个人介绍
hello hello~ ,这里是 code袁~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹
🦁作者简介 :一名喜欢分享和记录学习的在校大学生
💥个人主页 :code袁
💥 个人QQ :2647996100
🐯 个人wechat:code8896

专栏导航
code袁系列专栏导航
1 .毕业设计与课程设计:本专栏分享一些毕业设计的源码以及项目成果。🥰🥰🥰
2. 微信小程序开发:本专栏从基础到入门的一系开发流程,并且分享了自己在开发中遇到的一系列问题。🤹🤹🤹
3. vue开发系列全程线路:本专栏分享自己的vue的学习历程。非常期待和您一起在这个小小的互联网世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨


当涉及查找算法时,有许多不同的方法可供选择,每种方法都有其独特的特点和适用场景。以下是一篇关于查找算法的学习笔记,包括算法原理、代码示例和实际例子:
1. 线性查找(Linear Search)
算法原理 :线性查找算法,也被称为顺序查找算法,是一种简单的搜索算法,用于在一个元素集合中查找特定元素的位置或确定特定元素是否存在。
它的操作非常直观,它从集合的第一个元素开始,逐一检查每个元素,直到找到目标元素或者遍历整个集合为止。
代码示例:
python
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i
return -1
# 示例
arr = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
target = 5
result = linear_search(arr, target)
print("目标值在列表中的索引:", result)优缺性 :
(1)适用性:由于线性表有顺序存储和链式存储两种存储方式,顺序查找对这两种存储方式都适用,若对于顺序表,则通过数组的下标依次查找;对于链表,则通过指针依次查找,在链表中只能进行顺序查找。
(2)关键字比较次数:查找成功或不成功,关键字的比较次数始终是n+1次,当定位至第i个元素时,关键字的比较次数为n-i+1。由于这里采用监视哨(哨兵)的程序代码,若不采用监视哨,关键字的比较次数为n。
(3)平均查找长度:ASL成功=(n+1)/2,ASL不成功=n+1。
(4)时间复杂度:顺序查找的时间复杂度为O(n)。
(5)优缺点:顺序查找的优点是对元素的存储没有要求,可以顺序存储和链式存储,且对表内的有序性也没有要求;其缺点是当n较大时,ASL较大,导致效率低。
2. 二分查找(Binary Search)
算法原理 :二分查找要求在有序列表中查找目标值,通过比较目标值和列表中间元素的大小关系,缩小查找范围。
其基本步骤如下(设查找表有n个元素):
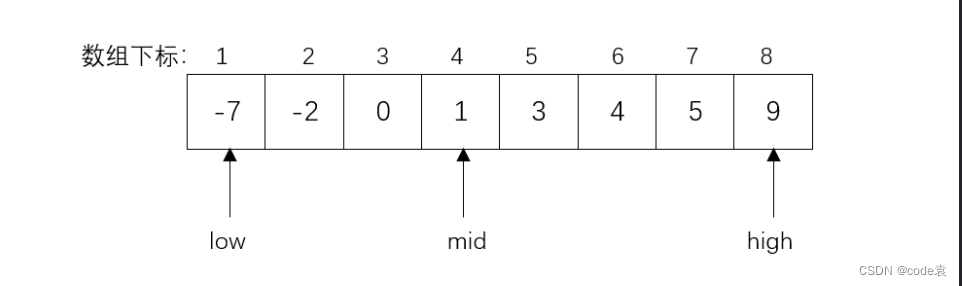
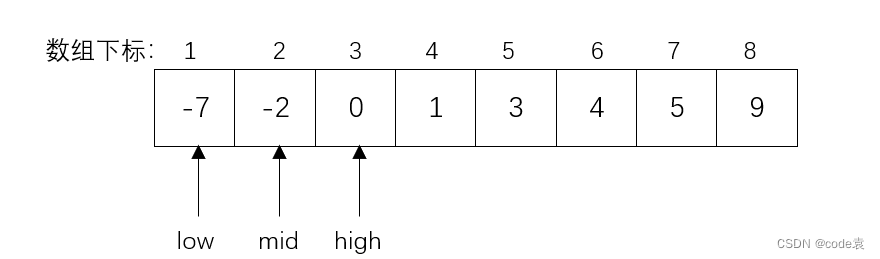
(1)初始查找范围,置初始变量范围,low=1,high=n;
(2)取中间元素,即mid=⌊(low+high)/2⌋(向下取整,取比它小的最大整数);
(3)将指定查找的关键字与中间元素进行比较,若相等,则表示查找成功,查找的元素即为mid指向的位置;若不相等,根据大于还是小于中间元素,选择中间元素的另一边元素继续进行比较:
①若查找关键字小于中间元素,low不变,high变为mid-1;
②若查找关键字大于中间元素,high不变,low变为mid+1。
(4)重复以上(2)、(3)步骤,直到查找成功或查找范围超出(low>high)为止。
代码示例:
python
def binary_search(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
# 示例
arr = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
target = 13
result = binary_search(arr, target)
print("目标值在列表中的索引:", result)
```。
### 3. 哈希表查找(Hash Table Search)
**算法原理**:哈希表通过哈希函数将键映射到存储桶中,实现快速的查找操作。
**代码示例**:
```python
