Stable diffusion prompts 使用语法、参数讲解、插件安装教程
本文基于 Stable diffusion WebUI 进行讲解(安装在 AutoDL 上,安装在本地电脑上的也同样适用本教程)。
初始界面:

文件目录结构:
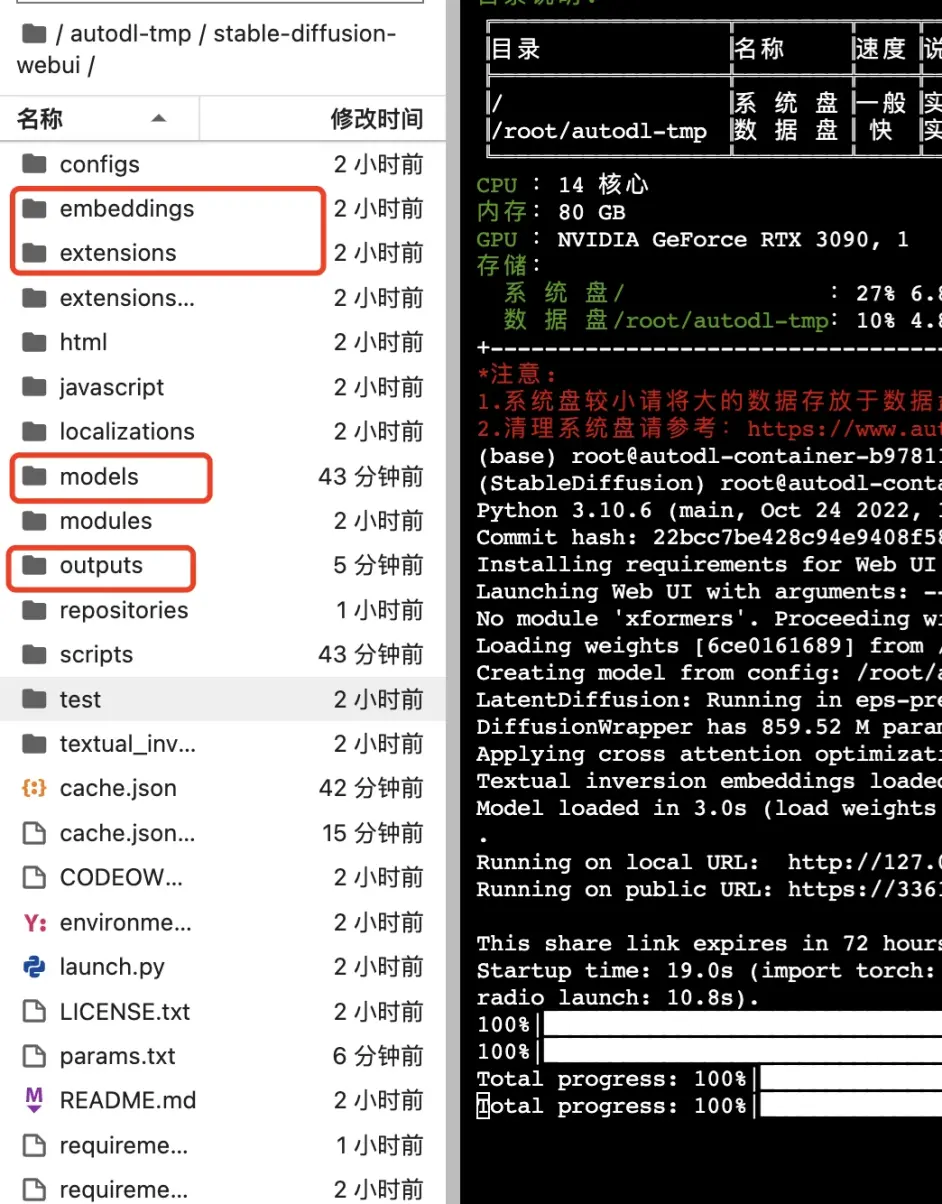
上图红框中的 4 个文件夹是我们常用到的,embeddings 放置训练的 embedding 模型,它可以在我们使用基础模型时,再添加此模型进行叠加效果。

extensions 插件安装目录,在 WebUI 插件安装界面安装后,可以此文件夹中查看,并上传相应的插件模型(如 ControlNet 需要专门的模型)
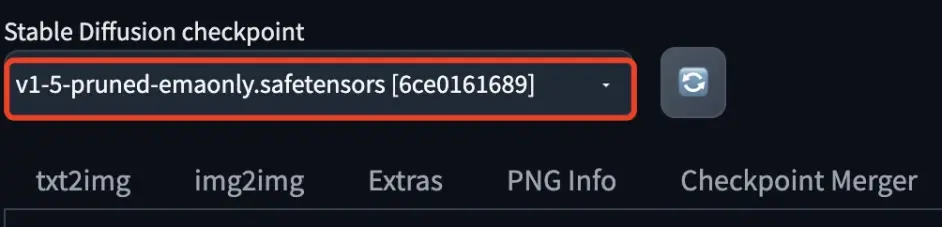
Models 模型文件夹,安装时会默认下载 v1-5-pruned-emaonly,我们从其它地方下载的模型可以拷贝到此文件夹,在需要使用某个模型时,可以进行切换,如下图:
outputs 生成的图系统会输出到这个文件夹里,可进行查看及保存。

上图从左到右,依次是:
txt2img: 文字生成图片
img2img: 图片生成图片
Extras: "无损"放大图片,优化(清晰、扩展)图像
