目录
[一 、入门](#一 、入门)
[1.1 列式存储](#1.1 列式存储)
[1.2 原生压缩](#1.2 原生压缩)
[1.3 向量化执行引擎](#1.3 向量化执行引擎)
[1.4 DBMS 功能](#1.4 DBMS 功能)
[1.5 分布式处理](#1.5 分布式处理)
[1.6 高吞吐写入能力](#1.6 高吞吐写入能力)
[1.7 实时分析](#1.7 实时分析)
[1.8 SQL支持](#1.8 SQL支持)
[1.9 高度可扩展](#1.9 高度可扩展)
[1.10 数据分区与线程级并行](#1.10 数据分区与线程级并行)
[1.11 应用场景](#1.11 应用场景)
[1.12 不适用场景](#1.12 不适用场景)
[2.1 官网](#2.1 官网)
[2.2 下载镜像](#2.2 下载镜像)
[2.3 启动clickhouse](#2.3 启动clickhouse)
[2.4 使用dbeaver连接测试,新建驱动后、新建连接即可](#2.4 使用dbeaver连接测试,新建驱动后、新建连接即可)
一 、入门
简介
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。ClickHouse 是一款 MPP (大规模并行处理)架构的数据库,它没有采用 Hadoop 生态中的主从架构,而是使用了多主对等网络结果,同时它也是基于关系模型的 ROLAP 方案
核心特性包括
1.1 列式存储
与传统的行式存储不同,列式存储在处理分析型查询时能显著提高效率,因为它允许数据库仅读取查询所需的相关列,减少I/O操作。
列式存储的好处是:
- 对于列的聚合,计数,求和等统计操作原因优于行式存储
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间。
1.2 原生压缩
数据在存储前会进行高效压缩,这不仅能节省存储空间,还能加速数据读取过程,因为从磁盘读取更少的数据量。
1.3 向量化执行引擎
ClickHouse利用SIMD指令集优化数据处理,通过并行处理数据块来加速查询执行。
1.4 DBMS 功能
ClickHouse 拥有完备的管理功能,而不仅是一个数据库。作为一个 DBMS,它具备了一些基本功能。
- DDL:Data Definition Language,数据定义语言,可以动态地创建、修改或删除数据库、表和视图,无须重启服务。
- DML:Data Manipulation Language,数据操作语言,可以动态增删改查数据。
- 权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全性。
