在我之前的文章 "Elasticsearch:ES|QL 查询 TypeScript 类型(一)",我们讲述了如何在 Nodejs 里对 ES|QL 进行查询。在今天的文章中,我们来使用一个完整的例子来进行详细描述。更多有关如何使用 Nodejs 来访问 Elasticsearch的知识,请参阅文章 "Elasticsearch:使用最新的 Nodejs client 8.x 来创建索引并搜索"。
在一下的演示中,我将使用 Elastic Stack 8.13.4 来进行展示。

安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
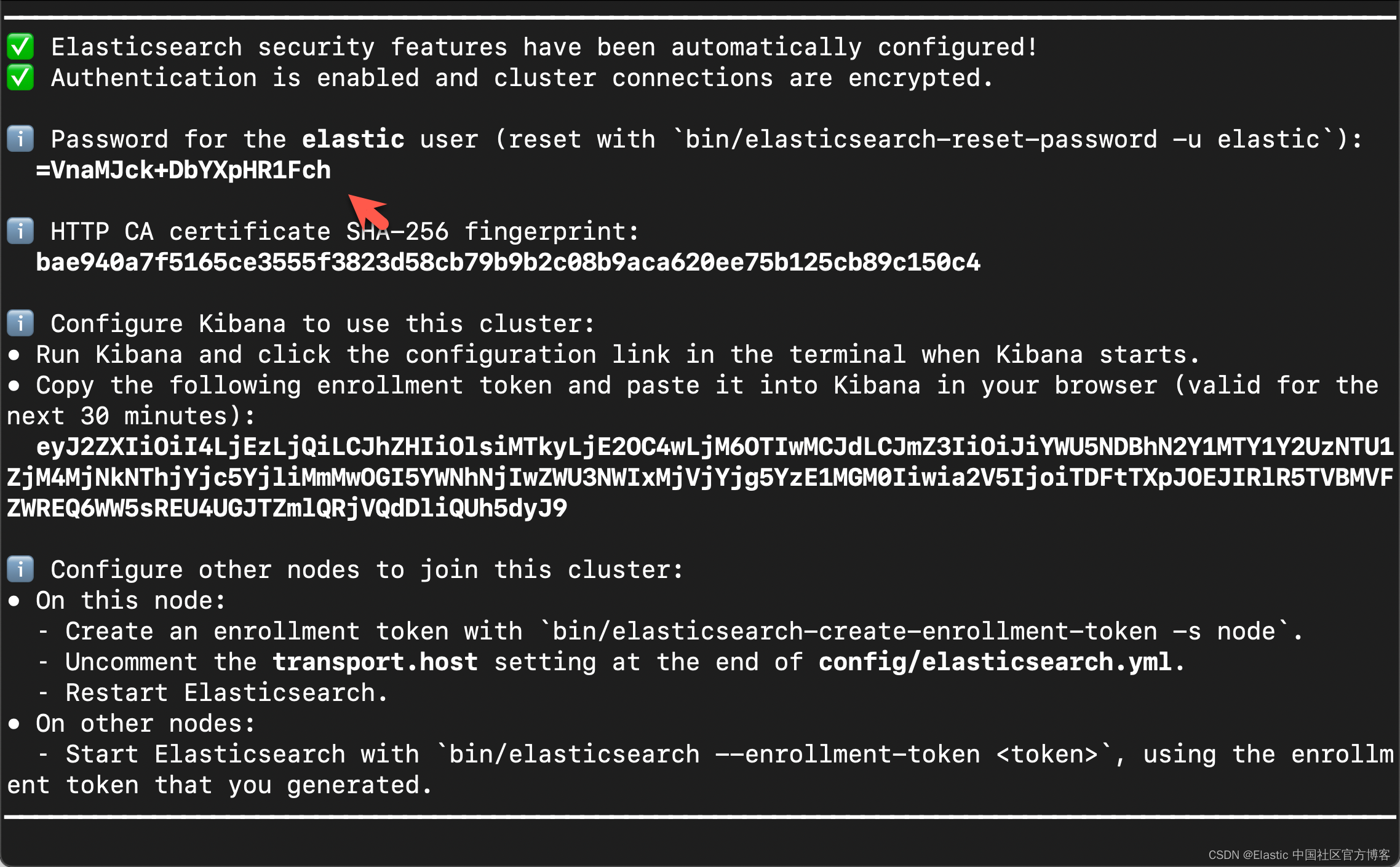
我们需要记下 Elasticsearch 超级用户 elastic 的密码。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.13.4/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
Nodejs 依赖包
我们可以使用如下的命令来安装最新的 nodejs 客户端包:
yarn add @elastic/elasticsearch
或者
npm install @elastic/elasticsearch我们可以通过如下的命令来查看安装的版本:
$ npm -v @elastic/elasticsearch
8.19.2创建项目目录并拷贝证书
我们在电脑里创建一个目录,并拷贝相应的 Elasticsearch 访问证书到该目录下:
$ pwd
/Users/liuxg/nodejs/esql
$ cp ~/elastic/elasticsearch-8.13.4/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt我们使用如下的命令来安装:
npm install --save-dev @types/node创建一个叫做 esql.ts 的文件
touch esql.ts我们使用如下的命令来安装 ts-node:
npm install -g ts-node typescript '@types/node'在下面我们将使用如下的命令来运行代码:
ts-node esql.ts 展示
连接到 Elasticsearch
我们编辑 esql.ts 如下:
import { Client } from '@elastic/elasticsearch'
import * as fs from "fs";
const client = new Client({
node: 'https://localhost:9200',
auth: {
username: 'elastic',
password: '=VnaMJck+DbYXpHR1Fch'
},
tls: {
ca: fs.readFileSync('./http_ca.crt'),
rejectUnauthorized: false
}
})
client.info()
.then((response) => console.log(JSON.stringify(response)))
.catch((error) => console.error(JSON.stringify(error))); 在上面,我们使用超级账号 elastic 来进行连接。我们使用证书来访问自签名证书的集群。你需要根据自己的 Elasticsearch 配置修改上面的代码。更多关于如何访问 Elasticsearch 的知识,请阅读文章 "Elasticsearch:使用最新的 Nodejs client 8.x 来创建索引并搜索"。 运行上面的代码,返回:
$ ts-node esql.ts