**PNG info:**从图片 exif 里获取图片的信息,如果是 Stable Diffusion 原始生成的 png 图片,图片的 exif 信息里会写入图片生成参数
**Checkpoint Merger:**合并不同的模型,生成新的模型
**Train:**训练 embedding 或者 hypernetwork
**Settings:**设置页面
**Extensions:**插件的安装和管理页面
txt2img
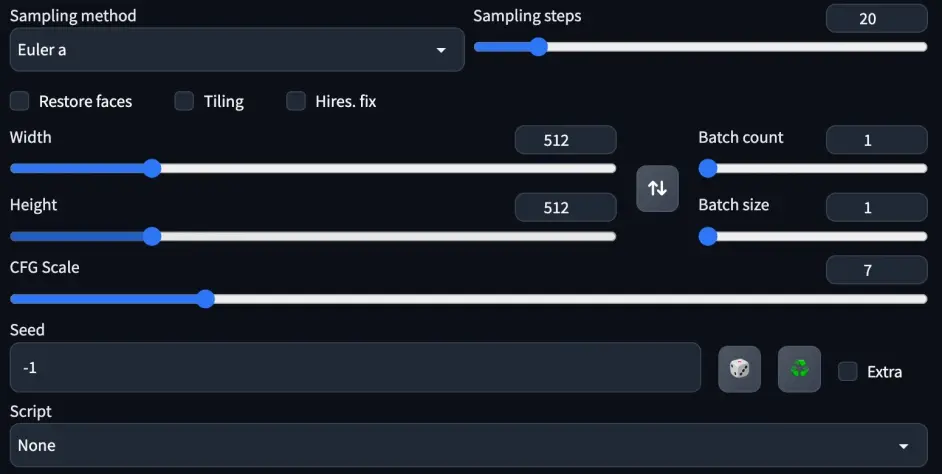
**Sampling method:**采样方法
● Euler a :富有创造力,不同步数可以生产出不同的图片。 超过 30~40 步基本就没什么增益了
● Euler:最常见的基础算法,最简单也最快
● DDIM:速度快,一般 20 步差不多
● LMS:eular 的延伸算法,相对更稳定一点,30 步就比较稳定
● PLMS:改进一点的 LMS
● DPM2:DDIM 的一种改进版,速度大约是 DDIM 的两倍
**Sampling Steps:**采样迭代步数
先随机出一个噪声图片,然后一步步调整图片,向提示词 Prompt 靠拢。其实就是告诉 Stable Diffusion,这样的步骤应该进行多少次,步骤越多,每一步移动也就越小越精确,同时也成比例地增加生成图像所需要的时间。大部分采样器超过 50 步后意义就不大了
