目录
[(1) 首先从词向量到Q、K、V](#(1) 首先从词向量到Q、K、V)
[(2) 计算Q*(K的转置),并归一化之后进行softmax](#(2) 计算Q*(K的转置),并归一化之后进行softmax)
[(3) 使用刚得到的权重矩阵,与V相乘,计算加权求和。](#(3) 使用刚得到的权重矩阵,与V相乘,计算加权求和。)
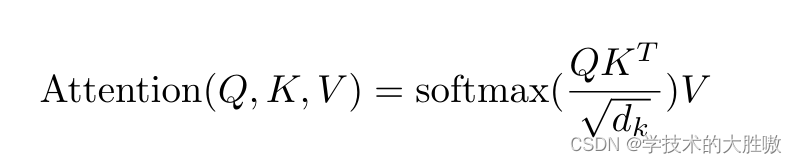
上面这个transformer中的注意力公式,相信大家不会陌生。公式并不复杂,但是why? 为什么是这个公式,为什么大家都说QKV代表Query(查询)、Key(键)和Value(值)?
之前了解transformer的时候,对于QKV的设定感到很奇怪,后来慢慢接受了这个设定,今天记录一下自己的理解。
1、向量点乘
首先从向量点乘说起,是用于计算两个向量的相似度。
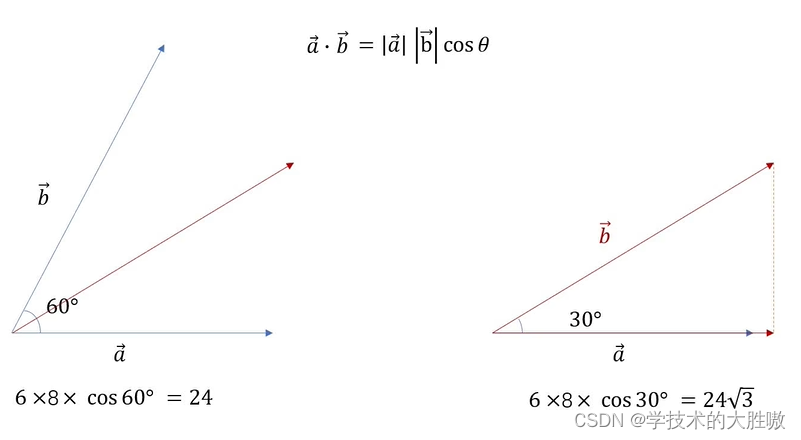
