1. 项目介绍
最近某站看到一个看到利用AI创作视频解说,成品画面很酷炫。对此以初学者视角进行复现,创意来源:用AI制作历史解说视频

2. 开始创作
我们参照原作者展示的内容,对古代人物屈原来生成解说视频。
2.1 故事脚本+分镜 【由GPT-4o支持】
2.1.1 生成分镜
GPT对话:
以屈原人物解说为主题,写一个具有传奇色彩和反差感的人物传记故事脚本,一共涵盖10个分镜(包含画面和旁白)

2.1.2 细化内容(面向文生图)
GPT对话:
依次对十个分镜生成画面描述,用于midjourney绘图,并翻译成英文

初步得到优质的画面描述英文版
2.2 文生图【由MidJourney支持】
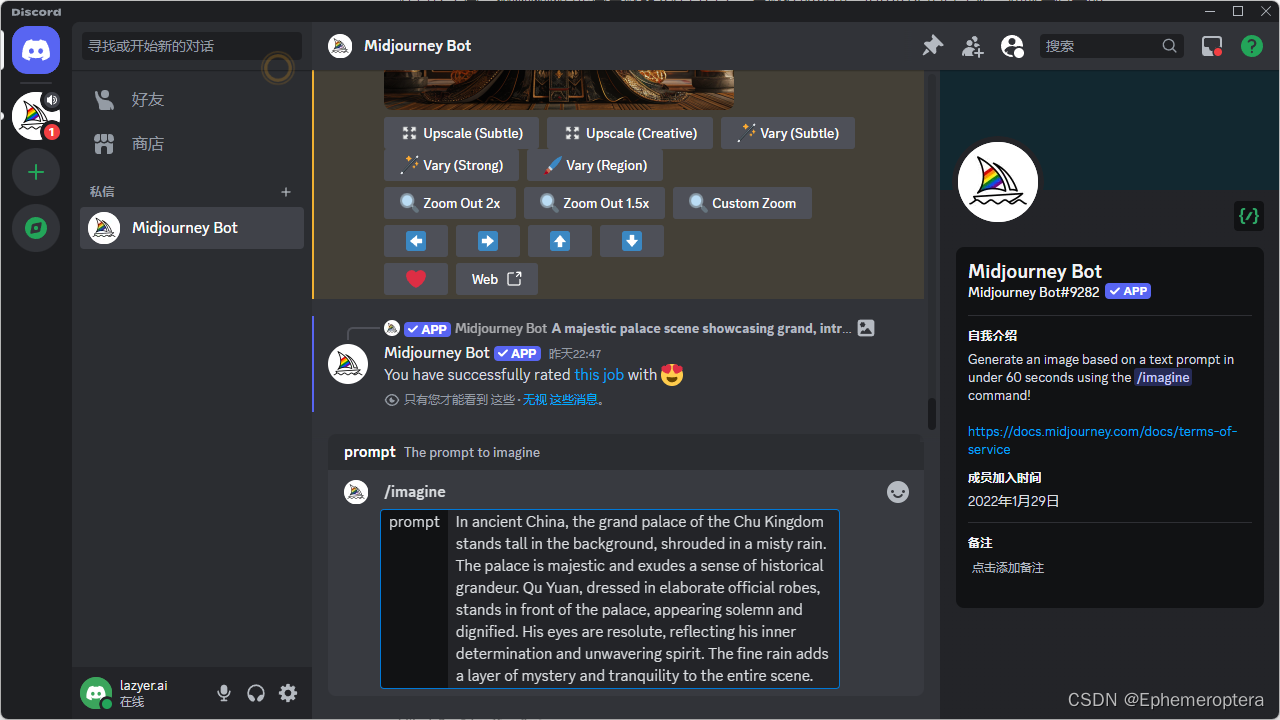
输入英文描述,
/Imagine promot描述
这里得到场景1生成的图片
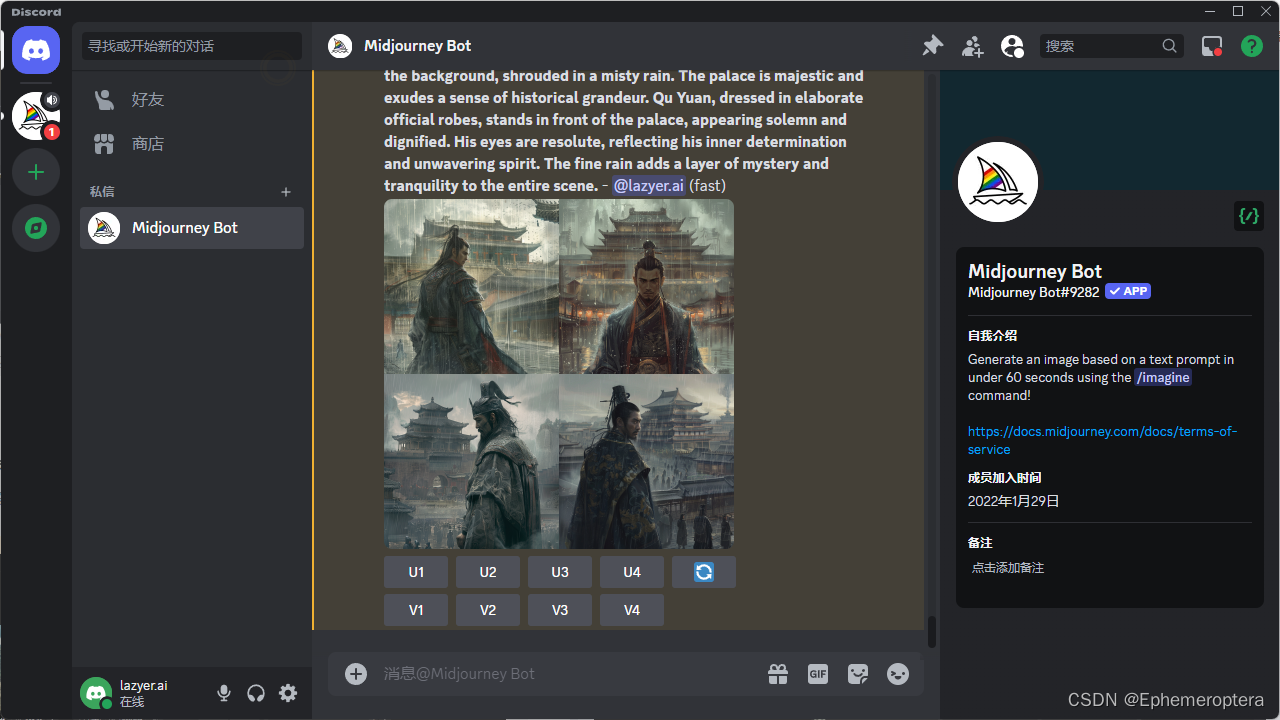
接下来我们需要根据第一张图片确定人物形象风格,来保证后续人物的一致性,获取该图片的链接用于后续场景图片生成的参数
对于后续图片的人物一致性,MidJourney 提供 "--cref <url>" 参数进行人物描绘参考
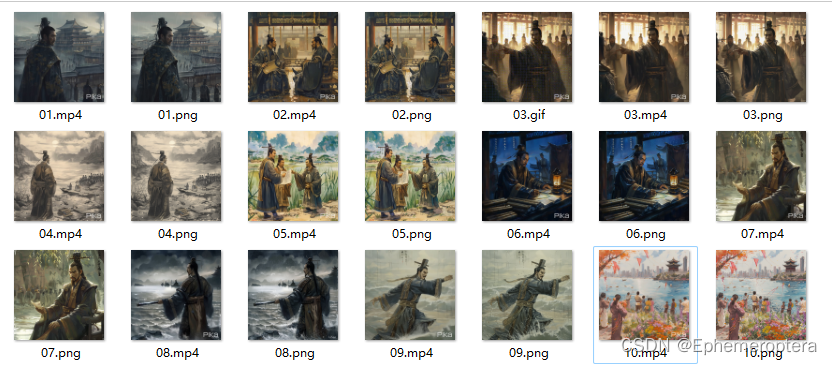
挑选了10张

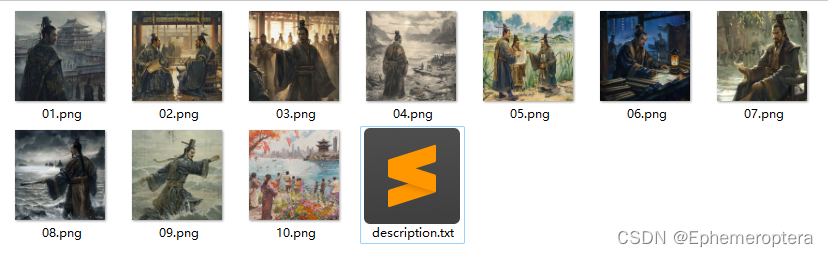
2.3 图生视频【由PiKa支持】
上传图片到pika,Strength of motion 设置为2,增加动感