**Restore faces:**优化面部,绘制面部图像特别注意。原理是调用一个神经网络模型对面部进行修复
**Tiling:**生成一个可以平铺的图像
**Highres. fix:**先生成低分辩率的图,接着添加细节之后再输出,可以把低分辨率的照片调整到高分辨率
Batch count、 Batch size: 都是生成几张图,前者计算时间长,后者需要显存大
**Denoising strength:**决定算法对图像内容的保留程度。因为加的噪声少,原图片部分多,加的噪声多,原图片部分少。在 0 处,什么都不会改变,而在 1 处,你会得到一个不相关的图像
**CFG Scale:**对描述参数的倾向程度(也就是生成图像与提示词的一致程度),越低的值产生越有创意的结果,如果太低,例如 1,那 Promp t就完全没用了。一般在 5~15 之间为好,7,9,12 是 3 个常见的设置值
**Seed:**种子数,只要种子数、参数、模型都一致,就能重新生成一样的图像,-1 的话是生成一个随机数
Prompt 语法
正向提示词例子:
(masterpiece:1.331), best quality,illustration,(1girl),(deep pink hair:1.331), (wavy hair:1.21),(disheveled hair:1.331), messy hair, long bangs, hairs between eyes,(white hair:1.331), multicolored hair,(white