【Stable Diffusion】文生图超详参数使用技巧和方法推荐
仁者见仁,智者见智,一千个读者,一千个哈姆雷特。
此章为记录学习和分享,为后继初学者提供便利。
作者:AI时代社
链接:https://zhuanlan.zhihu.com/p/629910090
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
操作界面介绍
典型的Stable Diffusion操作界面如下图:
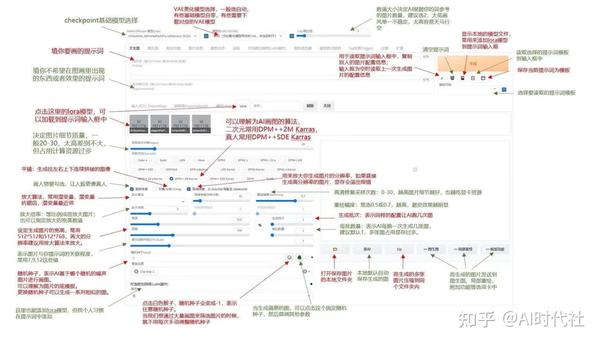
可以看到里面的参数非常多。
但新手小白其实只需要知道两个参数就行。
基础参数介绍
提示词(Prompt)和反向提示词(Negative Prompt)
提示词内输入的东西就是你想要画的东西,反向提示词内输入的就是你不想要画的东西。
提示框内只能输入英文 ,所有符号都要使用英文半角 ,词语之间使用半角逗号隔开。
反向提示词
这里重点提一下反向提示词,与提示词相反,反向提示词输入的是你不希望SD产生的。这是SD的一个非常强大但未被充分利用的功能。有时候你正面提示词写一堆,出来的效果也不理想,但是加上一个反向提示词就能获得理想的结果。
一般负面提示:低分辨率、错误、裁剪、最差质量、低质量、jpeg伪像、帧外、水印、签名
General: lowres, error, cropped, worst quality, low quality, jpeg artifacts, out of frame, watermark, signature

人物肖像的负面提示:变形、丑陋、残缺、毁容、文本、额外的四肢、面部切割、头部切割、额外的手指、额外的手臂、绘制不佳的脸、突变、比例不良、头部裁剪、四肢畸形、手突变、融合手指、长脖子
Negative prompts for people portraits: deformed, ugly, mutilated, disfigured, text, extra limbs, face cut, head cut, extra fingers, extra arms, poorly drawn face, mutation, bad proportions, cropped head, malformed limbs, mutated hands, fused fingers, long neck

逼真图像的负面提示:逼真:插图、绘画、素描、艺术、素描'
Negative prompts for photorealistic images: Photorealistic: illustration, painting, drawing, art, sketch'

基本上,掌握了提示词和反向提示词的书写,AI绘画就算是入门了(至少可以画出东西来了!)但如果想要更加一步的,请继续往下看(哪怕你是老手,下面的文章也值得你一看哦~)。
采样迭代步数(Steps)

Stable-Diffusion通过从充满噪点的画布开始创建图像,然后逐渐去噪以达到最终输出。Steps就是控制这些去噪步骤的数量。通常,越高越好,但一般情况下,我们使用的默认值是20个步骤,这其实已经足以生成任何类型的图像。
以下是有关在不同情况下使用steps的一般指南:
a 如果你正在测试新提示并希望获得快速结果 来调整输入,请使用10-15个steps。
b 找到所需的提示后,将步骤增加到20-30,很多人的习惯是28。
c 如果你正在创建带有毛皮或任何具有详细纹理的主题的面部或动物 ,并且觉得生成的图像缺少其中一些细节,请尝试将其提高到40或者更高。
特别提示:
有些人习惯于一上来就创建具有100或150步的图像,这对于LMS等采样器很有用,但除非你有很强的显卡,否则很多时候都是浪费时间。先用小步骤去测试,找到合适的提示词后再提升步数才是正确的方法。
而且,使用改进的快速采样器(如 DDIM 和 DPM++系列)一般用100以内的步数就完全OK了,通过对这些采样器使用大量步骤,很可能只会浪费时间和GPU算力,而不会提高图像质量。
采样方法(Sampler)
正如我们之前提到的,SD通过对起始噪声画布进行降噪来工作。这就是扩散采样器发挥作用的地方。简单来说,这些采样器是算法,它们在每个步骤后获取生成的图像并将其与文本提示请求的内容进行比较,然后对噪声进行一些更改,直到它逐渐达到与文本描述匹配的图像。
用户最常用的三个采样器分别是Euler a,DDIM和DPM++系列。你可以尝试这三个,看看哪个更适合你的提示。