图中可以看到如果两个向量的方向相同或相近 ,它们的点乘结果会很大 ,表示这两个向量相似度高 。相反,如果向量方向相反 ,点乘结果会很小或为负值。
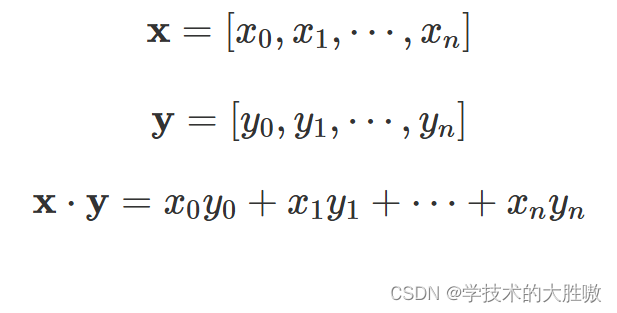
向量x和向量y点乘表示向量x在向量y上的投影再乘以向量y。反应两个向量的相似度。
假设矩阵X由n个行向量组成,每个行向量xi代表一个词的词向量,整个矩阵由这些词向量组成。简而言之,矩阵X是一个词向量矩阵,每个元素都是一个词的向量表示。
具体来说,矩阵X是一个n×n的方形矩阵,其中包含n个行向量(n个词的向量)。
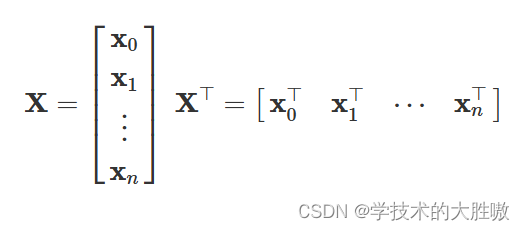
当矩阵X与它的转置XT进行乘法运算时,得到的是目标矩阵XXT。这个目标矩阵的每一个元素是通过矩阵X中的行向量与列向量的点乘得到的。如下图所示

例如,目标矩阵XXT中的第一行第一列元素X0⋅X0,实际上是向量𝑋X0与自身做点乘,这表示的是向量𝑋X0与自身的相似度,也就是它自身的模的平方。