{"name":"liuxgm.local","cluster_name":"elasticsearch","cluster_uuid":"JXoZ_Xu-QnasteO4AWnVvQ","version":{"number":"8.13.4","build_flavor":"default","build_type":"tar","build_hash":"da95df118650b55a500dcc181889ac35c6d8da7c","build_date":"2024-05-06T22:04:45.107454559Z","build_snapshot":false,"lucene_version":"9.10.0","minimum_wire_compatibility_version":"7.17.0","minimum_index_compatibility_version":"7.0.0"},"tagline":"You Know, for Search"}写入数据
esql.ts
import { Client } from '@elastic/elasticsearch'
import * as fs from "fs";
const client = new Client({
node: 'https://localhost:9200',
auth: {
username: 'elastic',
password: '=VnaMJck+DbYXpHR1Fch'
},
tls: {
ca: fs.readFileSync('./http_ca.crt'),
rejectUnauthorized: false
}
})
client.info()
.then((response) => console.log(JSON.stringify(response)))
.catch((error) => console.error(JSON.stringify(error)));
async function run () {
// Lets index some data into Elasticsearch
await client.indices.exists({
index: "books"
}).then(function (exists) {
if(exists) {
console.log("the index already existed")
} else {
console.log("the index has not been createdyet")
client.helpers.bulk({
datasource: [
{ name: "Revelation Space", author: "Alastair Reynolds", release_date: "2000-03-15", page_count: 585 },
{ name: "1984", author: "George Orwell", release_date: "1985-06-01", page_count: 328 },
{ name: "Fahrenheit 451", author: "Ray Bradbury", release_date: "1953-10-15", page_count: 227 },
{ name: "Brave New World", author: "Aldous Huxley", release_date: "1932-06-01", page_count: 268 },
],
onDocument(_doc) {
return { index: { _index: "books" } }
},
})
}
})
}
run().catch(console.log)在运行完上面的代码后,我们可以在 Kibana 中进行查看:

对数据进行 ES|QL 查询
const response = await client.esql.query({ query: 'FROM books' })
