无需进行全面的再训练,我们初始化了几个具有零填充权重的完全连接层,如上图(c)中的灰色块。
数据处理
对于大模型而言,数据准备很多时候比模型本身更加重要,EasyAnimate的训练包括图像数据和视频数据。下文详细介绍了视频数据处理方法,包括三个主要阶段:视频分割、视频过滤和视频描述。
这些步骤对于挑选具有详细描述的高质量视频数据至关重要。
视频分割
对于较长的视频分割,我们使用PySceneDetect以识别视频内的场景变化 并基于这些转换,根据一定的门限值来执行场景剪切,以确保视频片段的主题一致性。切割后,我们只保留长度在3到10秒之间的片段用于模型训练。
视频筛选
我们从三个方面对视频数据进行过滤,即运动过滤、文本过滤和美学过滤。
运动过滤 :在视频生成模型的训练过程中,确保视频显示运动感,将其与静态图像区分开来 ,这一点至关重要。同时,保持动作的一致性至关重要,因为过于不稳定的动作会削弱视频的整体稳定性 。为此,我们利用RAFT以指定的每秒帧数(FPS)计算帧之间的运动分数,并用合适的运动分数对视频进行滤波,以微调动态。
文本过滤 :视频数据往往包含特定的文本信息(如字幕) ,这不利于视频模型的学习过程。为了解决这个问题,我们使用光学字符识别(OCR)来确定视频中文本区域的比例面积。对采样的帧进行OCR以表示视频的文本分数。然后,我们过滤掉文本所占区域超过视频帧1%的任何视频片段,确保剩余视频对模型训练保持最佳状态。
美学过滤 :此外,互联网上有许多低质量的视频。这些视频可能缺乏主题焦点,或者过于模糊。为了提高我们训练数据集的质量,我们基于improved-aesthetic-predictor计算了美学分数并保存高分视频,为我们的视频生成获得视觉吸引力的训练集。
视频描述
