要了解哈夫曼树,可以先了解一下哈夫曼编码,假设我们有几个字母,他们的出现频率是A: 1 B: 2 C: 3 D: 4 E: 5 F: 6 G: 7。那么如果想要压缩数据的同时让访问更加快捷,就要让频率高的字母离根节点比较进,容易访问,频率低的离根节点远。
所以,构建哈夫曼树的步骤,是一直找最小频率的两个节点,组成一个树,拿上面的例子:
A B的频率最低,所以第一步先把AB当作左右孩子构建树,现在AB相当于一个节点,权值为3。
再次比较,最小的权值是3,3(一个是AB节点的根,一个是C节点)接着构成树。


现在最小的是权值为4,5节点,相当于4,5节点构成树,但此时上面的树仍然存在。
这里直接放最后树的结果了:
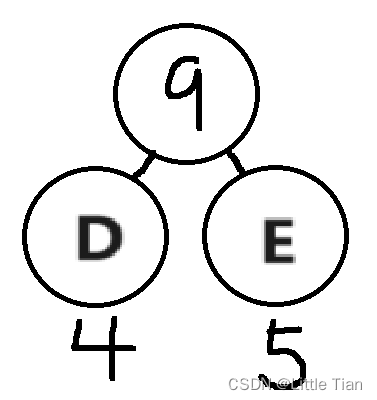

现在梳理一下步骤:
1.先找到最小的两个点,构建他们的根节点。
2.把这两个点从节点中去除,把他们的根节点加入进来。
3.循环这个过程直到只有一个节点。
首先我们要写一个寻找权值最小并且构建根节点的函数,这里我们用一个数组用来存放普通的树节点,根据数学推导,(会增加 n-1 个节点,因为最开始是2个节点增加一个)哈夫曼树最后是 2n-1 个节点,这里先创建n个节点,后面可以realloc扩容。
哈夫曼树的创建先创建 n 的节点的空间,给 n 个节点赋值,也就是初始值。这里的parent是告诉所有节点都在可比较的范围内,如果parent为1,那么说明节点已经参与构建树,也就是再寻找最小值时跳过。
cpp
typedef struct HuffmanTree {
TreeNode* array;
int length;
}HuffmanTree;
HuffmanTree* HuffmanTreeInit(int length,int* data,HuffmanTree* H) {
H = (HuffmanTree*)malloc(sizeof(HuffmanTree));
H->array = (TreeNode*)malloc(sizeof(TreeNode) * length);
H->length = length;
for (int i = 0; i < length; i++) {
H->array[i].val = data[i];
H->array[i].lchild = NULL;
H->array[i].rchild = NULL;
H->array[i].parent = 0;
}
return H;
}接着是寻找最小的两个值的节点,index数组存放的是两个节点的序号,最后返回,前后两个for循环一样,只不过要注意第二个for循环 && j!=index0 ,为了找到第二个最小值,不和第一个重复。
cpp
int* FindTwoMin(HuffmanTree* H) {
int* index = (int*)malloc(sizeof(int) * 2);
int min1 = 1000;
int min2 = 1000;
for (int i = 0; i < H->length; i++) {
if (H->array[i].parent == 0) {
if (H->array[i].val < min1) {
min1 = H->array[i].val;
index[0] = i;
}
}
}
for (int j = 0; j < H->length; j++) {
if (H->array[j].parent == 0) {
if (H->array[j].val < min2 && j!=index[0]) {
min2 = H->array[j].val;
index[1] = j;
}
}
}
return index;
}最后就是构建哈夫曼树:
cpp
void CreatHuffmanTree(HuffmanTree* H) {
int i = H->length,count=H->length;
while( i < count * 2 - 1) {
先找到最小的两个节点的序号
int* index = FindTwoMin(H);
创建最小两个节点的根
H->array = (TreeNode*)realloc(H->array,sizeof(TreeNode) * (i + 1));
H->array[i].val = H->array[index[0]].val + H->array[index[1]].val;
H->array[i].parent = 0;
H->array[i].lchild = &H->array[index[0]];
H->array[i].rchild = &H->array[index[1]];
把parent置为非0,表示已经构建
H->array[index[0]].parent = i;
H->array[index[1]].parent = i;
树的容量值更新
H->length++;
i++;
}
}最后是主函数和结果,最后用先序遍历打印了一下哈夫曼树,符合上面哈夫曼树的图。

这就是文章的全部内容了,希望对你有所帮助,如有错误欢迎评论。