同样地,第一行第二列元素X0⋅X1表示的是向量X0与向量X1之间的相似度,即它们之间的点乘结果。
这个过程可以推广到矩阵X的所有行和列,从而得到整个XXT矩阵,其中每个元素都表示了对应向量之间的相似度。
2、相似度计算举例
下面以词向量矩阵为例,这个矩阵中,每行为一个词的词向量。矩阵与自身的转置相乘,生成了目标矩阵,目标矩阵其实就是一个词的词向量与各个词的词向量的相似度。
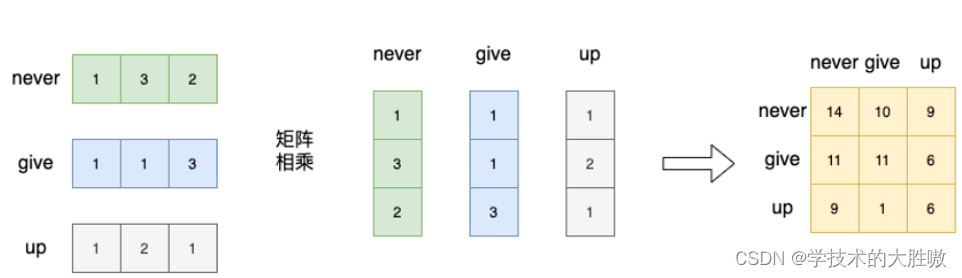
最终的矩阵数值代表了词向量之间的相似度。
我们为什么要求相似度,是为了合理分配权重。这个时候可以加上softmax
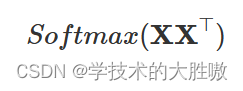
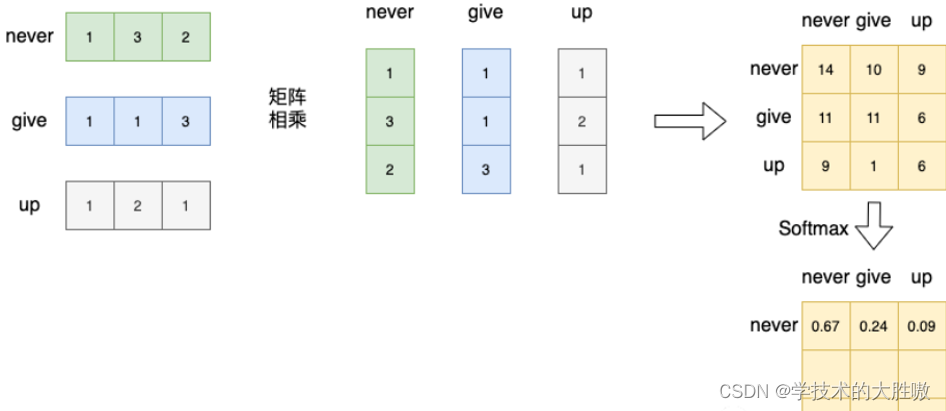
对上述得到的相似度矩阵应用Softmax函数,进行归一化处理。Softmax函数将每个元素转换成一个概率分布,使得每个元素的值都在0到1之间,并且所有元素的和为1。