视频字幕的质量直接影响生成视频的结果。我们对几种大型多式联运模型进行了全面比较,权衡了它们的性能和运营效率。经过仔细考虑和评估,我们选择VideoChat2和VILA作为视频数据字幕的任务,因为它们在我们的评估中表现出了卓越的性能,表明它们在实现具有细节和时间信息的视频字幕方面特别有前景。
模型训练
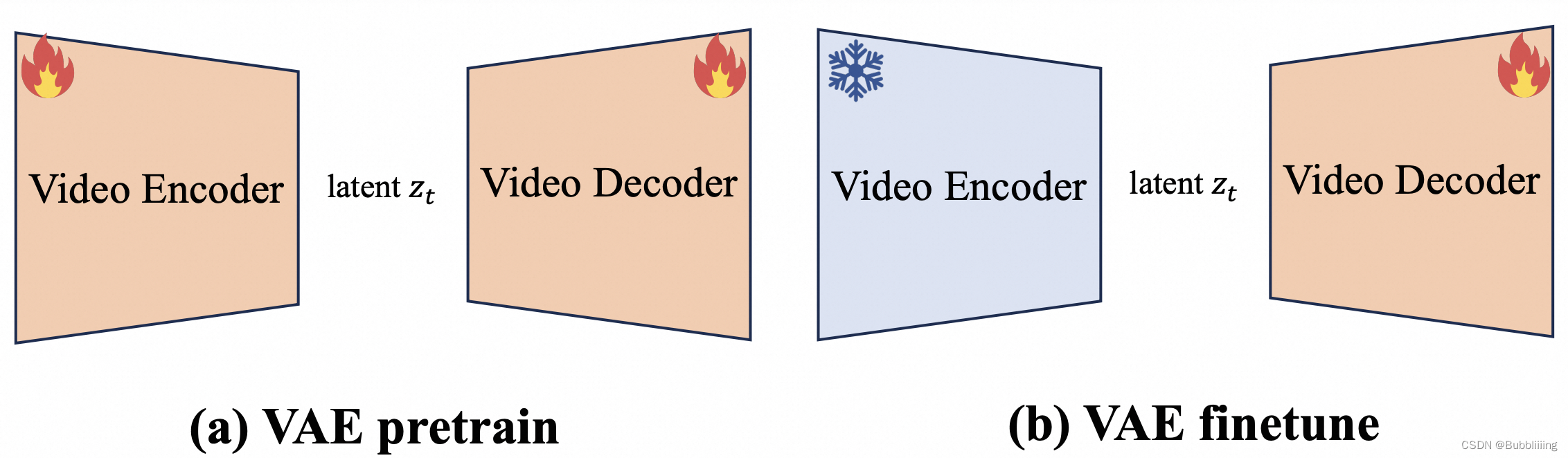
总共,我们使用大约1200万个图像和视频数据来训练视频VAE模型和DiT模型。我们首先训练视频VAE,然后使用三阶段粗到细训练策略将DiT模型适应于新的VAE。
视频VAE
MagViT:我们使用了β=(0.5,0.9)、学习率为1e-4的Adam优化器进行训练,总共训练了350k个步骤。我们的总批量是128。
Slice VAE:我们根据上述MagViT初始化Slice VAE的权重。然后分两个阶段训练切片VAE。首先,我们在200k步内使用Adam优化器,β=(0.5,0.9),批量大小=96,学习率为1e-4训练整个VAE。