1.前馈全连接神经网络对鸢尾花数据集进行分类
1.1导入鸢尾花数据集
iris =load_iris()1.2划分训练集测试集
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=23)参数1:数据集数据
参数2:数据集标签
参数3:测试集大小
参数4:随机种子
1.3划分验证集
x_train,X_valid,y_train,y_valid = train_test_split(x_train,y_train,test_size=0.2,random_state=12)1.4输出验证集训练集的形状
print(X_valid.shape)
print(X_train.shape)运行结果:

1.5 训练模型(和上篇文章有些方法是一样的)
keras.layers.Dropout(rate=0.2)Dropout是一种正则化方法,用于防止过拟合;rate=0.2表示在训练时,该层会随机地将20%的输入单元置0
8.6使用fit训练模型,将训练过程转为二维数组
h = model.fit(x_train,y_train,batch_size=10,epochs=20,validation_data=(X_valid,y_valid))
pd.DataFrame(h.history)运行结果:

1.7 画图
运行结果:

1.8评估模型:使用函数evaluate
model.evaluate(x_test,y_test,batch_size=1)运行结果:

2.卷积神经网络
2.1加载显示图像
2.1.1导入加载内置图像的库
from sklearn.datasets import load_sample_image2.1.2将图像进行归一化
china = load_sample_image('china.jpg')/255
flower = load_sample_image('flower.jpg')/2552.1.3绘制图像
plt.subplot(1,2,1)
plt.imshow(china)
plt.subplot(1,2,2)
plt.imshow(flower)2.1.4输出维度
print('china.jpg的维度:',china.shape)
print('flower.jpg的维度:',flower.shape)2.1.5将两张图像组成一个数组
imgs = np.array([china,flower])
img_shape = imgs.shape
print('数据集的维度:',img_shape)运行结果:

2.2确定卷积层大小,滑动步长 输出特征图数目
u = 7 #卷积层大小
s = 1 #滑动步长
p = 5 #输出特征图数目2.3定义二维卷积层
python
conv = keras.layers.Conv2D(filters = p,kernel_size = u,strides = s,padding = 'SAME',activation = 'relu',input_shape = img_shape)参数1:卷积核数量
参数2:卷积核的大小
参数3:卷积的步长
参数4:卷积操作时使用的填充方式, 'SAME' 表示使用边界像素填充,保持卷积后输出的空间维度与输入相同,'VALID'不使用填充,可能会导致输出的空间维度小于输入
参数5:激活函数
参数6:输出数据的形状
2.4将二维卷积层应用于图像数组,打印卷积后的张量大小
python
img_after_conv = conv(imgs)
print('卷积后的张量大小:',img_after_conv.shape)运行结果:
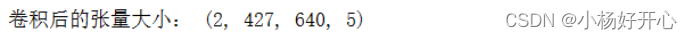
2.5 汇聚层
2.5.1应用最大池化层到卷积后的图像数据,减少数据维度,打印处理后的图像数据的形状
定义了一个最大池化层 ,参数为:指定了池化窗口的大小
python
pool_max = keras.layers.MaxPool2D(pool_size = 2)将最大池化层应用到卷积后的图像数据
python
img_after_pool_max = pool_max(img_after_conv)
print('最大汇聚后的张量大小:',img_after_pool_max.shape)运行结果:
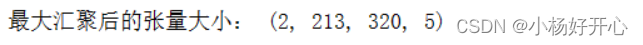
2.6 平均汇聚
和汇聚层操作过程一样,使用的方法不一样
keras.layers.AvgPool2D
运行结果:

2.7 全局平均汇聚
和汇聚层操作过程一样,使用的方法不一样
keras.layers.GlobalAvgPool2D
运行结果:
