基本概念
决策树归纳
决策树:决策树是一种类似流程图的树结构,其中每个内部结点(非树叶节点)表示在一个属性上的测试,每一个分枝代表该测试的一个输出,而每个树叶节点存放一个类标号,树的最顶层及节点是根节点
属性选择
信息熵
p为概率
先计算总的信息熵=-((p(是)log2(p(是))+p(否)log2(p(否))
属性1种类1熵=-(p(种类1是)log2(种类1是)+p(种类1否)log2(种类1否))
属性1增益=总信息熵-p(种类1)属性1种类1熵-p(种类2)属性1种类2熵
取最大的

信息增益


基尼指数
属性1种类1权重(1-(是)^2-(否)^2)+ 属性1种类2权重(1-(是)^2-(否)^2)取最小的
贝叶斯分类方法
预测类隶属关系的概率例如:一个给定的元组属于另一个特定类的概率
贝叶斯定理
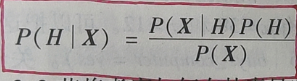
朴素贝叶斯
首先确定类别,不同类别的概率
列出每个类别中各个属性的概率
p(假设某个类别1)p(属性1|某个类别1)p(属性2|某个类别1)
p(假设某个类别2)p(属性1|某个类别2)p(属性2|某个类别2)
分别比较两个的概率,那个高就是哪个类别


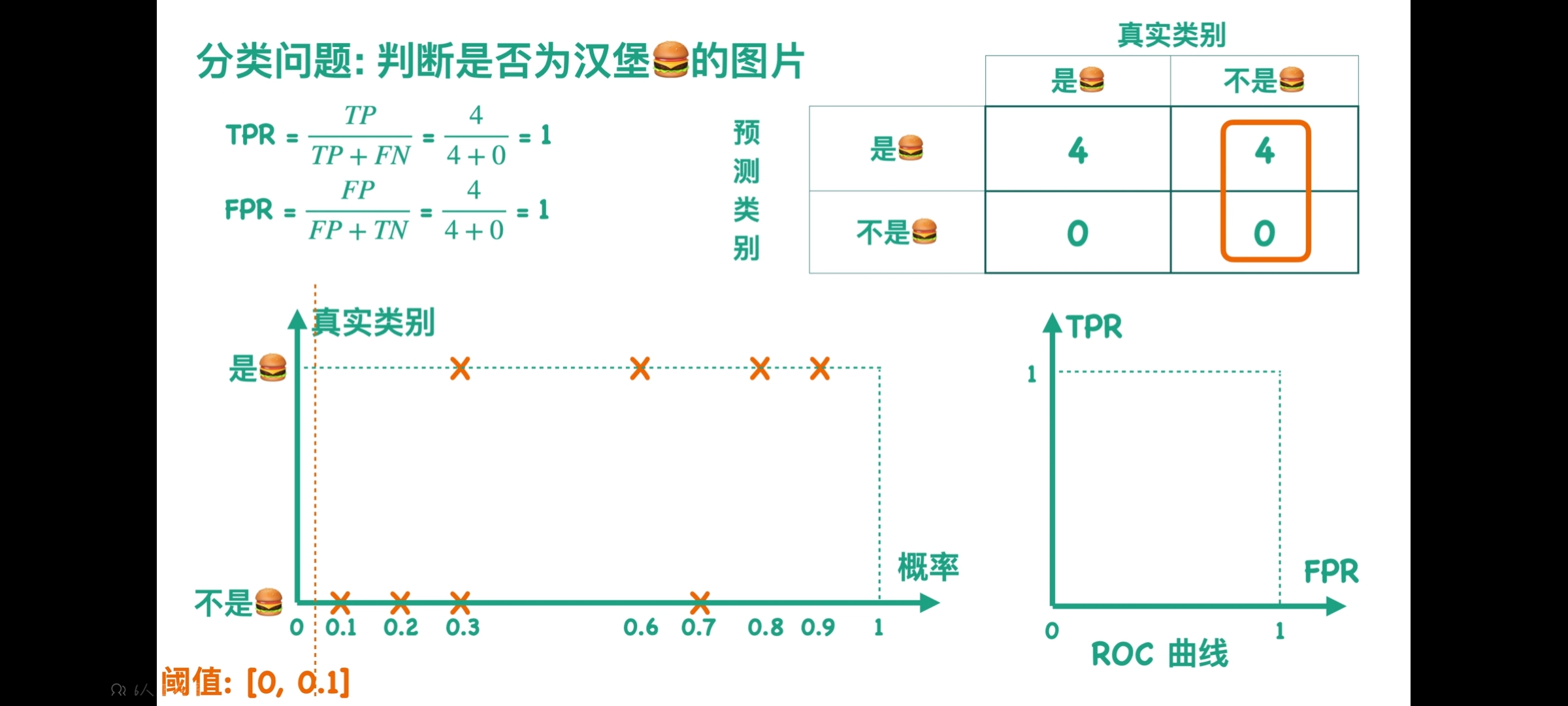
ROC曲线
TP(真正例)(True Positive)、FP(假正例)、TN(真负例)(True Negative)、FN(假负例)
TPR=(真正例)/(真正例+假负例)(实际为真的总数)
FPR=假正例
AdaBoost
AdaBoost是一种流行的提升算法,创建分类器的组合,每个给出一个加权投票(评委打分,不由一个人的分数决定,专家和观众占不同的比例,最算出来的才是最终分数)
流程:
1.赋予每个训练元组相同的权重1/d
2.有放回的抽样,形成一个训练集Di
3.把这个训练集拿去训练,训练出分类器Mi
4.使用Di作为检验集,看Mi的错误率error
5.错误率大于0.5就需要重新抽样形成Di,重复步骤
6.找到一个正确的,更新权重(1-error)error
7.直到所有正确的分类元组被找到,规范每个元组权重
高级方法
向后传播分类
后向传播:
1后向传播是一种神经网络学习算法
2神经网络是一组连接/输出单元,每个连接都有一个权重
多层前馈神经网络
1后向传播在多层前馈神经网络上学习
2神经网络由一个输入层和一个输出层,一个或多个隐藏层和一个输出层组成
3.有几个输出单元就有几层神经网络
4.给定足够多的训练样本,多层前馈神经网络可以逼近任何函数,也就是可以去模拟任何问题
5.网络是前馈的,权重不会回送到输入单位
6.网络是全连接的
向后传播