由于采样器的规则过于学术化,仔细讲解也未必能说出一个123来,这里以相同的参数,不同的采样器去测试了同一张图,分别出来的效果如上,仅供参考。
总体而言,欧拉采样器(Euler a)具有更平滑的颜色和较少定义的边缘,使其更具"梦幻"外观,因此如果这是你在生成的图像中喜欢的效果,请使用Euler a。
DPM2和DPM++系列更加写实。
LMS、DPM fast 虽然出图快,但有可能人是不完整的。
生成批次和生成数量
生成批次是显卡一共生成几批图片。
每批数量是显卡每批生成几张图片。
也就是说你每点击一次生成按钮,生成的图片数量=批次*数量
需要注意的是每批数量是显卡一次所生成的图片数量,速度要比调高批次快一点,但是调的太高可能会导致显存不足导致生成失败,而生成批次不会导致显存不足,只要时间足够会一直生成直到全部输出完毕。
输出分辨率(宽度和高度)
图片分辨率非常重要,直接决定了你的图片内容的构成和细节的质量。
a.输出大小
输出大小决定了画面内容的信息量,很多细节例如全身构图中的脸部,饰品,复杂纹样等只有在大图上才能有足够的空间表现,如果图片过小,像是脸部则只会缩成一团,是没有办法充分表现的。
但是图片越大ai就越倾向于往里面塞入更多的东西,绝大多数模型都是在512*512分辨率下训练的,少数在768*768下训练,所以当输出尺寸比较大比如说1024*1024的时候,ai就会尝试在图中塞入两到三张图片的内容量,于是会出现各种肢体拼接,不受词条控制的多人,多角度等情况,增加词条可以部分缓解,但是更关键的还是控制好画幅,先画中小图,再放大为大图。
大致的输出大小和内容关系参考:
1.约30w像素,如512*512,大头照和半身为主
2.约60w像素,如768*768,单人全身为主,站立或躺坐都有
3.越100w像素,如1024*1024,单人和两三人全身,站立为主
4.更高像素,群像,或者直接画面崩坏
b.宽高比例
宽高比例会直接决定画面内容,同样是1girl的例子:
1.方图512*512,会倾向于出脸和半身像
2.高图512*768,会倾向于出站着和坐着的全身像
3.宽图768*512,会倾向于出斜构图的半躺像
所以要根据想要的内容来调整输出比例。
提示词相关性(CFG Scale)
CFG这个参数可以看作是"创造力与提示"量表。较低的数字使AI有更多的自由发挥创造力,而较高的数字迫使它更多地坚持提示词的内容。
默认的CFG是7,这在创造力和生成你想要的东西之间是最佳平衡。通常不建议低于5,因为图像可能开始看起来更像AI的幻觉,而高于16可能会开始产生带有丑陋伪影的图像。

