参考资料:活用pandas库
1、k均值聚类
使用k均值算法,首先要选定数据中的群集数(k)。它会随机选取数据中的k个点,计算每个数据点到最初选取的k个点之间的距离。最接近某个群集的点会被划分到同一个集群组。然后把每个群集的中心指定为新的集群中心。重复该过程,计算每个点到每个群集中心的距离,并将其分配给一个群集,然后选择一些新的中心。该算法会重复执行直至收敛。
python
# 导入pandas库
import pandas as pd
# 读取数据集
wine=pd.read_csv(r"...\data\wine.csv")
# 数据展示,注意:数据值全是数值
print(wine.head())
# 删除Cultivar列,因为它与数据中的实际群集关联太过紧密
wine=wine.drop("Cultivar",axis=1)
# 导入KMeans模块
from sklearn.cluster import KMeans
# 创建3个群集
# 设置随机种子
kmeans=KMeans(n_clusters=3,random_state=42).fit(wine.values)
# 输出kmeans对象
print(kmeans)
import numpy as np
print(np.unique(kmeans.labels_,return_counts=True))由于人眼只能看到三维空间中的事物,所以需要减少数据的维数(至少要降至3维)。而且由于在纸张上绘制这些点,应尽量把维数降至2。
主成分分析(PCA)是一种投影技术,用于减少数据集的维数。其工作原理是在数据中找到较低的维数,将方差最大化。
python
# 从sklearn库中导入PCA模块
from sklearn.decomposition import PCA
# 把数据投射到两个成分上
pca=PCA(n_components=2).fit(wine)
# 转换数据到新空间
pca_trans=pca.transform(wine)
# 为投影命名
pca_trans_df=pd.DataFrame(pca_trans,columns=['pca1','pca2'])
# 连接数据
kmeans_3=pd.DataFrame(kmeans.labels_,columns=['cluster'])
kmeans_3=pd.concat([kmeans_3,pca_trans_df],axis=1)
print(kmeans_3.head())
# 绘制散点图
import seaborn as sns
import matplotlib.pyplot as plt
fig=sns.lmplot(x='pca1',y='pca2',data=kmeans_3,
hue='cluster',fit_reg=False)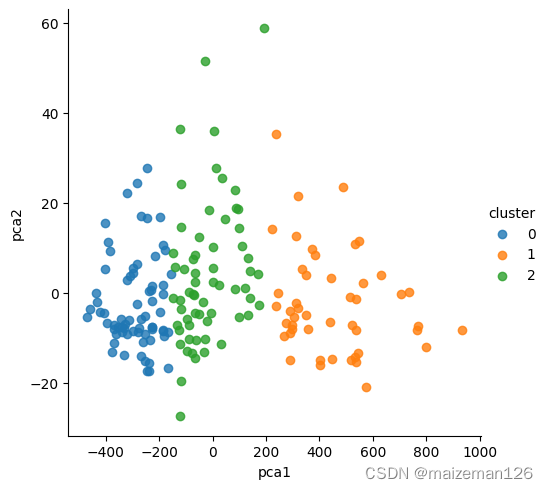
2、层次聚类
层次聚类旨在构建群体层次结构。具体实现方法有两种:一种是自下而上的凝聚法,另一种是从上到下的分裂法。
(1)最长距离法
python
# 导入hierarchy模块
from scipy.cluster import hierarchy
wine_complete=hierarchy.complete(wine)
fig=plt.figure()
dn=hierarchy.dendrogram(wine_complete)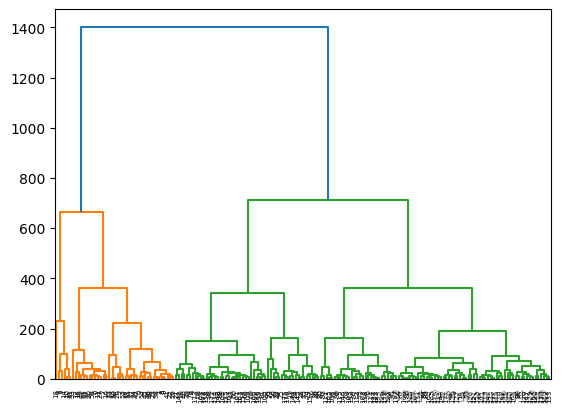
(2)最短距离法
python
wine_single=hierarchy.single(wine)
fig=plt.figure()
dn=hierarchy.dendrogram(wine_single)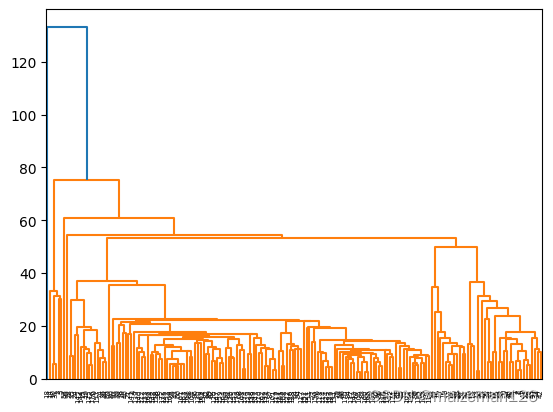
(3)平均距离法
python
wine_average=hierarchy.average(wine)
dn=hierarchy.dendrogram(wine_average)
(4)重心法
python
wine_centroid=hierarchy.centroid(wine)
dn=hierarchy.dendrogram(wine_centroid)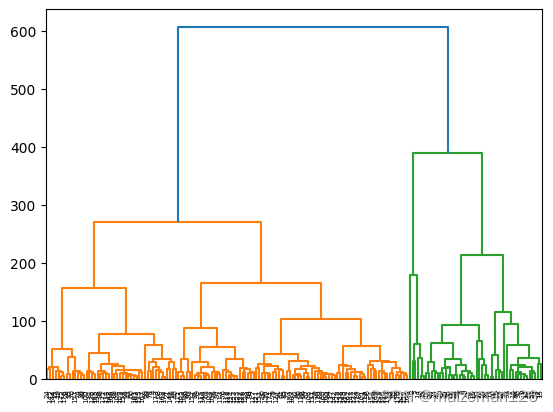
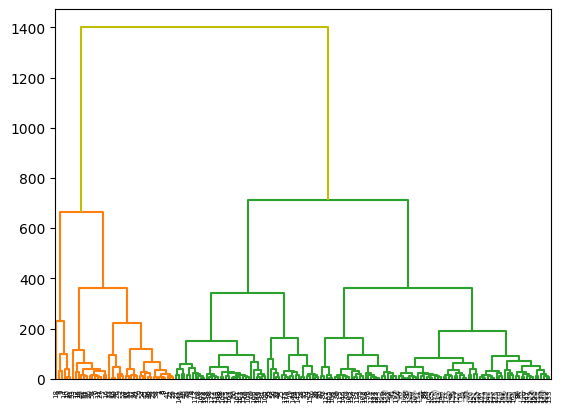
(5)手动设置阈值
可以为color_threshold传入值来根据特定阈值给组着色。scipy默认使用预设的MATLAB值。
python
wine_complete=hierarchy.complete(wine)
fig=plt.figure()
dn=hierarchy.dendrogram(
wine_complete,
# 默认MATLAB阈值
color_threshold=0.7*max(wine_complete[:,2]),
above_threshold_color='y'
)