这样,每个词向量与其他所有词向量的相似度都被转换成了一个概率权重。
接下来,将这个权重矩阵与原始的词向量矩阵 X 相乘。这个过程可以看作是每个词向量根据其权重与其他所有词向量进行加权求和。
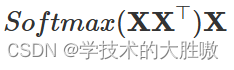
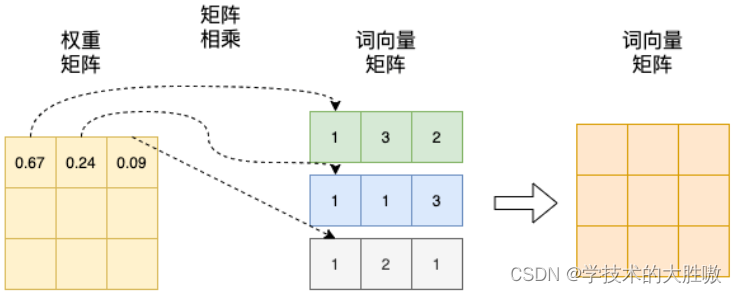
权重矩阵中某一行分别与词向量的一列相乘,词向量矩阵的一列其实代表着不同词的某一维度 。经过这样一个矩阵相乘,相当于一个加权求和的过程,得到结果词向量是经过加权求和之后的新表示。
这个新词向量综合了输入词向量矩阵中所有词的信息,权重由它们之间的相似度决定。
3、QKV分析
注意力Attention机制的最核心的公式为:
与
很相似。

QKV的由来可以用图片演示为:
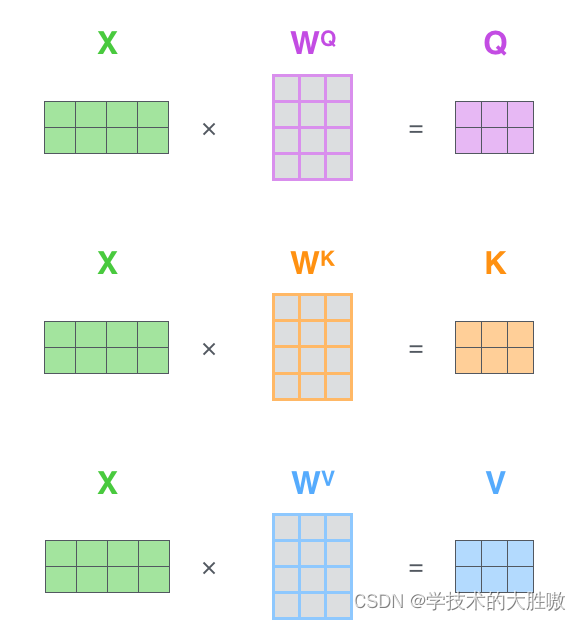
这些乘法操作是线性变换,它们将输入矩阵 X 映射到不同的表示空间,为注意力机制的计算提供基础。