console.log(response)完整的代码为:
esql.ts
import { Client } from '@elastic/elasticsearch'
import * as fs from "fs";
const client = new Client({
node: 'https://localhost:9200',
auth: {
username: 'elastic',
password: '=VnaMJck+DbYXpHR1Fch'
},
tls: {
ca: fs.readFileSync('./http_ca.crt'),
rejectUnauthorized: false
}
})
client.info()
.then((response) => console.log(JSON.stringify(response)))
.catch((error) => console.error(JSON.stringify(error)));
async function run () {
// Lets index some data into Elasticsearch
await client.indices.exists({
index: "books"
}).then(function (exists) {
if(exists) {
console.log("the index already existed")
} else {
console.log("the index has not been createdyet")
client.helpers.bulk({
datasource: [
{ name: "Revelation Space", author: "Alastair Reynolds", release_date: "2000-03-15", page_count: 585 },
{ name: "1984", author: "George Orwell", release_date: "1985-06-01", page_count: 328 },
{ name: "Fahrenheit 451", author: "Ray Bradbury", release_date: "1953-10-15", page_count: 227 },
{ name: "Brave New World", author: "Aldous Huxley", release_date: "1932-06-01", page_count: 268 },
],
onDocument(_doc) {
return { index: { _index: "books" } }
},
})
}
})
const response = await client.esql.query({ query: 'FROM books' })
console.log(response)
}
run().catch(console.log)上面代码的完整响应为:
$ ts-node esql.ts
the index already existed
{"name":"liuxgm.local","cluster_name":"elasticsearch","cluster_uuid":"JXoZ_Xu-QnasteO4AWnVvQ","version":{"number":"8.13.4","build_flavor":"default","build_type":"tar","build_hash":"da95df118650b55a500dcc181889ac35c6d8da7c","build_date":"2024-05-06T22:04:45.107454559Z","build_snapshot":false,"lucene_version":"9.10.0","minimum_wire_compatibility_version":"7.17.0","minimum_index_compatibility_version":"7.0.0"},"tagline":"You Know, for Search"}