bloomers:1.46),(open clothes),beautiful detailed eyes,purple|red eyes),expressionless,sitting,dark background, moonlight,flower_petals,city,full_moon,**分隔:**不同的关键词tag之间,需要使用英文逗号 , 分隔,逗号前后有空格或者换行不影响结果。例如:1girl,loli,long hair,low twintails(1 个女孩,loli,长发,低双马尾)
**混合:**WebUI 使用 | 分隔多个关键词,实现混合多个要素,注意混合是同等比例、同时混。例如:1girl,red|blue hair, long hair(1个女孩,红色与蓝色头发混合,长发)
**增强/减弱:**有两种写法。
● 第一种 (提示词:权重数值):数值从0.1~100,默认状态是 1,低于 1 就是减弱,大于 1 就是加强。例如:(loli:1.21),(one girl:1.21),(cat ears:1.1),(flower hairpin:0.9)
● 第二种 (((提示词))),每套一层()括号增强 1.1 倍,每套一层 \[\] 减弱 1.1 倍。也就是套两层是1.1*1.1=1.21 倍,套三层是 1.331 倍,套 4 层是 1.4641 倍。例如: ((loli)),((one girl)),(cat ears),flower hairpin,这与第一种写法等价,所以还是建议使用第一种方式。
**渐变:**可简单的理解时为,先按某种关键词生成,然后再此基础上向某个方向变化。
关键词1:关键词2:数字,数字大于 1 理解为第 X 步前为关键词 1,第 X 步后变成关键词 2,数字小于 1 理解为总步数的百分之 X 前为关键词 1,之后变成关键词 2。
例如:a girl with very long white:yellow:16 hair 等价为开始 a girl with very long white hair
,16步之后 a girl with very long yellow hair
例如:a girl with very long white:yellow:0.5 hair 等价为开始 a girl with very long white hair,50% 步之后 a girl with very long yellow hair
**交替:**轮流使用关键词,例如:cow\|horse in a field,这就是个牛与马的混合物;cow\|horse\|cat\|dog in a field 就是牛、马、猫、狗之间混合。
**Negative prompt:**负面提示词,用文字描述不想在图像中出现的内容。
一些常见的负面提示词:
lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry,missing arms,long neck,Humpbacked,missing limb,too many fingers,mutated,poorly drawn,out of frame,bad hands,owres,unclear eyes,poorly drawn,cloned face,bad faceimg2img
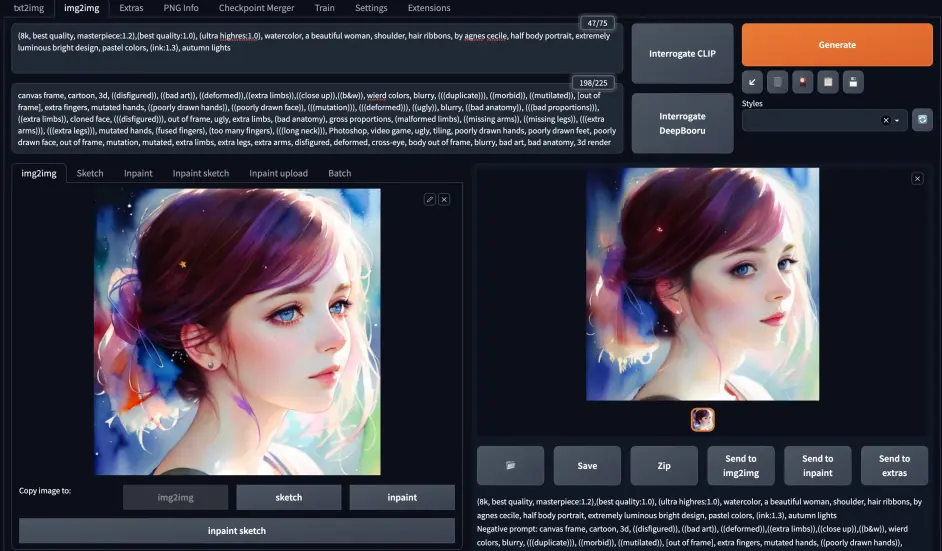
与 txt2img 类似,在文字提示词的基础上,增加了图片提示。
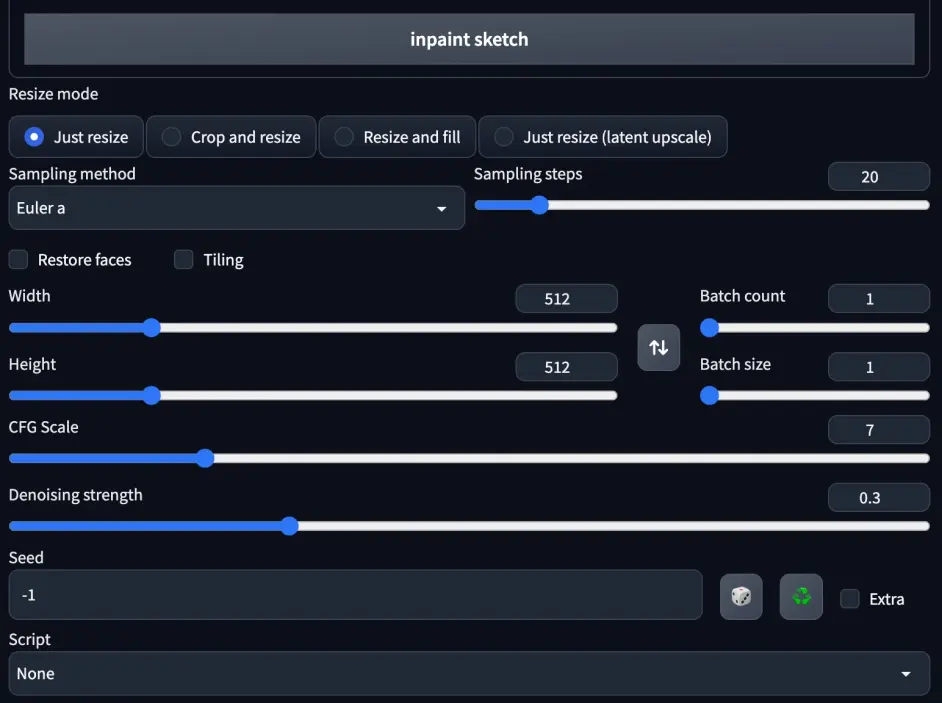
Denoising strength:与原图一致性的程度,一般大于 0.7 出来的都是新效果,小于 0.3 基本就会原图一致
Extras
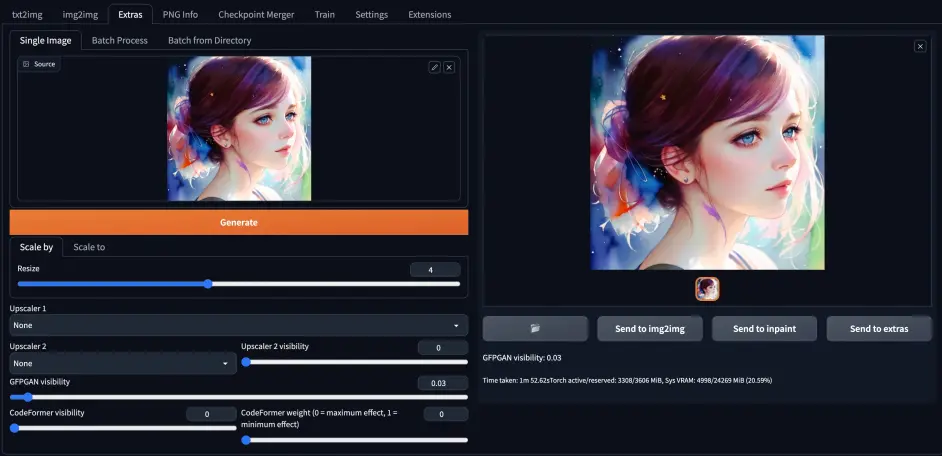
主要将图像进行优化,Resize 设置放大的倍率,GFPGAN visibility 主要对图像清晰度进行优化,CodeFormer visibility 对于老照片及人脸修复很有效,权重参数为 0 时效果最大,为 1 时效果最小,建议从 0.5 开始尝试。
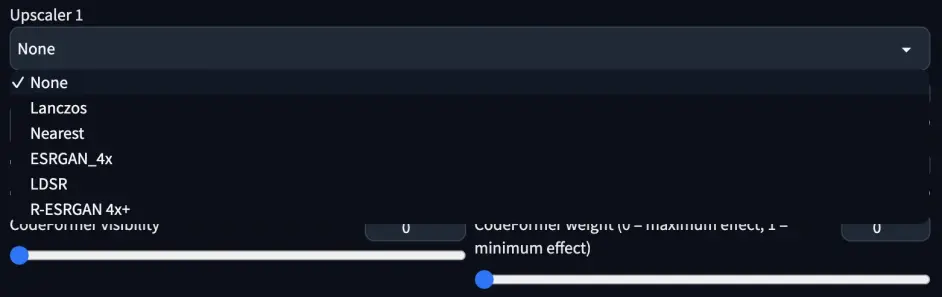
