哨兵机制中总结到,它并不能解决存储容量不够的问题,但是集群能。
-
广义的集群:只要有多个机器,构成了分布式系统,都可以称之为一个"集群",例如主从结构中的哨兵模式。
-
狭义的集群:redis 提供的集群模式,该模式主要是解决存储空间不够的问题(拓展存储空间)
集群的基本原理
在哨兵模式中,本质上还是 redis 主从节点存储数据,就要求一个主节点/从节点,存储整个数据的"全集",当数据量很大的时候就需要很大的内存,这时候把数据全保存在一台机器上就不太合适。
所以,就需要引入多台机器,每台机器存储一部分数据。
但是,并不是多引入机器就够了,每一台机器还要有对应的从节点,主要是为了在主节点挂了的情况下,进行数据备份。

怎么把数据分成多份(分片方法)
哈希求余
设有 N 个分片,使用0, N - 1这样的序号进行编号
针对某个给定的 key,先计算 hash 值,再把得到的结果 % N,得到的结果即为分片编号
但是,这样的方法在数据量持续增大,大到需要进一步增加机器的时候,或者缩容的时候,开销比较大。
因为机器的数量增多,就意味着 N 的大小变化了,求出的 hash 值也会变化,这时需要将原来的分片中的数据搬运到新的位置。
而且并不只是从一台数据搬运到另一台数据,还需要重新进行数据的备份。
所以,为了避免这么大的开销,往往不能直接在生产环境上操作,只能通过"替换"的方式实现;也就是不改变机器中存储的数据,而改变各台机器的主从关系。但这样的做法需要依赖更多的机器,成本更高,操作步骤复杂。
一致性哈希算法
为了降低上述的搬运开销,能够更高效扩容,业界提出来"一致性哈希算法"。
key 映射到分片序号的过程不再是简单求余,而是改为以下过程
- 把 0 - 2^32 - 1 这个数据空间,映射到一个圆环上,数据按照顺时针方向增长

- 假设当前存在三个分片,就把分片放到圆环的某个位置上
- 假定有一个 key,计算得到 hash 值 H,那么这个 key 就从 H 所在位置,顺时针往下找,找到的第一个分片即为该 key 所从属的分片
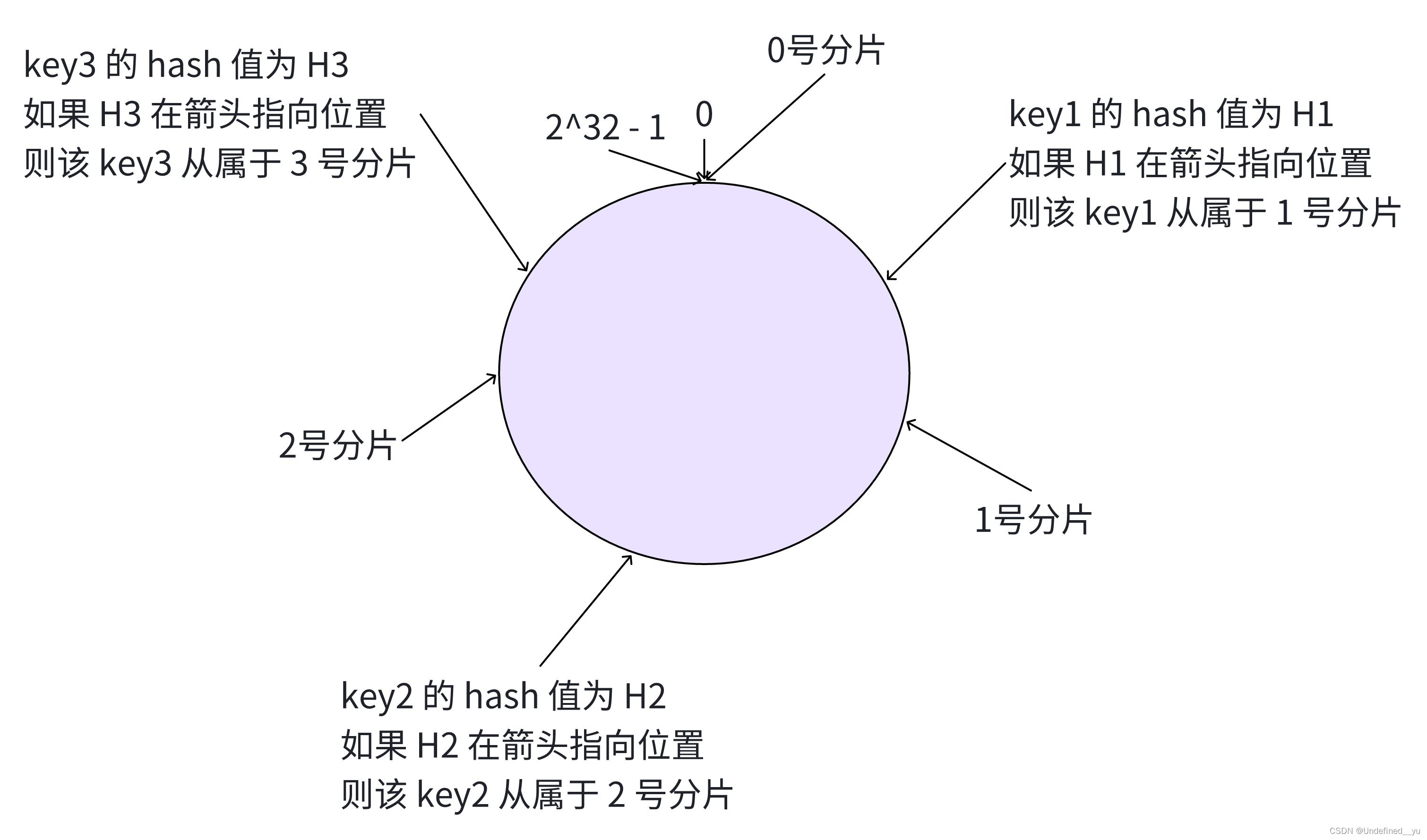
这就相当于,N 个分片的位置,把整个圆环分成了 N 个管辖区间,key 的 hash 值落在某个区间内,就归对应区间管理。

基于这种规则,连续的值不再是交替地出现在每一个分区中,而是连续的值处于一个分区,再增容或者缩容的时候,需要数据搬运的概率就大大降低了,需要搬运的数据也减少了。