效果如下
全部视频生成完毕,开始剪辑


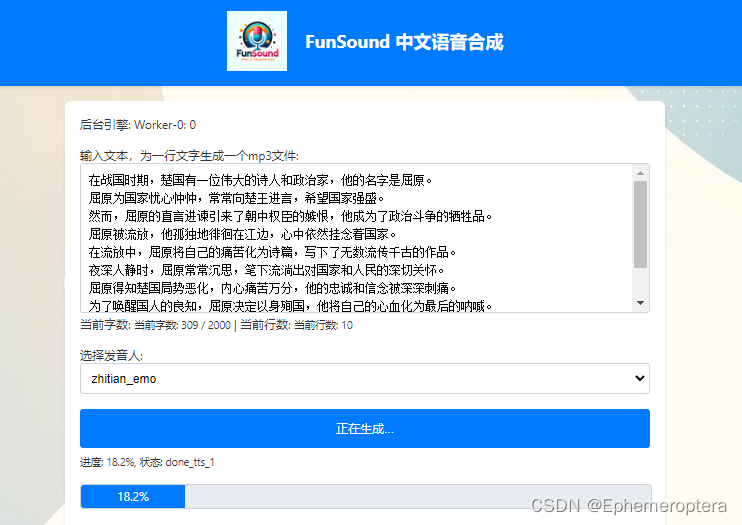
2.4 语音旁白【由Funsound支持】
这里为每个旁边生成语音
2.5 语音视频长度对齐
因为生成的视频和生成的音频长度不对等,这里我们需要保持音频长度不变,对视频帧率进行调整,长度一致后合成,顺便添加中文字幕。
参考我另一篇博客 音视频对齐,这里我给出python批量处理脚本
python
import os
from av_alignment import sync_audio_video_add_subtitle
def process(audio_dir,
video_dir,
text_file,
output_dir,
output_list_file,
font_path="./NotoSansCJKsc-Regular.ttf"):
if not os.path.exists(output_dir):os.makedirs(output_dir)
if os.path.exists(output_list_file):os.remove(output_list_file)
audio_list = os.listdir(audio_dir)
video_list = os.listdir(video_dir)
text_list = open(text_file,'rt',encoding='utf-8').readlines()
audio_list.sort()
