1. 前言
生成对抗网络(GAN,Generative Adversarial Network)是由Ian Goodfellow等人在2014年提出的一种深度学习模型,用于学习和生成与真实数据分布相似的数据。GAN由生成器(Generator)和判别器(Discriminator)两个部分组成,通过相互对抗的方式进行训练。生成器接受随机噪声并生成假数据,试图欺骗判别器;判别器则试图区分真实数据和生成数据,通过不断竞争,两个网络共同提升各自的性能。
在CP预测的娱乐项目中,GAN用于学习历史CP数据的分布,并生成类似的号码。需要强调的是,这种应用仅限于技术学习和娱乐,不具备实际预测能力。通过训练,生成器生成与历史数据分布相似的号码,判别器提升其区分真假数据的能力。最终,GAN展示了其在数据分布学习中的强大能力。
2. 准据准备
大lott 由7个号码组成,前区5个不重复数字【1-35】,后区2个不重复数字【1-12】。先搜集2500左右历史样本
接下来进行数据处理,用于训练

python
def lotto_data_loader(file_path, val_n=50, seed=24, batch_size=32):
# 读取文件
data = pd.read_excel(file_path)
# 数据预处理:拆分前区和后区号码并合并为一个数据集,然后进行归一化处理
front_area_numbers = data['前区'].str.split(' ', expand=True).astype(int)
back_area_numbers = data['后区'].str.split(' ', expand=True).astype(int)
# 归一化处理
front_area_numbers = (front_area_numbers - 1) / 34.0 # 前区号码范围1-35,归一化到0-1
back_area_numbers = (back_area_numbers - 1) / 11.0 # 后区号码范围1-12,归一化到0-1
# 合并前区和后区的号码
all_numbers = pd.concat([front_area_numbers, back_area_numbers], axis=1).values
all_numbers = torch.tensor(all_numbers, dtype=torch.float32)
print(f"All numbers shape: {all_numbers.shape}")
# Create TensorDataset
dataset = TensorDataset(all_numbers)
# 划分数据集
data_size = len(all_numbers) - val_n
train_dataset, val_dataset = random_split(dataset,
[data_size, val_n],
generator=torch.Generator().manual_seed(seed))
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False)
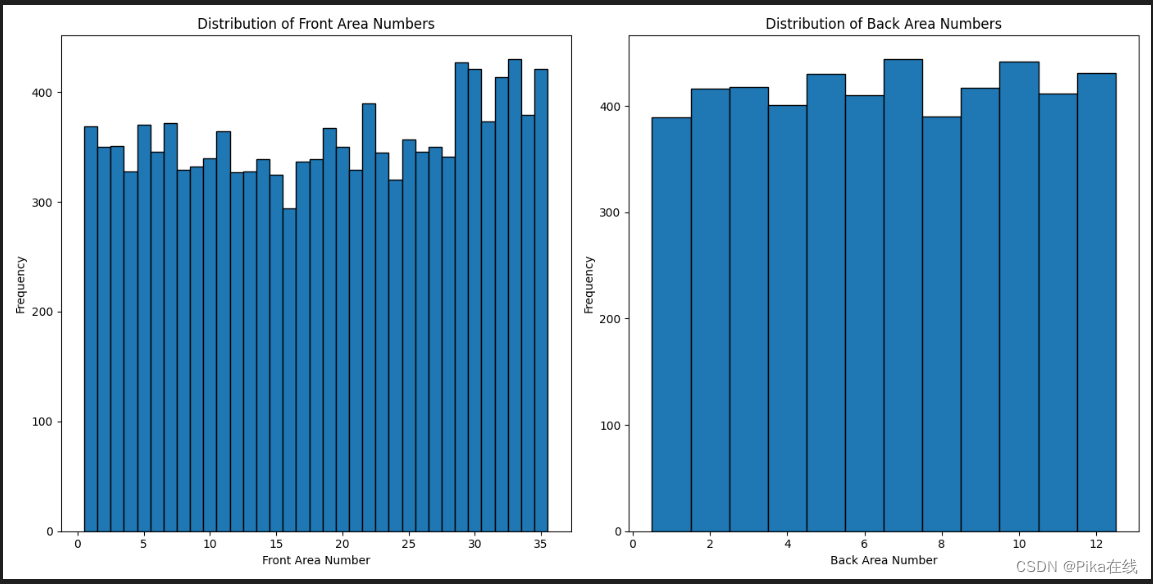
return train_loader, val_loaderCP中数字分布如下,是一个均匀分布
3. 定义GAN网络
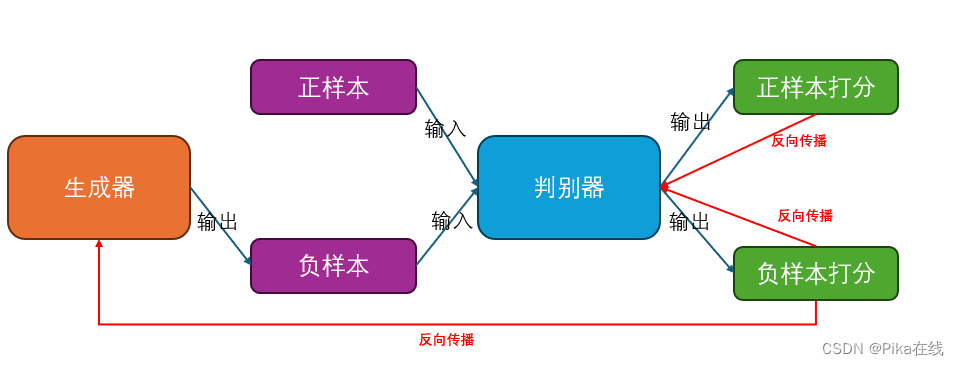
GAN的大致原理如图
【1】判别器对正负样本进行打分,同时根据二者误差信号优化自身
【2】生成器只生成逼真的负样本,同时根据判别器的负样本打分优化自身
3.1 定义生成器
定义一个简单的全连接网络预测CP号码
模型输入:随机噪声 【正态分布】
模型输出:7位CP号码0, 1 预测打分,继而预测CP序列:Y0:5 * 35 + Y5:7 *12
python