注意力机制不直接使用原始的输入矩阵 X,而是使用经过这三个权重矩阵变换后的Q、K、V。因为使用三个可训练的参数矩阵,可增强模型的拟合能力。
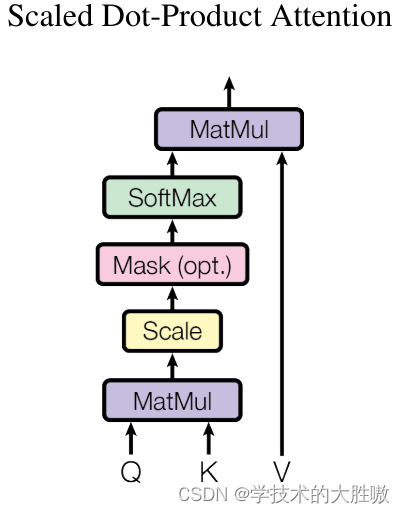
在上面这张论文中关于注意力的原图中,包含了我们之前所解释的过程,可以看到输入的是QKV,也就是真正输入到注意力的是这三个矩阵 。流程解释如下:

Mask是机器翻译等自然语言处理任务中经常使用的方法。在机器翻译等NLP场景中,每个样本句子的长短不同,对于句子结束之后的位置,无需参与相似度的计算(比如后面补充的数据都为0),否则影响Softmax的计算结果。
4、整体流程
利用流程图重新整理一下整体的流程。
(1) 首先从词向量到Q、K、V
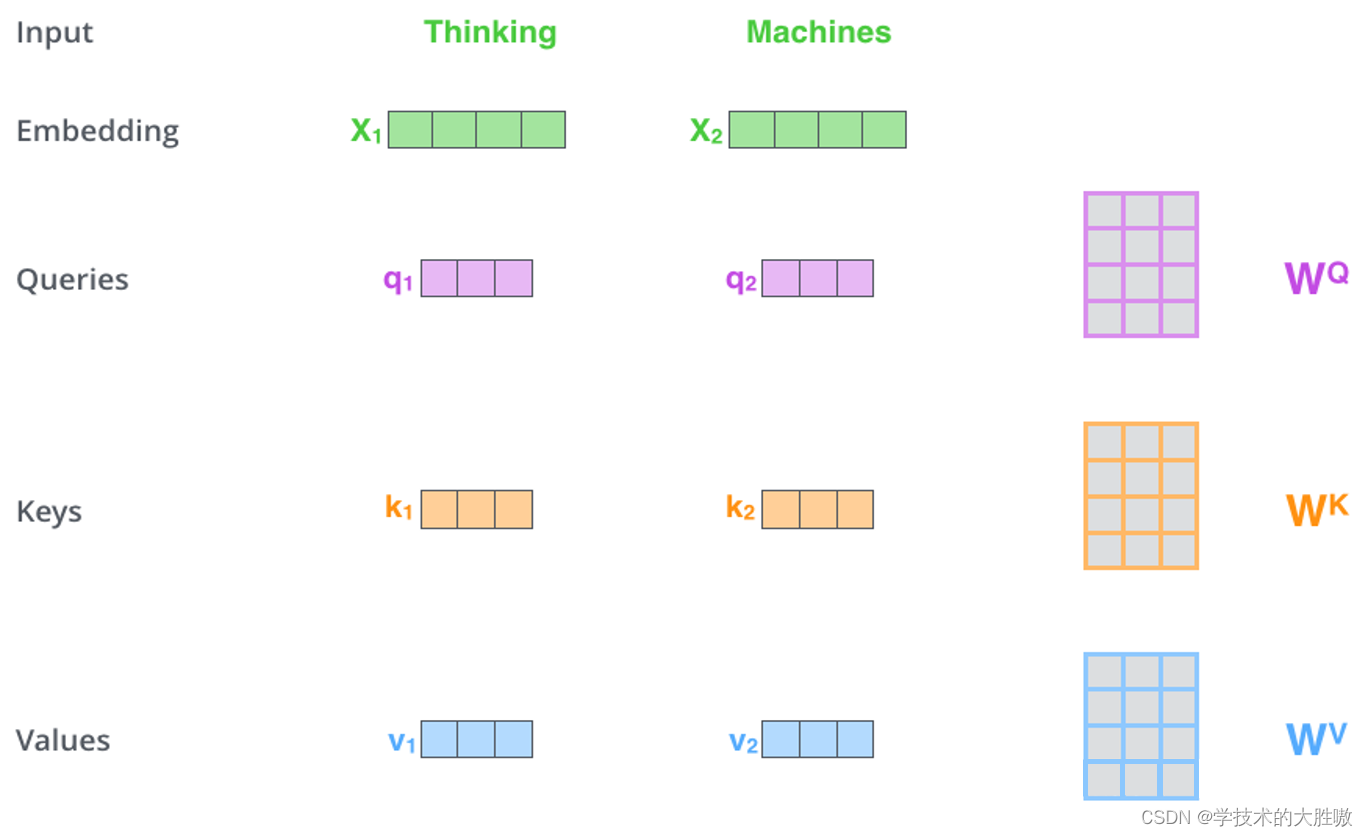
(2) 计算Q*(K的转置),并归一化之后进行softmax
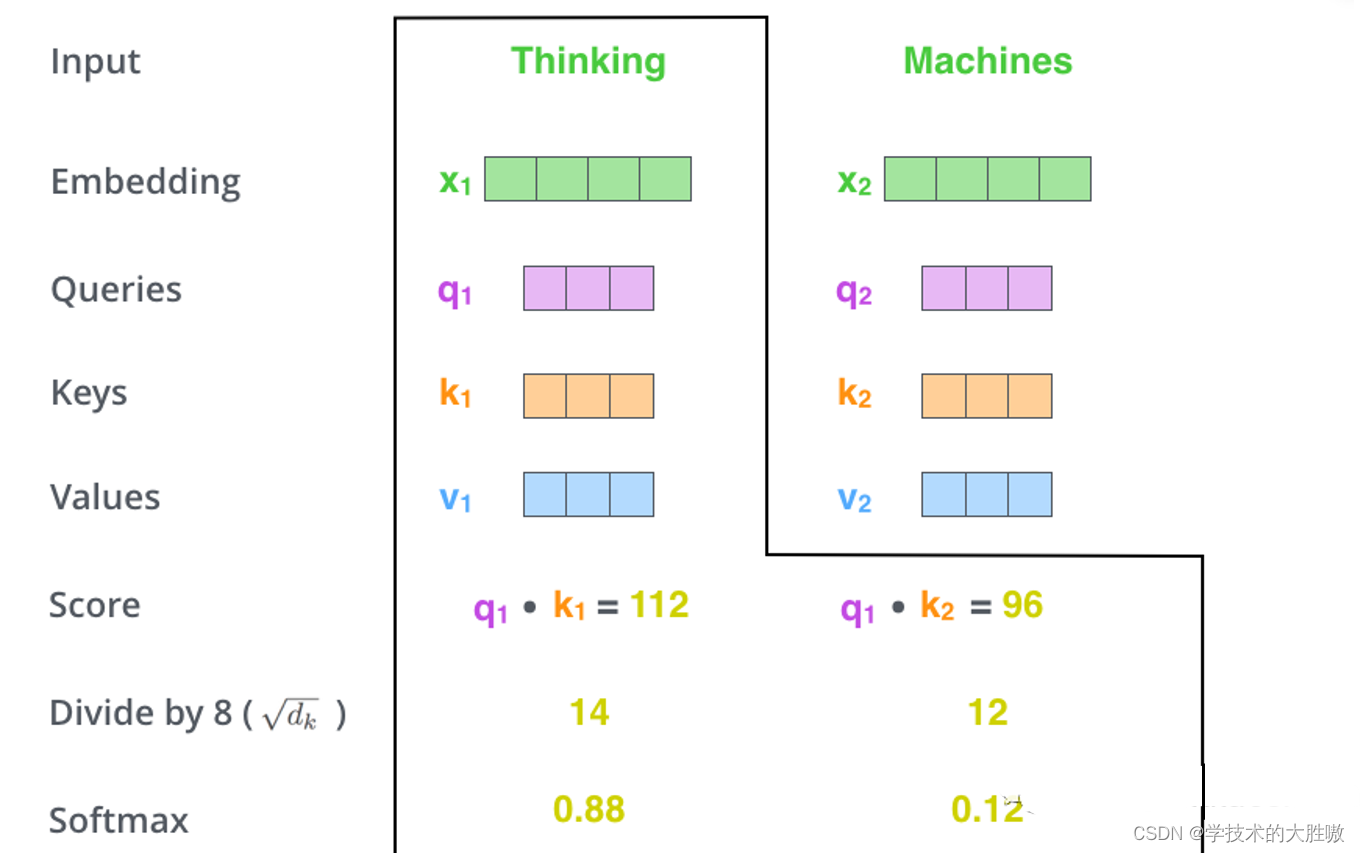