- 数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
- 分布式管理:提供集群模式,自助管理多个数据库节点。
1.5 分布式处理
ClickHouse支持数据的分布式存储和处理,可以通过ReplicatedMergeTree引擎实现数据的复制,确保高可用性。分布式表功能允许跨多个节点并行执行查询,提高整体查询性能。
1.6 高吞吐写入能力
ClickHouse 采用类 LSM Tree的结构,数据写入后定期在后台 Compaction。
- 通过类 LSM tree 的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台compaction 时也是多个段 merge sort 后顺序写回磁盘。
- 顺序写的特性,充分利用了磁盘的吞吐能力,即便在 HDD 上也有着优异的写入性能。
1.7 实时分析
尽管ClickHouse设计用于大数据分析,但它也能处理实时数据流,支持近实时的数据分析需求。
1.8 SQL支持
ClickHouse提供丰富的SQL支持,包括复杂的查询语句和聚合函数,便于数据分析和报告生成。
1.9 高度可扩展
ClickHouse易于水平扩展,可以通过添加更多节点来线性地提高处理能力。
1.10 数据分区与线程级并行
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity(索引粒度),然后通过多个 CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条 Query 就能利用整机所有CPU(很吃CPU)。极致的并行处理能力,极大的降低了查询延时。
所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps(query per second) 的查询业务,ClickHouse 并不是强项。其适用场景是数据已经处理好的、字段特别多的宽表
1.11 应用场景
- Web分析(如点击流分析)
- 电商数据分析
- 日志处理和分析
- 实时报表和仪表板
- IoT数据分析
- 规模数据分析和聚合:ClickHouse适用于需要处理大规模数据集的场景,特别是在需要进行复杂的数据分析和聚合操作时。它的列式存储和向量化查询引擎能够高效地执行大量的数据操作,并提供快速的查询结果。
- 实时查询和快速响应:ClickHouse具有高性能的查询引擎,能够以低延迟进行实时查询。它适用于需要快速响应的场景,如实时监控、交互式数据探索和仪表盘展示等。