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 256), # 输入层,输入维度为 input_dim,输出维度为256
nn.LeakyReLU(0.2), # LeakyReLU 激活函数
nn.BatchNorm1d(256), # 批量归一化
nn.Linear(256, 512), # 隐藏层,输入维度256,输出维度512
nn.LeakyReLU(0.2), # LeakyReLU 激活函数
nn.BatchNorm1d(512), # 批量归一化
nn.Linear(512, 1024), # 隐藏层,输入维度512,输出维度1024
nn.LeakyReLU(0.2), # LeakyReLU 激活函数
nn.BatchNorm1d(1024), # 批量归一化
nn.Linear(1024, output_dim), # 输出层,输入维度1024,输出维度 output_dim
nn.Sigmoid() # Sigmoid 激活函数,输出值在0到1之间
)
def forward(self, x):
"""前向传播函数"""
return self.model(x) # 将数据传入模型,得到输出,形状为 N x output_dim3.2 定义判别器
判别器也采用简单全连接网络,输出采用sigmoid 对正负样本进行打分0,1
0:False, 1:True
python
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
# 定义模型的全连接层和激活函数
self.model = nn.Sequential(
nn.Linear(input_dim, 512), # 输入层,输入维度为 input_dim,输出维度为512
nn.LeakyReLU(0.2), # LeakyReLU 激活函数
nn.Linear(512, 256), # 隐藏层,输入维度512,输出维度256
nn.LeakyReLU(0.2), # LeakyReLU 激活函数
nn.Linear(256, 1), # 输出层,输入维度256,输出维度1
nn.Sigmoid() # Sigmoid 激活函数,输出值在0到1之间
)
def forward(self, x):
return self.model(x) # 前向传播函数,返回模型的输出4. 定义损失函数
4.1 判别器损失函数
判别器用于鉴别真实样本和生成样本,前期鉴别的越准则生成器的仿真能力逐步越强【道高一尺魔高一丈】,我们考虑以下优化目标:
【1】使用经典的交叉熵来判别正负样本分布距离
【2】CP序列中前区和后区中每个数字唯一不重复,构建重复惩罚
【3】CP号段中前区号段5个号码不超过35,后区号段2个号码不超过12,构建溢出惩罚
python
def discriminator_loss(y_true, y_pred, generated_numbers):
bce_loss = nn.BCELoss()(y_pred, y_true)
# 获取生成的号码
front_numbers = generated_numbers[:, :5] * 34.0 + 1.0 # 反归一化到1-35
back_numbers = generated_numbers[:, 5:] * 11.0 + 1.0 # 反归一化到1-12
# 前区和后区号码范围约束(仅最大值约束)
front_range_loss = torch.sum(torch.clamp(front_numbers - 35.0, min=0.0))
back_range_loss = torch.sum(torch.clamp(back_numbers - 12.0, min=0.0))
# 使用torch.clamp确保前区和后区号码在适当范围内
front_numbers = torch.clamp(front_numbers, 1, 35)
back_numbers = torch.clamp(back_numbers, 1, 12)