接下来,参考Stable Diffusion的程序,我们只在100k步的第二阶段训练解码器,以更好地提高解码视频的保真度。
视频DIT
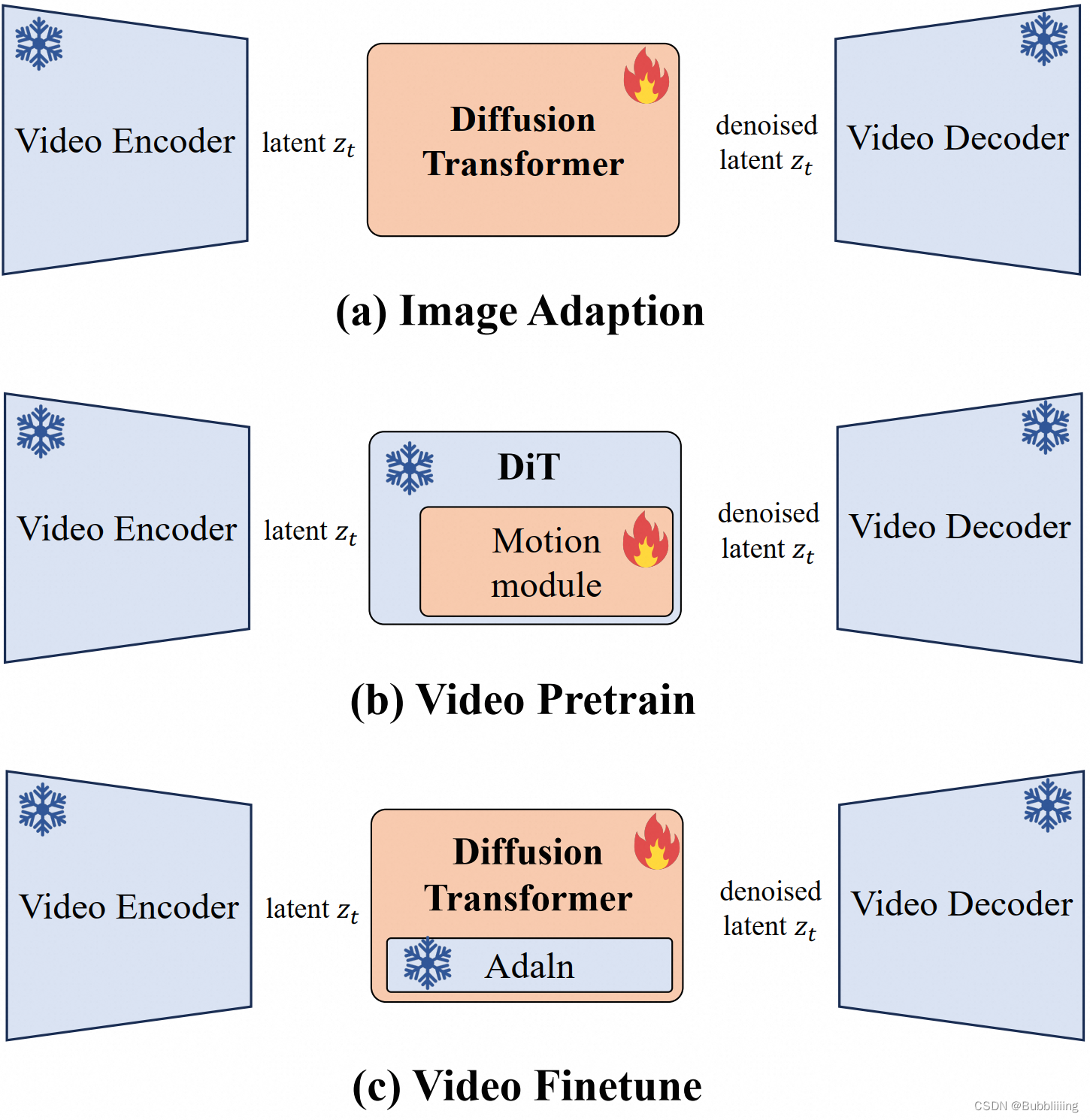
如图所示,dit模型的训练分为三个阶段。
最初,在引入新的视频VAE时,我们开始将DiT参数与该VAE对齐,此时仅使用图像数据。
随后,我们使用大规模视频数据集和图像数据来预训练运动模块(Motion Module),从而引入DiT的视频生成能力。在此处,我们引入了数据集分桶策略用于以不同的视频分辨率进行训练。目前,虽然该模型能够生成具有基本运动的视频,但输出的质量往往不太理想。
最后,我们使用高质量的视频数据来完善整个DiT模型,以增强其生成性能。
该模型是从较低分辨率到较高分辨率逐步训练的,这是节省GPU内存和减少计算时间的有效策略。