Upscaler 放大算法,一般不清楚可不选,或者选 ESRGAN_4x。
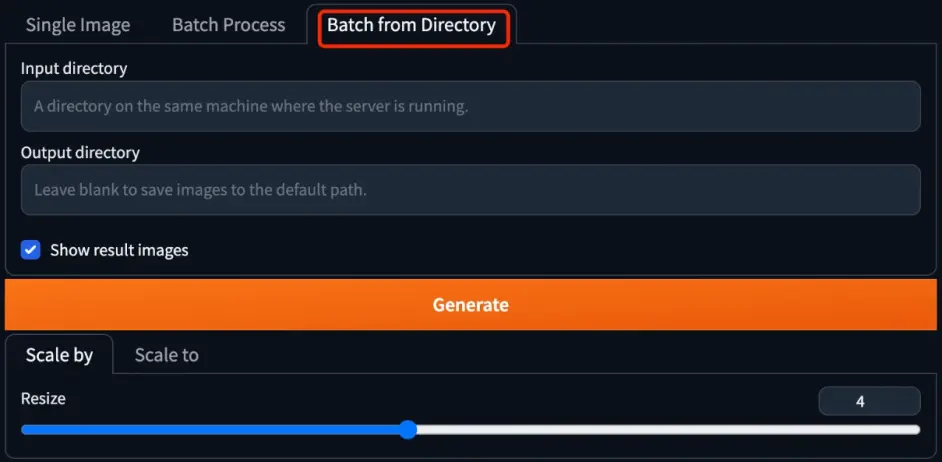
Batch from Directory 可以进行批量处理,在 Input directory 中输入需要批量处理图片的目录,在 Output directory 中输入保存结果目录。
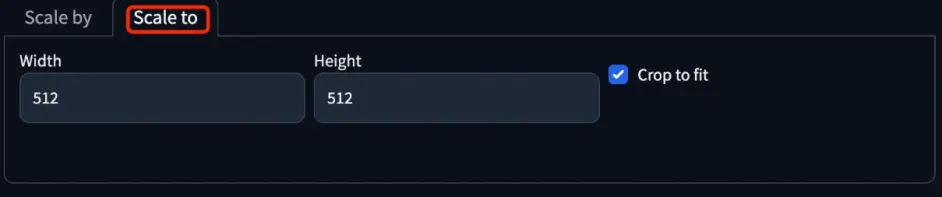
Scale to 中,可自定义图片的尺寸。
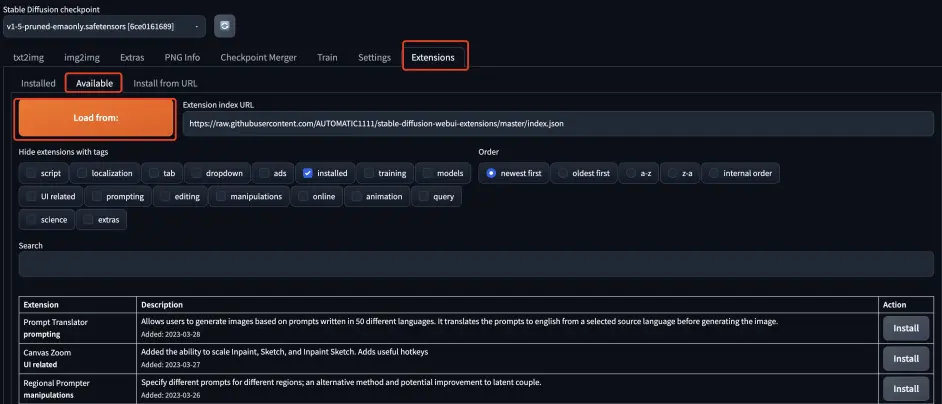
Extensions
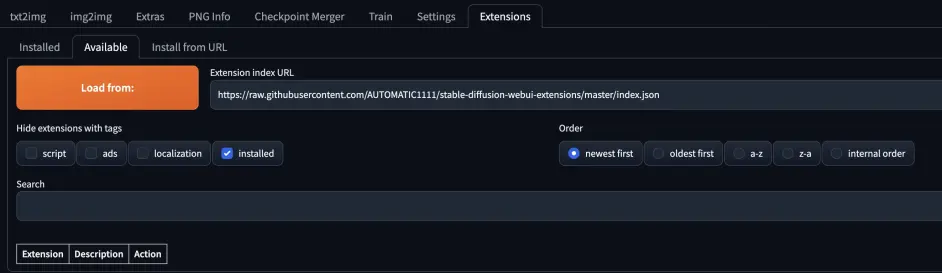
插件界面,installed 表示已经安装好的插件,Available 表示在线可用的插件,一般都是从这里安装。
点击 Load from: 加载出可用的插件,然后按 Ctrl + F,输入想要安装插件的名称,以此进行查找。
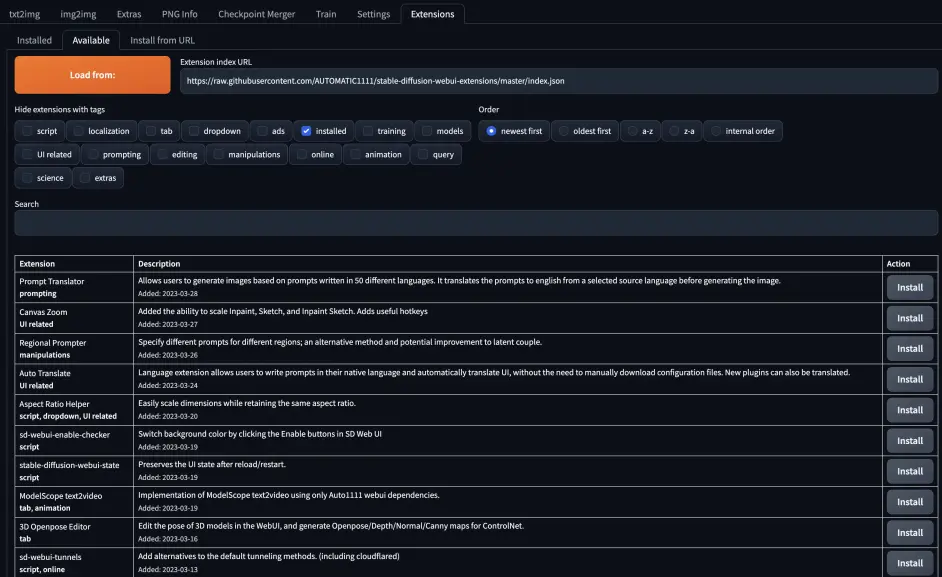
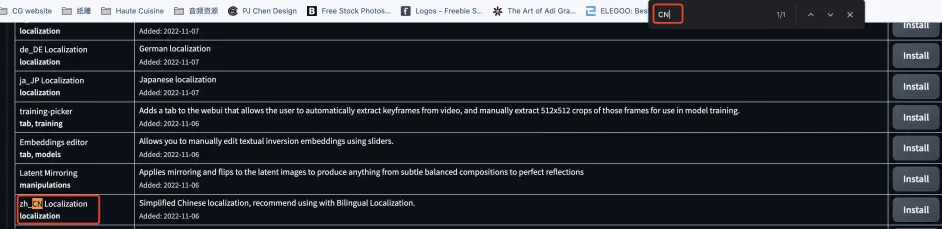
输入 CN,查找汉化插件:
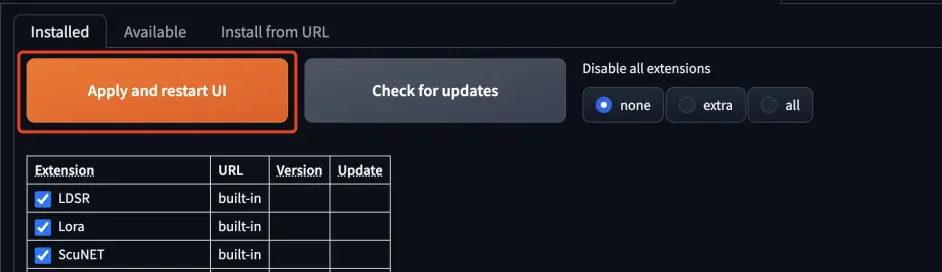
安装后,重新启动 UI 界面,插件就可以生效了。
两个比较重要的插件:Dreambooth,ControlNet。