1.flume作为生产者集成Kafka
kafka作为flume的sink,扮演消费者角色
1.1 flume配置文件
vim $kafka/jobs/flume-kafka.conf
bash
# agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = TAILDIR
#记录最后监控文件的断点的文件,此文件位置可不改
a1.sources.r1.positionFile = /export/server/flume/job/data/tail_dir.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /export/server/flume/job/data/.*file.*
a1.sources.r1.filegroups.f2 =/export/server/flume/job/data/.*log.*
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = customers
a1.sinks.k1.kafka.bootstrap.servers =node1:9092,node2:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c11.2开启flume监控
flume-ng agent -n a1 -c conf/ -f /export/server/kafka/jobs/kafka-flume.conf
1.3开启Kafka消费者
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092 --topic consumers --from-beginning
1.4生产数据
往被监控文件输入数据
ljr@node1 data$echo hello >>file2.txt
ljr@node1 data$ echo ============== >>file2.txt
查看Kafka消费者
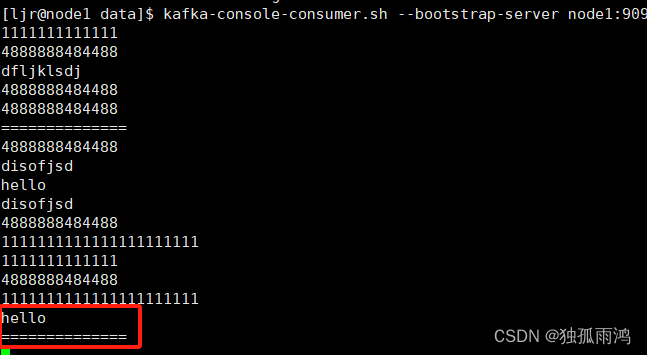
可见Kafka集成flume生产者成功。
2.flume作为消费者集成Kafka
kafka作为flume的source,扮演生产者角色
2.1flume配置文件
vim $kafka/jobs/flume-kafka.conf
bash
# agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
#注意不要大于channel transactionCapacity的值100
a1.sources.r1.batchSize = 50
a1.sources.r1.batchDurationMillis = 200
a1.sources.r1.kafka.bootstrap.servers =node1:9092, node1:9092
a1.sources.r1.kafka.topics = consumers
a1.sources.r1.kafka.consumer.group.id = custom.g.id
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
#注意transactionCapacity的值不要小于sources batchSize的值50
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12.2开启flume监控
flume-ng agent -n a1 -c conf/ -f /export/server/kafka/jobs/kafka-flume1.conf
2.3开启Kafka生产者并生产数据
kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092 --topic consumers

查看flume监控台

可见Kafka集成flume消费者成功。