# 前区和后区号码不重复约束
front_unique_loss = torch.sum((torch.nn.functional.one_hot(front_numbers.to(torch.int64) - 1, num_classes=35).sum(dim=1) > 1.0).float())
back_unique_loss = torch.sum((torch.nn.functional.one_hot(back_numbers.to(torch.int64) - 1, num_classes=12).sum(dim=1) > 1.0).float())
# 组合损失
total_loss = bce_loss + 0.1 * (front_range_loss + back_range_loss + front_unique_loss + back_unique_loss)
return total_loss对正负样本的鉴别的联合损失
python
# Labels for real and fake data
valid = torch.ones(batch_size, 1)
fake = torch.zeros(batch_size, 1)
# Generate fake lottery numbers from random noise
noise = torch.randn(batch_size, input_dim)
fake_numbers = generator(noise)
# Train the discriminator
real_loss = discriminator_loss(valid, discriminator(real_numbers), real_numbers)
fake_loss = discriminator_loss(fake, discriminator(fake_numbers.detach()), fake_numbers.detach())
d_loss = 0.5 * (real_loss + fake_loss)
d_loss.backward()4.2 生成器损失
生成器的优化目标之和负样本有关,即构建逼真的伪样本
python
g_loss = discriminator_loss(valid, discriminator(fake_numbers), fake_numbers)
g_loss.backward()5. G/D 联合训练
这里对生成器(G)/判别器(D)联合训练,在每个epoch里对判别器多训练优先培养鉴别能力
【训练停止条件】:(1)整体loss下降切收敛(2)判别器的识别率下降即无法分辨
python
for epoch in range(epochs):
for real_numbers_batch in train_loader:
real_numbers = real_numbers_batch[0]
batch_size = real_numbers.size(0)
# print(real_numbers.shape)
# 更新判别器n_critic次
for _ in range(n_critic):
# 为真实和生成的数据设置标签
valid = torch.ones(batch_size, 1)
fake = torch.zeros(batch_size, 1)
# 从随机噪声生成假的彩票号码
noise = torch.randn(batch_size, input_dim)
fake_numbers = generator(noise)
# 训练判别器
optimizer_D.zero_grad()
real_loss = discriminator_loss(valid, discriminator(real_numbers), real_numbers)
fake_loss = discriminator_loss(fake, discriminator(fake_numbers.detach()), fake_numbers.detach())