但是,虽然搬运成本低了,但这几个分片上的数据量,可能会不再均匀(数据倾斜)。
哈希槽分区算法(Redis真正采用的方法)
为了解决上述问题(搬运成本高和数据分配不均匀),Redis cluster 引入了哈希槽(hash slots)算法。
hash_slot = clc16(key) % 16384
其中 clc16 也是一种 hash 算法,16384 是 16 * 1024,也就是 2^14。
相当于把整个哈希值,映射到 16384 个槽位上,也就是 0, 16384。
然后再把这些槽位比较均匀地分配给每个分片,每个分片的节点都需要记录自己持有哪些分片。
假设当前有三个分片,一种可能的分配方式:
-
0 号分片:0, 5461,共 5462 个槽位
-
1 号分片:5462, 10923,共 5462 个槽位
-
2 号分片:10924, 16383,共 5460 个槽位
这里的分片规则是很灵活的,每个分片持有的槽位也不一定连续。
每个分片的节点使用位图来表示自己持有哪些槽位,对于 16384 个槽位来说,需要 2048 个字节(2KB)大小的内存空间表示。
如果需要进行扩容,就可以针对原有的槽位进行重新分配。
一种可能的分配方式:
-
0 号分片:0, 4095,共 4096 个槽位
-
1 号分片:5462, 9557,共 4096 个槽位
-
2 号分片:10924, 15019,共 4096 个槽位
-
3 号分片:4096, 5461 + 9558, 10923 + 15020, 16383,共 4096个槽位
在实际使用 Redis 集群分片的时候,不需要手动指定哪些槽位分配给某个分片,只需要告诉某个分片应该持有多少个槽位即可,Redis 会自动完成后续的槽位分配,以及对应的 key 搬运的工作。
Redis 集群最多有 16384 个分片吗?
不是的,如果集群有 16384 个分片,就意味着每个分片上只有一个槽位。key 值需要先映射到槽位,再映射到分片。如果每个分片包含的槽位比较多,并且槽位个数相当,就可以认为包含的 key 的数量相当;但如果每个分片的槽位很少,就不能直观地反应出 key 的数量,因为经过 hash 映射后具体到哪个分片的随机性比较大。
而且,如果分片个数达到 1.6w 这么大,所需要的主机数可能会达到 4w 以上,集群规模太大,可用性就会很难保证,出故障的概率会变大。
实际上,Redis 的作者建议集群分片数不应该超过 1000.
为什么是 16384 个槽位?
-
节点之间通过心跳包通信,心跳包中包含了该节点持有哪些 slots。这个是使用位图的结构表示的,表示 16384(16k)个 slots,需要的位图大小是 2KB。如果给定的 slots 数更多了,则需要消耗更多的空间,8KB来表示。这样的空间虽然对于内存来说不算什么,但是在频繁的网络心跳包中,是一个不小的开销。
-
另一方面,Redis 集群一般不建议超过 1000 个分片。所以 16K 对于最大 1000 个分片来说是足够用的,同时也会使对应的槽位配置位图体积不至于很大。
故障处理
故障判定
集群中的所有节点,都会周期性的使用心跳包进行通信。
-
节点 A 给节点 B 发送 ping 包,B 就会给 A 返回一个 pong 包。ping 和 pong 处理 message type 属性之外,其他部分都是一样的。这里包含了集群的配置信息(该节点的 id,该节点从属于哪个分片,是主节点还是从节点,从属于谁,持有哪些 slots 的位图...)。
-
每个节点每秒钟都会给一些随机的节点发起 ping 包,而不是全发一遍。这样设定是为了避免在节点很多的时候,心跳包也非常多(比如有 9 个节点,如果全发,就是 9 * 8 有 72 组心跳了,而且这是按照 N^2 这样的级别增长的)。
-
当节点 A 给节点 B 发起 ping 包,B 不能如期回应的时候,此时 A 就会尝试重置和 B 的 TCP 连接,看能否连接成功。如果仍然连接失败,A 就会把 B 设为 PFAIL 状态(相当于主观下线)。
-
A 判定 B 为 FAIL 之后,会通过 redis 内置的 Gossip 协议,和其他节点进行沟通,向其他节点确认 B 的状态(每个节点都会维护一个自己的"下线列表",由于视角不同,每个节点的下线列表也不一定相同)。
-
此时 A 发现其他很多节点,也认为 B 为 FAIL,并且数目超过总集群个数的一半,那么 A 就会把 B 标记成 FAIL(相当于客观下线),并把这个消息同步给其他节点(其他节点收到之后,也会把 B 标记成 FAIL)。
至此,B 就彻底被判定为故障节点了。
某个或某些节点宕机,有时候会引起整个集群都宕机(成为 FAIL 状态)。
以下三种情况会出现集群宕机:
-
某个分片,所有的主节点和从节点都挂了。
-
某个分片,主节点挂了,但没有从节点。
-
超过一半的 master 节点挂了。
核心原则是保证每个 slots 都能正常工作(存取数据)
故障迁移
上述例子中,B 故障,并且 A 把 B FAIL 的消息告知集群中的其他节点。
-
如果 B 是从节点,则不需要进行故障迁移。
-
如果 B 是主节点,则会由 B 的从节点(例如 C 和 D)触发故障迁移。
所谓的故障迁移,就是把从节点提拔成主节点,继续给整个 redis 集群提供支持。
具体流程如下:
-
从节点判定自己是否具有参选资格。如果从节点和主节点已经太久没有通信(此时认为从节点中的数据和主节点相差太大了),时间超过阈值,就失去竞选资格。
-
具有资格的结点,例如 C 和 D,就会先休眠一段时间。休眠时间 = 500ms 基础时间 + 0, 500ms 随机时间 + 排名 * 1000ms。offset 的值越大,则排名越靠前。
-
例如 C 的休眠时间到了,C 就会给其他所有集群中的节点,进行拉票操作。但只有主节点才有投票资格。
-
主节点就会把自己的票投给 C(每个主节点只有 1 票)。当 C 收到的票数超过主节点数目的一半,C 就会晋升成主节点(C 自己负责执行 slaveof no one,并让 D 执行 slaveof C)。
-
同时,C 还会把自己成为主节点的消息,同步给其他集群的节点,大家也都会更新自己保存的集群结构信息。
上述选举的过程,称为 Raft 算法,是一种在分布式系统中广泛使用的算法。
在随机休眠时间的加持下,基本上就是谁先唤醒,谁就能竞选成功。