- 时序数据处理:对于时序数据,如传感器数据、日志数据、时间序列数据等,ClickHouse表现出色。它支持按时间范围进行快速查询,并且具有优化的存储和索引策略,适用于时序数据的存储和分析。
- 高并发查询:ClickHouse是一个高度可扩展的数据库系统,能够处理高并发的查询请求。它适用于需要支持多用户同时查询和大规模并发操作的场景。
1.12 不适用场景
- 事务处理和数据一致性要求:ClickHouse不是一个事务型数据库,不适用于强调数据一致性和事务性操作的场景。如果应用需要确保数据的完整性和一致性,并进行复杂的事务处理,其他事务型数据库更适合。
- 实时数据更新和频繁写入操作:ClickHouse的性能重点在于查询操作,对于实时数据更新和频繁的写入操作,其性能可能不如专门设计用于事务处理和实时写入的数据库系统。
- 复杂的关系查询和事务处理:ClickHouse是一种列式数据库,对于复杂的关系查询(如多表关联、递归查询等)和事务处理,其性能可能不如基于行式存储的数据库系统。
- 少量数据的存储和查询:如果应用场景中的数据量较小,并且对于查询性能要求不高,使用ClickHouse可能会过于复杂和冗余。在这种情况下,可以考虑更轻量级的数据库解决方案
二、ClickHouse单机版安装
2.1 官网
Fast Open-Source OLAP DBMS - ClickHouse
2.2 下载镜像
docker pull yandex/clickhouse-server
docker pull yandex/clickhouse-client2.3 启动clickhouse
① 可正常连接方法(推荐尝试)
bash
docker run -d -p 8123:8123 -p 9000:9000 --name clickhouse yandex/clickhouse-server② 网上方法:
参考文章:https://blog.csdn.net/lcl_xiaowugui/article/details/104724726
1)启动server端
默认直接启动即可
docker run -d --name 启动之后的名称 --ulimit nofile=262144:262144 yandex/clickhouse-server
如果想指定目录启动,这里以clickhouse-test-server命令为例,可以随意写
mkdir /work/clickhouse/clickhouse-test-db ## 创建数据文件目录
使用以下路径启动,在外只能访问clickhouse提供的默认9000端口,只能通过clickhouse-client连接server