(3) 使用刚得到的权重矩阵,与V相乘,计算加权求和。
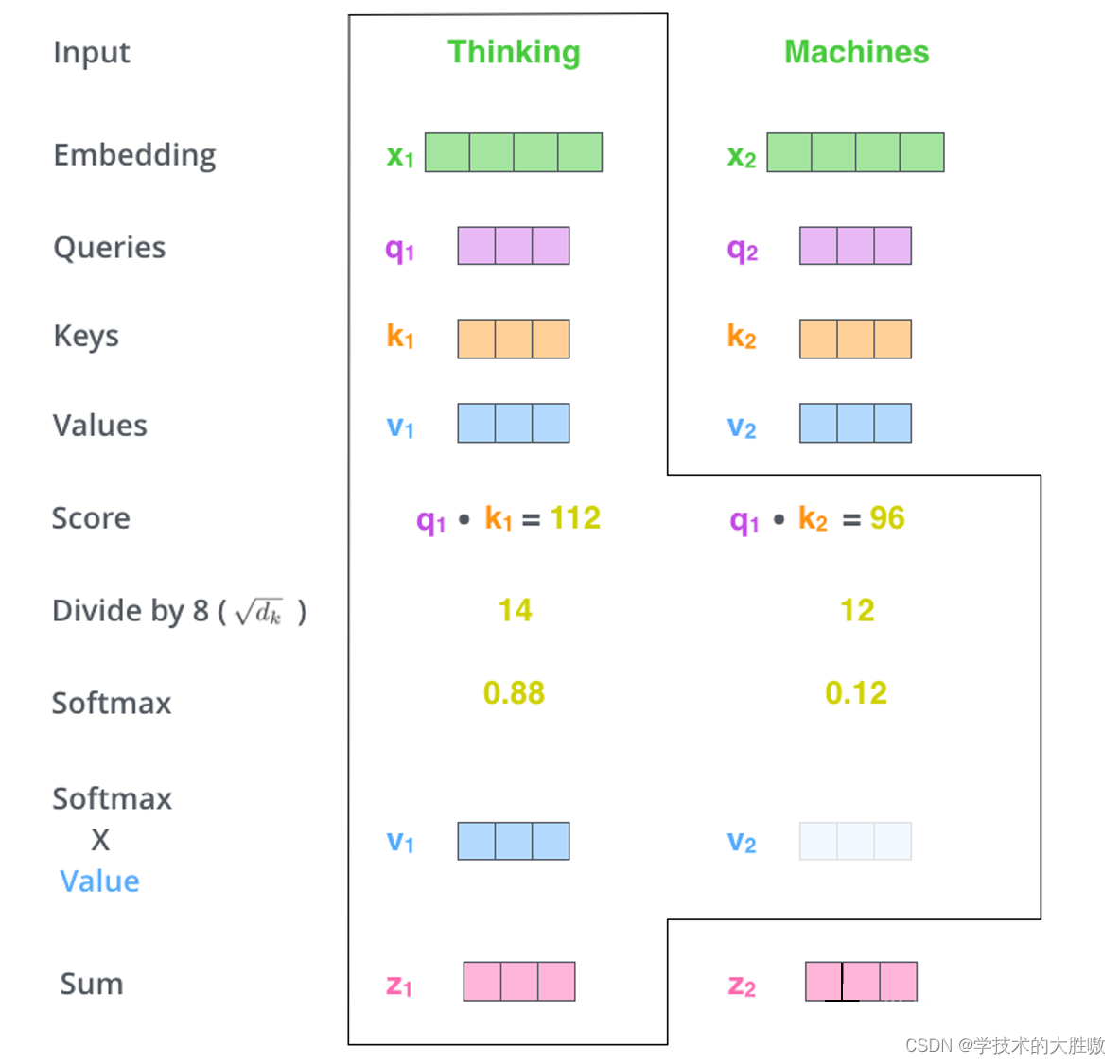
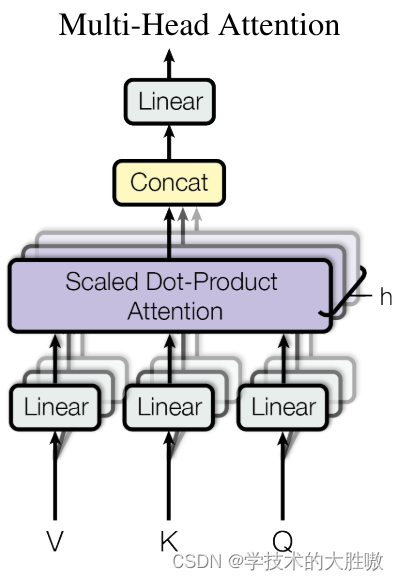
5、多头注意力
为了增强拟合性能,Transformer对Attention继续扩展,提出了多头注意力(Multiple Head Attention)。如下图
其实就是重复之前的步骤,如下图
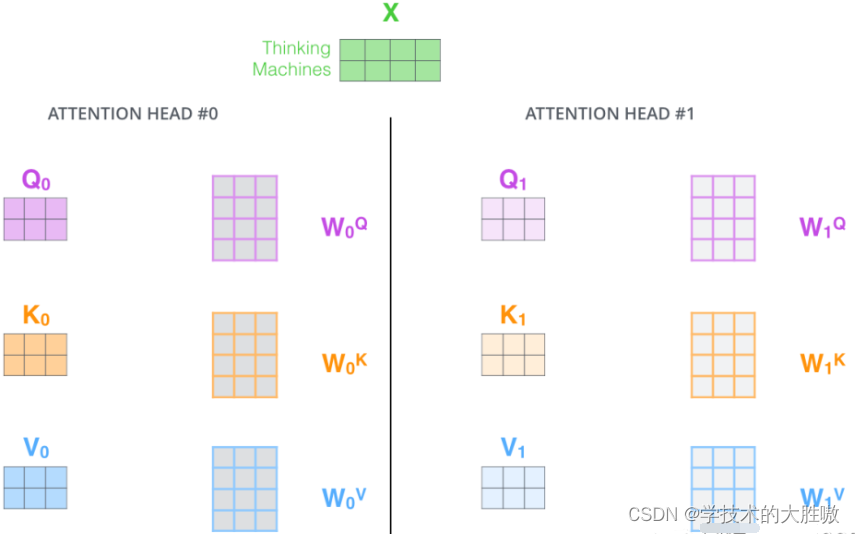
定义多组可训练的参数矩阵,生成多组Q、K、V。
比如我们定义8组参数,同样的输入X,最终会得到8个不同的输出,从Z0-Z7。
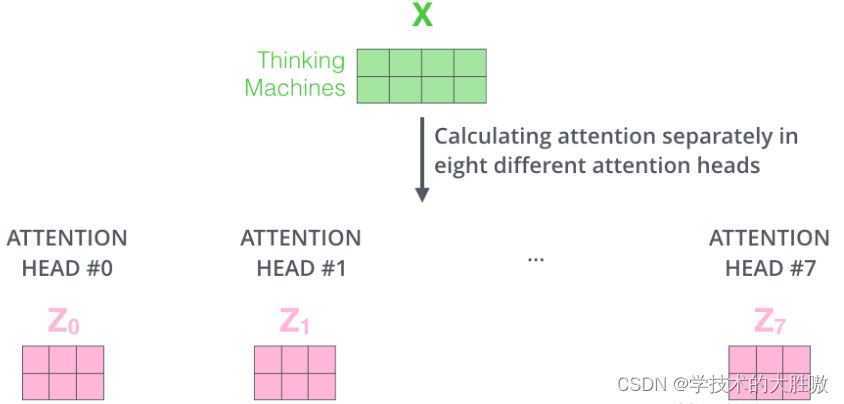
在输出到下一层前,需要将8个输出拼接到一起,乘以矩阵WO, 将维度降低回我们想要的维度。

输入的X是2行4列,QKV是2行3列,经过QKT得到2行2列,再乘以V得到2行3列的Z,8个Z拼接成2行24列的矩阵,通过乘以一个24行4列的矩阵WO可以变回X的2行4列,之后继续输入到下一层。
当前为后续层 时,即不是第一层的编码器,输入数据不再是原始文本,而是上一层编码器的输出。这意味着每一层都会接收前一层的输出作为自己的输入。
6、个人理解(如有不对,还请指正)
其实大家常说的Q 是Query,K 是Key,V 是Value,并非一定就是以我们主观上理解的逻辑。更多的是为transformer的有效性找到合理的解释,我个人理解为transformer的设计是empirical,那些解释是由果推因。
多头注意力机制为模型提供了一种并行处理信息的能力,允许它同时在多个表示子空间中捕捉数据的特征。这种设计不仅拓宽了模型的感知范围,而且使其能够在不同的潜在特征空间中探索更为丰富的信息维度。
这些特征空间中蕴含的信息,可能超出了人类直观理解的范畴,但正是这些难以捉摸的特征,为模型提供了更深层次的数据理解能力,从而在各种任务中展现出卓越的性能。