d_loss = 0.5 * (real_loss + fake_loss)
d_loss.backward()
optimizer_D.step()
# 计算判别器准确率
real_acc = (discriminator(real_numbers) > 0.5).float().mean()
fake_acc = (discriminator(fake_numbers.detach()) < 0.5).float().mean()
d_acc = 0.5 * (real_acc + fake_acc)
# 训练生成器
optimizer_G.zero_grad()
g_loss = discriminator_loss(valid, discriminator(fake_numbers), fake_numbers)
g_loss.backward()
optimizer_G.step()
# 使用验证数据进行评估
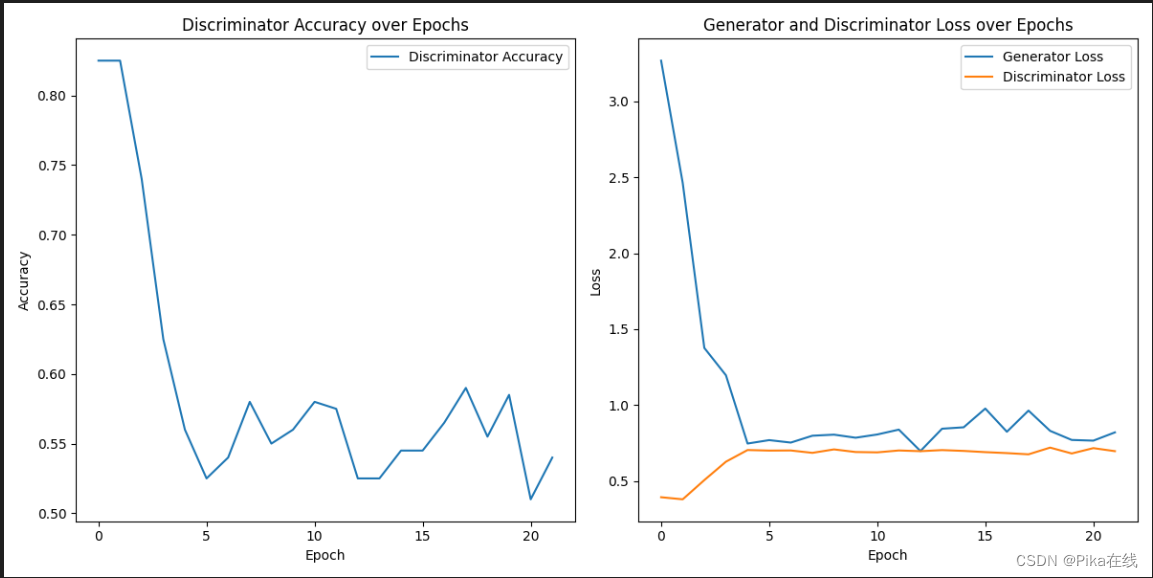
val_g_loss, val_d_loss, val_d_acc = evaluate(generator, discriminator, val_loader)训练的日志如下
可以看到【1】生成器损失下降切收敛【2】判别器识别率下降,难以区分仿真样本
6. 生成CP号码
训练好生成器,开始预测CP号码啦
python
import torch
import numpy as np
from generator import Generator
# 定义生成器输入(噪声)的维度和生成器输出(彩票号码)的维度
input_dim = 100
output_dim = 7
# 实例化生成器模型
generator = Generator(input_dim, output_dim)
# 加载训练好的生成器模型权重
generator.load_state_dict(torch.load('generator_model.pth'))
generator.eval() # 设置生成器为评估模式
# 生成新的噪声数据
batch_size = 10 # 生成10组彩票号码
noise = torch.randn(batch_size, input_dim)
# 通过生成器生成彩票号码
with torch.no_grad(): # 禁用梯度计算
generated_numbers = generator(noise).numpy()
# 对生成的彩票号码进行后处理(反归一化)
# 假设前区号码范围1-35,后区号码范围1-12
front_area_numbers = generated_numbers[:, :5] * 34 + 1
back_area_numbers = generated_numbers[:, 5:] * 11 + 1
# 将彩票号码转换为整数
front_area_numbers = front_area_numbers.astype(int)
back_area_numbers = back_area_numbers.astype(int)
# 打印生成的彩票号码
print("Generated Lottery Numbers:")
for i in range(batch_size):
print(f"Front Area: {front_area_numbers[i]}, Back Area: {back_area_numbers[i]}")
# 保存生成的彩票号码到文件
np.savetxt('generated_lottery_numbers.txt', np.hstack((front_area_numbers, back_area_numbers)), fmt='%d', delimiter=',')运行完毕后,生成器给出10组建议号码

7. 总结
本文采用GAN网络范式来尝试拟合CP序列分布,内容仅为技术学习,含娱乐成分,不构成任何TZ建议