docker run -d --name clickhouse-test-server --ulimit nofile=262144:262144 --volume=/work/clickhouse/clickhouse_test_db:/var/lib/clickhouse yandex/clickhouse-server
2)docker启动clickhouse-client
docker run -it --rm --link clickhouse-test-server:clickhouse-server yandex/clickhouse-client --host clickhouse-server
2.4 使用dbeaver连接测试,新建驱动后、新建连接即可
首先需要安装连接工具Dbeaver。
Dbeaver安装教程地址:DBeaver安装与使用教程(超详细安装与使用教程)_dbeaver安装步骤-CSDN博客
第一步,新建驱动管理器:
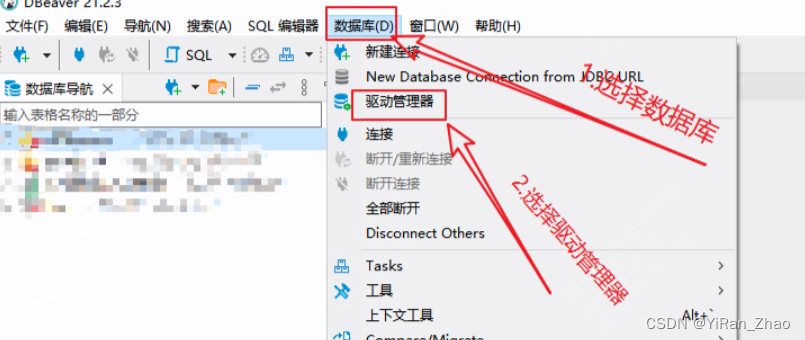
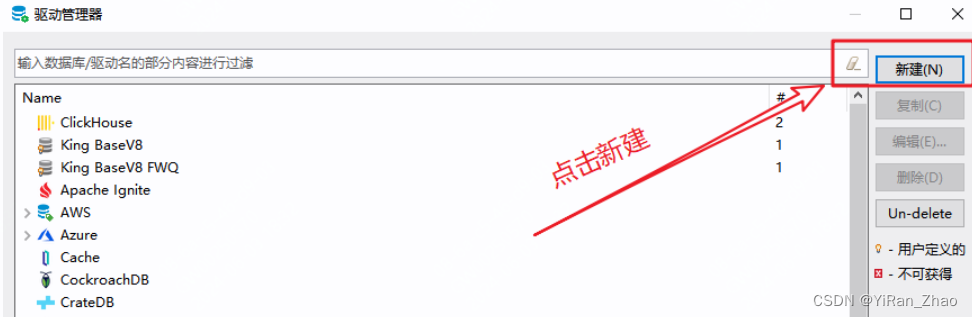
第二步,填写驱动信息:
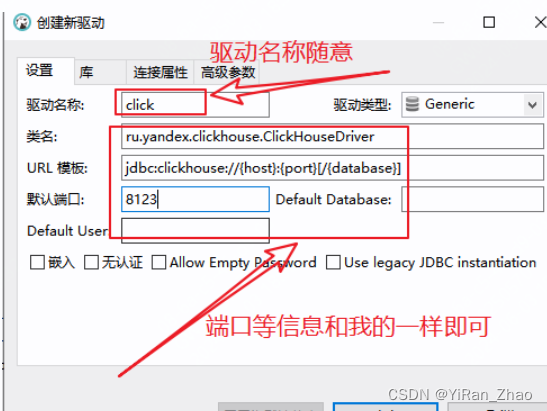
第三步,设置库:
第一种方法:事先下载好的驱动文件,添加文件即可。
驱动下载链接:Download clickhouse-jdbc JAR files with all dependencies
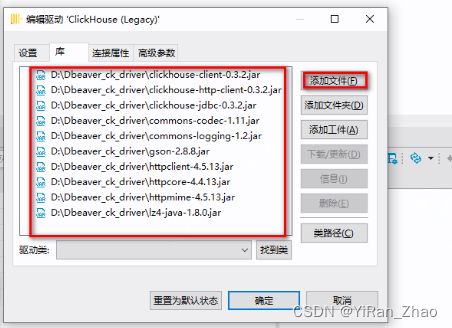
第二种方法:先不设置库,我们再新建数据库连接时,填写完连接配置信息,点击测试链接,在弹出来的地方选择下载按钮,等它全部下载完驱动后即可测试连接
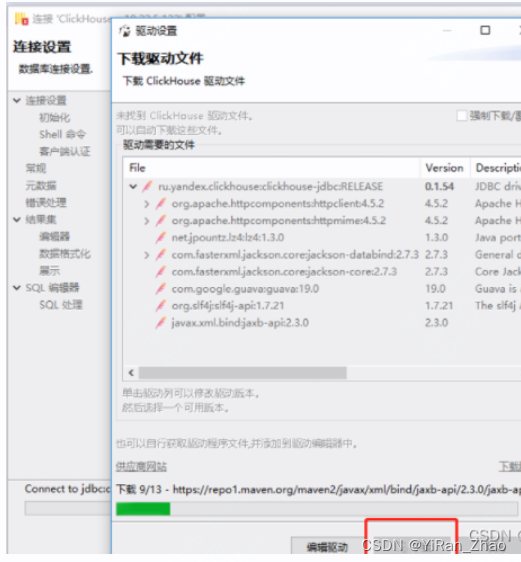
第四步,新建数据库连接:
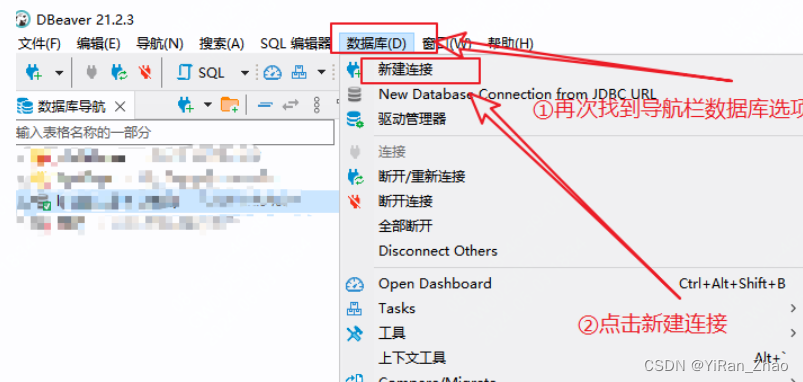
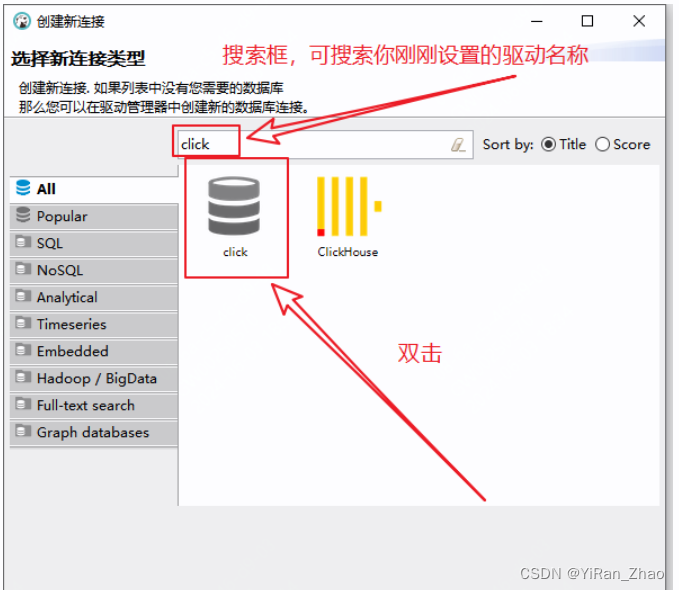
第五步,填写数据库连接配置信息:
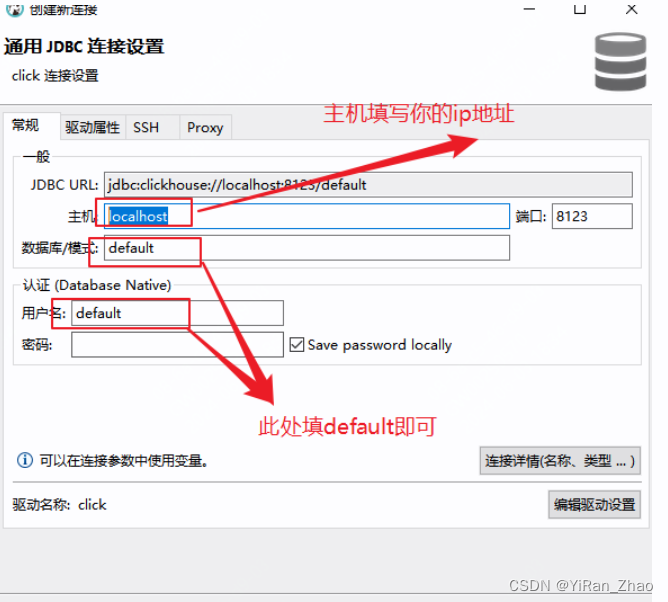
第六步,测试连接:
到了这一步,说明连接配置信息填写完成,如果库没有设置,就可以按照上面的第二种方法点击测试链接,在弹出来的地方选择下载按钮,等它全部下载完驱动后即可测试连接。
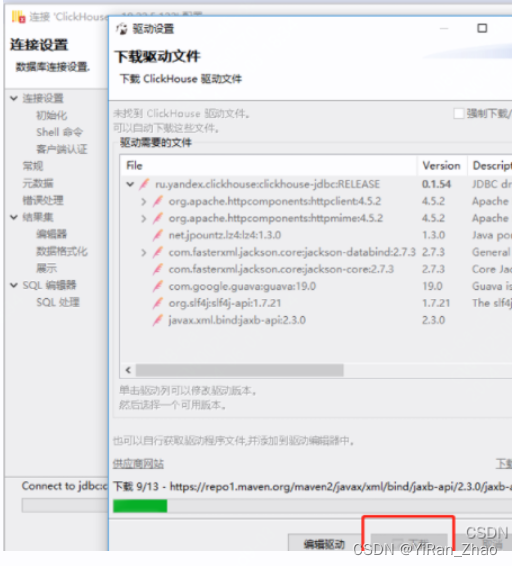
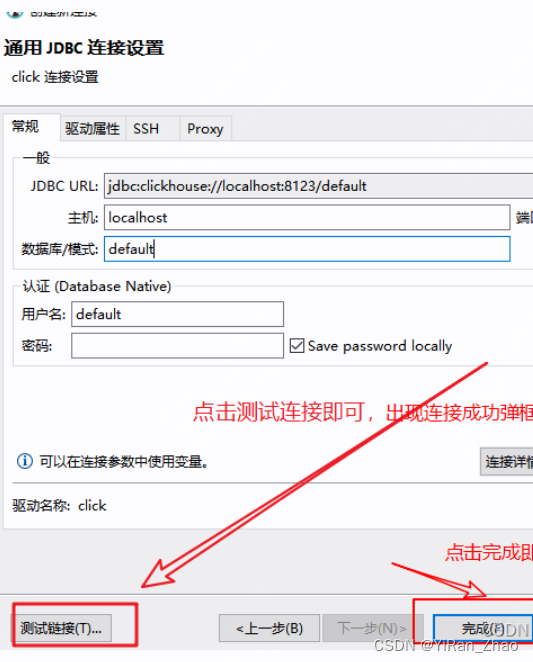
到了这一步,clickhouse已经连接成功了。