支持向量机
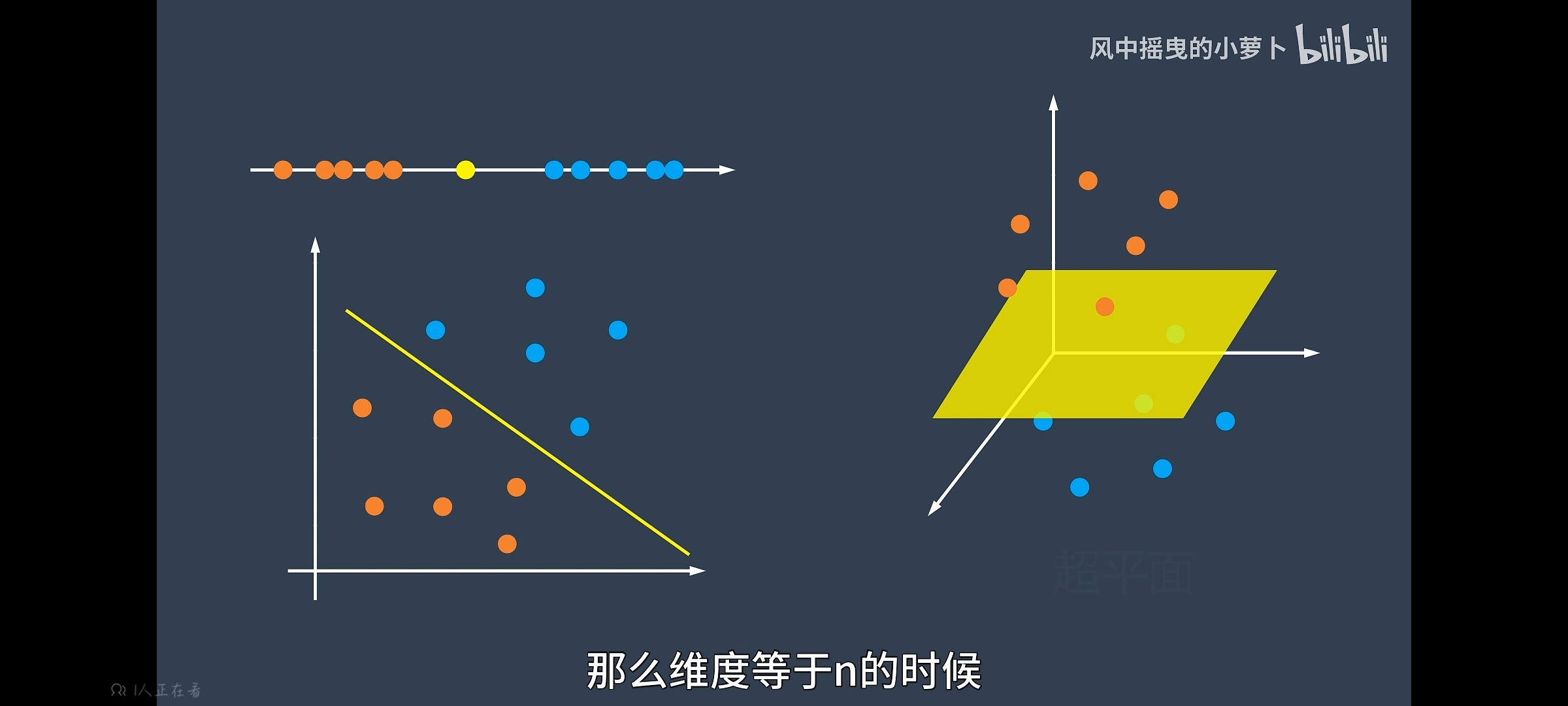
无论在什么纬度,存在一个线性或者非线性的线或者平面可以去分开两个数据集