EasyAnimate V2的Lora训练
数据集准备
我们提供了一个可供EasyAnimate V2进行Lora训练的图文数据集。
这是一个人像的Minimalism极简风数据集,共包含约20张图片,其中demo如下所示:

数据集中已经提供了标注信息。我们可以将其放置在datasets目录下,如下图所示。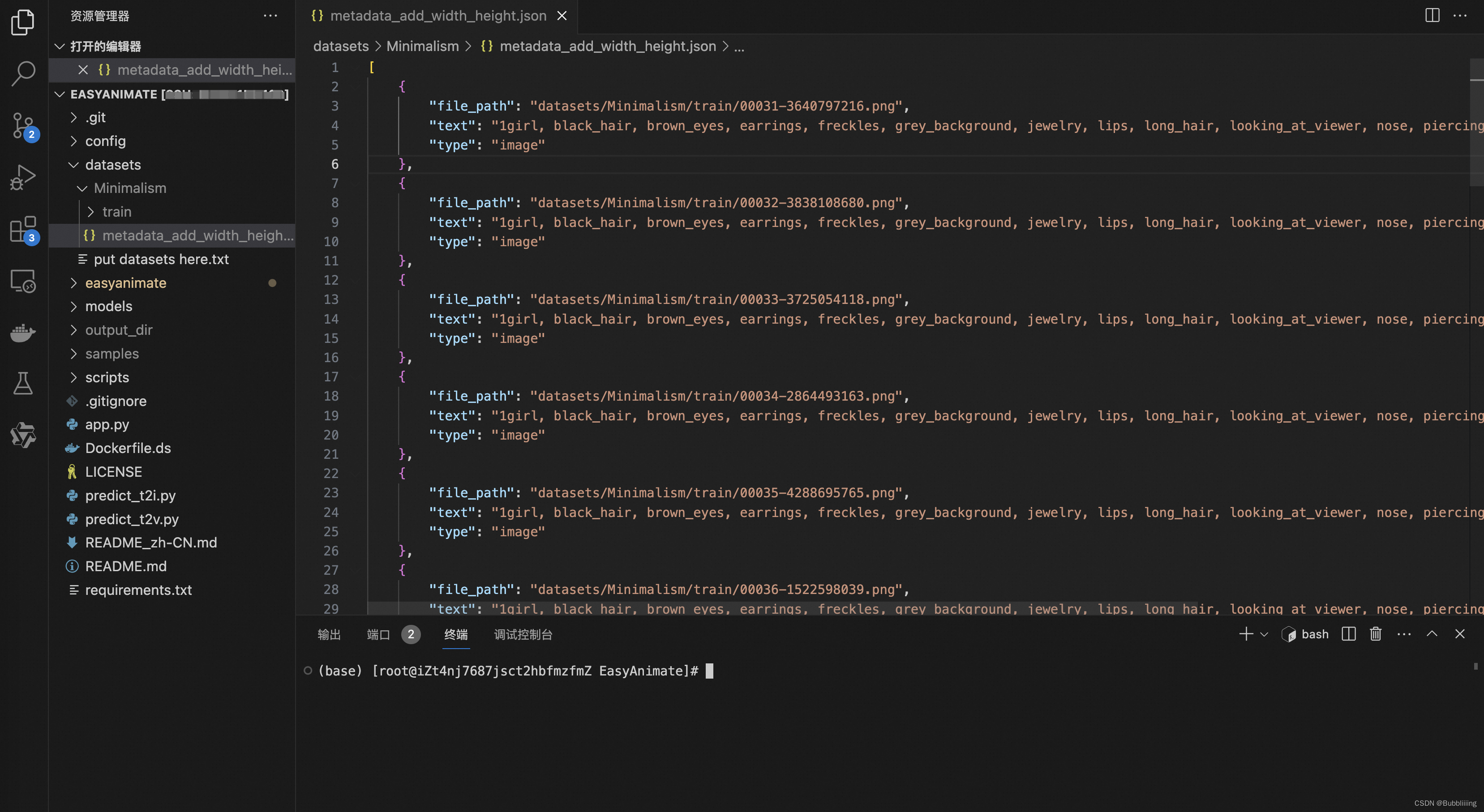
在这里我们即可使用相对路径也可以使用绝对路径,为了不同机器的使用方便,这里我使用了相对路径。
如果同学们期待使用自己的数据集进行训练,训练准备数据集json文件,数据集json文件的格式如下:
json
[
{
"file_path": "videos/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "train/00000001.