# 使用Python内置的字典实现哈希表
hash_table = {'A': 1, 'B': 2, 'C': 3, 'D': 4}
# 查找操作
key = 'C'
if key in hash_table:
print("键'{}'对应的值为{}".format(key, hash_table[key]))
else:
print("键'{}'不存在".format(key))3. 分块查找
1、查找思想
分块查找也称为索引顺序查找,它将查找表分为若干块,要求每个块内可以无序,但块间是必须有序的,即上一块的最大关键字大于或小于后一块中的最小或最大关键字值。
另外,还需建立一个索引表,索引表内是按关键字排列有序的,索引表中的一项对应线性表的一块,索引表内由关键字域和指针域组成,前者存放该块内的最大关键字,后者存放指向该块中第一个和最后一个元素的指针(数组下标值)。
#include <stdio.h>
// 定义块的结构
struct Block {
int size; // 块的大小
int *data; // 块内的数据
int max; // 块内数据的最大值(用于加速搜索)
};
// 分块查找函数
int blockSearch(struct Block blocks[], int numBlocks, int target) {
int blockIndex = 0;
// 在每个块中进行线性查找,找到包含目标值的块
while (blockIndex < numBlocks && target > blocks[blockIndex].max) {
blockIndex++;
}
// 在找到的块中进行线性查找
for (int i = 0; i < blocks[blockIndex].size; i++) {
if (blocks[blockIndex].data[i] == target) {
return blockIndex * blocks[blockIndex].size + i; // 返回元素的全局索引
}
}
// 如果未找到目标值
return -1;
}
int main() {
// 示例数据
struct Block blocks[] = {
{5, (int[]){1, 3, 5, 7, 9}, 9},
{5, (int[]){11, 13, 15, 17, 19}, 19},
{4, (int[]){21, 23, 25, 27}, 27}
};
int numBlocks = sizeof(blocks) / sizeof(blocks[0]);
int target = 15;
// 执行分块查找
int result = blockSearch(blocks, numBlocks, target);
if (result != -1) {
printf("元素 %d 在数组中的索引是 %d。\n", target, result);
} else {
printf("元素 %d 不在数组中。\n", target);
}
return 0;
}优缺性
1.减小查找范围: 分块查找充分利用了数据集的分块结构,可以迅速定位到包含目标元素的块,从而缩小了查找范围,减少了查找的时间复杂度。
2.适用于分布式存储: 当数据分布在多个块中,每个块都可以存储在不同的存储设备或位置上时,分块查找可以用于分布式存储系统中,提高查找效率。
3.适用于静态数据: 如果数据集是静态的,即不会频繁发生插入、删除等操作,分块查找可以更好地发挥其优势。因为在动态数据集中,频繁的插入和删除可能导致块的重新组织,增加了实现的复杂性。
4.块内线性查找: 在找到包含目标元素的块后,仍需要在该块内进行线性查找。如果块内的元素数量较大,查找效率可能不如其他更高效的算法。
5.对块的依赖性: 分块查找对于块的划分敏感,如果块的划分不合理,可能导致查找效率下降。因此,块的选择需要谨慎,并且在动态数据集中可能需要频繁调整块的划分。
6.不适用于动态数据: 在频繁发生插入和删除操作的动态数据集中,分块查找可能需要频繁地调整块的划分,导致算法复杂度增加,不如一些更适合动态数据的数据结构和算法。
🎉写在最后
🍻伙伴们,如果你已经看到了这里,觉得这篇文章有帮助到你的话不妨点赞👍或 Star ✨支持一下哦!手动码字,如有错误,欢迎在评论区指正💬~
你的支持就是我更新的最大动力💪~