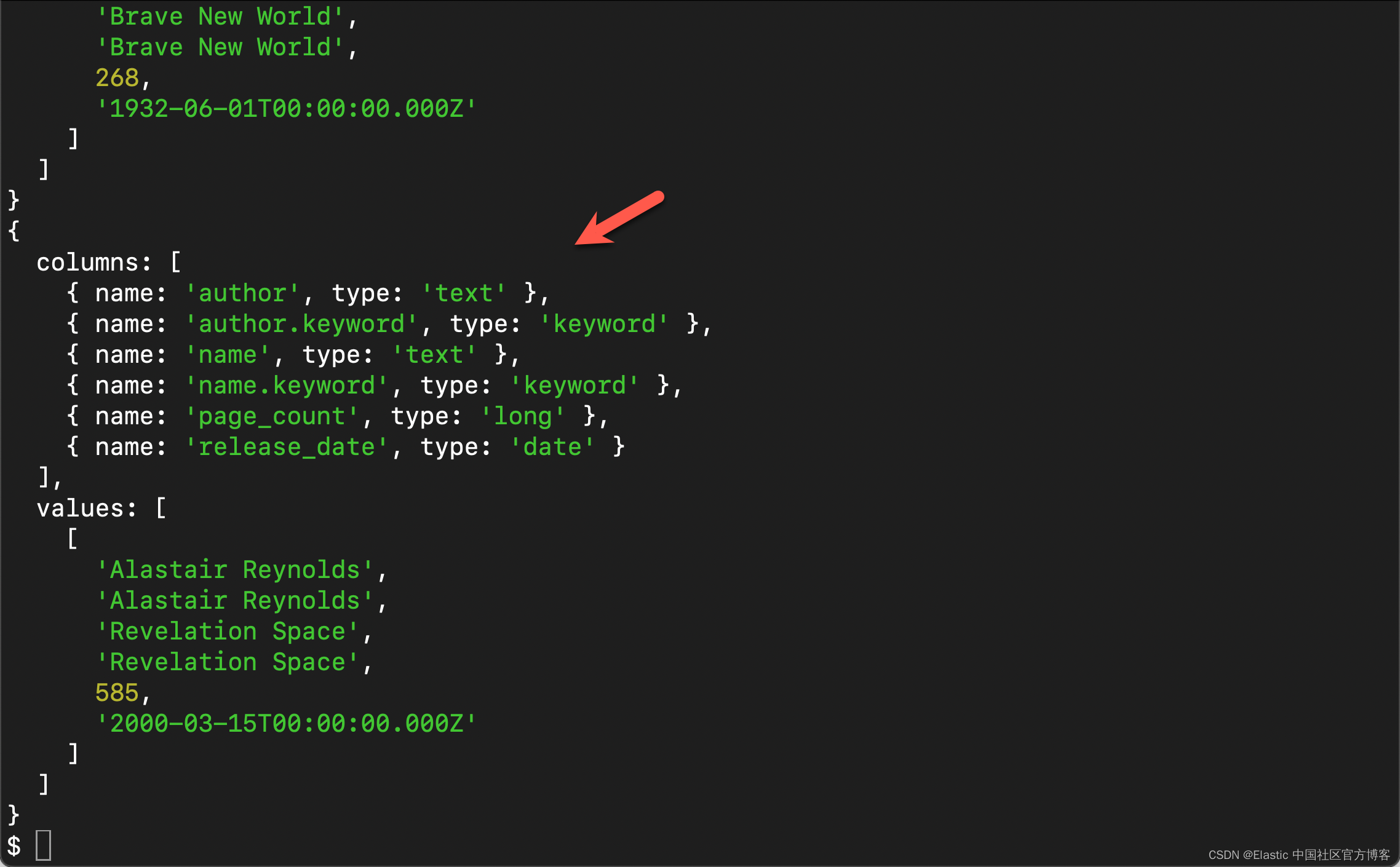
{
columns: [
{ name: 'author', type: 'text' },
{ name: 'author.keyword', type: 'keyword' },
{ name: 'name', type: 'text' },
{ name: 'name.keyword', type: 'keyword' },
{ name: 'page_count', type: 'long' },
{ name: 'release_date', type: 'date' }
],
values: [
[
'Alastair Reynolds',
'Alastair Reynolds',
'Revelation Space',
'Revelation Space',
585,
'2000-03-15T00:00:00.000Z'
],
[
'George Orwell',
'George Orwell',
'1984',
'1984',
328,
'1985-06-01T00:00:00.000Z'
],
[
'Ray Bradbury',
'Ray Bradbury',
'Fahrenheit 451',
'Fahrenheit 451',
227,
'1953-10-15T00:00:00.000Z'
],
[
'Aldous Huxley',
'Aldous Huxley',
'Brave New World',
'Brave New World',
268,
'1932-06-01T00:00:00.000Z'
]
]
}将每行返回为值数组是一个简单的默认设置,在许多情况下很有用。不过,如果你想要一个记录数组(JavaScript 应用程序中的标准结构),则需要额外的努力来转换数据。
幸运的是,在 8.14.0 中,JavaScript 客户端将包含一个新的 ES|QL 助手来为你执行此操作:
const { records } = await client.helpers.esql({ query: 'FROM books' }).toRecords()
/*
Returns:
[
{ name: "Revelation Space", author: "Alastair Reynolds", release_date: "2000-03-15", page_count: 585 },
{ name: "1984", author: "George Orwell", release_date: "1985-06-01", page_count: 328 },
{ name: "Fahrenheit 451", author: "Ray Bradbury", release_date: "1953-10-15", page_count: 227 },
{ name: "Brave New World", author: "Aldous Huxley", release_date: "1932-06-01", page_count: 268 },
]
*/截止目前为止,8.14 还没有发布。期待在正式发布后,我们再重新尝试。
更多关于 ES|QL 的查询,请详细阅读文章 "Elasticsearch:ES|QL 动手实践"。
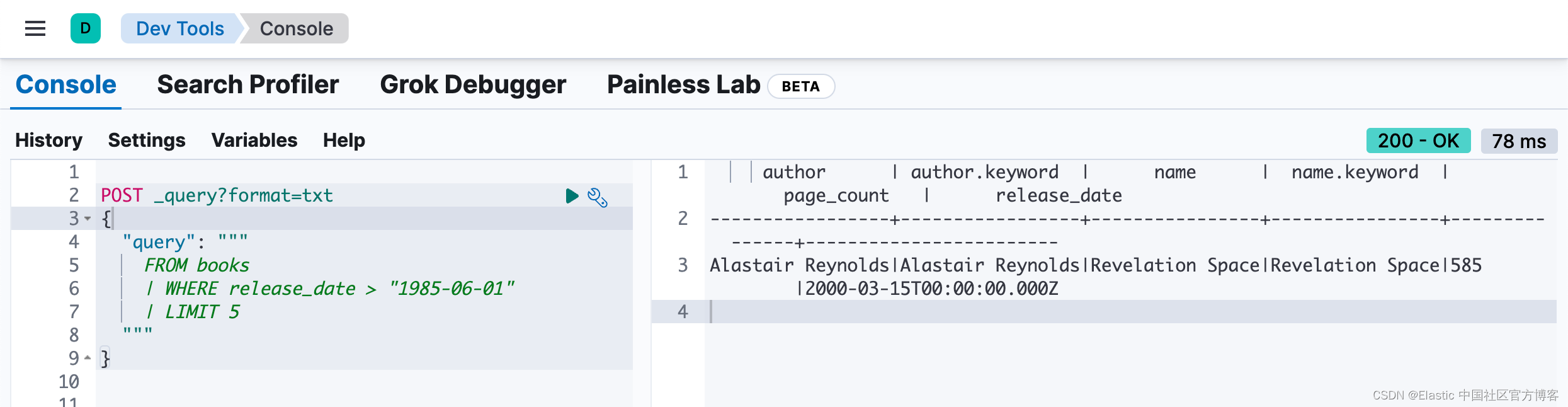
在文章的最后,我们可以来完成另外一个查询。我们使用 Kibana 来进行查询:
POST _query?format=txt
{