video_list.sort()
i = 1
f = open(output_list_file,'a+')
for audio_file,video_file,text in zip(audio_list,video_list,text_list):
audio_file = os.path.join(audio_dir,audio_file)
video_file = os.path.join(video_dir,video_file)
text = text.strip()
out_file = '%s/%08d.mp4'%(output_dir,i)
print("audio_file:",audio_file)
print("video_file:",video_file)
print("text:",text)
sync_audio_video_add_subtitle(audio_path=audio_file,
video_path=video_file,
subtitle_text=text,
output_path=out_file,
font_path=font_path,
font_size=30, # 设置字体大小
font_color=(255, 255, 255), # 设置字体颜色
subtitle_bottom_margin=80)
i += 1
print(f"{out_file}",file=f)
f.close()
if __name__ == "__main__":
audio_dir = r"C:\Users\60568\Pictures\create\屈原\mp3"
video_dir = r"C:\Users\60568\Pictures\create\屈原\mp4"
text_file = r"C:\Users\60568\Pictures\create\屈原\subtitle.txt"
output_dir = "./sync"
output_list_file="./sync.txt"
output_video_file = "./output.mp4"
# 音视频对齐
process(audio_dir,
video_dir,
text_file,
output_dir=output_dir,
output_list_file=output_list_file)2.6 视频融合润色【由剪映支持】
将所有片段对齐好后,在剪映上进行对齐并配上bgm,然后导出完整视频

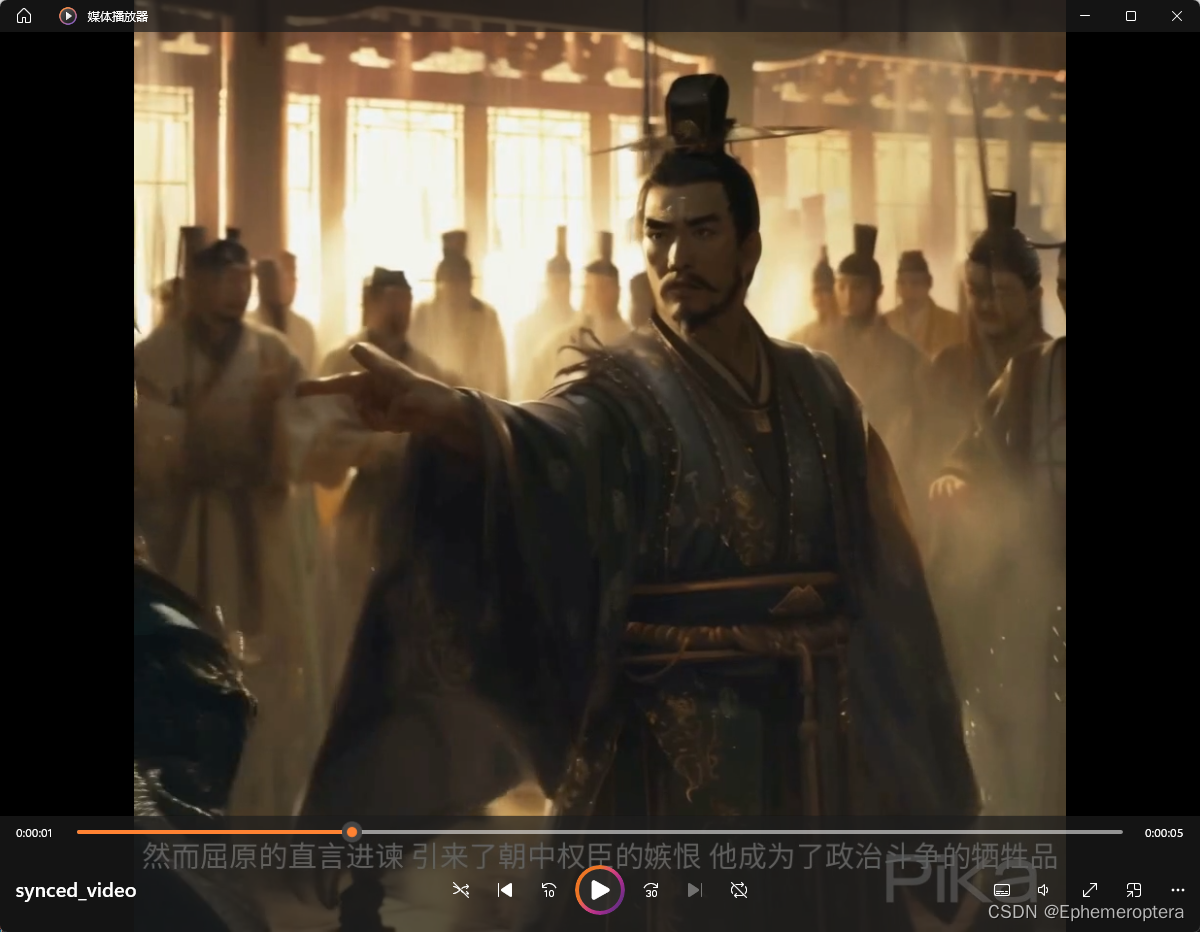
3. 成品展示
写到这终于完成了第一个ai视频的创作,比较粗糙,来看看成品吧:一分钟了解历史人物屈原
欢迎大家提出建议,感谢大家关注,博主会持续更新有趣的技术内容。
4.参考
https://mmmnote.com/article/7e8/03/article-ed3f6a082982ceb0.shtml
https://blog.csdn.net/Ephemeroptera/article/details/139553597?spm=1001.2014.3001.5502