1、问题描述
impala执行查询:select * from stmta_raw limit 10;
报错信息如下:
bash
Query: select * from sfmta_raw limit 10
Query submitted at: 2018-04-11 14:46:29 (Coordinator: http://mrj001:25000)
ERROR: AnalysisException: Failed to load metadata for table: 'sfmta_raw'
CAUSED BY: TableLoadingException: Failed to load metadata for table: test.sfmta_raw. Running 'invalidate metadata test.sfmta_raw' may resolve this problem.
CAUSED BY: NoClassDefFoundError: org/apache/hadoop/fs/adl/AdlFileSystem
CAUSED BY: ClassNotFoundException: org.apache.hadoop.fs.adl.AdlFileSystem2、集群环境
【操作系统】Centos6.5
【hadoop版本】2.7.1
【impala版本】2.10.0-cdh5.14.0
3、报错分析
3.1、使用日志提示解决方案
bash
#根据日志提示执行
invalidate metadata test.sfmta_raw3.2、检查依赖lib包依赖
bash
#检查依赖,看是否有依赖没有引入
cd /usr/lib/impala/lib
#检查是否存在依赖包
ls -s | grep azure3.3、检查core-site.xml配置
bash
#进入impala配置目录
cd /etc/impala/conf
#检查配置文件
cat core-site.xml
#查看下面引入的是否有下面属性,如果没有则添加
<property>
<name>fs.AbstractFileSystem.adl.impl</name>
<value>org.apache.hadoop.fs.adl.Adl</value>
</property>
<property>
<name>fs.adl.impl</name>
<value>org.apache.hadoop.fs.adl.AdlFileSystem</value>
</property>3.4、检查hadoop lib目录
bash
#进入impala配置目录
cd $HADOOP_HOME/lib
#检查配置文件
ls -l | grep azure
#如果上一步有对应jar包,则查找下面jar包(该包包括缺失的class实现类)
ls -l | grep hadoop-azure-datalake3.5、检查hadoop lib目录
如果3.2、3.3、3.4中均缺失相应jar包,则代表当前版本hadoop中不支持AdlFileSystem的实现,需要更新hadoop版本;本人使用了apache hadoop2.7.1,经过检查发现确实没有这个子类。经过hadoop官网查询验证
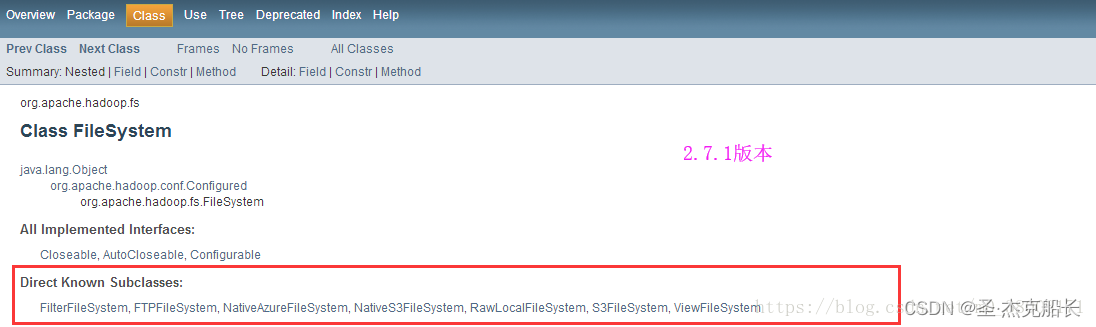
hadoop2.9.0版本有这个子类;问题终于找到
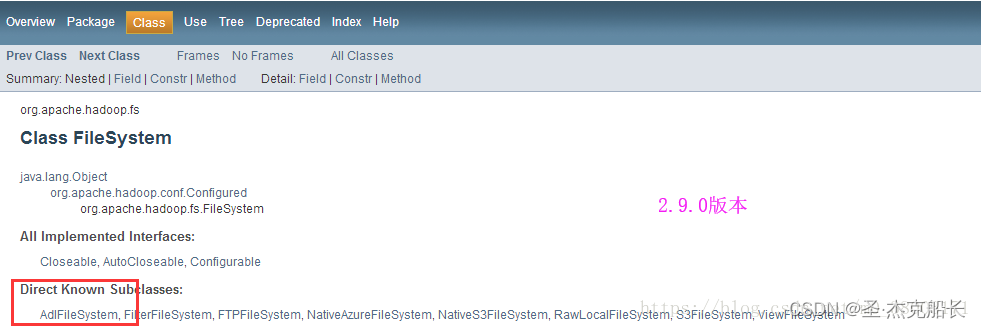
3.6、更新hadoop版本
检查环境兼容性,更新hadoop版本至2.9.0或更高版本