"query": """
FROM books
| WHERE release_date > "1985-06-01"
| LIMIT 5
"""
}
我们使用 Nodejs 来进行查询:
const query = 'FROM books | WHERE release_date > "1985-06-01" | LIMIT 5'
const response1 = await client.esql.query({ query: query })
console.log(response1)esql.ts
import { Client } from '@elastic/elasticsearch'
import * as fs from "fs";
const client = new Client({
node: 'https://localhost:9200',
auth: {
username: 'elastic',
password: '=VnaMJck+DbYXpHR1Fch'
},
tls: {
ca: fs.readFileSync('./http_ca.crt'),
rejectUnauthorized: false
}
})
client.info()
.then((response) => console.log(JSON.stringify(response)))
.catch((error) => console.error(JSON.stringify(error)));
async function run () {
// Lets index some data into Elasticsearch
await client.indices.exists({
index: "books"
}).then(function (exists) {
if(exists) {
console.log("the index already existed")
} else {
console.log("the index has not been createdyet")
client.helpers.bulk({
datasource: [
{ name: "Revelation Space", author: "Alastair Reynolds", release_date: "2000-03-15", page_count: 585 },
{ name: "1984", author: "George Orwell", release_date: "1985-06-01", page_count: 328 },
{ name: "Fahrenheit 451", author: "Ray Bradbury", release_date: "1953-10-15", page_count: 227 },
{ name: "Brave New World", author: "Aldous Huxley", release_date: "1932-06-01", page_count: 268 },
],
onDocument(_doc) {
return { index: { _index: "books" } }
},
})
}
})
const response = await client.esql.query({ query: 'FROM books' })
console.log(response)
const query = 'FROM books | WHERE release_date > "1985-06-01" | LIMIT 5'
const response1 = await client.esql.query({ query: query })
console.log(response1)
}
run().catch(console.log)上面最后一个查询的结果为: