
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
引言
作为一名深耕分布式系统多年的技术人,常常被问到:"分布式计算到底是什么?它为什么如此重要?"在这个数据爆炸的时代,单体系统已经无法满足日益增长的计算需求,分布式计算应运而生,成为支撑现代互联网架构的基石。
一、分布式计算的基本概念
1.1 什么是分布式计算
分布式计算是一种计算模式,它将一个复杂的计算任务分解成多个子任务,分配给不同的计算节点并行执行,最后将结果汇总得到最终答案。这种模式使得我们能够突破单机性能的限制,处理规模更大、复杂度更高的问题。
"分布式计算的本质是资源调度和数据协同。" ------ 分布式系统先驱 Leslie Lamport
1.2 分布式计算的核心特点
分布式计算具有以下几个核心特点:
- 并发性:多个节点同时处理任务
- 分布性:计算资源物理分布在不同位置
- 异构性:节点可能使用不同的硬件和软件
- 自治性:每个节点可以独立运行和管理
- 故障恢复:系统能够从部分节点故障中恢复
二、分布式计算的关键技术
2.1 分布式通信
分布式系统中,节点间通信是基础。主要有两种通信模型:
2.1.1 消息传递模型
消息传递是最基本的通信方式,节点通过发送和接收消息进行交互。
python
# 简单的分布式消息传递示例
import socket
import json
# 服务端代码
def start_server(host='0.0.0.0', port=8888):
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((host, port))
server_socket.listen(5)
print(f"服务器启动,监听端口 {port}")
while True:
client_socket, addr = server_socket.accept()
print(f"客户端连接: {addr}")
# 接收数据
data = client_socket.recv(1024).decode('utf-8')
task = json.loads(data)
# 处理任务
result = process_task(task)
# 返回结果
response = json.dumps(result)
client_socket.send(response.encode('utf-8'))
client_socket.close()
# 客户端代码
def send_task(task, host='localhost', port=8888):
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect((host, port))
# 发送任务
data = json.dumps(task)
client_socket.send(data.encode('utf-8'))
# 接收结果
response = client_socket.recv(1024).decode('utf-8')
result = json.loads(response)
client_socket.close()
return result2.1.2 RPC(远程过程调用)
RPC允许程序像调用本地函数一样调用远程服务,大大简化了分布式编程。
python
# 使用Python的xmlrpc实现简单RPC
from xmlrpc.server import SimpleXMLRPCServer
from xmlrpc.client import ServerProxy
# 服务端
def start_rpc_server(host='0.0.0.0', port=8000):
server = SimpleXMLRPCServer((host, port))
server.register_introspection_functions()
# 注册计算函数
server.register_function(add, 'add')
server.register_function(multiply, 'multiply')
print(f"RPC服务器启动,监听端口 {port}")
server.serve_forever()
def add(x, y):
return x + y
def multiply(x, y):
return x * y
# 客户端
def call_remote_function():
proxy = ServerProxy('http://localhost:8000/')
result1 = proxy.add(5, 3) # 调用远程add函数
result2 = proxy.multiply(4, 7) # 调用远程multiply函数
return result1, result22.2 分布式一致性
分布式一致性是分布式系统中最核心的挑战之一,涉及到多个节点对数据状态达成一致的过程。
2.2.1 一致性协议
Paxos和Raft是两种最著名的分布式一致性协议。下面我们来看Raft协议的基本流程:
python
# Raft协议简化实现(状态机部分)
class RaftNode:
def __init__(self, node_id, all_nodes):
self.node_id = node_id
self.all_nodes = all_nodes
self.state = "follower" # follower, candidate, leader
self.current_term = 0
self.voted_for = None
self.log = []
self.commit_index = 0
self.last_applied = 0
def start_election(self):
"""开始选举过程"""
self.current_term += 1
self.state = "candidate"
self.voted_for = self.node_id
votes = 1 # 给自己投票
# 请求其他节点投票
for node in self.all_nodes:
if node != self.node_id:
if self.request_vote(node):
votes += 1
# 获得多数票则成为leader
if votes > len(self.all_nodes) // 2:
self.state = "leader"
self.start_heartbeat()
def request_vote(self, target_node):
"""向目标节点请求投票"""
# 实际实现中会通过网络发送投票请求
# 这里简化处理,返回True表示获得投票
return True
def start_heartbeat(self):
"""开始发送心跳维持leader地位"""
print(f"节点 {self.node_id} 成为leader,开始发送心跳")图1展示了Raft协议的基本工作流程:
领导阶段 选举阶段 初始化阶段 初始状态 选举超时 增加任期号 发送RequestVote 获得多数票 收到更高任期 收到同任期Leader消息 定期发送心跳 接收客户端请求 复制到多数节点 应用到状态机 维持Leader地位 追加日志 提交日志 响应客户端 投票给自己 收集投票 成为Leader 退化为Follower Follower状态 节点启动 转变为Candidate
图1:Raft协议工作流程图 - 展示了Raft共识算法的三个主要阶段:初始化、选举和领导阶段,以及各状态之间的转换关系。
2.3 分布式协调
分布式协调服务用于管理分布式系统中的配置信息、命名服务、分布式锁等功能。ZooKeeper是最流行的分布式协调服务之一。
python
# 使用ZooKeeper实现分布式锁
from kazoo.client import KazooClient
import time
import uuid
class DistributedLock:
def __init__(self, zk_servers, lock_path):
self.zk = KazooClient(servers=zk_servers)
self.zk.start()
self.lock_path = lock_path
self.lock_node = None
def acquire(self, timeout=10):
"""获取分布式锁"""
# 创建临时顺序节点
self.lock_node = self.zk.create(
f"{self.lock_path}/lock_",
ephemeral=True,
sequence=True
)
# 获取所有锁节点
start_time = time.time()
while time.time() - start_time < timeout:
# 获取所有锁节点并排序
lock_nodes = sorted(self.zk.get_children(self.lock_path))
# 检查是否获得锁(自己的节点是否是第一个)
if self.lock_node.endswith(lock_nodes[0]):
return True
# 监听前一个节点的删除事件
prev_node = lock_nodes[lock_nodes.index(lock_nodes[0]) - 1]
event = threading.Event()
self.zk.DataWatch(f"{self.lock_path}/{prev_node}",
func=lambda data, stat, event:
event.is_deleted and event.set())
# 等待前一个节点释放锁
event.wait(timeout=timeout - (time.time() - start_time))
# 超时,释放资源
self.release()
return False
def release(self):
"""释放分布式锁"""
if self.lock_node and self.zk.exists(self.lock_node):
self.zk.delete(self.lock_node)
self.lock_node = None
def close(self):
"""关闭ZooKeeper连接"""
self.release()
self.zk.stop()三、分布式计算框架实践
3.1 MapReduce:分布式计算的经典框架
MapReduce是Google提出的分布式计算框架,它将复杂的分布式计算任务抽象为Map和Reduce两个阶段。
图2展示了MapReduce的工作流程:
客户端 作业跟踪器 Map节点 Shuffle阶段 Reduce节点 分布式文件系统 提交MapReduce作业 读取输入数据 分配Map任务 读取数据块 执行Map函数 输出中间结果 数据分区和排序 分配Reduce任务 执行Reduce函数 输出最终结果 返回计算结果 客户端 作业跟踪器 Map节点 Shuffle阶段 Reduce节点 分布式文件系统
图2:MapReduce工作流程图 - 时序图展示了MapReduce作业从提交到完成的完整流程,包括任务分配、数据处理和结果输出的各个环节。
下面是使用Hadoop MapReduce实现单词计数的示例:
java
// WordCountMapper.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
// WordCountReducer.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
// WordCountDriver.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}3.2 Spark:内存计算的分布式框架
Apache Spark是一个基于内存计算的分布式计算框架,相比MapReduce,它提供了更高的计算效率。
python
# 使用PySpark进行词频统计
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder \
.appName("WordCount") \
.master("local[*]") \
.getOrCreate()
# 读取文本文件
lines = spark.sparkContext.textFile("hdfs://input/*.txt")
# 执行词频统计
word_counts = lines \
.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
# 保存结果
word_counts.saveAsTextFile("hdfs://output/word_counts")
# 打印前10个单词
for word, count in word_counts.take(10):
print(f"{word}: {count}")
# 关闭SparkSession
spark.stop()图3展示了Spark的架构设计:
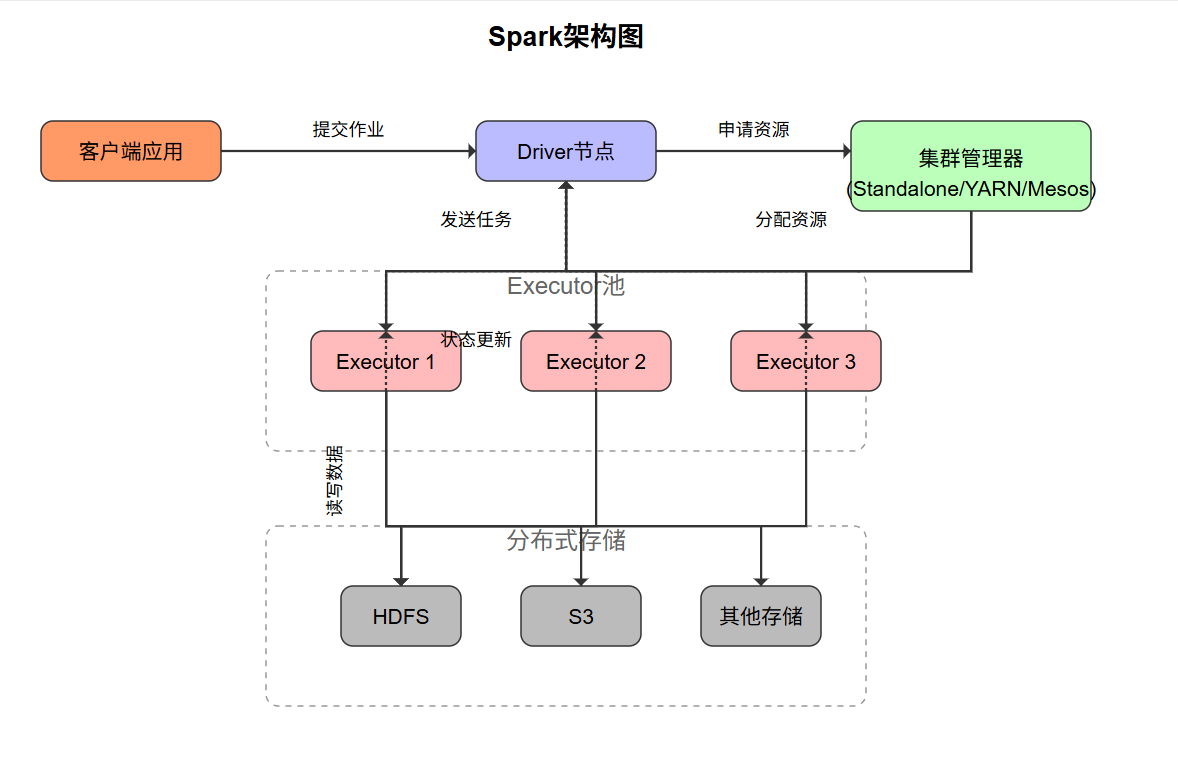
图3:Spark架构图 - 展示了Spark的核心组件及其交互关系,包括客户端、Driver节点、集群管理器、Executor和分布式存储系统。
四、分布式计算的挑战与解决方案
4.1 常见挑战
分布式系统面临着多种独特的挑战,下表总结了主要挑战及其解决方案:
| 挑战 | 描述 | 解决方案 |
|---|---|---|
| 网络分区 | 网络故障导致系统分为多个独立部分 | 使用CAP理论指导设计,Paxos/Raft共识算法 |
| 节点故障 | 单个或多个节点停止工作 | 冗余设计,心跳检测,自动故障转移 |
| 时钟同步 | 各节点时钟不一致 | NTP协议,逻辑时钟,向量时钟 |
| 数据一致性 | 多副本数据同步问题 | 强一致性(2PC/3PC),最终一致性(Gossip) |
| 负载均衡 | 节点间任务分配不均 | 动态任务调度,数据分区策略 |
| 安全性 | 分布式环境中的安全威胁 | 身份认证,加密通信,访问控制 |
4.2 性能优化策略
分布式系统的性能优化涉及多个层面:
4.2.1 数据本地化
尽量将计算任务分配到数据所在节点,减少网络传输开销。
python
# Spark中的数据本地化示例
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataLocality").getOrCreate()
# 设置数据本地化级别
spark.conf.set("spark.locality.wait", "10s") # 等待本地数据的最长时间
spark.conf.set("spark.locality.wait.process", "0s") # 进程本地化
spark.conf.set("spark.locality.wait.node", "3s") # 节点本地化
spark.conf.set("spark.locality.wait.rack", "6s") # 机架本地化
# 读取数据并进行计算
rdd = spark.sparkContext.textFile("hdfs://path/to/data")
result = rdd.map(lambda x: process_data(x)).reduce(lambda a, b: combine_results(a, b))4.2.2 缓存策略
合理使用缓存减少重复计算:
python
# Spark中的RDD缓存
rdd = spark.sparkContext.textFile("large_dataset.txt")
# 对经常使用的数据进行缓存
cached_rdd = rdd.filter(lambda x: is_important(x)).cache() # 或 persist()
# 多次使用缓存的数据
result1 = cached_rdd.map(lambda x: process1(x)).collect()
result2 = cached_rdd.map(lambda x: process2(x)).collect()图4展示了分布式系统中不同一致性级别与性能的关系:
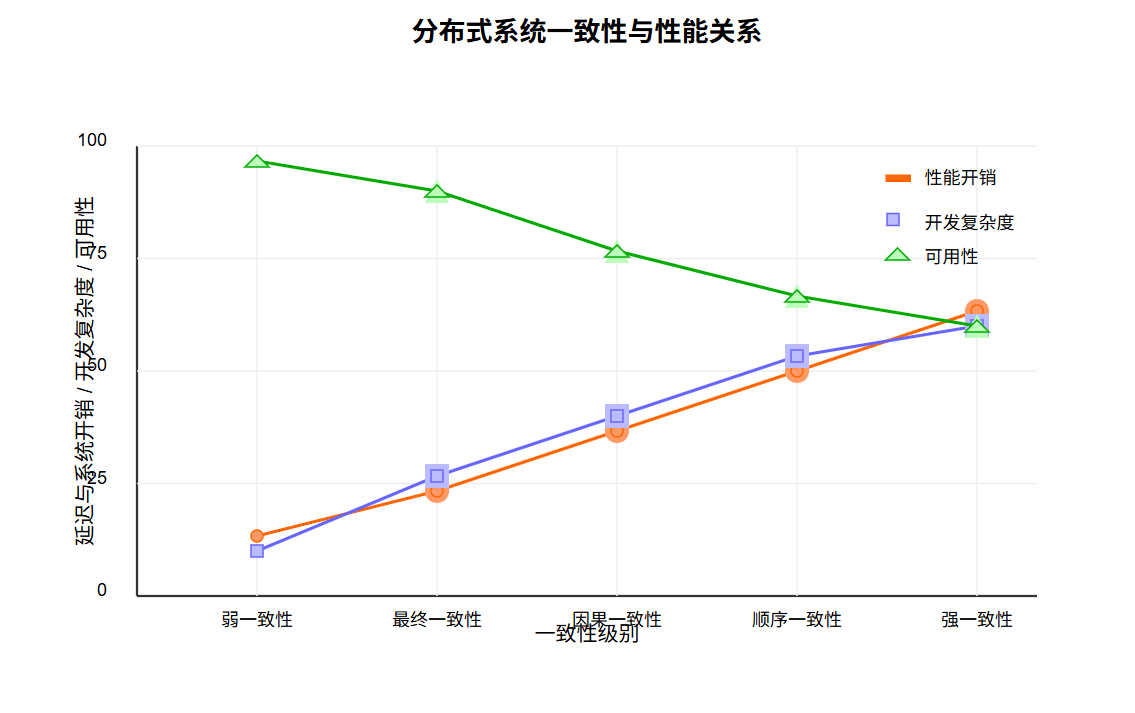
图4:分布式系统一致性与性能关系图 - 展示了不同一致性级别对系统性能开销、开发复杂度和可用性的影响。
五、分布式计算的未来趋势
5.1 边缘计算
边缘计算将计算能力下沉到网络边缘,减少延迟,提高实时性:
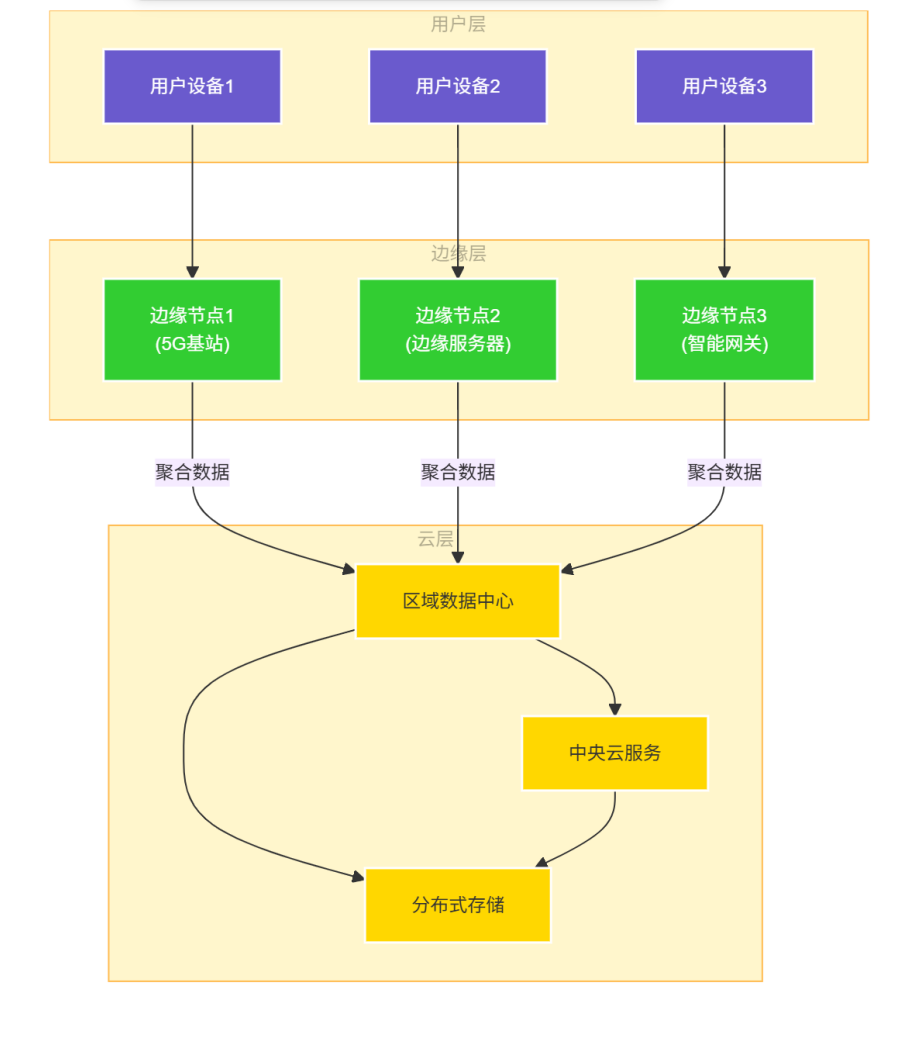
图5:边缘计算架构图 - 展示了边缘计算的三层架构:用户层、边缘层和云层,以及数据在不同层级之间的流动。
5.2 分布式机器学习
分布式机器学习将传统机器学习算法扩展到分布式环境,提高训练效率:
python
# PyTorch分布式训练示例
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torch.nn.parallel import DistributedDataParallel as DDP
import os
# 初始化分布式环境
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# 清理分布式环境
def cleanup():
dist.destroy_process_group()
# 简单的神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# 训练函数
def train(rank, world_size):
setup(rank, world_size)
# 创建模型并移至对应设备
model = Net().to(rank)
# 包装模型以支持分布式训练
ddp_model = DDP(model, device_ids=[rank])
# 损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# 准备数据加载器(需要进行数据分片)
# ...
# 训练循环
for epoch in range(10):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(rank), target.to(rank)
optimizer.zero_grad()
output = ddp_model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
cleanup()六、实战案例:构建高可用分布式系统
6.1 系统架构设计
下面我们通过一个电商推荐系统的例子,展示如何构建一个高可用的分布式系统:
6.2 关键代码实现
python
# 分布式推荐系统的服务注册与发现
import etcd3
import json
import time
class ServiceRegistry:
def __init__(self, etcd_host='localhost', etcd_port=2379):
self.etcd = etcd3.client(host=etcd_host, port=etcd_port)
self.lease_id = None
def register_service(self, service_name, service_ip, service_port, ttl=60):
"""注册服务到etcd"""
# 创建租约
self.lease_id = self.etcd.lease(ttl)
# 服务信息
service_info = {
'ip': service_ip,
'port': service_port,
'timestamp': time.time()
}
# 注册服务
service_key = f"/services/{service_name}/{service_ip}:{service_port}"
self.etcd.put(
service_key,
json.dumps(service_info),
lease=self.lease_id
)
print(f"服务 {service_name} 注册成功: {service_ip}:{service_port}")
return True
def keep_alive(self):
"""保持服务活跃"""
if self.lease_id:
self.etcd.lease_keepalive(self.lease_id)
def discover_service(self, service_name):
"""发现服务"""
prefix = f"/services/{service_name}/"
services = []
for key, value in self.etcd.get_prefix(prefix):
service_info = json.loads(value.decode('utf-8'))
services.append(service_info)
return services总结
分布式计算已经成为支撑现代大数据处理、人工智能和高并发应用的基础设施。通过本文的探讨,我们从基本概念出发,深入研究了分布式计算的关键技术、主流框架以及面临的挑战与解决方案。
在实践中,构建高性能、高可用的分布式系统需要综合考虑多个因素:一致性与可用性的权衡、网络延迟的优化、容错机制的设计等。随着边缘计算、分布式机器学习等新兴技术的发展,分布式计算的应用场景将更加广泛,技术也将持续演进。
作为技术从业者,我们需要不断学习和实践,掌握分布式系统的设计理念和实现技巧,才能在这个数据爆炸的时代构建出高效、可靠的计算系统。
在未来的技术之路上,分布式计算将继续扮演重要角色,它不仅是解决大数据处理的工具,更是推动人工智能、物联网等领域发展的关键基础设施。让我们一起探索分布式计算的无限可能!
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!