那么何时使用不同的CFG刻度值呢?CFG量表可以分为不同的范围,每个范围适用于不同的提示类型和目标。
1.CFG 2--6:创意,但可能过于失真,没有按照提示进行操作。对于简短的提示可能很有趣且有用;
2.CFG 7--10:建议用于大多数提示。创造力和引导式生成之间的良好平衡;
3.CFG 10--15:当你确定提示很详细并且非常清楚你希望图像的外观时(有些纯风景和建筑类的图片可能需要的CFG会比较高,大家可以参考相应的模型说明);
4.CFG 16--20: 除非提示非常详细,否则通常不建议使用。可能会影响一致性和质量;
5.CFG >20:几乎从不使用。
随机种子(seed)
随机种子是一个决定我们之前讨论的初始随机噪声的数字,由于随机噪声决定了最终图像,这就是为什么每次在StableDiffusion系统上运行完全相同的提示时都会得到不同的图像,以及为什么如果多次使用相同的提示运行相同的seed的时候,你会得到相同的生成图像。
由于相同的种子和提示组合每次都提供相同的图像,因此我们可以通过多种方式利用此属性:
a.控制角色的特定特征:在这个例子中,我们改变了情绪,但这也适用于其他物理特征,如头发颜色或肤色,但变化越小,它就越有可能被改变。

b.测试特定单词的效果:如果你想知道提示中的特定单词发生了哪些变化,则可以使用相同的种子和修改后的提示进行测试,最好通过每次更改单个单词或短语来测试提示。

c.更改样式:如果你喜欢图像的构图,但想知道它以不同的样式显示效果。这可用于肖像、风景或你创建的任何场景。

IMG 2 IMG参数
Img2img 功能的工作方式与 txt2img 完全相同,唯一的区别是你提供了一个用作起点的图像,而不是种子编号产生的噪声。
噪点被添加到你用作 img2img 的初始化图像的图像中,然后根据提示继续扩散过程。添加的噪声量取决于**"重绘幅度(Denoising)"**这个参数,该参数的范围从0到1,其中0根本不添加噪声,你将获得添加的确切图像,1完全用噪声替换图像,几乎就像你使用普通的txt2img而不是img2img一样。
那么如何决定使用什么力量呢?这是一个带有示例的简单指南:
a.要创建图像的变体,建议使用的强度为 0.5-0.75,并且具有相同的提示。当你喜欢创建的图像的构图但某些细节看起来不够好,或者你想创建与你在其他软件(如 Blender或 photoshop)中创建的图像相似的图像时,这可能很有用(在这种情况下,提示将是对原有图像的描述)。

b.要更改图像样式,同时使其与原始图像相似,你可以多次使用较低强度的img2img,与具有较高强度的单个img2img相比,可以获得更好的图像保真度。

在这个例子中,我们使用0.25的强度4次,所以每次我们生成图像时,我们都会将生成的图像重新插入img2img中,并以相同的提示和强度重新运行它,直到我们得到我们需要的样式。如果在img2img中使用相同的图像,强度更高,你将很快失去图像相似性。
最后想说
AIGC(AI Generated Content)技术,即人工智能生成内容的技术,具有非常广阔的发展前景。随着技术的不断进步,AIGC的应用范围和影响力都将显著扩大。以下是一些关于AIGC技术发展前景的预测和展望:
1、AIGC技术将使得内容创造过程更加自动化,包括文章、报告、音乐、艺术作品等。这将极大地提高内容生产的效率,降低成本。2、在游戏、电影和虚拟现实等领域,AIGC技术将能够创造更加丰富和沉浸式的体验,推动娱乐产业的创新。3、AIGC技术可以帮助设计师和创意工作者快速生成和迭代设计理念,提高创意过程的效率。
未来,AIGC技术将持续提升,同时也将与人工智能技术深度融合,在更多领域得到广泛应用。感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程。
对于从来没有接触过AI绘画的同学,我已经帮你们准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
AIGC学习必备工具和学习步骤
工具都帮大家整理好了,安装就可直接上手
现在AI绘画还是发展初期,大家都在摸索前进。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。
学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图 、Stable Diffusion安装包 、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册 、AI绘画视频教程 、AIGC实战等等。
【Stable Diffusion安装包(含常用插件、模型)】
【AI绘画12000+提示词库】
【AI绘画800+骨骼姿势图】

【AI绘画视频合集】
这份完整版的stable diffusion资料我已经打包好,点击下方卡片即可免费领取!