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]其中,file_path指的是文件的路径,type指的是文件的种类,有video和image两种,text指的是视频对应的描述。
训练sh文件修改
训练Lora权重需要使用到scripts/train_t2iv_lora.sh文件,我们主要修改其中的DATASET_NAME和DATASET_META_NAME。
DATASET_NAME指向了数据集相对路径的根目录,以本文的摆放路径为例,直接指定EasyAnimate的根目录即可,即"./"
DATASET_META_NAME指向了数据集对应的json文件,指向Minimalism下的json文件,即"datasets/Minimalism/metadata_add_width_height.json"即可。
为满足更低的显卡需求,在这里我们开启low_vram减少显存需求,当前最低显存要求为24G,对应A10、3090、4090、4090D显卡。

开始训练
开始训练的流程较为简单,在配置好的环境下直接sh scripts/train_t2iv_lora.sh即可。

开始训练后如下所示:
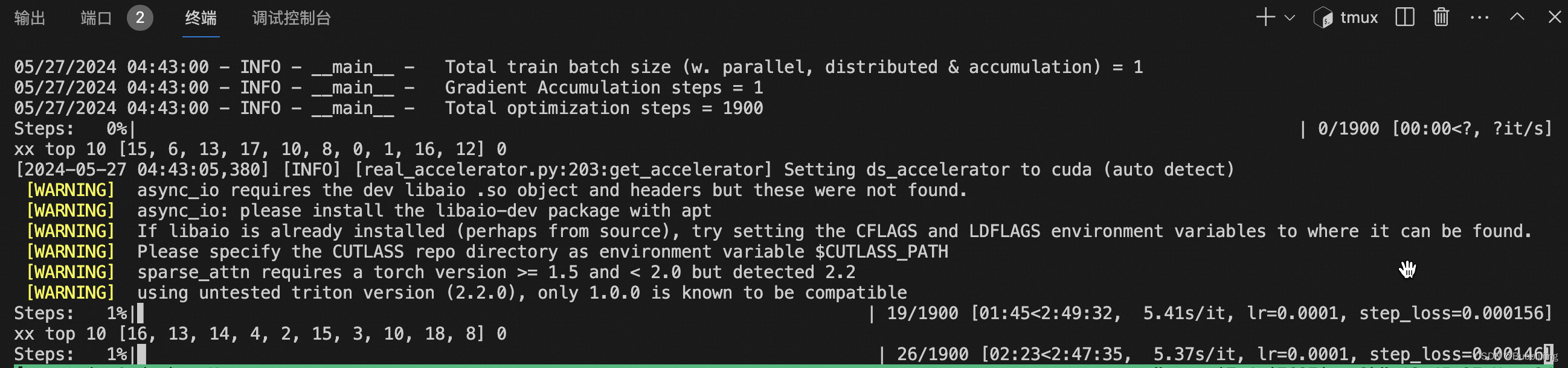
训练结果预测
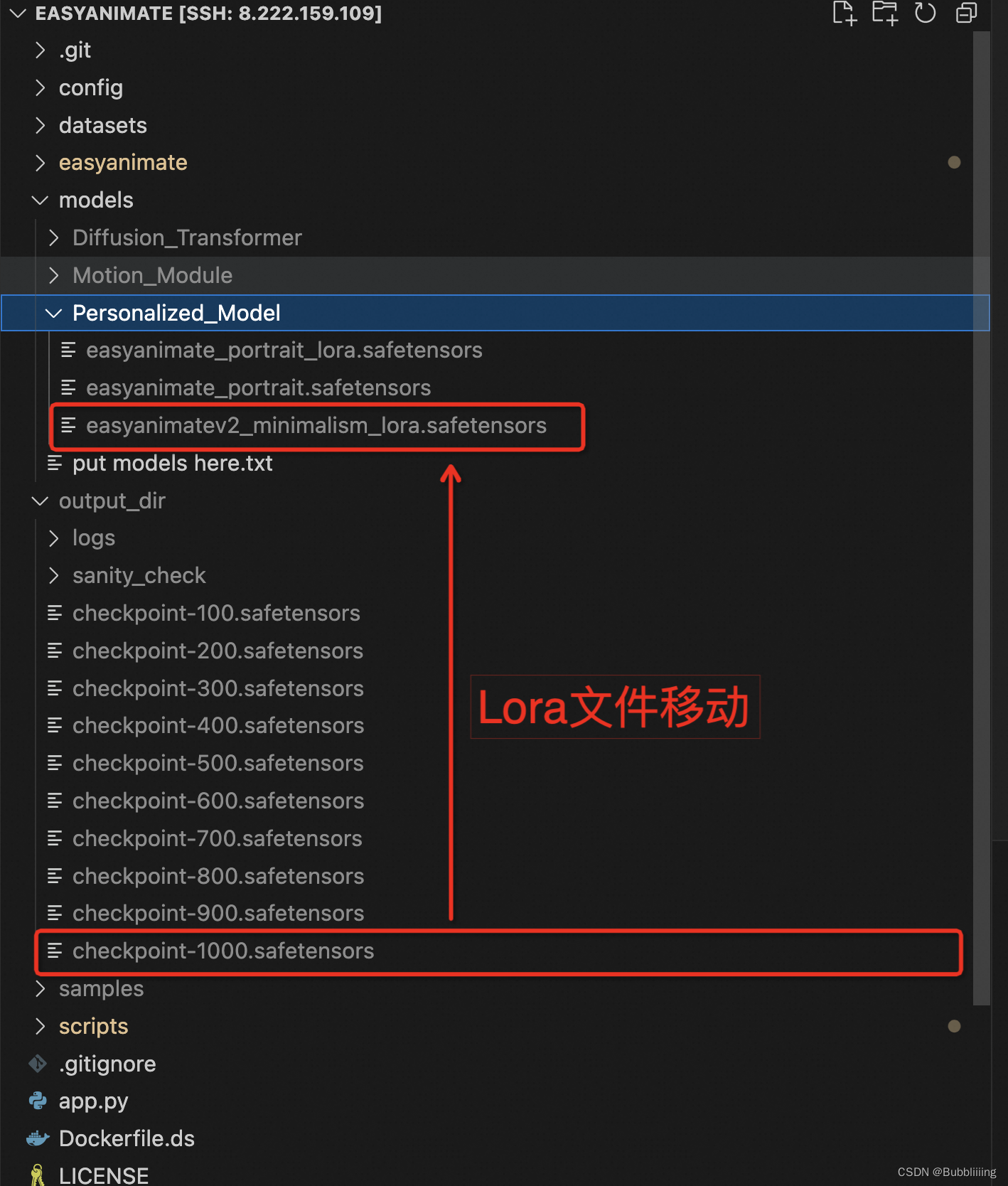
我们首先将训练好的Lora移动到指定的文件夹。
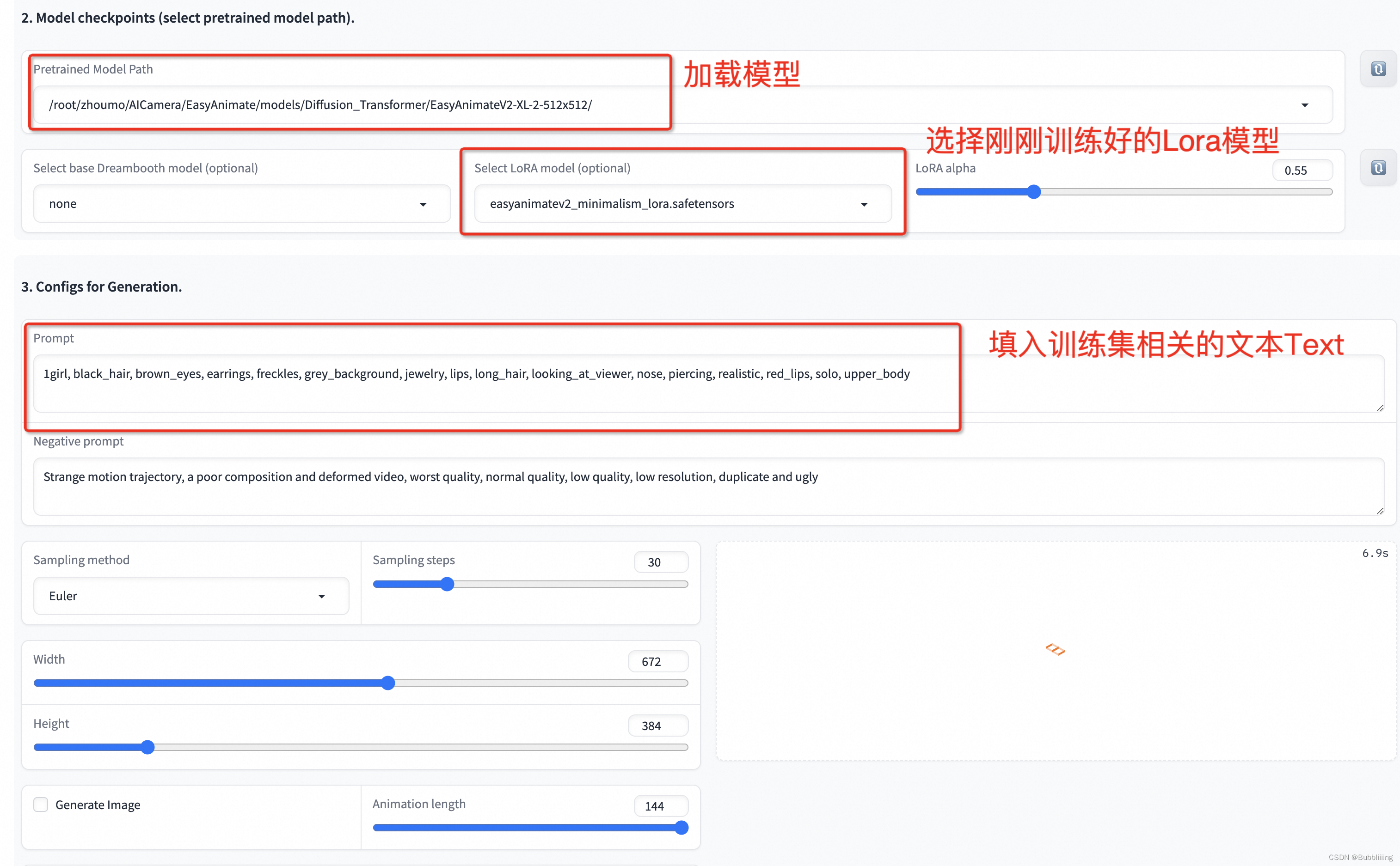
然后python app.py启动webui,在页面上进行选择。
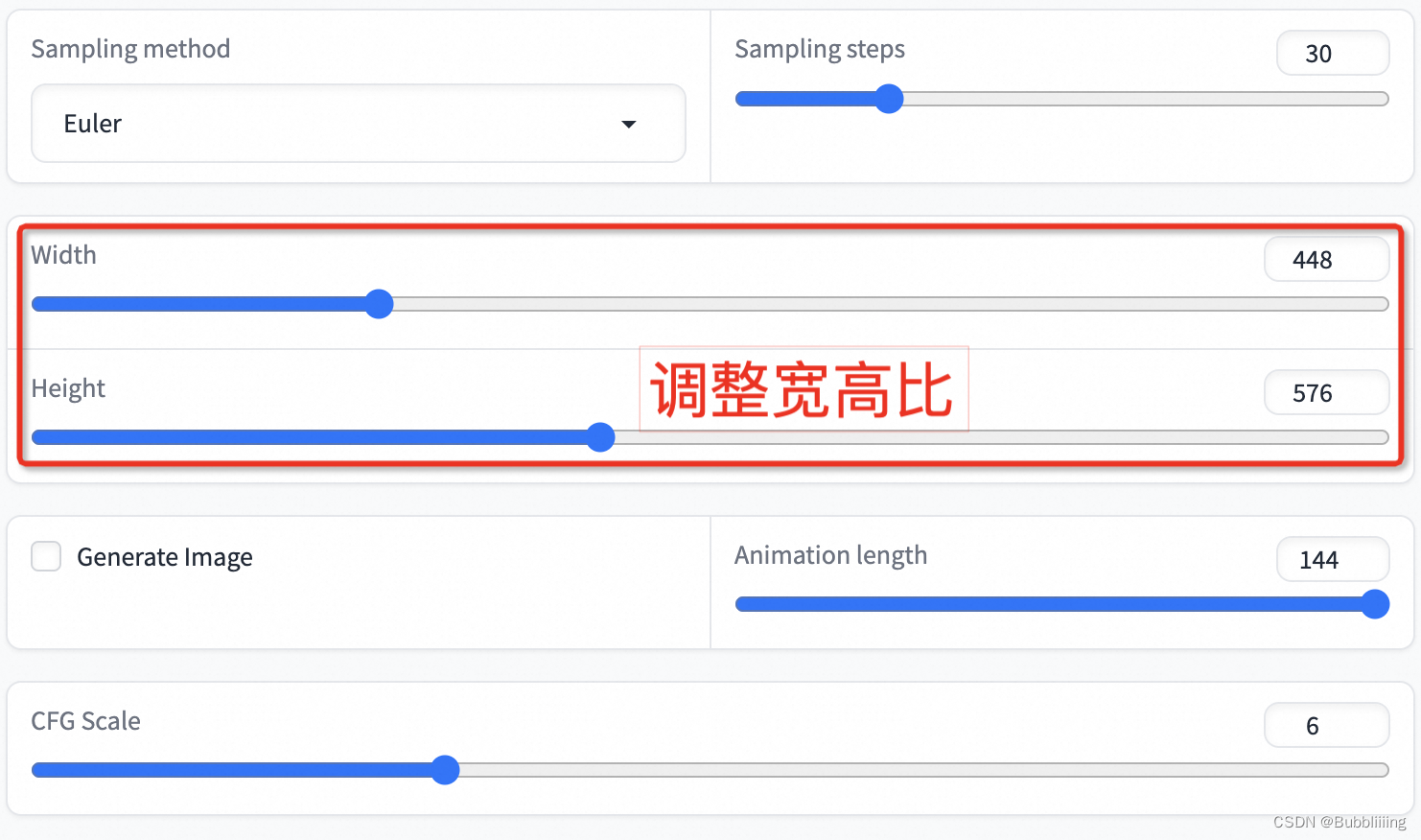
点击下方的生成即可获得结果。
生成结果